Query Fanout
Lær hvordan Query Fanout fungerer i AI-søgesystemer. Opdag hvordan AI udvider enkelte forespørgsler til flere underforespørgsler for at forbedre svarnøjagtighed...
10 min læsning
Opdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT opdeler enkeltforespørgsler i flere søgninger. Lær om query fanout-mekanismer, konsekvenser for AI-synlighed og optimering af content-strategi.
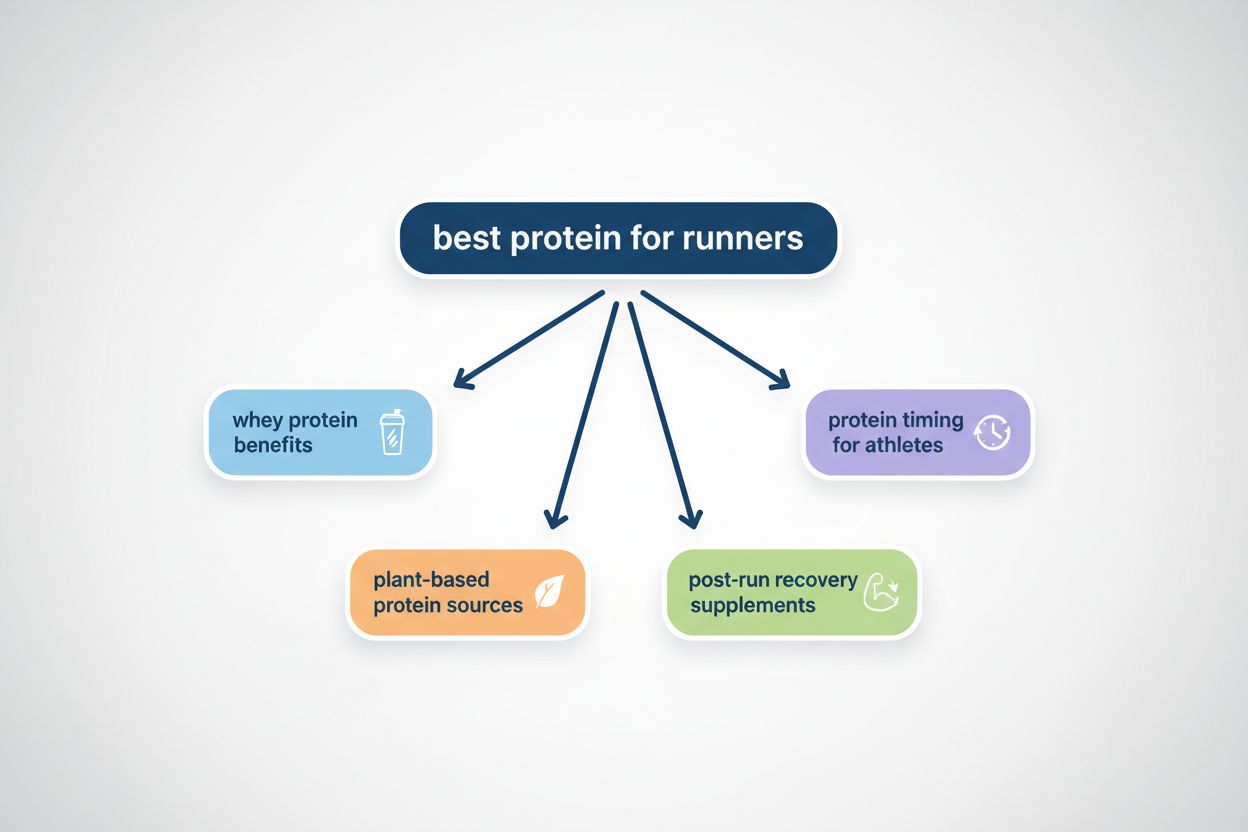
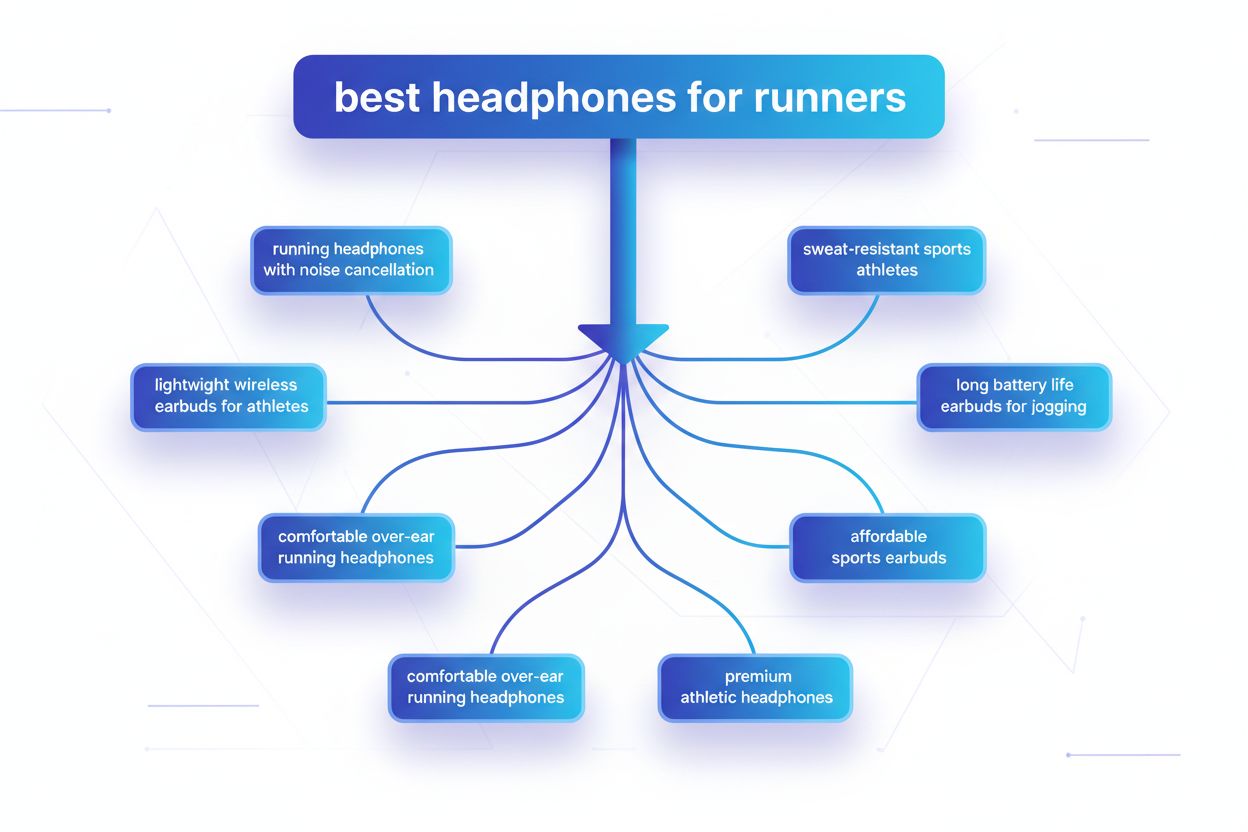
Query fanout er processen, hvor store sprogmodeller automatisk opdeler en enkelt brugerforespørgsel i flere underforespørgsler for at indsamle mere omfattende information fra forskellige kilder. I stedet for at udføre en enkelt søgning opdeler moderne AI-systemer brugerens hensigt i 5-15 relaterede forespørgsler, der fanger forskellige vinkler, fortolkninger og aspekter af den oprindelige anmodning. For eksempel, når en bruger søger “bedste hovedtelefoner til løbere” i Googles AI Mode, genererer systemet cirka 8 forskellige søgninger, herunder variationer som “løbehovedtelefoner med støjreduktion”, “lette trådløse ørepropper til atleter”, “svedresistente sportshovedtelefoner” og “ørepropper med lang batterilevetid til jogging”. Dette repræsenterer et fundamentalt opgør med traditionel søgning, hvor en enkelt forespørgselsstreng matches mod et indeks. Nøgleegenskaber ved query fanout inkluderer:
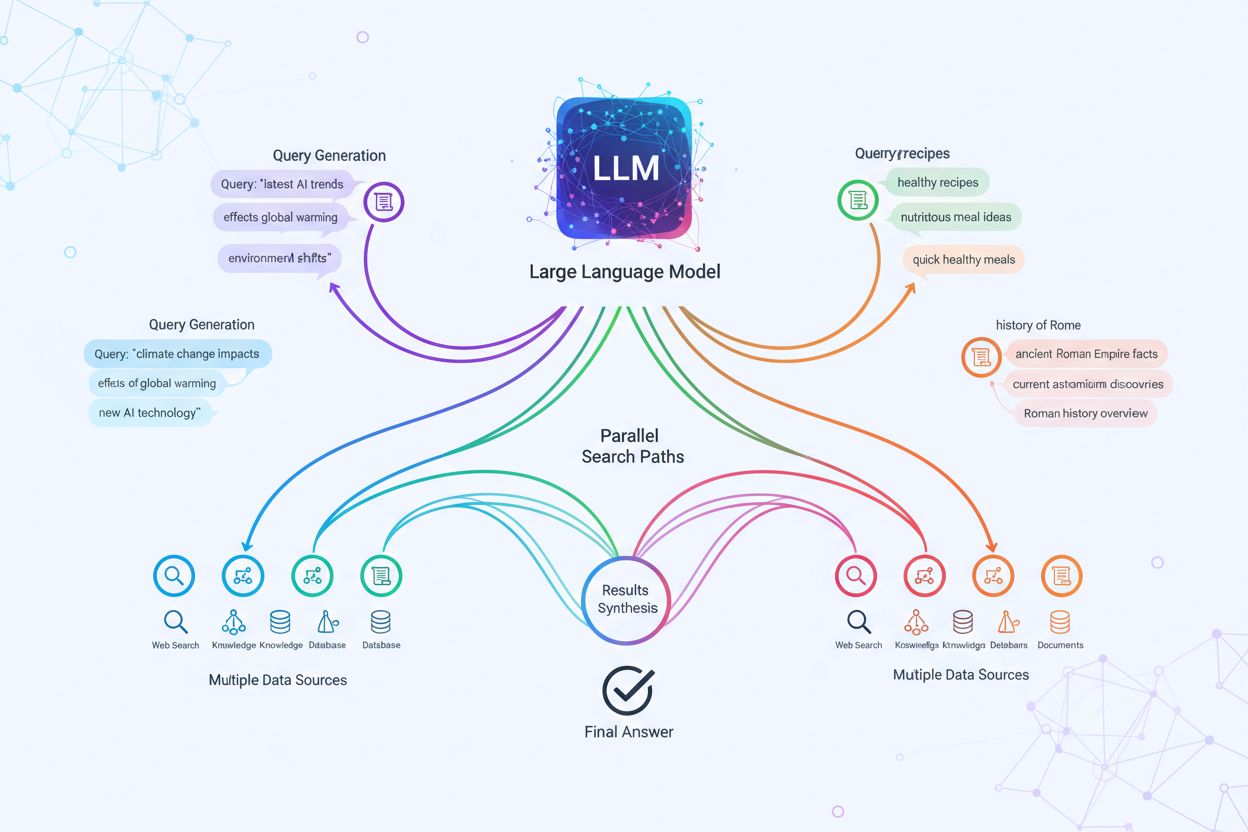
