
Indholdets relevansscoring
Lær hvordan indholdets relevansscoring bruger AI-algoritmer til at måle, hvor godt indhold matcher brugerforespørgsler og -hensigt. Forstå BM25, TF-IDF, og hvor...
7 min læsning

AI Retrieval Scoring er processen med at kvantificere relevansen og kvaliteten af hentede dokumenter eller afsnit i forhold til en brugerforespørgsel. Det anvender sofistikerede algoritmer til at evaluere semantisk betydning, kontekstuel hensigtsmæssighed og informationskvalitet, og afgør hvilke kilder der sendes videre til sprogmodeller til svargenerering i RAG-systemer.
AI Retrieval Scoring er processen med at kvantificere relevansen og kvaliteten af hentede dokumenter eller afsnit i forhold til en brugerforespørgsel. Det anvender sofistikerede algoritmer til at evaluere semantisk betydning, kontekstuel hensigtsmæssighed og informationskvalitet, og afgør hvilke kilder der sendes videre til sprogmodeller til svargenerering i RAG-systemer.
AI Retrieval Scoring er processen med at kvantificere relevansen og kvaliteten af hentede dokumenter eller afsnit i forhold til en brugerforespørgsel eller opgave. I modsætning til simpel nøgleords-matchning, som kun identificerer overfladisk termoverlap, anvender retrieval scoring sofistikerede algoritmer til at evaluere semantisk betydning, kontekstuel hensigtsmæssighed og informationskvalitet. Denne scoringsmekanisme er grundlæggende for Retrieval-Augmented Generation (RAG) systemer, hvor den afgør, hvilke kilder der sendes videre til sprogmodeller til svargenerering. I moderne LLM-applikationer påvirker retrieval scoring direkte svarkvalitet, reduktion af hallucinationer og brugertilfredshed ved at sikre, at kun den mest relevante information når frem til genereringsstadiet. Kvaliteten af retrieval scoring er derfor en kritisk komponent for den samlede systemydelse og pålidelighed.
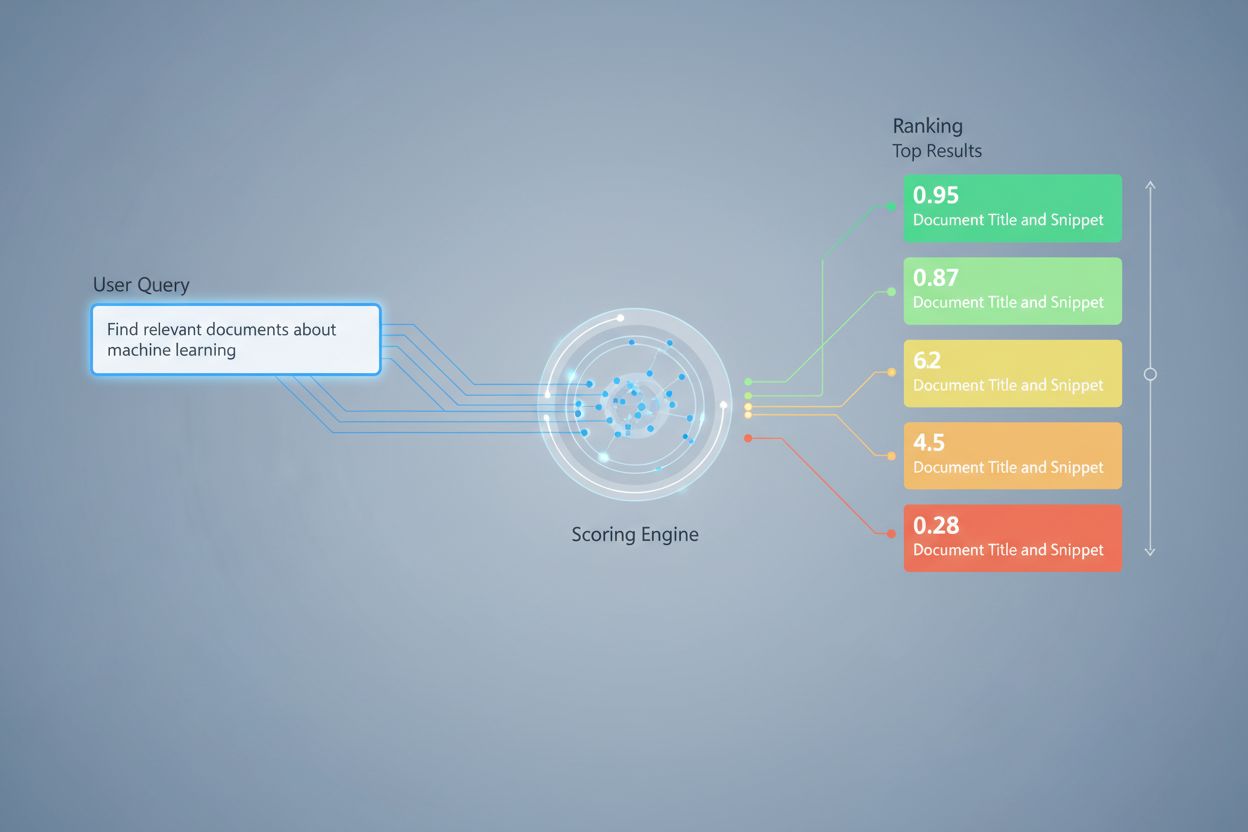
Retrieval scoring anvender flere algoritmiske tilgange, som hver især har deres styrker til forskellige formål. Semantisk lighedsscoring bruger indlejringsmodeller til at måle den begrebsmæssige sammenhæng mellem forespørgsler og dokumenter i vektorrum, hvilket fanger betydning ud over overfladiske nøgleord. BM25 (Best Matching 25) er en probabilistisk rangeringsfunktion, der tager højde for termfrekvens, omvendt dokumentfrekvens og normalisering af dokumentlængde, hvilket gør den meget effektiv til traditionel tekstretrieval. TF-IDF (Term Frequency-Inverse Document Frequency) vægter termer baseret på deres betydning i dokumenter og på tværs af samlinger, selvom den mangler semantisk forståelse. Hybride tilgange kombinerer flere metoder—såsom at sammenflette