Google-Extended
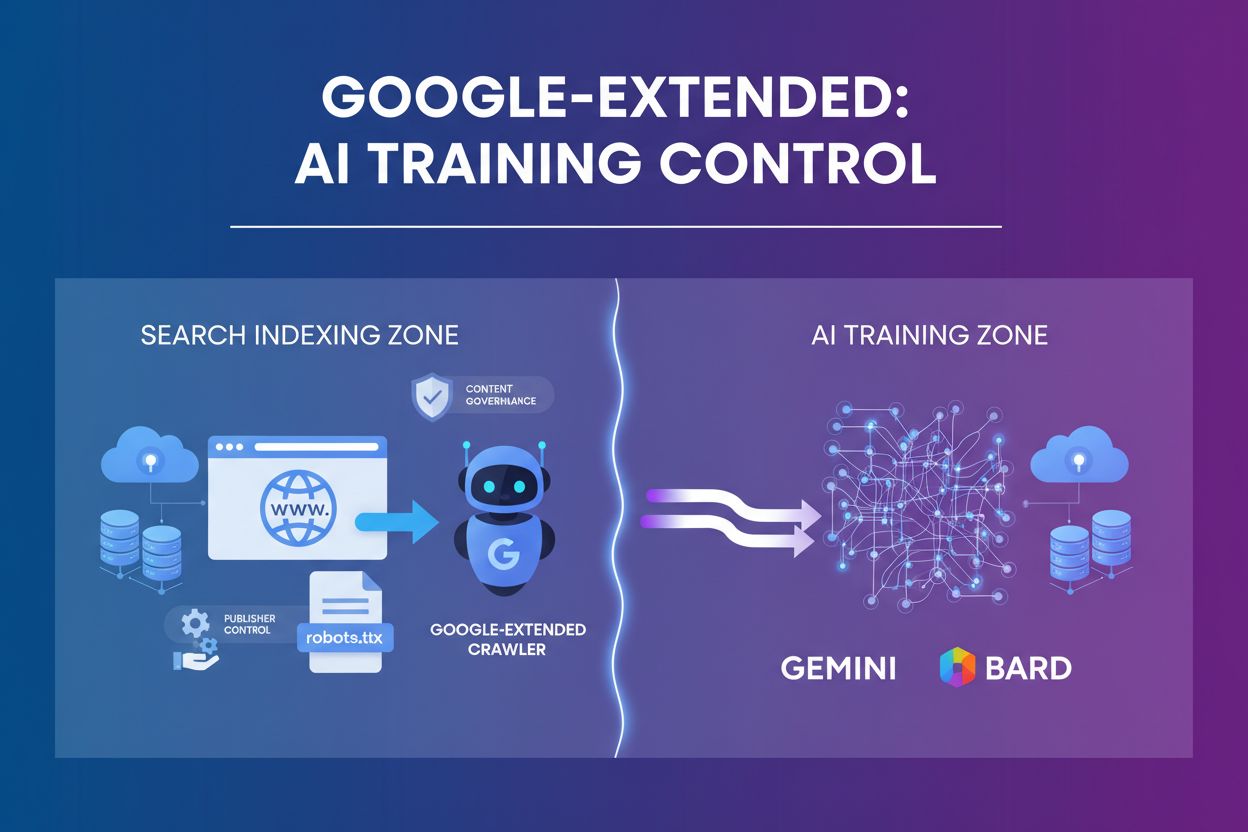
Lær om Google-Extended, user-agent-tokenet der lader udgivere styre, om deres indhold bruges til AI-træning i Gemini og Vertex AI. Forstå hvordan det adskiller ...