Den tekniske implementering af query fanout bygger på avancerede NLP-algoritmer, der analyserer forespørgselskompleksitet og genererer semantisk meningsfulde varianter. LLM’er fremstiller otte primære typer af forespørgselsvarianter: ækvivalente forespørgsler (omformulering med identisk betydning), opfølgningsforespørgsler (udforskning af relaterede emner), generaliseringsforespørgsler (udvidelse af omfanget), specificeringsforespørgsler (indsnævring af fokus), kanoniseringsforespørgsler (standardisering af terminologi), oversættelsesforespørgsler (konvertering mellem domæner), entailment-forespørgsler (udforskning af logiske implikationer) og afklaringsforespørgsler (afklaring af tvetydige begreber). Systemet anvender neurale sprogmodeller til at vurdere forespørgselskompleksitet—målt på faktorer som entitetsantal, relationsdensitet og semantisk tvetydighed—for at afgøre, hvor mange underforespørgsler der skal genereres. Når de er genereret, udføres disse forespørgsler parallelt på tværs af flere indhentningssystemer, herunder webcrawlere, viden-grafer (som Google’s Knowledge Graph), strukturerede databaser og vektorsimilaritetsindekser. Forskellige platforme implementerer denne arkitektur med varierende grad af gennemsigtighed og sofistikation:
| Platform | Mekanisme | Gennemsigtighed | Antal forespørgsler | Rangeringsmetode |
|---|---|---|---|---|
| Google AI Mode | Eksplicit fanout med synlige forespørgsler | Høj | 8-12 forespørgsler | Flertrinsrangering |
| Microsoft Copilot | Iterativ Bing Orchestrator | Medium | 5-8 forespørgsler | Relevansscoring |