BM25- og semantiske scorer—for at udnytte både leksikale og semantiske signaler. Ud over scoringsmetoder giver evalueringsmålinger som Precision@k (procentdel af top-k resultater, der er relevante), Recall@k (procentdel af alle relevante dokumenter fundet i top-k), NDCG (Normalized Discounted Cumulative Gain, som tager højde for rangposition), og MRR (Mean Reciprocal Rank) kvantitative mål for retrieval kvalitet. At forstå styrker og svagheder ved hver tilgang—såsom BM25’s effektivitet versus semantisk scorings dybere forståelse—er essentielt for at vælge passende metoder til specifikke applikationer.
| Scoring Method | How It Works | Best For | Key Advantage |
|---|---|---|---|
| Semantisk Lighed | Sammenligner indlejringer ved brug af cosinuslighed eller andre afstandsmål | Begrebsmæssig betydning, synonymer, parafraser | Fanger semantiske relationer ud over nøgleord |
| BM25 | Probabilistisk rangering med hensyn til termfrekvens og dokumentlængde | Eksakt frasematchning, nøgleordsbaserede forespørgsler | Hurtig, effektiv, gennemprøvet i produktion |
| TF-IDF | Vægter termer efter frekvens i dokument og sjældenhed i samlingen | Traditionel informationshentning | Simpel, fortolkelig, letvægts |
| Hybrid Scoring | Kombinerer semantiske og nøgleordsbaserede tilgange med vægtet fusion | Almindelig hentning, komplekse forespørgsler | Udnytter styrker fra flere metoder |
| LLM-baseret Scoring | Bruger sprogmodeller til at vurdere relevans med tilpassede prompts | Kompleks kontekstvurdering, domænespecifikke opgaver | Fanger nuancerede semantiske relationer |
I RAG-systemer fungerer retrieval scoring på flere niveauer for at sikre genereringskvalitet. Systemet scorer typisk individuelle chunks eller afsnit i dokumenter, hvilket muliggør finmasket relevansvurdering frem for at behandle hele dokumenter som enheder. Denne relevansscoring per chunk gør det muligt for systemet kun at udtrække de mest relevante informationssegmenter, hvilket reducerer støj og irrelevant kontekst, der kunne forvirre sprogmodellen. RAG-systemer implementerer ofte scoringstærskler eller cutoff-mekanismer, der filtrerer resultater med lav score fra, før de når til genereringsstadiet, og forhindrer, at kilder af lav kvalitet påvirker det endelige svar. Kvaliteten af den hentede kontekst hænger direkte sammen med genereringskvaliteten—højt scorende, relevante afsnit fører til mere præcise, velunderbyggede svar, mens retrievals af lav kvalitet giver hallucinationer og faktuelle fejl. Overvågning af retrieval scorer giver tidlige advarselssignaler om systemforringelse og gør det til en nøglemåling for AI-svar overvågning og kvalitetssikring i produktion.
