
Hvad er Burstiness i AI-Indhold, og Hvordan Påvirker det Detektion
Lær hvad burstiness betyder i AI-genereret indhold, hvordan det adskiller sig fra menneskelige skrivevaner, og hvorfor det har betydning for AI-detektion og ind...
8 min læsning
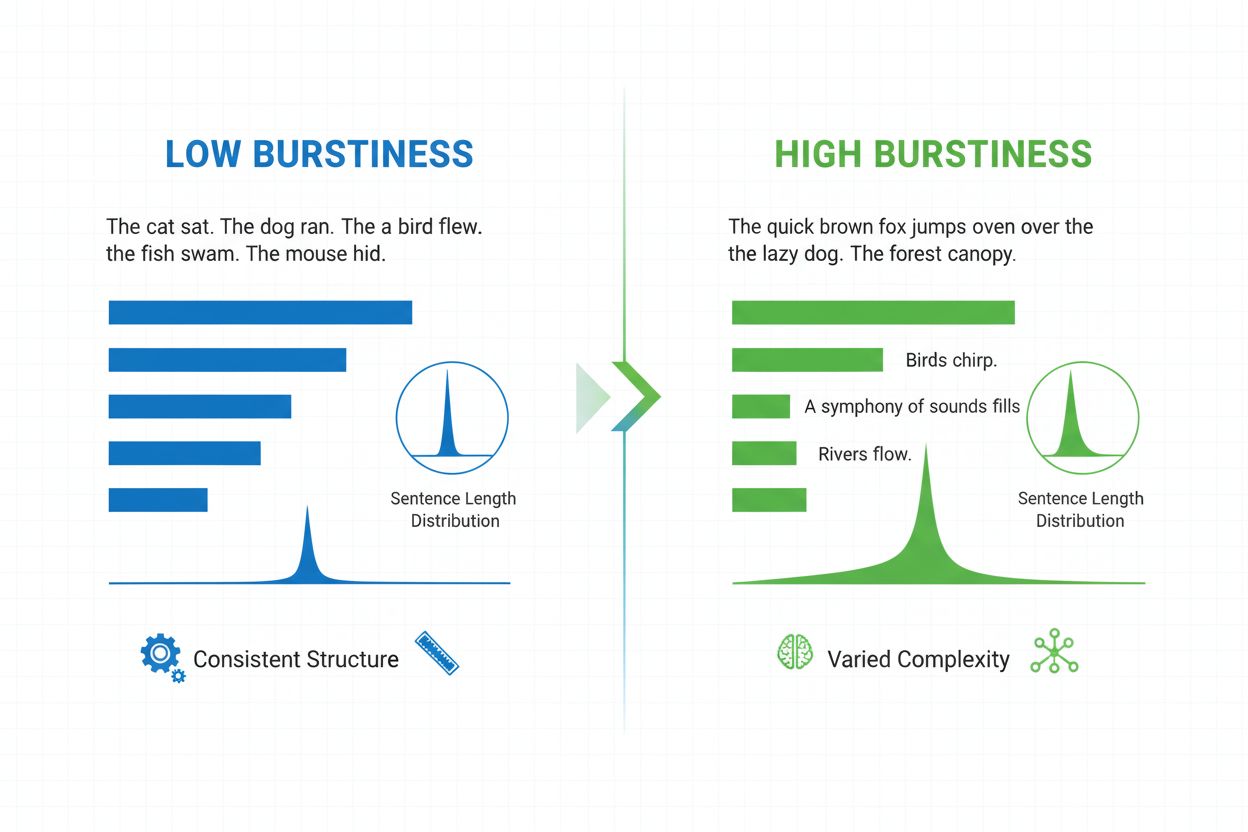
Burstiness er en sproglig måling, der vurderer variationen i sætningslængde, -struktur og -kompleksitet i løbet af et dokument. Den kvantificerer, hvor meget en forfatter veksler mellem korte, slagkraftige sætninger og længere, mere komplekse, og fungerer som en central indikator i AI-genereret indholdsdetektion og naturlig sprog-analyse.