| Perplexity | Hybridindhentning med flertrinsrangering | Høj | 6-10 forespørgsler | Citeringsbaseret |
| ChatGPT | Implicit forespørgselsgenerering | Lav | Ukendt | Intern vægtning |
Komplekse forespørgsler undergår avanceret opdeling, hvor systemet bryder dem ned i tilhørende entiteter, attributter og relationer, før varianter genereres. Når der behandles en forespørgsel som “Bluetooth-hovedtelefoner med komfortabelt over-ear-design og langtidsholdbart batteri egnet til løbere”, udfører systemet entitetscentreret forståelse ved at identificere nøgleentiteter (Bluetooth-hovedtelefoner, løbere) og udtrække kritiske attributter (komfortabel, over-ear, langtidsholdbart batteri). Opdelingsprocessen udnytter viden-grafer til at forstå, hvordan disse entiteter relaterer sig til hinanden og hvilke semantiske variationer, der findes—at “over-ear-hovedtelefoner” og “circumaurale hovedtelefoner” er ækvivalente, eller at “langtidsholdbart batteri” kan betyde 8+ timer, 24+ timer eller flerdages batterilevetid afhængigt af konteksten. Systemet identificerer relaterede begreber gennem semantiske lighedsforanstaltninger og forstår, at forespørgsler om “svedresistens” og “vandresistens” er beslægtede, men adskilte, og at “løbere” også kan være interesseret i “cyklister”, “fitnessudøvere” eller “udendørs atleter”. Denne opdeling muliggør generering af målrettede underforespørgsler, der indfanger forskellige facetter af brugerens hensigt i stedet for blot at omformulere den oprindelige anmodning.