Re-ranking fungerer som en anden filtreringsmekanisme, der forfiner de indledende retrieval-resultater og ofte væsentligt forbedrer rangordningsnøjagtigheden. Efter at en indledende retriever har genereret kandidater med foreløbige scorer, anvender en re-ranker mere avanceret scoringslogik til at omordne eller filtrere kandidaterne, typisk ved brug af mere beregningskrævende modeller, der kan foretage dybere analyser. Reciprocal Rank Fusion (RRF) er en populær teknik, der kombinerer rangeringer fra flere retrievere ved at tildele scorer baseret på resultatposition og derefter sammenflette disse scorer til en samlet rangering, der ofte overgår individuelle retrievere. Scorenormalisering bliver kritisk, når man kombinerer resultater fra forskellige retrieval-metoder, da rå scorer fra BM25, semantisk lighed og andre tilgange opererer på forskellige skalaer og skal kalibreres til sammenlignelige niveauer. Ensemble-retriever tilgange udnytter flere retrieval-strategier samtidigt, hvor re-ranking afgør den endelige rækkefølge baseret på samlet evidens. Denne flertrinsmetode forbedrer rangordningsnøjagtighed og robusthed betydeligt sammenlignet med enkelttrins-retrieval, især i komplekse domæner, hvor forskellige retrieval-metoder fanger komplementære relevanssignaler.
Precision@k: Måler andelen af relevante dokumenter blandt de øverste k resultater; nyttig til at vurdere om de hentede resultater er pålidelige (f.eks. Precision@5 = 4/5 betyder 80% af de fem øverste resultater er relevante)
Recall@k: Beregner procentdelen af alle relevante dokumenter, der findes blandt de øverste k resultater; vigtig for at sikre fuldstændig dækning af tilgængelig relevant information
Hit Rate: Binær måling, der angiver om mindst ét relevant dokument findes blandt de øverste k resultater; nyttig til hurtige kvalitetstjek i produktion
NDCG (Normalized Discounted Cumulative Gain): Tager højde for rangposition ved at tildele større værdi til relevante dokumenter placeret tidligt; spænder fra 0-1 og er ideel til vurdering af rangordningskvalitet
MRR (Mean Reciprocal Rank): Måler gennemsnitspositionen for det første relevante resultat på tværs af flere forespørgsler; særligt nyttig til at vurdere om det mest relevante dokument rangeres højt
F1 Score: Harmonisk gennemsnit af precision og recall; giver balanceret vurdering når både falske positiver og falske negativer har samme betydning
MAP (Mean Average Precision): Gennemsnitlig precisionværdi ved hver position hvor et relevant dokument findes; omfattende måling for samlet rangordningskvalitet på tværs af flere forespørgsler
LLM-baseret relevansscoring udnytter sprogmodeller selv som dommere for dokumentrelevans og tilbyder et fleksibelt alternativ til traditionelle algoritmiske tilgange. I denne tilgang instruerer omhyggeligt udformede prompts en LLM i at vurdere, om et hentet afsnit besvarer en given forespørgsel, og producerer enten binære relevansscorer (relevant/ikke relevant) eller numeriske scorer (f.eks. en skala fra 1-5, der angiver relevansstyrke). Denne metode opfanger nuancerede semantiske relationer og domænespecifik relevans, som traditionelle algoritmer kan overse, især ved komplekse forespørgsler der kræver dyb forståelse. Dog medfører LLM-baseret scoring udfordringer som beregningsomkostninger (LLM-inferens er dyrere end indlejringslighed), potentiel inkonsistens på tværs af prompts og modeller samt behov for kalibrering med menneskelige labels for at sikre scorerne svarer til reel relevans. På trods af disse begrænsninger har LLM-baseret scoring vist sig værdifuld til at evaluere RAG-systemkvalitet og til oprettelse af træningsdata til specialiserede scoringsmodeller, hvilket gør det til et vigtigt værktøj i AI-overvågning for vurdering af svarkvalitet.
