
AI-hallucinationer og brandsikkerhed: Beskyt dit omdømme
Lær hvordan AI-hallucinationer truer brandsikkerheden på tværs af Google AI Overviews, ChatGPT og Perplexity. Opdag overvågningsstrategier, indholdsforstærkning...
9 min læsning

Opdag hvordan LLM-grounding og websøgning gør det muligt for AI-systemer at få adgang til realtidsinformation, reducere hallucinationer og levere præcise citater. Lær om RAG, implementeringsstrategier og bedste praksis for virksomheder.
Store sproglige modeller trænes på enorme mængder tekstdata, men denne træningsproces har en kritisk begrænsning: den indfanger kun information tilgængelig op til et bestemt tidspunkt, kendt som knowledge cutoff-datoen. For eksempel, hvis en LLM er trænet med data til og med december 2023, har den ingen viden om begivenheder, opdagelser eller udviklinger, der er sket efter denne dato. Når brugere stiller spørgsmål om aktuelle begivenheder, nylancerede produkter eller breaking news, kan modellen ikke hente denne information fra sine træningsdata. I stedet for at indrømme usikkerhed, genererer LLM’er ofte svar, der lyder plausible, men som faktuelt er forkerte—et fænomen kendt som hallucination. Denne tendens bliver især problematisk i applikationer, hvor nøjagtighed er kritisk, såsom kundesupport, finansiel rådgivning eller medicinsk information, hvor forældet eller opdigtet information kan få alvorlige konsekvenser.
Grounding er processen, hvor en LLM’s forudtrænede viden suppleres med ekstern, kontekstuel information ved inferenstid. I stedet for kun at stole på mønstre lært under træningen, forbinder grounding modellen til virkelige datakilder—hvad enten det er websider, interne dokumenter, databaser eller API’er. Dette koncept stammer fra kognitiv psykologi, især teorien om situated cognition, som hævder, at viden anvendes mest effektivt, når den er forankret i den kontekst, hvor den skal bruges. I praksis forvandler grounding problemet fra “generér et svar fra hukommelsen” til “syntetisér et svar ud fra den givne information.” En streng definition fra nyere forskning kræver, at LLM’en bruger al væsentlig viden fra den givne kontekst og holder sig inden for dens rammer uden at hallucinere yderligere information.
| Aspekt | Ikke-groundet svar | Groundet svar |
|---|---|---|
| Informationskilde | Kun forudtrænet viden | Forudtrænet viden + ekstern data |
| Nøjagtighed for aktuelle begivenheder | Lav (knowledge cutoff-begrænsninger) | Høj (adgang til aktuel information) |