6 min læsning
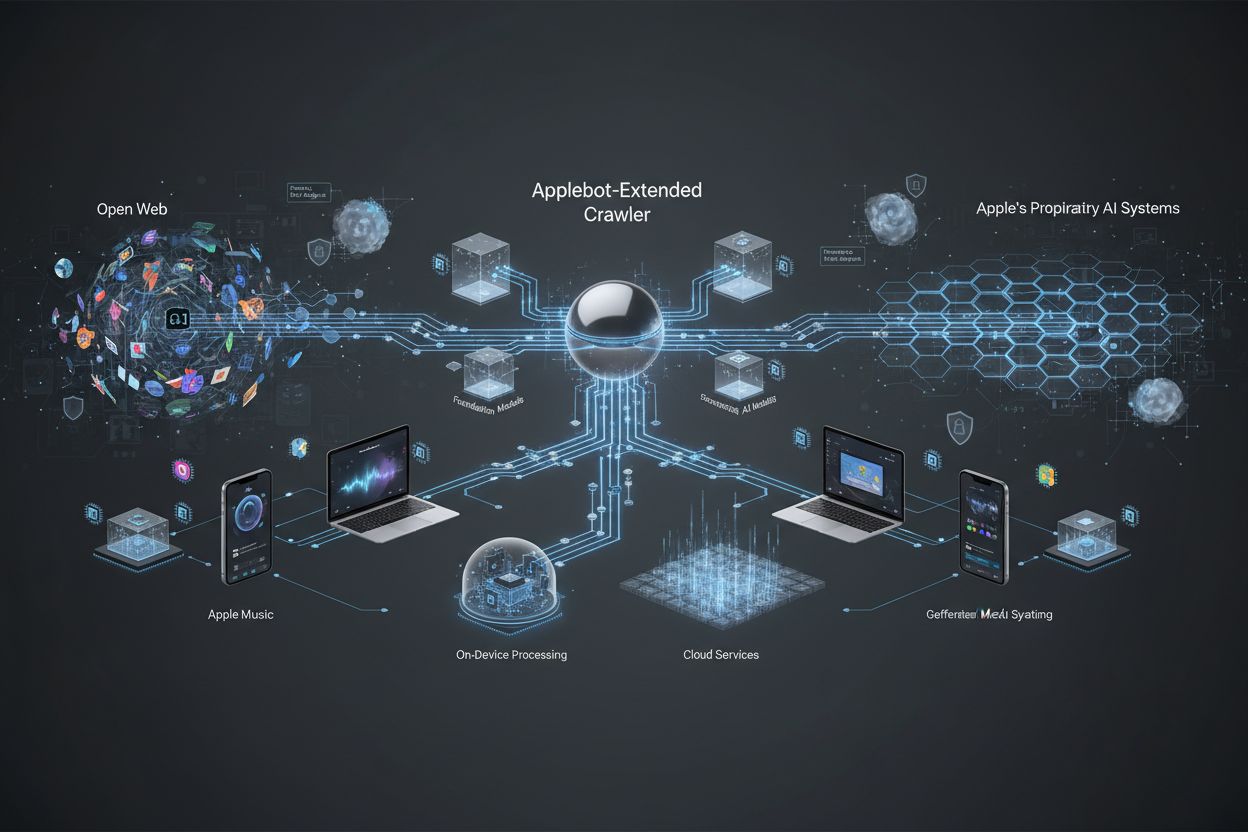
Apples specialiserede webcrawler, der evaluerer indhold til træning af Apple Intelligence og generative AI-modeller. Den fungerer som en sekundær evalueringsmekanisme i forhold til den almindelige Applebot og afgør, hvilket offentligt tilgængeligt webindhold der er egnet til inkludering i Apples foundation-modeller og LLM’er. Website-ejere kan styre dens adgang via robots.txt-direktiver uafhængigt af den almindelige Applebot.
Apples specialiserede webcrawler, der evaluerer indhold til træning af Apple Intelligence og generative AI-modeller. Den fungerer som en sekundær evalueringsmekanisme i forhold til den almindelige Applebot og afgør, hvilket offentligt tilgængeligt webindhold der er egnet til inkludering i Apples foundation-modeller og LLM'er. Website-ejere kan styre dens adgang via robots.txt-direktiver uafhængigt af den almindelige Applebot.