Effektiv implementering af retrieval scoring kræver nøje overvejelse af flere praktiske faktorer. Metodevalg afhænger af kravene til brugsscenariet: semantisk scoring er bedst til at fange betydning, men kræver indlejringsmodeller, mens BM25 tilbyder hastighed og effektivitet ved leksikalsk matchning. Afvejningen mellem hastighed og nøjagtighed er central—indlejringsbaseret scoring giver bedre forståelse af relevans, men medfører latenstid, mens BM25 og TF-IDF er hurtigere, men mindre semantisk sofistikerede. Computational cost inkluderer inferenstid for modeller, hukommelseskrav og behov for skalering af infrastruktur, især vigtigt for produktion i stor skala. Parameterjustering indebærer tilpasning af tærskler, vægte i hybride tilgange og re-ranking cutoffs for at optimere ydeevne til specifikke domæner og brug. Kontinuerlig overvågning af scoringsydelse via målinger som NDCG og Precision@k hjælper med at identificere forringelse over tid og muliggør proaktive forbedringer, så ens produktion af RAG-systemer leverer konsistent svar-kvalitet.
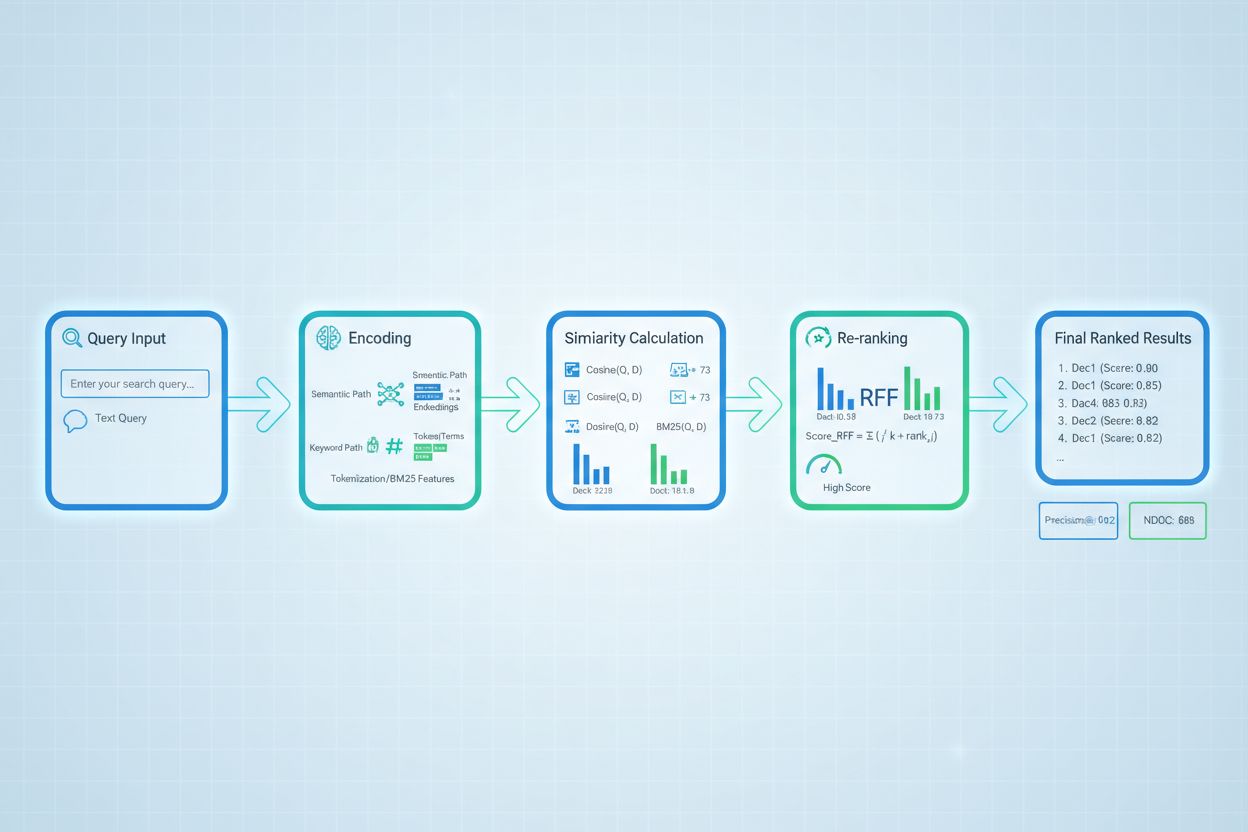
Avancerede retrieval scoring-teknikker går ud over basal relevansvurdering for at fange komplekse kontekstuelle relationer. Omskrivning af forespørgsler kan forbedre scoring ved at omformulere brugerforespørgsler til flere semantisk ækvivalente former, så retrieveren kan finde relevante dokumenter, der ellers ville blive overset ved bogstavelig matchning. Hypothetical Document Embeddings (HyDE) genererer syntetiske relevante dokumenter ud fra forespørgsler og bruger disse hypotetiske til at forbedre retrieval scoring ved at finde rigtige dokumenter, der ligner det idealiserede relevante indhold. Multi-query tilgange sender flere variationer af forespørgslen til retrievere og samler deres scorer, hvilket forbedrer robusthed og dækning sammenlignet med enkelt-forespørgsels retrieval. Domænespecifikke scoringsmodeller trænet på mærkede data fra bestemte brancher eller vidensdomæner kan opnå bedre resultater end generelle modeller, især værdifuldt til specialiserede anvendelser som medicinske eller juridiske AI-systemer. Kontekstuelle scoringstilpasninger tager højde for faktorer som dokumenters aktualitet, kildeautoritet og brugerkontekst, hvilket muliggør en mere sofistikeret relevansvurdering, der rækker ud over ren semantisk lighed og inkorporerer virkelighedsnære relevansfaktorer, der er afgørende for produktionsklare AI-systemer.