Query fanout styrker fundamentalt indhentningskomponenten i Retrieval-Augmented Generation (RAG)-rammeværker ved at muliggøre rigere og mere mangfoldig evidensindsamling inden genereringsfasen. I traditionelle RAG-pipelines bliver en enkelt forespørgsel indlejret og matchet mod en vektordatabase, hvilket potentielt kan gå glip af relevante informationer, der bruger anden terminologi eller konceptuel indramning. Query fanout adresserer denne begrænsning ved at udføre flere indhentningsoperationer parallelt, hver optimeret til en specifik forespørgselsvariant, som tilsammen samler beviser fra forskellige vinkler og kilder. Denne parallelle indhentningsstrategi reducerer markant risikoen for hallucinationer ved at forankre LLM-svar i flere uafhængige kilder—når systemet henter information om “over-ear-hovedtelefoner”, “circumaurale designs” og “full-size hovedtelefoner” separat, kan det krydstjekke og validere påstande på tværs af disse forskellige resultater. Arkitekturen inkorporerer semantisk chunking og passagebaseret indhentning, hvor dokumenter opdeles i meningsfulde semantiske enheder i stedet for faste længder, hvilket gør det muligt at hente de mest relevante passager uanset dokumentstruktur. Ved at kombinere beviser fra flere underforespørgsler leverer RAG-systemer svar, der er mere omfattende, bedre dokumenterede og mindre tilbøjelige til de skråsikre, men ukorrekte outputs, som én-forespørgsels-indhentning ofte giver.