Applebot-Extended er en specialiseret webcrawler drevet af Apple, der udvider mulighederne for den almindelige Applebot til at indsamle og evaluere indhold specielt til træning af Apple Intelligence-systemer. Hvor den oprindelige Applebot primært tjener Apples behov for søgning og indeksering, fungerer Applebot-Extended som en særskilt crawler, der fokuserer på at indsamle indhold af høj kvalitet, som kan bruges til at forbedre Apples generative AI- og maskinlæringsmodeller. Denne crawler repræsenterer Apples dedikation til at udvikle avancerede AI-træningsdatasæt ved systematisk at identificere og behandle webindhold, der lever op til specifikke kvalitetsstandarder. Skellet mellem den almindelige Applebot og Applebot-Extended er væsentligt for website-ejere, da de to crawlere har forskellige formål og kan administreres uafhængigt via robots.txt-direktiver.
Applebot-Extended fungerer inden for et to-niveau crawler-system, hvor den indledende indholdsopdagelse foretages af den almindelige Applebot, efterfulgt af en sekundær evalueringsfase udført af Applebot-Extended. Når Applebot-Extended besøger en webside, foretager den en omfattende indholdsevaluering for at afgøre, om materialet lever op til Apples standarder for inkludering i AI-træningsdatasæt. Crawleren identificerer sig selv via en specifik user agent-streng, der adskiller den fra den almindelige Applebot, så website-administratorer kan skelne mellem de to crawlere i deres serverlogs og analyseplatforme. Applebot-Extended evaluerer indhold ud fra flere kriterier, herunder relevans, nøjagtighed, originalitet og overholdelse af kvalitetsretningslinjer, der sikrer, at kun førsteklasses indhold bidrager til Apple Intelligence-systemer.
| Funktion | Applebot | Applebot-Extended |
|---|---|---|
| Primært formål | Generel indeksering og søgning | Indsamling af AI-træningsdata |
| Indholdsfokus | Alt webindhold | Udvalgt indhold af høj kvalitet |
| User agent | Applebot | Applebot-Extended |
| Evalueringsdybde | Standard crawling | Avanceret kvalitetsvurdering |
| Blokeringsmetode | robots.txt-direktiver | Separate robots.txt-regler |

Apple Intelligence repræsenterer Apples integrerede suite af AI-drevne funktioner, der skal forbedre brugeroplevelser på tværs af iOS, iPadOS, macOS og andre Apple-platforme gennem behandling både på enheden og i skyen. De generative AI-muligheder, som Applebot-Extended-data muliggør, omfatter avancerede skriveværktøjer, billedgenerering, intelligente forbedringer af søgning og kontekstbevidste assistentfunktioner, der udnytter foundation-modeller og large language models (LLM’er) trænet på udvalgt webindhold. Disse systemer gør det muligt at bruge funktioner som Skriveværktøjer til e-mail og dokumentkomposition, Image Playground til kreativ indholdsskabelse og forbedrede Siri-egenskaber, der forstår komplekse brugerforespørgsler med større nuancerigdom og præcision. Apples tilgang lægger vægt på privatlivsbevarende AI ved at behandle meget af denne intelligens på enheden, mens Applebot-Extended sikrer, at træningsdataene, der ligger til grund for disse systemer, stammer fra kilder af høj kvalitet og diversitet på nettet. Crawlerens selektive tilgang til indsamling af indhold har direkte indflydelse på raffinementet og pålideligheden af Apple Intelligence-funktioner, som er tilgængelige for millioner af brugere globalt.
