
Prompt-biblioteker til manuel AI-synlighedstest
Lær hvordan du bygger og bruger prompt-biblioteker til manuel AI-synlighedstest. Gør-det-selv guide til at teste, hvordan AI-systemer henviser til dit brand på ...
10 min læsning

Lær hvordan du tester din brands tilstedeværelse i AI-motorer med prompttestning. Opdag manuelle og automatiserede metoder til at overvåge AI-synlighed på tværs af ChatGPT, Perplexity og Google AI.
Prompttestning er processen med systematisk at indsende forespørgsler til AI-motorer for at måle, om dit indhold optræder i deres svar. I modsætning til traditionel SEO-testning, der fokuserer på søgerangeringer og klikrater, evaluerer AI-synlighedstestning din tilstedeværelse på tværs af generative AI-platforme som ChatGPT, Perplexity og Google AI Overviews. Denne forskel er afgørende, da AI-motorer bruger andre rangeringsmekanismer, hentesystemer og citeringsmønstre end traditionelle søgemaskiner. Testning af din tilstedeværelse i AI-svar kræver en fundamentalt anderledes tilgang—en der tager højde for, hvordan store sprogmodeller henter, syntetiserer og tilskriver information fra hele nettet.
Manuel prompttestning er fortsat den mest tilgængelige indgang til forståelse af din AI-synlighed, selvom det kræver disciplin og dokumentation. Sådan fungerer testning på tværs af større AI-platforme:
| AI-motor | Testtrin | Fordele | Ulemper |
|---|---|---|---|
| ChatGPT | Indsend prompter, gennemgå svar, noter omtaler/citationer, dokumenter resultater | Direkte adgang, detaljerede svar, citationstracking | Tidskrævende, inkonsistente resultater, begrænset historisk data |
| Perplexity | Indtast forespørgsler, analyser kildeangivelse, følg citationens placering | Klar kildeangivelse, realtidsdata, brugervenlig | Manuel dokumentation påkrævet, begrænset kapacitet for forespørgsler |
| Google AI Overviews | Søg forespørgsler i Google, gennemgå AI-genererede resuméer, noter kildeinddragelse | Integreret med søgning, stort trafikpotentiale, naturlig brugeradfærd | Begrænset kontrol over forespørgselsvariationer, inkonsistent tilstedeværelse |
| Google AI Mode | Få adgang via Google Labs, test specifikke forespørgsler, følg fremhævede uddrag | Ny platform, direkte testadgang | Tidlig fase, begrænset tilgængelighed |
ChatGPT-testning og Perplexity-testning udgør fundamentet i de fleste manuelle teststrategier, da disse platforme repræsenterer de største brugerbaser og mest gennemsigtige citeringsmekanismer.
Selvom manuel testning giver værdifuld indsigt, bliver det hurtigt upraktisk i stor skala. Selv test af 50 prompter manuelt på fire AI-motorer kræver over 200 individuelle forespørgsler, der hver især kræver manuel dokumentation, skærmbilleder og resultat-analyse—en proces, der tager 10-15 timer per testrunde. Manuelle testbegrænsninger rækker ud over tidsforbruget: Menneskelige testere introducerer inkonsistens i dokumentationen, har svært ved at opretholde den nødvendige testfrekvens for at spore trends og kan ikke aggregere data på tværs af hundreder af prompter for at identificere mønstre. Skalerbarhedsproblemet bliver akut, når du skal teste brandede variationer, ikke-brandede variationer, long-tail-forespørgsler og konkurrencebenchmarking samtidig. Derudover giver manuel testning kun øjebliksbilleder; uden automatiserede systemer kan du ikke følge, hvordan din synlighed ændrer sig uge for uge eller identificere, hvilke indholdsopdateringer der faktisk har forbedret din AI-tilstedeværelse.