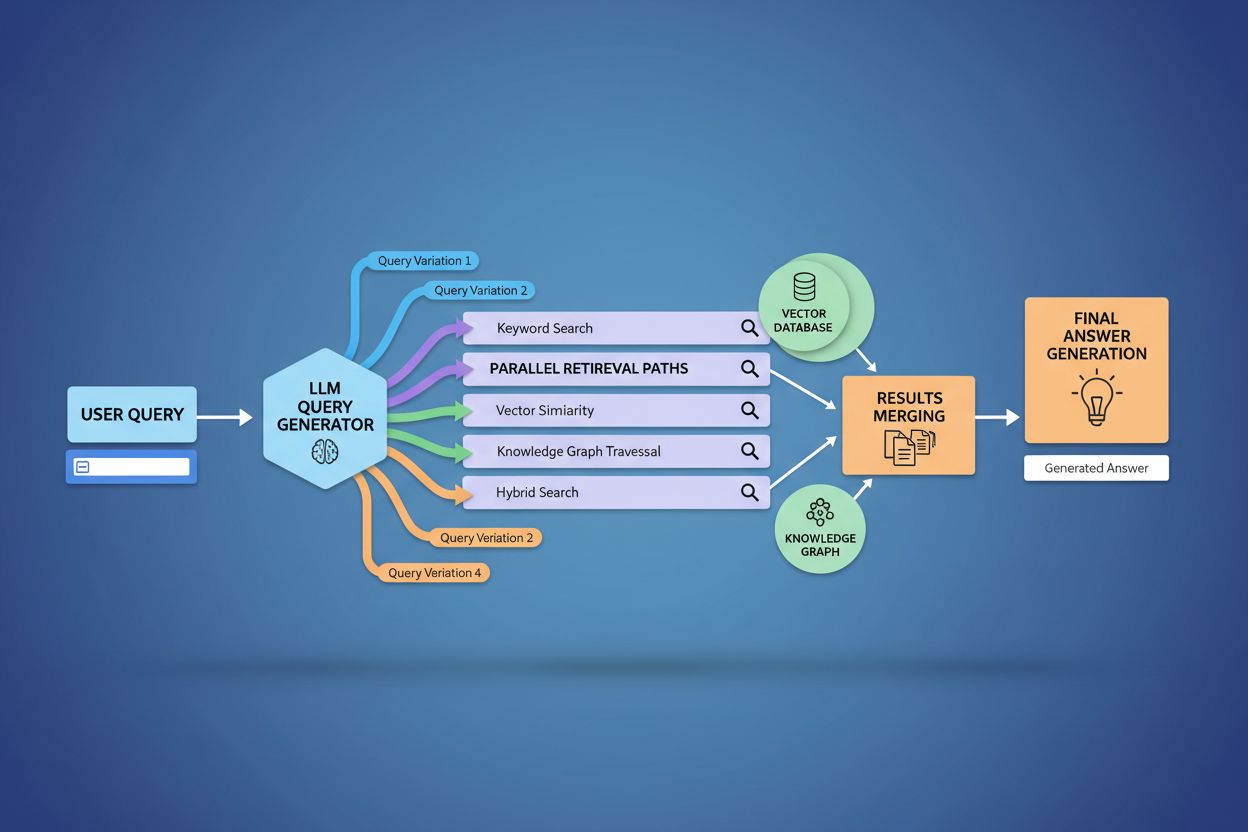
Brugerkontekst og personaliseringssignaler former dynamisk, hvordan query fanout udvider individuelle anmodninger, hvilket skaber personlige indhentningsveje, der kan afvige betydeligt fra bruger til bruger. Systemet inkorporerer flere personaliseringsdimensioner, herunder brugerattributter (geografisk placering, demografisk profil, professionel rolle), søgehistorik (tidligere forespørgsler og klik), tidsmæssige signaler (tid på dagen, sæson, aktuelle begivenheder) og opgavekontekst (om brugeren researcher, handler eller lærer). For eksempel udvides en forespørgsel om “bedste hovedtelefoner til løbere” forskelligt for en 22-årig ultramarathonløber i Kenya sammenlignet med en 45-årig motionsløber i Minnesota—den første brugers udvidelse vil måske fremhæve holdbarhed og varmeresistens, mens den andens fokuserer på komfort og tilgængelighed. Dog introducerer denne personalisering “to-punkts transformation”-problemet, hvor systemet behandler nuværende forespørgsler som variationer af historiske mønstre, hvilket potentielt begrænser udforskning og forstærker eksisterende præferencer. Personalisering kan utilsigtet skabe filterbobler, hvor forespørgselsudvidelse systematisk favoriserer kilder og perspektiver, der stemmer overens med brugerens historik, hvilket begrænser eksponering for alternative synspunkter eller ny information. At forstå disse personaliseringsmekanismer er afgørende for indholdsskabere, da det samme indhold måske eller måske ikke hentes afhængigt af brugerens profil og historik.