Burstiness er en sproglig måling, der vurderer variationen i sætningslængde, -struktur og -kompleksitet i løbet af et dokument. Den kvantificerer, hvor meget en forfatter veksler mellem korte, slagkraftige sætninger og længere, mere komplekse, og fungerer som en central indikator i AI-genereret indholdsdetektion og naturlig sprog-analyse.
Burstiness er en kvantificerbar sproglig måling, der vurderer variationen og udsvingene i sætningslængde, -struktur og -kompleksitet i et skriftligt dokument eller tekstafsnit. Begrebet stammer fra idéen om “udbrud” af varierende sætningsmønstre—vekslen mellem korte, præcise sætninger og længere, mere indviklede. I naturlig sprogbehandling og AI-indholdsdetektion fungerer burstiness som en vigtig indikator for, om tekst er skrevet af et menneske eller genereret af et kunstigt intelligens-system. Menneskelige forfattere producerer naturligt tekst med høj burstiness, fordi de instinktivt varierer deres sætningsopbygning afhængigt af betoning, tempo og stilistisk intention. Omvendt udviser AI-genereret tekst typisk lav burstiness, fordi sprogmodeller trænes på statistiske mønstre, der favoriserer konsistens og forudsigelighed. At forstå burstiness er essentielt for indholdsskabere, undervisere, forskere og organisationer, der overvåger AI-genereret indhold på platforme som ChatGPT, Perplexity, Google AI Overviews og Claude.
Begrebet burstiness opstod fra forskning i computerlingvistik og informationsteori, hvor forskere forsøgte at kvantificere de statistiske egenskaber ved naturligt sprog. Tidligt arbejde inden for stylometri—statistisk analyse af skrivestil—identificerede, at menneskelig skrivning udviser karakteristiske variationsmønstre, der fundamentalt adskiller sig fra maskinskabt tekst. I takt med at store sprogmodeller (LLMs) blev mere sofistikerede i begyndelsen af 2020’erne, indså forskere, at burstiness kombineret med perpleksitet (en måling af ordfordelighed) kunne tjene som en pålidelig indikator for AI-genereret indhold. Ifølge forskning fra QuillBot og akademiske institutioner bruger cirka 78% af virksomheder nu AI-drevne indholdsovervågningsværktøjer, der inkorporerer burstiness-analyse i deres detektionsalgoritmer. Stanford Universitys 2023-undersøgelse af TOEFL-essays demonstrerede, at burstiness-baserede detektionsmetoder, selvom de er nyttige, har betydelige begrænsninger—særligt i forhold til falske positiver i ikke-indfødt engelskskrivning. Denne forskning har drevet udviklingen af mere sofistikerede, flerlags AI-detekteringssystemer, der supplerer burstiness med andre sproglige markører, semantisk sammenhæng og kontekstuel hensigtsmæssighed.
Burstiness beregnes ved at analysere den statistiske fordeling af sætningslængder og strukturelle mønstre i en tekst. Målingen kvantificerer varians—altså hvor meget de enkelte sætninger afviger fra den gennemsnitlige sætningslængde i et dokument. Et dokument med høj burstiness indeholder sætninger, der varierer markant i længde; for eksempel kan en forfatter følge en tre-ords sætning (“Ser du?”) med en femogtyve-ords sætning med flere ledsætninger og indskudte sætninger. Omvendt indikerer lav burstiness, at de fleste sætninger samler sig omkring en lignende længde, typisk mellem tolv og atten ord, hvilket skaber en monoton rytme. Beregningen omfatter flere trin: først måles længden af hver sætning i ord; dernæst udregnes gennemsnitlig sætningslængde; til sidst beregnes standardafvigelsen for at bestemme, hvor meget de enkelte sætninger afviger fra gennemsnittet. En højere standardafvigelse indikerer større variation og dermed højere burstiness. Moderne AI-detektorer som Winston AI og Pangram anvender avancerede algoritmer, der ikke kun tæller ord, men også analyserer syntaktisk kompleksitet—den strukturelle opbygning af ledsætninger, fraser og grammatiske elementer. Denne dybere analyse afslører, at menneskelige forfattere bruger forskellige sætningsstrukturer (enkle, sammensatte, komplekse og sammensat-komplekse sætninger) i uforudsigelige mønstre, mens AI-modeller har tendens til at foretrække bestemte strukturelle skabeloner, der ofte optræder i deres træningsdata.