Automatiserede AI-synlighedsværktøjer eliminerer det manuelle arbejde ved løbende at indsende prompter til AI-motorer, indfange svar og sammenfatte resultater i dashboards. Disse platforme bruger API’er og automatiserede workflows til at teste hundreder eller tusinder af prompter efter den tidsplan, du definerer—dagligt, ugentligt eller månedligt—uden menneskelig indblanding. Automatiseret testning indsamler strukturerede data om omtaler, citationer, tildelingsnøjagtighed og sentiment på tværs af alle større AI-motorer samtidig. Realtidsovervågning gør det muligt straks at opdage synlighedsændringer, korrelere dem med indholdsopdateringer eller algoritmeændringer og reagere strategisk. Data-aggregationsmulighederne på disse platforme afslører mønstre, som manuel testning overser: hvilke emner genererer flest citationer, hvilke indholdsformater AI-motorer foretrækker, hvordan din share of voice sammenlignes med konkurrenters, og om dine citationer har korrekt tildeling og links. Denne systematiske tilgang forvandler AI-synlighed fra en lejlighedsvis revision til en kontinuerlig informationsstrøm, der informerer indholdsstrategi og konkurrencepositionering.
Gode prompttestnings-praksisser kræver gennemtænkt valg af prompter og balancerede testporteføljer. Overvej disse væsentlige elementer:
AI-synlighedsmetrikker giver et flerdimensionelt billede af din tilstedeværelse på tværs af generative AI-platforme. Citationstracking viser ikke blot, om du optræder, men hvor fremtrædende—om du er primær kilde, en blandt flere, eller blot nævnt i forbifarten. Share of voice sammenligner din citeringshyppighed mod konkurrenter inden for samme emneområde, hvilket indikerer konkurrenceposition og indholdsautoritet. Sentimentanalyse, som pioneret af platforme som Profound, vurderer om dine citationer præsenteres positivt, neutralt eller negativt i AI-svar—kritisk kontekst, som rå omtaletællinger kan overse. Tildelingsnøjagtighed er lige så vigtig: Giver AI-motoren korrekt kredit til dit indhold med et link, eller parafraseres det uden attribution? Forståelse af disse metrikker kræver kontekstuel analyse—en enkelt omtale i en højt trafikeret forespørgsel kan opveje ti omtaler i lavvolumen-forespørgsler. Konkurrencebenchmarking giver vigtigt perspektiv: Hvis du optræder i 40% af relevante prompter, men konkurrenter i 60%, har du identificeret et synlighedsgab, der er værd at adressere.
AI-synlighedsplatformmarkedet indeholder flere specialiserede værktøjer, hver med sine styrker. AmICited giver omfattende citationstracking på tværs af ChatGPT, Perplexity og Google AI Overviews med detaljeret attributanalyse og konkurrencebenchmarking. Conductor fokuserer på promptniveau-tracking og emneautoritet, så teams kan forstå, hvilke emner der genererer mest AI-synlighed. Profound vægter sentimentanalyse og kildeangivelsesnøjagtighed, afgørende for at forstå, hvordan AI-motorer præsenterer dit indhold. LLM Pulse tilbyder manuel testvejledning og dækning af nye platforme, værdifuldt for teams der bygger testprocesser fra bunden. Valget afhænger af dine prioriteter: Hvis omfattende automatisering og konkurrenceanalyse er vigtigst, udmærker AmICited sig; hvis emneautoritet driver din strategi, passer Conductors tilgang bedre; hvis det er afgørende at forstå, hvordan AI-motorer vinkler dit indhold, skiller Profounds sentimentfunktioner sig ud. De fleste avancerede teams bruger flere platforme for at få komplementære indsigter.