Store AI-platforme implementerer query fanout med markant forskellige arkitekturer, gennemsigtighedsniveauer og strategiske tilgange, der afspejler deres bagvedliggende infrastruktur og designfilosofi. Googles AI Mode bruger eksplicit, synlig query fanout, hvor brugere kan se de 8-12 genererede underforespørgsler vist sammen med resultaterne, og affyrer hundreder af individuelle søgninger mod Googles indeks for at samle omfattende beviser. Microsoft Copilot bruger en iterativ tilgang drevet af Bing Orchestrator, der genererer 5-8 forespørgsler sekventielt og forfiner sættet baseret på mellemliggende resultater før den endelige indhentningsfase. Perplexity implementerer en hybridindhentningsstrategi med flertrinsrangering, genererer 6-10 forespørgsler og udfører dem både mod webkilder og sin egen indeks, hvorefter avancerede rangeringsalgoritmer bringer de mest relevante passager frem. ChatGPT’s tilgang forbliver for det meste uklar for brugeren, idet forespørgselsgenereringen sker implicit i modellens interne processering, hvilket gør det svært at vide præcist, hvor mange forespørgsler der genereres, eller hvordan de udføres. Disse arkitektoniske forskelle har betydelige konsekvenser for gennemsigtighed, reproducerbarhed og mulighederne for indholdsskabere for at optimere til hver platform:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Forespørgsels-synlighed | Fuldt synlig for brugeren | Delvist synlig | Synlig i citater | Skjult |
| Eksekveringsmodel | Parallel batch | Iterativ sekventiel | Parallel med rangering | Intern/implicit |
| Kildediversitet | Kun Google-indeks | Bing + proprietær | Web + proprietært indeks | Træningsdata + plugins |
| Citationsgennemsigtighed | Høj | Medium | Meget høj | Lav |
| Tilpasningsmuligheder | Begrænset | Medium | Høj | Medium |
Query fanout introducerer flere tekniske og semantiske udfordringer, der kan få systemet til at afvige fra brugerens faktiske hensigt og hente teknisk relateret, men i sidste ende ikke brugbar information. Semantisk drift opstår gennem generativ udvidelse, når LLM’en skaber forespørgselsvarianter, der, selvom de er semantisk beslægtede med originalen, gradvist forskyder betydningen—en forespørgsel om “bedste hovedtelefoner til løbere” kan udvides til “atletiske hovedtelefoner”, derefter “sportsudstyr”, derefter “fitnesstilbehør” og dermed bevæge sig væk fra den oprindelige hensigt. Systemet skal skelne mellem latent hensigt (hvad brugeren måske vil, hvis de vidste mere) og eksplicit hensigt (hvad de faktisk spurgte om), og aggressiv forespørgselsudvidelse kan sammenblande disse, så der hentes information om produkter, brugeren aldrig havde i tankerne. Iterativ udvidelsesdivergens opstår, når hver genereret forespørgsel afføder yderligere underforespørgsler, hvilket skaber et forgrenet træ af stadig mere tangentiale søgninger, der tilsammen henter information langt fra den oprindelige anmodning. Filterbobler og personaliseringsbias betyder, at to brugere, der stiller identiske spørgsmål, får systematisk forskellige forespørgselsudvidelser baseret på deres profiler, hvilket kan skabe ekkokamre, hvor hver brugers udvidelse forstærker deres eksisterende præferencer. Virkelige scenarier demonstrerer disse faldgruber: en bruger, der søger “billige hovedtelefoner”, kan få sin forespørgsel udvidet til at omfatte luksusmærker på baggrund af sin browsehistorik, eller en forespørgsel om “hovedtelefoner til hørehæmmede” kan udvides til generelle tilgængelighedsprodukter, hvilket udvander den oprindelige hensigts specificitet.