Retrieval scoring tildeler numeriske relevansværdier til dokumenter baseret på deres forhold til en forespørgsel, mens ranking ordner dokumenter ud fra disse scorer. Scoring er evalueringsprocessen, ranking er resultatet af sorteringen. Begge er essentielle for at RAG-systemer kan levere præcise svar.
Retrieval scoring afgør, hvilke kilder der når frem til sprogmodellen til svargenerering. Høj kvalitet i scoring sikrer, at relevant information vælges, hvilket reducerer hallucinationer og forbedrer svarkvalitet. Dårlig scoring fører til irrelevant kontekst og upålidelige AI-svar.
Semantisk scoring bruger indlejring til at forstå begrebsmæssig betydning og opfanger synonymer og relaterede koncepter. Nøgleordsbaseret scoring (som BM25) matcher præcise termer og fraser. Semantisk scoring er bedst til at forstå intentionen, mens nøgleordsscoring er bedst til at finde specifik information.
Nøglemålinger inkluderer Precision@k (nøjagtighed af topresultater), Recall@k (dækning af relevante dokumenter), NDCG (rangordningskvalitet) og MRR (placering af første relevante resultat). Vælg målinger baseret på dit brugsscenarie: Precision@k for kvalitetsfokuserede systemer, Recall@k for fuldstændig dækning.
Ja, LLM-baseret scoring bruger sprogmodeller som dommere til at vurdere relevans. Denne tilgang opfanger nuancerede semantiske relationer, men er beregningsmæssigt krævende. Det er værdifuldt til at evaluere RAG-kvalitet og oprette træningsdata, men kræver kalibrering med menneskelige labels.
Re-ranking anvender en anden filtrering med mere sofistikerede modeller for at forfine de indledende resultater. Teknikker som Reciprocal Rank Fusion kombinerer flere retrieval-metoder og forbedrer nøjagtighed og robusthed. Re-ranking overgår væsentligt enkelttrins-retrieval i komplekse domæner.
BM25 og TF-IDF er hurtige og lette, velegnede til realtidssystemer. Semantisk scoring kræver inferens med indlejringsmodeller og øger forsinkelsen. LLM-baseret scoring er den mest krævende. Vælg ud fra dine krav til latenstid og tilgængelige ressourcer.
Overvej dine prioriteter: semantisk scoring til meningsfokuserede opgaver, BM25 for hastighed og effektivitet, hybride tilgange for balanceret ydeevne. Evaluer på dit specifikke domæne med målinger som NDCG og Precision@k. Test flere metoder og mål deres effekt på den endelige svarkvalitet.
Følg hvordan AI-systemer som ChatGPT, Perplexity og Google AI refererer til dit brand, og vurder kvaliteten af deres kildehentning og rangering. Sørg for at dit indhold bliver korrekt citeret og rangeret af AI-systemer.
Lær hvordan indholdets relevansscoring bruger AI-algoritmer til at måle, hvor godt indhold matcher brugerforespørgsler og -hensigt. Forstå BM25, TF-IDF, og hvor...

Lær, hvad læsbarhedsscorer betyder for synlighed i AI-søgning. Opdag, hvordan Flesch-Kincaid, sætningsstruktur og indholdsformatering påvirker AI-citater i Chat...
Lær hvad en AI-synlighedsscore er, hvordan den måler dit brands tilstedeværelse i AI-genererede svar på tværs af ChatGPT, Perplexity og andre AI-platforme, og h...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.