
AI-synlighedsordbog: 100 udtryk enhver marketingmedarbejder bør kende
Omfattende ordbog med 100+ essentielle AI-synligheds- og GEO-udtryk enhver marketingmedarbejder bør kende. Lær om citationstracking, brandovervågning og ordfork...
9 min læsning

Den grad, hvormed AI-platforme offentliggør, hvordan de udvælger og rangerer kilder, når de genererer svar. AI-rangeringsgennemsigtighed henviser til synligheden af de algoritmer og kriterier, der afgør, hvilke kilder der vises i AI-genererede svar, hvilket adskiller sig fra traditionelle søgemaskiners rangering. Denne gennemsigtighed er afgørende for indholdsskabere, udgivere og brugere, der har behov for at forstå, hvordan information udvælges og prioriteres. Uden gennemsigtighed kan brugere ikke verificere kilders troværdighed eller forstå potentielle bias i AI-genereret indhold.
Den grad, hvormed AI-platforme offentliggør, hvordan de udvælger og rangerer kilder, når de genererer svar. AI-rangeringsgennemsigtighed henviser til synligheden af de algoritmer og kriterier, der afgør, hvilke kilder der vises i AI-genererede svar, hvilket adskiller sig fra traditionelle søgemaskiners rangering. Denne gennemsigtighed er afgørende for indholdsskabere, udgivere og brugere, der har behov for at forstå, hvordan information udvælges og prioriteres. Uden gennemsigtighed kan brugere ikke verificere kilders troværdighed eller forstå potentielle bias i AI-genereret indhold.
AI-rangeringsgennemsigtighed henviser til offentliggørelsen af, hvordan kunstig intelligens udvælger, prioriterer og præsenterer kilder, når der genereres svar på brugerforespørgsler. I modsætning til traditionelle søgemaskiner, som viser rangerede lister af links, integrerer moderne AI-platforme som Perplexity, ChatGPT og Googles AI Overblik kildeudvælgelsen i selve svarprocessen, hvilket gør rangeringskriterierne stort set usynlige for brugerne. Denne uigennemsigtighed skaber et kritisk gab mellem det, brugeren ser (et syntetiseret svar), og hvordan svaret blev konstrueret (hvilke kilder der blev valgt, vægtet og citeret). For indholdsskabere og udgivere betyder denne mangel på gennemsigtighed, at deres synlighed afhænger af algoritmer, de ikke kan forstå eller påvirke gennem traditionelle optimeringsmetoder. Skellet til traditionel søgemaskinegennemsigtighed er markant: Hvor Google offentliggør generelle rangeringsfaktorer og kvalitetsretningslinjer, behandler AI-platforme ofte deres kildeudvælgelsesmekanismer som forretningshemmeligheder. Centrale interessenter, der påvirkes, inkluderer indholdsskabere, der søger synlighed, udgivere med fokus på trafik, brandmanagers, der overvåger omdømme, forskere, der skal verificere informationskilder, og brugere, der har behov for at forstå troværdigheden af AI-genererede svar. At forstå AI-rangeringsgennemsigtighed er blevet essentielt for alle, der producerer, distribuerer eller stoler på digitalt indhold i en stadig mere AI-formidlet informationsverden.