| Måling | Burstiness | Perpleksitet | Måle-fokus |
|---|---|---|---|
| Definition | Variation i sætningslængde og struktur | Forudsigelighed af enkelte ord | Sætningsniveau vs. ordniveau |
| Menneskelig skrivning | Høj (varierede strukturer) | Høj (uforudsigelige ord) | Naturlig rytme og ordforråd |
| AI-genereret tekst | Lav (ensartede strukturer) | Lav (forudsigelige ord) | Statistisk konsistens |
| Detektionsanvendelse | Identificerer strukturel monotoni | Identificerer ordvalgsmønstre | Komplementære detektionsmetoder |
| Falsk positiv-risiko | Højere for ESL-forfattere | Højere for teknisk/akademisk skrivning | Begge har begrænsninger |
| Beregning | Standardafvigelse af sætningslængder | Sandsynlighedsfordelingsanalyse | Forskellige matematiske tilgange |
| Pålidelighed alene | Utilstrækkelig til endelig detektion | Utilstrækkelig til endelig detektion | Mest effektiv i kombination |
Store sprogmodeller som ChatGPT, Claude og Google Gemini trænes gennem en proces kaldet næste-token forudsigelse, hvor modellen lærer at forudsige det mest statistisk sandsynlige ord, der skal følge en given sekvens. Under træningen optimeres disse modeller eksplicit for at minimere perpleksitet på deres træningsdatasæt, hvilket utilsigtet skaber lav burstiness som et biprodukt. Når en model gentagne gange møder en bestemt sætningsstruktur i træningsdataene, lærer den at reproducere den struktur med høj sandsynlighed, hvilket medfører ensartede, forudsigelige sætningslængder. Forskning fra Netus AI og Winston AI viser, at AI-modeller udviser et karakteristisk stilometrisk fingeraftryk præget af ensartet sætningsopbygning, overforbrug af overgangssætninger (såsom “Desuden”, “Derfor”, “Ydermere”) og en tendens til passiv frem for aktiv stemme. Modellernes afhængighed af sandsynlighedsfordelinger betyder, at de søger mod de mest almindelige mønstre i træningsdataene frem for at udforske hele spektret af mulige sætningsopbygninger. Dette skaber en paradoksal situation: jo mere data en model trænes på, jo mere lærer den at reproducere almindelige mønstre, og dermed falder burstiness. Derudover mangler AI-modeller spontanitet og følelsesmæssig variation, som kendetegner menneskelig skrivning—de skriver ikke anderledes, når de er begejstrede, frustrerede eller vil understrege et punkt. I stedet bevarer de en konsistent stilistisk grundtone, der afspejler det statistiske centrum af deres træningsdistribution.
AI-detekteringsplatforme har inkorporeret burstiness-analyse som en kernekomponent i deres detektionsalgoritmer, dog med varierende grad af sofistikation. Tidlige detektionssystemer var stærkt afhængige af burstiness og perpleksitet som primære målinger, men forskning har afsløret væsentlige begrænsninger ved denne tilgang. Ifølge Pangram Labs producerer perpleksitets- og burstiness-baserede detektorer falske positiver, når de analyserer tekst fra sprogmodellernes træningsdatasæt—mest bemærkelsesværdigt bliver Uafhængighedserklæringen ofte markeret som AI-genereret, fordi den optræder så ofte i træningsdataene, at modellen tildeler den ensartet lav perpleksitet. Moderne detektionssystemer som Winston AI og Pangram anvender nu hybridtilgange, der kombinerer burstiness-analyse med dybe læringsmodeller trænet på forskellige menneske- og AI-genererede tekstprøver. Disse systemer analyserer flere sproglige dimensioner samtidigt: variation i sætningsstruktur, leksikalsk diversitet (ordforrådsrigdom), tegnsætningsmønstre, kontekstuel sammenhæng og semantisk overensstemmelse. Integrationen af burstiness i bredere detektionsrammer har øget nøjagtigheden betydeligt—Winston AI rapporterer 99,98% nøjagtighed i at skelne AI-genereret fra menneskeskabt indhold ved at analysere flere markører fremfor kun burstiness. Målingen forbliver dog værdifuld som én del af en samlet detektionsstrategi, især i kombination med analyse af perpleksitet, stilometriske mønstre og semantisk konsistens.