Fremkomsten af query fanout flytter fundamentalt content-strategi fra keyword-ranking optimering til citeringsbaseret synlighed, hvilket kræver, at indholdsskabere gentænker, hvordan de strukturerer og præsenterer information. Traditionel SEO fokuserede på at rangere for specifikke søgeord; AI-drevet søgning prioriterer at blive citeret som autoritativ kilde på tværs af flere forespørgselsvarianter og kontekster. Indholdsskabere bør bruge atomiske, entitetsrige content-strategier, hvor information struktureres omkring specifikke entiteter (produkter, begreber, personer) med rig semantisk markup, der gør det muligt for AI-systemer at udtrække og citere relevante passager. Emneklyngedannelse og tematisk autoritet bliver stadig vigtigere—i stedet for at skabe isolerede artikler om enkeltord etablerer succesrigt indhold omfattende dækning af emneområder, hvilket øger chancen for at blive hentet på tværs af de mange forespørgselsvarianter, fanout genererer. Schema markup og implementering af strukturerede data gør det muligt for AI-systemer at forstå content-strukturen og udtrække relevant information mere effektivt, hvilket øger sandsynligheden for citation. Succeskriterier skifter fra sporing af keyword rankings til overvågning af citeringsfrekvens via værktøjer som AmICited.com, der sporer, hvor ofte brands og indhold optræder i AI-genererede svar. Konkrete best practices inkluderer: at skabe omfattende, veldokumenteret indhold, der dækker flere vinkler af et emne; implementere rig schema markup (Organization-, Product-, Article-schemaer); opbygge tematisk autoritet gennem sammenhængende indhold; og løbende auditere, hvordan dit indhold optræder i AI-svar på tværs af forskellige platforme og brugersegmenter.
Query fanout repræsenterer det mest markante arkitektoniske skifte i søgning siden mobile-first-indeksering og omstrukturerer fundamentalt, hvordan information opdages og præsenteres for brugeren. Udviklingen mod semantisk infrastruktur betyder, at søgesystemer i stigende grad vil operere på betydning snarere end nøgleord, hvor query fanout bliver standardmekanismen for informationsindhentning frem for et valgfrit supplement. Citeringsmålinger bliver lige så vigtige som backlinks i vurderingen af indholdets synlighed og autoritet—et stykke indhold, der citeres på tværs af 50 AI-svar, vejer tungere end indhold, der ligger nr. 1 på et enkelt søgeord. Dette skift skaber både udfordringer og muligheder: traditionelle SEO-værktøjer, der tracker keyword rankings, bliver mindre relevante, og nye målerammer med fokus på citeringsfrekvens, kildediversitet og optræden på tværs af forespørgselsvarianter bliver nødvendige. Men udviklingen skaber også muligheder for brands for at optimere specifikt til AI-søgning ved at opbygge autoritativt, velstruktureret indhold, der fungerer som pålidelig kilde på tværs af flere forespørgselstolkninger. Fremtiden indebærer sandsynligvis øget gennemsigtighed omkring query fanout-mekanismer, hvor platforme konkurrerer på, hvor tydeligt de viser brugeren begrundelsen for deres multiforeshørgselstilgang, og hvor indholdsskabere udvikler specialiserede strategier for at maksimere synlighed på tværs af de forskellige indhentningsveje, som fanout skaber.