AI-platforme benytter Retrieval-Augmented Generation (RAG)-systemer, som kombinerer sprogmodeller med realtids informationssøgning for at forankre svar i faktiske kilder i stedet for udelukkende at stole på træningsdata. RAG-processen omfatter tre hovedstadier: retrieval (at finde relevante dokumenter), ranking (at rangere kilder efter relevans) og generation (at syntetisere information med kildeangivelser). Forskellige platforme anvender forskellige rangeringsmetoder—Perplexity prioriterer kildeautoritet og aktualitet, Googles AI Overblik lægger vægt på emnerelevans og E-E-A-T-signaler (Erfaring, Ekspertise, Autoritet, Troværdighed), mens ChatGPT Search balancerer kildekvalitet med svarets fyldestgørelse. Faktorer, der påvirker kildeudvælgelsen, inkluderer typisk domæneautoritet (etableret ry og backlink-profil), informationsaktualitet (oplysningernes friskhed), emnerelevans (semantisk sammenhæng med forespørgslen), engagementssignaler (brugerinteraktionsmålinger) og citeringsfrekvens (hvor ofte kilder refereres af andre autoritative sider). AI-systemer vægter disse signaler forskelligt afhængigt af brugerens hensigt—faktuelle forespørgsler prioriterer måske autoritet og aktualitet, mens holdningsbaserede forespørgsler kan fremhæve mangfoldige perspektiver og engagement. Rangeringsalgoritmerne forbliver for det meste uoffentliggjorte, selvom platformenes dokumentation giver begrænset indsigt i vægtningen.
| Platform | Citeringsgennemsigtighed | Kildeudvælgelseskriterier | Offentliggørelse af rangeringsalgoritme | Brugerkontrol |
|---|---|---|---|---|
| Perplexity | Høj – kildehenvisninger i teksten | Autoritet, aktualitet, relevans, emneekspertise | Moderat – vis dokumentation | Medium – kildefiltrering |
| Google AI Overblik | Middel – citerede kilder oplyst | E-E-A-T, emnerelevans, friskhed, engagement | Lav – minimal indsigt | Lav – begrænset tilpasning |
| ChatGPT Search | Middel – kilder oplyst separat | Kvalitet, relevans, fyldestgørelse, autoritet | Lav – proprietær algoritme | Lav – ingen tilpasning |
| Brave Leo | Middel – kildeangivelse | Privatlivsvenlige kilder, relevans, autoritet | Lav – privatlivsfokuseret uigennemsigtighed | Medium – kildevalg |
| Consensus | Meget høj – akademisk fokus med målinger | Citeringsantal, peer review-status, aktualitet, emnerelevans | Høj – akademiske standarder transparente | Høj – filtrering efter studietype og kvalitet |
AI-branchen mangler standardiserede praksisser for offentliggørelse af, hvordan rangeringssystemerne virker, hvilket skaber et fragmenteret landskab, hvor hver platform selv bestemmer graden af gennemsigtighed. OpenAI’s ChatGPT Search forklarer kun minimalt om kildeudvælgelse, Metas AI-systemer tilbyder begrænset dokumentation, og Googles AI Overblik informerer mere end konkurrenterne, men undlader stadig væsentlige algoritmiske detaljer. Platformene modstår fuld offentliggørelse med henvisning til konkurrencefordel, forretningshemmeligheder og kompleksiteten i at forklare maskinlæring for alment publikum—men denne uigennemsigtighed forhindrer ekstern revision og ansvarlighed. “Source laundering”-problemet opstår, når AI-systemer citerer kilder, der selv aggregerer eller omskriver originalt indhold, hvilket skjuler informationens egentlige ophav og potentielt forstærker misinformation gennem flere lag af syntese. Reguleringstrykket stiger: EU’s AI-forordning kræver, at højrisiko AI-systemer fører dokumentation over træningsdata og beslutningsprocesser, mens NTIA AI Accountability Policy opfordrer virksomheder til at offentliggøre AI-systemers kapabiliteter, begrænsninger og passende anvendelser. Konkrete eksempler på manglende offentliggørelse inkluderer Perplexitys indledende problemer med korrekt kildeangivelse (senere forbedret), Googles vage forklaring på udvælgelse i AI Overblik, samt ChatGPT’s begrænsede gennemsigtighed om hvorfor visse kilder vælges frem for andre. Fraværet af standardiserede målinger for gennemsigtighed gør det svært for brugere og tilsyn at sammenligne platforme objektivt.