| Hallucinationsrisiko | Høj (modellen gætter) | Lav (begrænset af givet kontekst) |
| Citeringsmulighed | Begrænset eller umulig | Fuld sporbarhed til kilder |
| Skalerbarhed | Fast (modelstørrelse) | Fleksibel (kan tilføje nye datakilder) |
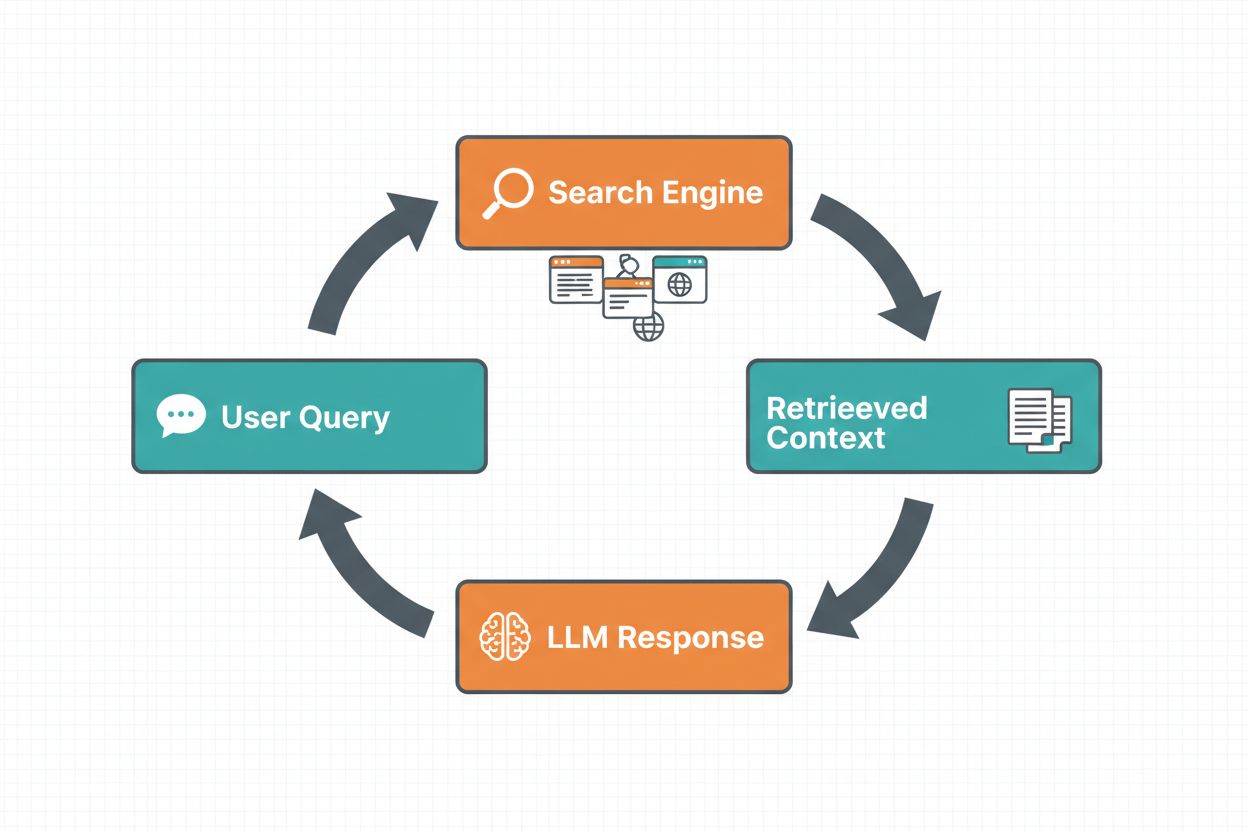
Websøgning-grounding gør det muligt for LLM’er at få adgang til realtidsinformation ved automatisk at søge på nettet og indarbejde resultaterne i modellens svargenerering. Arbejdsgangen følger en struktureret sekvens: først analyserer systemet brugerens prompt for at afgøre, om en websøgning vil forbedre svaret; dernæst genererer det én eller flere søgeforespørgsler optimeret til at hente relevant information; tredje skridt er at udføre disse forespørgsler mod en søgemaskine (såsom Google Search eller DuckDuckGo); fjerde skridt er at behandle søgeresultaterne og udtrække relevant indhold; og endelig gives denne kontekst til LLM’en som en del af prompten, så modellen kan generere et groundet svar. Systemet returnerer også grounding metadata—struktureret information om, hvilke søgeforespørgsler der blev kørt, hvilke kilder der blev hentet, og hvordan specifikke dele af svaret understøttes af disse kilder. Disse metadata er essentielle for at opbygge tillid og gøre det muligt for brugere at verificere påstande.
Websøgning-grounding arbejdsgang:
Retrieval Augmented Generation (RAG) har vist sig som den dominerende grounding-teknik, der kombinerer årtiers forskning i informationssøgning med moderne LLM-evner. RAG fungerer ved først at hente relevante dokumenter eller passager fra en ekstern videnskilde (typisk indekseret i en vektordatabase) og derefter give disse hentede elementer som kontekst til LLM’en. Hentningsprocessen involverer typisk to trin: en retriever bruger effektive algoritmer (som BM25 eller semantisk søgning med embeddings) til at identificere kandidater, og en ranker bruger mere sofistikerede neurale modeller til at genrangerer kandidaterne efter relevans. Den hentede kontekst inkorporeres derefter i prompten, så LLM’en kan syntetisere svar, der er forankret i autoritativ information. RAG giver betydelige fordele frem for finjustering: det er mere omkostningseffektivt (ingen behov for at genoplære modellen), mere skalerbart (tilføj blot nye dokumenter til vidensbasen) og nemmere at vedligeholde (opdatér information uden genoplæring). For eksempel kan en RAG-prompt se sådan ud:
Brug følgende dokumenter til at besvare spørgsmålet.