Query fanout er den automatiserede proces, hvor AI-systemer opdeler en enkelt brugerforespørgsel i flere underforespørgsler og udfører dem parallelt, mens query expansion traditionelt henviser til at tilføje relaterede termer til en enkelt forespørgsel. Query fanout er mere sofistikeret og genererer semantisk forskellige varianter, der fanger forskellige vinkler og fortolkninger af den oprindelige hensigt.
Query fanout har stor indflydelse på synligheden, fordi dit indhold skal kunne findes på tværs af flere forespørgselsvarianter, ikke kun den præcise brugerforespørgsel. Indhold, der dækker forskellige vinkler, bruger varieret terminologi og er godt struktureret med schema markup, har større sandsynlighed for at blive hentet og citeret på tværs af de forskellige underforespørgsler, der genereres af fanout.
Alle større AI-søgeplatforme bruger query fanout-mekanismer: Google AI Mode bruger eksplicit, synlig fanout (8-12 forespørgsler); Microsoft Copilot bruger iterativ fanout via Bing Orchestrator; Perplexity implementerer hybridindhentning med multi-stage ranking; og ChatGPT bruger implicit query-generering. Hver platform implementerer det forskelligt, men alle opdeler komplekse forespørgsler i flere søgninger.
Ja. Optimer ved at skabe atomisk, entitetsrigt indhold struktureret omkring specifikke begreber; implementere omfattende schema markup; opbygge tematisk autoritet gennem sammenhængende indhold; bruge klar, varieret terminologi; og dække flere vinkler af et emne. Værktøjer som AmICited.com hjælper dig med at overvåge, hvordan dit indhold vises ved forskellige forespørgselsopdelinger.
Query fanout øger latensen, fordi flere forespørgsler udføres parallelt, men moderne systemer afbøder dette gennem parallel behandling. Hvor en enkelt forespørgsel kan tage 200 ms, tilføjer udførelsen af 8 forespørgsler parallelt typisk kun 300-500 ms samlet latenstid på grund af samtidig udførsel. Afvejningen er det værd for forbedret svartkvalitet.
Query fanout styrker Retrieval-Augmented Generation (RAG) ved at muliggøre rigere evidensindsamling. I stedet for at hente dokumenter til en enkelt forespørgsel henter fanout beviser for flere forespørgselsvarianter parallelt, hvilket giver LLM'en en mere mangfoldig, omfattende kontekst til at generere præcise svar og reducere risikoen for hallucinationer.
Personalisering former, hvordan forespørgsler opdeles baseret på brugerens attributter (placering, historie, demografi), tidsmæssige signaler og opgavens kontekst. Den samme forespørgsel udvides forskelligt for forskellige brugere, hvilket skaber personlige indhentningsveje. Dette kan øge relevansen, men skaber også filterbobler, hvor brugere ser systematisk forskellige resultater baseret på deres profiler.
Query fanout repræsenterer det største skifte i søgning siden mobile-first-indeksering. Traditionelle keyword ranking-målinger bliver mindre relevante, da den samme forespørgsel udvides forskelligt for forskellige brugere. SEO-professionelle skal flytte fokus fra keyword rankings til citeringsbaseret synlighed, content-struktur og entitetsoptimering for at få succes i AI-drevet søgning.
Forstå, hvordan dit brand vises på tværs af AI-søgeplatforme, når forespørgsler udvides og opdeles. Spor citater og omtaler i AI-genererede svar.
Lær hvordan Query Fanout fungerer i AI-søgesystemer. Opdag hvordan AI udvider enkelte forespørgsler til flere underforespørgsler for at forbedre svarnøjagtighed...

Lær de essentielle første skridt til at optimere dit indhold til AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews. Opdag hvordan du strukturerer i...
Lær hvordan du opretter TOFU-indhold optimeret til AI-søgning. Mestre strategier for bevidsthedsstadiet til ChatGPT, Perplexity, Google AI Overviews og Claude....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.