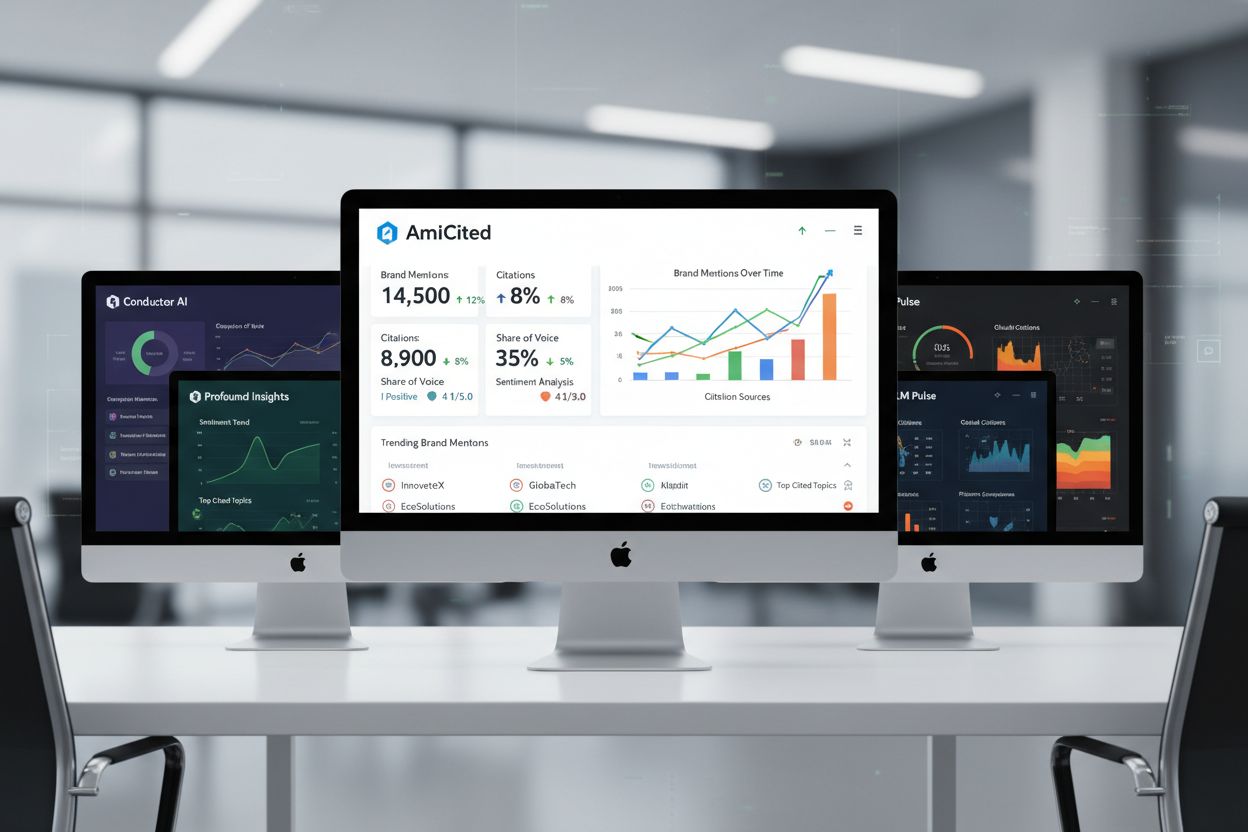
Organisationer underminerer ofte deres testindsats gennem undgåelige fejl. Overdreven brug af brandede prompter skaber et falsk synlighedsbillede—du kan rangere godt på “Firmanavn”-søgninger, mens du forbliver usynlig på de brancheemner, der faktisk driver opdagelse og trafik. Inkonsekvente testschedules giver upålidelige data; sporadisk test gør det umuligt at skelne reelle synlighedstrends fra normale udsving. At ignorere sentimentanalyse fører til fejltolkning af resultater—at optræde i et AI-svar, der vinkler dit indhold negativt eller fremhæver konkurrenter fordelagtigt, kan faktisk skade din position. Manglende side-niveau data forhindrer optimering: at vide du optræder på et emne er værdifuldt, men at vide hvilke specifikke sider optræder og hvordan de tilskrives, muliggør målrettede indholdsforbedringer. En anden kritisk fejl er kun at teste aktuelt indhold; test af historisk indhold afslører, om ældre sider stadig genererer AI-synlighed eller om de er blevet erstattet af nyere kilder. Endelig, hvis du ikke korrelerer testresultaterne med indholdsændringer, kan du ikke lære, hvilke opdateringer der faktisk forbedrer AI-synlighed, og forhindrer løbende optimering.
Prompttestningsresultater bør direkte informere din indholdsstrategi og AI-optimeringsprioriteter. Når testning viser, at konkurrenter dominerer et højtvolumen-emne, hvor du har minimal synlighed, bliver det emne en indholdsprioritet—enten via nyt indhold eller optimering af eksisterende sider. Testresultater identificerer, hvilke indholdsformater AI-motorer foretrækker: Hvis konkurrenters listeartikler optræder oftere end dine lange guides, kan formatoptimering forbedre synligheden. Emneautoritet fremgår af testdata—emner, hvor du optræder konsekvent på tværs af flere promptvariationer, indikerer etableret autoritet, mens emner, hvor du optræder sporadisk, antyder indholdsgab eller svag position. Brug testning til at validere indholdsstrategi, før du investerer tungt: Hvis du planlægger at målrette et nyt emne, test først den aktuelle synlighed for at forstå konkurrenceintensitet og realistisk synlighedspotentiale. Testning afslører også tildelingsmønstre: Hvis AI-motorer citerer dit indhold uden links, bør din indholdsstrategi vægte unikke data, original research og distinkte synspunkter, som AI-motorer føler sig forpligtede til at tilskrive. Integrer endelig testning i din indholdskalender—planlæg testcyklusser omkring større indholdslanceringer for at måle effekt og justere strategi baseret på reelle AI-synlighedsresultater frem for antagelser.