Uigennemsigtigheden i AI-rangeringssystemerne skaber betydelige synlighedsudfordringer for indholdsskabere, da traditionelle SEO-strategier ikke direkte kan overføres til AI-platforme. Udgivere har svært ved at forstå, hvorfor deres indhold optræder i nogle AI-svar, men ikke andre, hvilket gør det umuligt at udvikle målrettede strategier for at øge synligheden i AI-genererede svar. Citeringsbias opstår, når AI-systemer uforholdsmæssigt favoriserer visse kilder—etablerede nyhedsmedier, akademiske institutioner eller store websites—mens mindre udgivere, uafhængige skribenter og nicheeksperter, der kan have værdifuld viden, overses. Mindre udgivere er særligt udfordrede, fordi AI-systemer ofte vægter domæneautoritet tungt, og nyere eller specialiserede hjemmesider har ikke samme backlink-profil eller brandgenkendelse som etablerede medier. Forskning fra Search Engine Land viser, at AI Overblik har reduceret klikrater til traditionelle søgeresultater med 18-64% afhængigt af forespørgselstype, og trafikken koncentreres blandt de få kilder, der citeres i AI-svarene. Skellet mellem SEO (Search Engine Optimization) og GEO (Generative Engine Optimization) bliver kritisk—mens SEO handler om at rangere i traditionel søgning, kræver GEO forståelse for og optimering mod AI-platformes udvælgelseskriterier, som stadig er uigennemsigtige. Indholdsskabere har brug for værktøjer som AmICited.com til at overvåge, hvor deres indhold optræder i AI-svar, spore citeringshyppighed og forstå deres synlighed på tværs af platforme.
AI-branchen har udviklet flere rammer for at dokumentere og offentliggøre systemadfærd, men implementeringen er stadig ujævn på tværs af platforme. Modelkort giver standardiseret dokumentation af maskinlæringsmodellens ydeevne, tiltænkte brug, begrænsninger og bias-analyse—svarende til næringsdeklarationer for AI-systemer. Datasheets for Datasets dokumenterer sammensætning, indsamlingsmetodik og potentielle skævheder i træningsdata, baseret på princippet om, at AI-systemer kun er så gode som deres data. Systemkort tager et bredere perspektiv og dokumenterer hele systemets adfærd, herunder komponentinteraktioner, potentielle fejlscenarier og performance på tværs af brugergrupper. NTIA AI Accountability Policy anbefaler, at virksomheder