Forholdet mellem burstiness og læsbarhed er veldokumenteret i sprogforskning. Flesch Reading Ease og Flesch-Kincaid Grade Level-score, der måler tekstens tilgængelighed, korrelerer stærkt med burstiness-mønstre. Tekst med højere burstiness opnår typisk bedre læsbarhedsscore, fordi varieret sætningslængde forebygger mental træthed og fastholder læserens opmærksomhed. Når læserne møder en ensartet rytme af sætninger i samme størrelse, tilpasser hjernen sig et forudsigeligt mønster, hvilket kan føre til uengagement og ringere forståelse. Omvendt skaber høj burstiness en bølgeeffekt, der holder læseren mentalt engageret ved at variere den kognitive belastning—korte sætninger giver hurtig, letfordøjelig information, mens længere tillader udvikling af komplekse idéer og nuancer. Forskning fra Metrics Masters viser, at høj burstiness giver cirka 15-20% bedre hukommelsesretention end lav burstiness, da den varierede rytme hjælper med at lagre information mere effektivt i langtidshukommelsen. Dette princip gælder på tværs af indholdstyper: blogindlæg, akademiske artikler, marketingtekst og teknisk dokumentation drager alle fordel af strategisk burstiness. Forholdet er dog ikke lineært—overdreven burstiness, hvor variation prioriteres over klarhed, kan gøre teksten hakkende og svær at følge. Den optimale tilgang indebærer målrettet variation, hvor valg af sætningsstruktur tjener indholdets mening og forfatterens kommunikative intention, ikke blot for at øge en måling.
På trods af udbredt anvendelse i AI-detekteringssystemer har burstiness-baseret detektion markante begrænsninger, som forskere og praktikere bør kende. Pangram Labs har offentliggjort omfattende forskning, der påviser fem hovedmangler: For det første klassificeres tekst fra AI-træningsdatasæt fejlagtigt som AI-genereret, fordi modeller optimeres til at minimere perpleksitet på træningsdata; for det andet er burstiness-værdier relative til specifikke sprogmodeller, så forskellige modeller producerer forskellige perpleksitetsprofiler; for det tredje eksponerer lukkede kommercielle modeller som ChatGPT ikke token-sandsynligheder, hvilket umuliggør perpleksitetsberegning; for det fjerde bliver ikke-indfødte engelskskrivende uforholdsmæssigt markeret som AI-genereret på grund af deres mere ensartede sætningsstrukturer; og for det femte kan burstiness-baserede detektorer ikke selvforbedres iterativt med yderligere data. Stanford 2023-undersøgelsen af TOEFL-essays fandt, at cirka 26% af ikke-indfødt engelskskrivning fejlagtigt blev markeret som AI-genereret af perpleksitets- og burstiness-baserede detektorer, sammenlignet med kun 2% falske positiver for indfødt engelsk. Denne bias rejser alvorlige etiske bekymringer i undervisningssammenhænge, hvor AI-detektion bruges til at evaluere elevopgaver. Derudover udviser skabelonbaseret indhold i marketing, akademisk skrivning og teknisk dokumentation naturligt lav burstiness på grund af stilkrav og strukturelle konventioner, hvilket fører til falske positiver i disse domæner. Disse begrænsninger har ført til udviklingen af mere avancerede detektionstilgange, hvor burstiness ses som ét signal blandt mange frem for en endegyldig indikator for AI-generering.