Manuel testning indebærer at sende prompter til AI-motorer individuelt og dokumentere resultaterne i hånden, hvilket er tidskrævende og svært at skalere. Automatiseret testning bruger platforme til løbende at sende hundreder af prompter på tværs af flere AI-motorer efter en fastlagt plan, fange strukturerede data og aggregere resultater i dashboards til trendanalyse og konkurrencebenchmarking.
Etabler en konsekvent testrytme på mindst ugentlig eller hver anden uge for at spore meningsfulde trends og korrelere synlighedsændringer med indholdsopdateringer eller algoritmeændringer. Hyppigere testning (dagligt) er gavnligt for højtprioriterede emner eller konkurrenceprægede markeder, mens mindre hyppig testning (månedligt) kan være tilstrækkelig for stabile, modne indholdsområder.
Følg 75/25-reglen: cirka 75% ikke-brandede prompter (brancheemner, problemstillinger, informationsforespørgsler) og 25% brandede prompter (dit firmanavn, produktnavne, brandede søgeord). Denne balance hjælper dig med at forstå både opdagelsessynlighed og brandspecifik tilstedeværelse uden at oppuste resultaterne med forespørgsler, du sandsynligvis allerede dominerer.
Du vil begynde at se indledende signaler inden for de første par testrunder, men meningsfulde mønstre opstår typisk efter 4-6 ugers konsekvent sporing. Denne tidsramme giver dig mulighed for at etablere et grundlag, tage højde for naturlige udsving i AI-svar og korrelere synlighedsændringer med specifikke indholdsopdateringer eller optimeringstiltag.
Ja, du kan udføre manuel testning gratis ved direkte adgang til ChatGPT, Perplexity, Google AI Overviews og Google AI Mode. Dog er gratis manuel testning begrænset i skala og konsistens. Automatiserede platforme som AmICited tilbyder gratis prøveperioder eller freemium-muligheder, så du kan teste metoden før du forpligter dig til betalte planer.
De vigtigste måleparametre er citationer (når AI-motorer linker til dit indhold), omtaler (når dit brand nævnes), share of voice (din synlighed sammenlignet med konkurrenter) og sentiment (om dine citationer præsenteres positivt). Tildelingsnøjagtighed—om AI-motorer korrekt krediterer dit indhold—er lige så vigtig for at forstå den reelle synlighedspåvirkning.
Effektive prompter genererer konsistente, handlingsorienterede data, der korrelerer med dine forretningsmål. Test om dine prompter afspejler reel brugeradfærd ved at sammenligne dem med søgeforespørgselsdata, kundeinterviews og salgssamtaler. Prompter, der genererer synlighedsændringer efter indholdsopdateringer, er særligt værdifulde til at validere din teststrategi.
Start med de største motorer (ChatGPT, Perplexity, Google AI Overviews), der repræsenterer de største brugerbaser og trafikudbytte. Efterhånden som dit program modnes, udvid til nye motorer som Gemini, Claude og andre, der er relevante for dit publikum. Valget afhænger af, hvor dine målgrupper faktisk opholder sig, og hvilke motorer der driver mest henvisningstrafik til dit site.
Test din brands tilstedeværelse i ChatGPT, Perplexity, Google AI Overviews og mere med AmICiteds omfattende AI-synlighedsovervågning.
Lær hvordan du bygger og bruger prompt-biblioteker til manuel AI-synlighedstest. Gør-det-selv guide til at teste, hvordan AI-systemer henviser til dit brand på ...

Lær, hvordan du udfører effektiv promptforskning for AI-synlighed. Opdag metoder til at forstå brugerforespørgsler i LLM'er og spore dit brand på tværs af ChatG...

Lær hvad prompt engineering er, hvordan det fungerer med AI-søgemaskiner som ChatGPT og Perplexity, og opdag essentielle teknikker til at optimere dine AI-søger...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.