opretholder detaljeret dokumentation af AI-systemets udvikling, test og implementering, især for højrisiko-applikationer med samfundsmæssig betydning. EU’s AI-forordning kræver, at højrisiko AI-systemer opretholder teknisk dokumentation, træningsdataregistrering og præstationslogfiler, med krav om gennemsigtighedsrapporter og brugeroplysning. Bedste praksis i branchen omfatter i stigende grad:
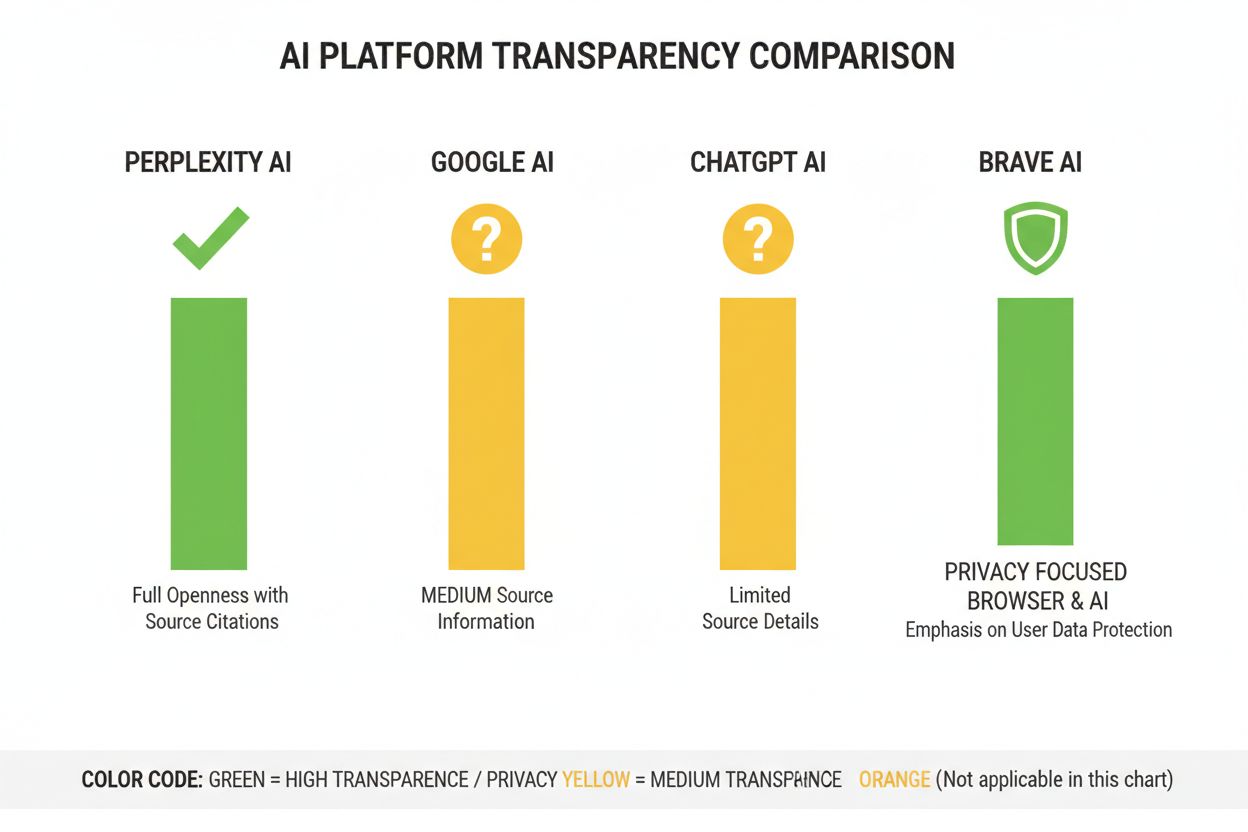
Perplexity har positioneret sig som den mest citeringsgennemsigtige AI-platform, med kildehenvisninger integreret i svarene, så brugerne kan se præcis, hvilke kilder der ligger til grund for hvert udsagn. Platformen dokumenterer sin rangeringsmetode relativt klart, med vægt på kildeautoritet, emneekspertise og aktualitet, selvom den præcise vægtning forbliver proprietær. Googles AI Overblik tilbyder moderat gennemsigtighed ved at liste citerede kilder efter svaret, men forklarer kun i begrænset omfang, hvorfor enkelte kilder er valgt frem for andre, eller hvordan rangeringsalgoritmen vægter forskellige signaler. Googles dokumentation fremhæver E-E-A-T-principper, men oplyser ikke fuldt ud, hvordan disse måles og vægtes i AI-rangeringen. OpenAI’s ChatGPT Search repræsenterer et kompromis, hvor kilder vises separat fra svaret og brugeren kan klikke til originalindholdet, men med minimal forklaring af kildeudvælgelse eller rangeringsmetode. Brave Leo sætter privatliv i højsædet og oplyser, at den benytter privatlivsvenlige kilder og ikke sporer brugerforespørgsler, dog på bekostning af mindre detaljeret forklaring af rangeringsmekanismer. Consensus adskiller sig ved udelukkende at fokusere på akademisk forskning og tilbyder høj gennemsigtighed gennem citeringsmålinger, peer review-status og kvalitetsindikatorer, hvilket gør den mest algoritmetransparente platform til forskningssøgninger. Brugerkontrol varierer betydeligt: Perplexity tillader kildefiltrering, Consensus giver filtrering efter studietype og kvalitet, mens Google og ChatGPT kun giver minimal mulighed for tilpasning. Variationerne i gennemsigtighed afspejler forskellige forretningsmodeller og målgrupper, hvor akademiske platforme prioriterer åbenhed, mens forbrugerrettede platforme balancerer gennemsigtighed med forretningshemmeligheder.