Applebot-Extended målretter specifikke kategorier af indhold, der udviser høj informationsværdi og pålidelighed til AI-træningsformål. Crawleren prioriterer indhold ud fra følgende kriterier:
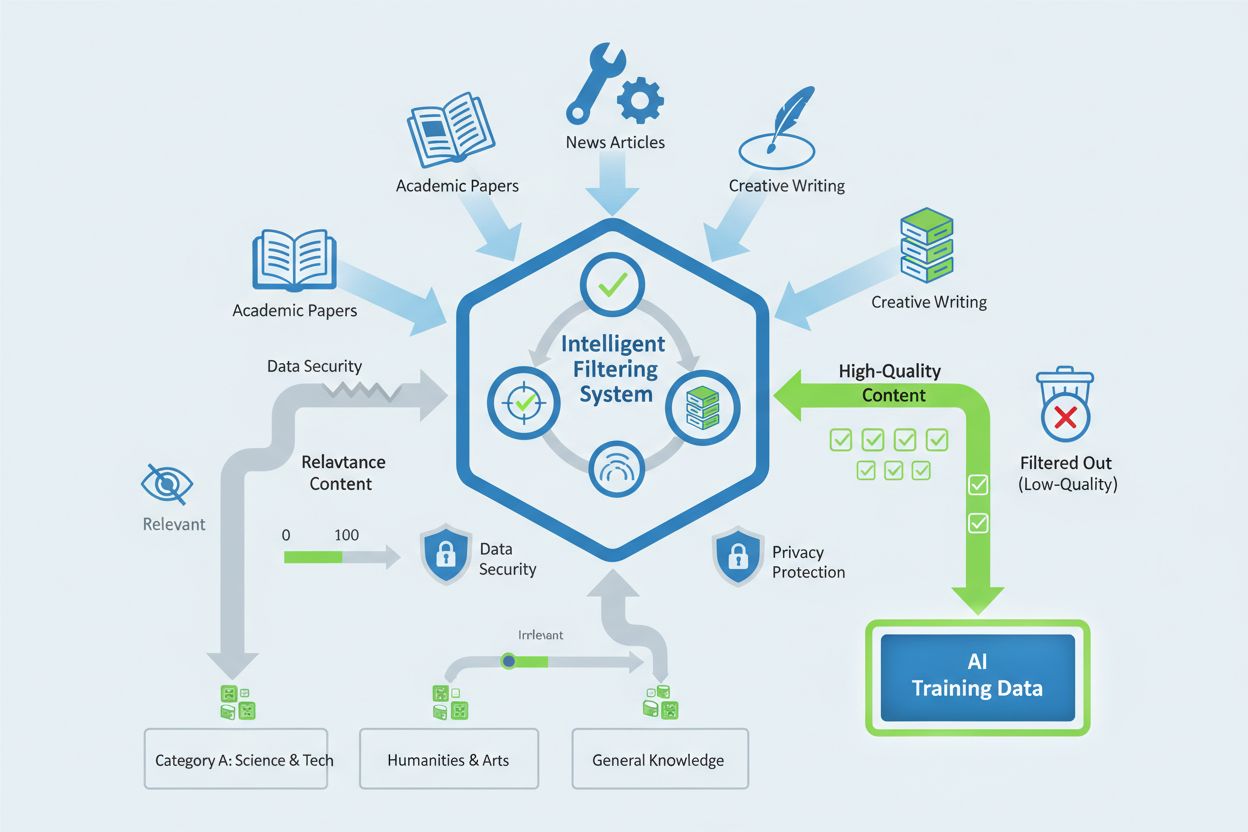
Crawleren benytter sofistikerede datafiltreringsmekanismer til at fjerne lavkvalitetsindhold, herunder spam, duplikeret materiale og indhold med minimal informationsværdi. Apple implementerer privatlivsbevarende evalueringsteknikker, der vurderer indholdets kvalitet uden unødvendigt at lagre persondata eller følsomme oplysninger. Udvælgelsesprocessen inkluderer automatiserede kvalitetsscoringssystemer, der vurderer faktorer såsom kildens troværdighed, indholdets originalitet, faktuel nøjagtighed og relevans for Apple Intelligence-træningsmål. Website-ejere kan påvirke deres indholds inklusion ved at opretholde høje redaktionelle standarder, sikre originalt og autoritativt materiale og undgå praksisser, der kunstigt oppuster kvalitetsmålinger for indhold.
Website-administratorer kan styre Applebot-Extendeds adgang til deres indhold via robots.txt-direktiver, som giver detaljeret kontrol over crawleradfærd uafhængigt af de begrænsninger, der gælder for den almindelige Applebot. For at blokere specifikt for Applebot-Extended, mens den almindelige Applebot fortsat må crawle, kan website-ejere implementere målrettede regler, der skelner mellem de to crawlere via deres respektive user agent-identifikatorer. Den afgørende forskel er, at blokering af den almindelige Applebot ikke automatisk blokerer Applebot-Extended og omvendt—hver crawler skal administreres særskilt, hvis forskellige adgangspolitikker ønskes. Blokering af Applebot-Extended har minimal direkte SEO-betydning, da det ikke påvirker søgerangeringer, men det forhindrer dit indhold i at bidrage til Apple Intelligence-træning, hvilket potentielt kan begrænse din sides synlighed i Apples AI-drevne funktioner og tjenester.