[Spørgsmål]
Hvad er hovedstaden i Canada?
[Dokument 1]
Ottawa er hovedstaden i Canada, beliggende i Ontario...
[Dokument 2]
Canada er et land i Nordamerika med ti provinser...
En af de mest overbevisende fordele ved websøgning-grounding er muligheden for at få adgang til og indarbejde realtidsinformation i LLM-svar. Dette er især værdifuldt for applikationer, der kræver aktuelle data—nyhedsanalyse, markedsundersøgelser, begivenhedsinformation eller produkt-tilgængelighed. Ud over blot adgang til frisk information giver grounding citater og kildehenvisninger, hvilket er afgørende for at opbygge brugertillid og muliggøre verifikation. Når en LLM genererer et groundet svar, returnerer den strukturerede metadata, der kortlægger specifikke påstande tilbage til deres kildedokumenter, hvilket muliggør inline-citater som “[1] source.com” direkte i svarteksten. Denne evne er direkte i tråd med missionen for platforme som AmICited.com, der overvåger, hvordan AI-systemer refererer til og citerer kilder på tværs af forskellige platforme. Muligheden for at spore, hvilke kilder et AI-system har konsulteret, og hvordan det har tilskrevet information, bliver stadig vigtigere for brandovervågning, indholdsattribution og ansvarlig AI-udrulning.
Hallucinationer opstår, fordi LLM’er grundlæggende er designet til at forudsige det næste token baseret på tidligere tokens og deres lærte mønstre, uden nogen iboende forståelse af grænserne for deres viden. Når de konfronteres med spørgsmål uden for deres træningsdata, fortsætter de med at generere tekst, der lyder plausibel, i stedet for at indrømme usikkerhed. Grounding adresserer dette ved fundamentalt at ændre modellens opgave: i stedet for at generere fra hukommelsen syntetiserer modellen nu ud fra givet information. Tekniske set, når relevant ekstern kontekst inkluderes i prompten, flyttes token-sandsynlighedsfordelingen mod svar forankret i denne kontekst, hvilket gør hallucinationer mindre sandsynlige. Forskning viser, at grounding kan reducere hallucinationsrater med 30-50% afhængig af opgave og implementering. For eksempel, hvis man spørger “Hvem vandt EM 2024?” uden grounding, kan en ældre model give et forkert svar; med grounding via websøgning identificerer den korrekt Spanien som vinder med specifikke kampdetaljer. Denne mekanisme virker, fordi modellens attention-mekanismer nu kan fokusere på den givne kontekst i stedet for at stole på potentielt ufuldstændige eller modstridende mønstre fra træningsdata.
Implementering af websøgning-grounding kræver integration af flere komponenter: et søge-API (som Google Search, DuckDuckGo via Serp API eller Bing Search), logik til at afgøre, hvornår grounding er nødvendig, og prompt engineering til effektivt at indarbejde søgeresultater. En praktisk implementering starter typisk med en vurdering af, om brugerens forespørgsel kræver aktuel information—dette kan gøres ved at spørge LLM’en selv, om prompten har brug for information nyere end dens knowledge cutoff. Hvis grounding er nødvendig, udfører systemet en websøgning, behandler resultaterne for at udtrække relevante uddrag og konstruerer en prompt, der inkluderer både det originale spørgsmål og søgekonteksten. Omkostningsovervejelser er vigtige: hver websøgning medfører API-omkostninger, så implementering af dynamisk grounding (kun at søge, når det er nødvendigt) kan reducere udgifterne betydeligt. For eksempel kræver en forespørgsel som “Hvorfor er himlen blå?” sandsynligvis ikke en websøgning, mens “Hvem er den nuværende præsident?” helt sikkert gør. Avancerede implementeringer bruger mindre, hurtigere modeller til at træffe grounding-beslutningen, hvilket reducerer latenstid og omkostninger, mens større modeller forbeholdes den endelige svargenerering.