Troværdighed og tillid afhænger grundlæggende af, at brugerne forstår, hvordan information når frem til dem—når AI-systemer skjuler deres kilder eller rangeringslogik, kan brugerne ikke selv verificere udsagn eller vurdere kilders pålidelighed. Gennemsigtighed muliggør verificering og faktatjek, så forskere, journalister og oplyste brugere kan spore påstande tilbage til originale kilder og vurdere deres nøjagtighed og kontekst. Fordelene ved forebyggelse af misinformation og bias er betydelige: Når rangeringsalgoritmer er synlige, kan forskere identificere systematiske skævheder (f.eks. politiske eller kommercielle favoriseringer), og platforme kan holdes ansvarlige for at forstærke falsk information. Algoritmisk ansvarlighed er en grundlæggende brugerrettighed i demokratiske samfund—folk har krav på at vide, hvordan systemer, der former deres informationsmiljø, træffer beslutninger, især når disse systemer påvirker offentlig mening, købsbeslutninger og adgang til viden. For forskning og akademisk arbejde er gennemsigtighed afgørende, fordi forskere skal kunne forstå kildeudvælgelsen for at kontekstualisere AI-genererede resuméer og undgå utilsigtet reliance på skæve eller ufuldstændige kildesæt. Forretningsmæssigt for indholdsskabere er konsekvenserne store: Uden viden om rangeringsfaktorer kan udgivere ikke optimere deres strategi, mindre aktører kan ikke konkurrere retfærdigt, og hele økosystemet bliver mindre meritokratisk. Gennemsigtighed beskytter også brugere mod manipulation—hvis rangeringskriterier er skjult, kan ondsindede aktører udnytte ukendte svagheder til at fremme vildledende indhold, mens gennemsigtige systemer kan revideres og forbedres.
Regulatoriske tendenser bevæger sig mod obligatorisk gennemsigtighed: EU’s AI-forordnings ikrafttræden i 2025-2026 vil kræve detaljeret dokumentation og offentliggørelse for højrisiko AI-systemer, mens lignende regler er på vej i Storbritannien, Californien og andre steder. Branchen bevæger sig mod standardisering af gennemsigtighedspraksis, hvor organisationer som Partnership on AI og akademiske institutioner udvikler fælles rammer for dokumentation og offentliggørelse af AI-adfærd. Brugerkravet om gennemsigtighed vokser, i takt med at bevidstheden om AI’s rolle i informationsdistribution stiger—undersøgelser viser, at over 70% af brugerne ønsker at forstå, hvordan AI-systemer udvælger kilder og rangerer information. Teknologiske fremskridt inden for forklarlig AI (XAI) gør det mere og mere muligt at give detaljerede forklaringer på rangeringsbeslutninger uden at afsløre hele den proprietære algoritme, for eksempel via LIME (Local Interpretable Model-agnostic Explanations) og SHAP (SHapley Additive exPlanations). Overvågningsværktøjer som AmICited.com bliver stadig vigtigere, efterhånden som platformene indfører gennemsigtighedstiltag, så indholdsskabere og udgivere kan spore deres synlighed på tværs af AI-systemer og forstå, hvordan rangeringsændringer påvirker deres rækkevidde. Samspillet mellem regulering, brugernes forventninger og teknologiske muligheder betyder, at 2025-2026 bliver afgørende år for AI-rangeringsgennemsigtighed, hvor platforme sandsynligvis vil implementere mere standardiserede offentliggørelsespraksisser, bedre brugerkontrol over kildevalg og klarere forklaringer på rangeringslogik. Fremtiden vil sandsynligvis byde på lagdelt gennemsigtighed—akademiske platforme i front med høj åbenhed, forbrugerrettede platforme med moderat gennemsigtighed og brugertilpasning, og regulering som et basiskrav på tværs af industrien.