# Bloker kun Applebot-Extended, men tillad den almindelige Applebot
User-agent: Applebot-Extended
Disallow: /
# Tillad den almindelige Applebot
User-agent: Applebot
Allow: /
# Bloker både Applebot og Applebot-Extended
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Bloker specifikke mapper for Applebot-Extended
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple opretholder en privatlivsførst-tilgang til Applebot-Extendeds aktiviteter og understreger, at indsamling af indhold til AI-træning respekterer brugernes privatliv og databeskyttelsesregler på tværs af jurisdiktioner. Virksomheden implementerer tekniske og organisatoriske foranstaltninger for at sikre, at persondata ikke indsamles eller opbevares unødvendigt under crawling- og evalueringsprocessen, hvor vurderingen af indholdet fokuserer på informationsværdi frem for udtrækning af personoplysninger. Website-ejere og indholdsskabere bevarer individuelle privatlivsrettigheder i forhold til deres data, herunder retten til at anmode om oplysninger om, hvordan deres indhold bruges, samt at udøve retten til at få det fjernet under gældende privatlivslovgivning såsom GDPR og CCPA. Apple stiller Apple Intelligence Privacy Inquiries-formularen til rådighed som en formel mekanisme for enkeltpersoner til at indsende spørgsmål, bekymringer eller anmodninger om, hvordan deres indhold eller persondata håndteres i forbindelse med Apple Intelligence-systemer. Denne strukturerede tilgang til privatliv sikrer, at fordelene ved avancerede AI-muligheder balanceres med fundamentale rettigheder til databeskyttelse og brugerautonomi.
Website-ejere kan opdage Applebot-Extended-besøg ved at overvåge serverlogs og analysere user agent-strenge, hvor “Applebot-Extended” vil fremgå i feltet til crawleridentifikation. Specialiserede analysetools som Dark Visitors og UseHall giver udvidet indsigt i AI-crawlertrafik, så administratorer kan spore crawl-mønstre, hyppighed og ressourceforbrug forbundet med Applebot-Extended-besøg. Disse overvågningsløsninger hjælper website-ejere med at forstå effekten af AI-crawlere på serverressourcer og båndbredde og muliggør informerede beslutninger om crawleradgang og optimeringsstrategier. Ved at implementere passende trafikdetektion og logningsmekanismer kan administratorer skelne Applebot-Extended-aktivitet fra anden crawlertrafik og menneskelige brugeres adfærd og opnå værdifuld indsigt i, hvordan deres indhold bidrager til Apples AI-træningsinfrastruktur.
Applebot-Extended opererer i et bredere økosystem af AI-fokuserede webcrawlere, der tjener forskellige formål og arbejder under forskellige politikker, som hver især afspejler deres moderselskabs tilgang til AI-udvikling og dataindsamling. Googlebot tjener primært Googles søgeindekserings- og rangeringsfunktioner, mens separate crawlere som Googlebot-Extended håndterer indholdsevaluering for Googles AI-systemer, hvilket gør den funktionelt sammenlignelig med Apples to-niveau-tilgang, men på et betydeligt større skala. Bingbot, Microsofts crawler, understøtter ligeledes både søgeindeksering og AI-træning til Copilot og andre generative AI-tjenester, dog med forskellige evalueringskriterier og privatlivsrammer. ChatGPT-crawleren (drevet af OpenAI) fokuserer specifikt på indholdsindsamling til store sprogmodeltræninger og arbejder med eksplicitte opt-out-mekanismer og andre databrugsaftaler end Apples tilgang. I modsætning til nogle konkurrenter skiller Applebot-Extended sig ud gennem Apples fokus på on-device behandling og privatlivsbeskyttelse, hvilket begrænser opbevaring af data i skyen og giver klarere opt-out-muligheder via robots.txt og formelle privatlivsforespørgsler. Den komparative analyse viser, at selvom alle større teknologivirksomheder bruger AI-crawlere, varierer deres evalueringskriterier, dataopbevaringspolitikker og brugerkontrolmekanismer betydeligt og afspejler forskellige virksomheders filosofi omkring AI-udvikling, privatliv og rettigheder for indholdsskabere. Website-ejere bør forstå disse forskelle, når de træffer beslutninger om crawleradgang, da hver crawlers politikker og indflydelse på brugen af deres indhold i AI-systemer adskiller sig væsentligt.