Selvom grounding er kraftfuldt, introducerer det flere udfordringer, der skal håndteres omhyggeligt. Daterelevans er kritisk—hvis den hentede information ikke faktisk adresserer brugerens spørgsmål, hjælper grounding ikke og kan endda introducere irrelevant kontekst. Datamængde præsenterer et paradoks: selvom mere information virker fordelagtigt, viser forskning, at LLM-præstation ofte forringes med for meget input, et fænomen kaldet “lost in the middle”-bias, hvor modeller har svært ved at finde og bruge information, der er placeret i midten af lange kontekster. Tokeneffektivitet bliver en bekymring, fordi hver del af den hentede kontekst bruger tokens, hvilket øger latenstid og omkostninger. Princippet om “less is more” gælder: hent kun de top-k mest relevante resultater (typisk 3-5), arbejd med mindre tekststykker frem for hele dokumenter og overvej at udtrække nøglesætninger fra længere passager.
| Udfordring | Indvirkning | Løsning |
|---|---|---|
| Daterelevans | Irrelevant kontekst forvirrer modellen | Brug semantisk søgning + rankers; test retrieval-kvalitet |
| Lost in Middle-bias | Modellen overser vigtig info i midten | Minimer inputstørrelse; placer kritisk info først/sidst |
| Tokeneffektivitet | Høj latenstid og omkostning | Hent færre resultater; brug mindre uddrag |
| Forældet information | Forældet kontekst i vidensbase | Implementér opdateringspolitikker; versionskontrol |
| Latenstid | Langsomme svar pga. søgning + inferens | Brug asynkrone operationer; caché hyppige forespørgsler |
Udrulning af grounding-systemer i produktionsmiljøer kræver omhyggelig opmærksomhed på governance, sikkerhed og driftsmæssige forhold. Kvalitetssikring af data er fundamentalt—den information, du grounder på, skal være nøjagtig, aktuel og relevant for dine brugsscenarier. Adgangskontrol bliver kritisk, når der groundes på proprietære eller følsomme dokumenter; du skal sikre, at LLM’en kun får adgang til information, der er passende for hver bruger baseret på deres tilladelser. Opdaterings- og driftshåndtering kræver etablering af politikker for, hvor ofte vidensbaser opdateres, og hvordan man håndterer modstridende information på tværs af kilder. Audit logging er essentielt for compliance og fejlfinding—du bør registrere, hvilke dokumenter der blev hentet, hvordan de blev rangeret, og hvilken kontekst der blev givet til modellen. Yderligere overvejelser inkluderer:
Feltet for LLM-grounding udvikler sig hurtigt ud over simpel tekstbaseret retrieval. Multimodal grounding er på vej, hvor systemer kan grounde svar i billeder, videoer og strukturerede data sammen med tekst—særligt vigtigt for domæner som juridisk dokumentanalyse, medicinsk billeddiagnostik og teknisk dokumentation. Automatiseret ræsonnement lægges oven på RAG, så agenter ikke kun kan hente information, men også syntetisere på tværs af flere kilder, drage logiske konklusioner og forklare deres ræsonnement. Beskyttelsesforanstaltninger (guardrails) integreres med grounding for at sikre, at selv med adgang til ekstern information opretholder modeller sikkerhedskrav og overholder politikker. Opdateringer direkte i modellen er et andet nyt område—i stedet for udelukkende at stole på ekstern retrieval, undersøger forskere måder at opdatere modelvægte direkte med ny information, hvilket potentielt kan reducere behovet for omfattende eksterne vidensbaser. Disse fremskridt antyder, at fremtidige grounding-systemer vil være mere intelligente, mere effektive og mere i stand til at håndtere komplekse, flertrins ræsonnementer, mens de opretholder faktuel nøjagtighed og sporbarhed.