AI-rangeringsgennemsigtighed henviser til, hvor åbent AI-platforme offentliggør deres algoritmer for udvælgelse og rangering af kilder i genererede svar. Det er vigtigt, fordi brugere skal kunne forstå kilders troværdighed, indholdsskabere skal optimere for AI-synlighed, og forskere skal kunne verificere informationskilder. Uden gennemsigtighed kan AI-systemer forstærke misinformation og skabe urimelige fordele for etablerede medier frem for mindre udgivere.
AI-platforme anvender Retrieval-Augmented Generation (RAG)-systemer, der kombinerer sprogmodeller med realtids informationssøgning. De rangerer kilder baseret på faktorer som domæneautoritet, informationsaktualitet, emnerelevans, engagementssignaler og citeringsfrekvens. Dog er den præcise vægtning af disse faktorer fortsat overvejende proprietær og ikke offentliggjort af de fleste platforme.
Traditionel SEO fokuserer på at rangere i søgemaskinernes linklister, hvor Google offentliggør generelle rangeringsfaktorer. AI-rangeringsgennemsigtighed handler om, hvordan AI-platforme udvælger kilder til syntetiserede svar, hvilket involverer andre kriterier og for det meste ikke offentliggøres. Mens SEO-strategier er veldokumenterede, er AI-rangeringsfaktorer for det meste uigennemsigtige.
Du kan klikke videre til de originale kilder for at verificere udsagn i deres fulde kontekst, tjekke om kilderne stammer fra autoritative domæner, se efter peer review-status (især ved akademisk indhold) og krydstjekke information på tværs af flere kilder. Værktøjer som AmICited hjælper med at spore, hvilke kilder der vises i AI-svar, og hvor ofte dit indhold citeres.
Consensus fører an i gennemsigtighed ved udelukkende at fokusere på peer-reviewet akademisk forskning med klare citeringsmålinger. Perplexity tilbyder kildehenvisninger i teksten og moderat dokumentation af rangeringsfaktorer. Googles AI Overblik har middel gennemsigtighed, mens ChatGPT Search og Brave Leo kun giver begrænset indsigt i deres rangeringsalgoritmer.
Modelkort er standardiseret dokumentation af AI-systemers ydeevne, tiltænkte anvendelser, begrænsninger og bias-analyse. Datasheets dokumenterer sammensætningen af træningsdata, indsamlingsmetoder og potentielle skævheder. Systemkort beskriver den samlede systemadfærd. Disse værktøjer øger gennemsigtigheden og sammenligneligheden af AI-systemer, på samme måde som næringsdeklarationer for fødevarer.
EU's AI-forordning kræver, at højrisiko AI-systemer opretholder detaljeret teknisk dokumentation, registre over træningsdata og logfiler for ydeevne. Den påbyder gennemsigtighedsrapporter og brugeroplysning om anvendelsen af AI-systemer. Disse krav skubber AI-platforme mod større åbenhed om rangeringsmekanismer og kriterier for kildeudvælgelse.
AmICited.com er en AI-citatovervågningsplatform, der sporer, hvordan AI-systemer som Perplexity, Google AI Overblik og ChatGPT citerer dit brand og indhold. Den giver indsigt i, hvilke kilder der optræder i AI-svar, hvor ofte dit indhold citeres, og hvordan din rangeringsgennemsigtighed sammenlignes på tværs af forskellige AI-platforme.
Følg med i, hvordan AI-platforme som Perplexity, Google AI Overblik og ChatGPT citerer dit indhold. Forstå din rangeringsgennemsigtighed og optimer din synlighed på tværs af AI-søgemaskiner med AmICited.
Omfattende ordbog med 100+ essentielle AI-synligheds- og GEO-udtryk enhver marketingmedarbejder bør kende. Lær om citationstracking, brandovervågning og ordfork...
Opdag kritiske AI-synligheds blinde vinkler, hvor konkurrenter får fordele. Lær rammeværktøj for gap-analyse og værktøjer til at overvåge AI-tilstedeværelse på ...
Bliv ekspert i Semrush AI Visibility Toolkit med vores omfattende guide. Lær at overvåge brandets synlighed i AI-søgning, analysere konkurrenter og optimere til...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.