Applebot er Apples primære webcrawler, der bruges til søgeindeksering og til at drive funktioner som Spotlight og Siri-søgning. Applebot-Extended er en sekundær crawler, der evaluerer indhold, som allerede er indekseret af Applebot, for at afgøre om det er egnet til træning af Apples generative AI-modeller. De tjener forskellige formål og kan administreres uafhængigt via robots.txt.
Du kan blokere Applebot-Extended ved at tilføje specifikke regler i din robots.txt-fil. Brug 'User-agent: Applebot-Extended' efterfulgt af 'Disallow: /' for at blokere hele sitet, eller angiv bestemte mapper. Dette forhindrer dit indhold i at blive brugt til Apple Intelligence-træning, mens den almindelige Applebot stadig kan indeksere dit site til søgeformål.
Blokering af Applebot-Extended har minimal direkte SEO-effekt, da det ikke påvirker placeringer i søgemaskiner. Det forhindrer dog dit indhold i at bidrage til Apple Intelligence-træning, hvilket kan reducere din synlighed i Apples AI-drevne funktioner og tjenester i fremtiden.
Applebot-Extended målretter indhold af høj kvalitet, herunder akademiske artikler, teknisk dokumentation, professionelle nyhedsartikler, originalt kreativt materiale og indhold fra anerkendte fageksperter. Crawleren evaluerer indhold baseret på troværdighed, originalitet, faktuel nøjagtighed og relevans for AI-træningsformål.
Nej. Apple oplyser eksplicit, at de ikke bruger brugeres private persondata eller brugerinteraktioner, når foundation-modeller til Apple Intelligence trænes. Virksomheden benytter kun offentligt tilgængeligt webindhold, licenseret materiale og syntetisk skabte data. Apple implementerer privatlivsbeskyttende foranstaltninger for at fjerne personlige oplysninger fra træningsdatasæt.
Du kan opdage Applebot-Extended-besøg ved at overvåge serverlogs for 'Applebot-Extended' user agent-strengen. Specialiserede analysetools som Dark Visitors og UseHall giver udvidet indsigt i AI-crawlertrafik, så du kan spore crawl-mønstre, hyppighed og ressourceforbrug.
Apple Intelligence er Apples integrerede suite af AI-drevne funktioner på tværs af iOS, iPadOS, macOS og andre platforme. Applebot-Extended indsamler indhold af høj kvalitet, der træner foundation-modellerne og large language models, som driver Apple Intelligence-funktioner som Skriveværktøjer, Image Playground og forbedrede Siri-muligheder.
Ja. Apple stiller formularen Apple Intelligence Privacy Inquiries til rådighed, hvor personer kan indsende anmodninger om, hvordan deres indhold eller persondata håndteres i forbindelse med Apple Intelligence-systemer. Du kan også bruge almindelige robots.txt-direktiver til at fravælge Applebot-Extended-crawling.
Følg hvordan dit indhold vises i Apple Intelligence og andre AI-systemer med AmICiteds omfattende AI-overvågningsplatform.
Lær om Google-Extended, user-agent-tokenet der lader udgivere styre, om deres indhold bruges til AI-træning i Gemini og Vertex AI. Forstå hvordan det adskiller ...

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...

Lær hvad Google-Extended er, hvordan det fungerer, og om du bør blokere det i din robots.txt. Forstå forskellen mellem kontrol over AI-træning og AI Overblik....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.