Grounding supplerer en LLM med ekstern information ved inferenstid uden at ændre selve modellen, mens finjustering genoplærer modellen på nye data. Grounding er mere omkostningseffektivt, hurtigere at implementere og nemmere at opdatere med ny information. Finjustering er bedre, når du har brug for grundlæggende at ændre modellens adfærd eller har domænespecifikke mønstre, der skal læres.
Grounding reducerer hallucinationer ved at give LLM'en faktuel kontekst at trække på i stedet for kun at stole på dens træningsdata. Når relevant ekstern information inkluderes i prompten, flyttes modellens sandsynlighedsfordeling for tokens mod svar, der er forankret i denne kontekst, hvilket gør opdigtet information mindre sandsynlig. Forskning viser, at grounding kan reducere hallucinationsrater med 30-50%.
Retrieval Augmented Generation (RAG) er en grounding-teknik, der henter relevante dokumenter fra en ekstern videnskilde og giver dem som kontekst til LLM'en. RAG er vigtig, fordi det er skalerbart, omkostningseffektivt og gør det muligt at opdatere information uden at genoplære modellen. Det er blevet branchestandard for at bygge grounded AI-applikationer.
Implementer web search grounding, når din applikation har brug for adgang til aktuel information (nyheder, begivenheder, nylige data), når nøjagtighed og citater er kritiske, eller når din LLM's knowledge cutoff er en begrænsning. Brug dynamisk grounding til kun at søge, når det er nødvendigt, hvilket reducerer omkostningerne og latenstiden for forespørgsler, der ikke kræver frisk information.
Vigtige udfordringer inkluderer at sikre datarelevans (den hentede information skal faktisk besvare spørgsmålet), håndtering af datamængde (mere er ikke altid bedre), håndtering af 'lost in the middle'-bias hvor modeller overser information i lange kontekster, og optimering af tokeneffektivitet. Løsninger inkluderer at bruge semantisk søgning med rankers, hente færre men mere relevante resultater og placere kritisk information først eller sidst i konteksten.
Grounding er direkte relevant for AI-svarovervågning, fordi det gør det muligt for systemer at levere citater og kildehenvisninger. Platforme som AmICited sporer, hvordan AI-systemer refererer til kilder, hvilket kun er muligt, når grounding er korrekt implementeret. Dette hjælper med at sikre ansvarlig AI-udrulning og brandattribution på tværs af forskellige AI-platforme.
'Lost in the middle'-bias er et fænomen, hvor LLM'er præsterer dårligere, når relevant information er placeret i midten af lange kontekster sammenlignet med information i begyndelsen eller slutningen. Dette sker, fordi modeller har tendens til at 'skimme', når de behandler store mængder tekst. Løsninger inkluderer at minimere inputstørrelse, placere kritisk information på foretrukne steder og bruge mindre tekststykker.
Til produktion skal du fokusere på kvalitetssikring af data, implementere adgangskontrol for følsom information, etablere opdaterings- og fornyelsespolitikker, aktivere audit logging for compliance og skabe brugerfeedback-sløjfer til at identificere fejl. Overvåg tokenforbrug for at optimere omkostninger, implementer versionskontrol for vidensbaser og følg modeladfærd for at opdage drift.
AmICited sporer, hvordan GPT'er, Perplexity og Google AI Overviews citerer og refererer til dit indhold. Få realtidsindsigt i AI-svarovervågning og brandattribution.
Lær hvordan AI-hallucinationer truer brandsikkerheden på tværs af Google AI Overviews, ChatGPT og Perplexity. Opdag overvågningsstrategier, indholdsforstærkning...

Opdag hvordan Retrieval-Augmented Generation forvandler AI-citater og muliggør nøjagtig kildeangivelse og forankrede svar på tværs af ChatGPT, Perplexity og Goo...

Omfattende definition af Store Sprogmodeller (LLM'er): AI-systemer trænet på milliarder af parametre for at forstå og generere sprog. Lær hvordan LLM'er fungere...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.