Burstiness-mønstre varierer betydeligt på tværs af forskellige skrivegenrer og kontekster, hvilket afspejler de forskellige kommunikative formål og forventninger i hvert domæne. Akademisk skrivning, især i STEM-fag, har tendens til at udvise lavere burstiness, fordi forfatterne følger stramme stilguider og anvender ensartede strukturelle skabeloner for klarhed og præcision. Juridiske dokumenter, tekniske specifikationer og videnskabelige artikler prioriterer alle konsistens og forudsigelighed over stilistisk variation, hvilket resulterer i naturligt lav burstiness-score. Omvendt demonstrerer kreativ skrivning, journalistik og marketingtekst typisk høj burstiness, fordi disse genrer prioriterer læserengagement og følelsesmæssig effekt gennem varieret tempo og rytme. Skønlitteratur bruger især dramatiske skift i sætningslængde til at fremhæve, opbygge spænding og styre fortælletempo. Erhvervskommunikation ligger midt imellem—professionelle e-mails og rapporter opretholder moderat burstiness for at balancere klarhed og engagement. Flesch-Kincaid Grade Level viser, at akademisk skrivning til universitetsuddannede ofte bruger længere, mere komplekse sætninger, hvilket kan se ud som lavere burstiness; men variationen i ledsætningsstruktur og underordning skaber stadig meningsfuld burstiness. At forstå disse kontekstuelle variationer er afgørende for AI-detekteringssystemer, da de skal tage højde for genrespecifikke skrivekonventioner for at undgå falske positiver. En teknisk manual med ensartet lange sætninger bør ikke markeres som AI-genereret alene på grund af lav burstiness—den lave burstiness afspejler stilistisk hensigtsmæssighed for genren, ikke maskinskabt tekst.
Fremtiden for burstiness-analyse i AI-detektion bevæger sig mod mere sofistikerede, kontekstbevidste tilgange, der anerkender målingens begrænsninger, men udnytter dens indsigter. Efterhånden som store sprogmodeller bliver stadig mere avancerede, begynder de at inkorporere burstiness-variation i deres output, hvilket gør detektion baseret udelukkende på denne måling mindre pålidelig. Forskere udvikler adaptive detektionssystemer, der analyserer burstiness sammen med semantisk sammenhæng, faktuel nøjagtighed og kontekstuel hensigtsmæssighed. Fremkomsten af AI-humaniseringsværktøjer, der bevidst øger burstiness og andre menneskelignende træk, markerer en igangværende våbenkapløb mellem detektions- og undvigelsesteknologier. Eksperter forudsiger dog, at virkelig pålidelig AI-detektion i sidste ende vil afhænge af kryptografiske verifikationsmetoder og oprindelsessporing frem for kun sproglig analyse. For indholdsskabere og organisationer er den strategiske konsekvens klar: Frem for at se burstiness som en måling, man kan manipulere, bør forfattere fokusere på at udvikle autentiske, varierede skrivestile, der naturligt afspejler menneskelig kommunikation. AmICiteds overvågningsplatform repræsenterer en ny front på dette område, idet den sporer, hvordan brands optræder på tværs af AI-genererede svar og analyserer de sproglige karakteristika ved disse optrædener. I takt med at AI-systemer bliver mere udbredte i indholdsgenerering og -distribution, bliver forståelse af burstiness og relaterede målinger stadig vigtigere for at opretholde brandauthenticitet, sikre akademisk integritet og bevare skellet mellem menneskeskabt og maskinskabt indhold. Udviklingen mod multisignal-detektionstilgange betyder, at burstiness forbliver relevant som én komponent i omfattende AI-overvågningssystemer, selvom dens rolle bliver mere nuanceret og kontekstafhængig.
Burstiness og perpleksitet er komplementære målinger, der bruges i AI-detektion. Perpleksitet måler, hvor forudsigelige de enkelte ord er i en tekst, mens burstiness måler variationen i sætningsstruktur og længde på tværs af et helt dokument. Menneskelig skrivning udviser typisk højere perpleksitet (mere uforudsigelige ordvalg) og højere burstiness (mere varierede sætningsstrukturer), hvorimod AI-genereret tekst har tendens til at vise lavere værdier for begge målinger på grund af dens afhængighed af statistiske mønstre fra træningsdata.
Høj burstiness skaber en rytmisk flow, der øger læserens engagement og forståelse. Når forfattere veksler mellem korte, slagkraftige sætninger og længere, komplekse, fastholdes læserens interesse og ensformighed undgås. Forskning viser, at varieret sætningsstruktur forbedrer hukommelsesretention og gør indholdet mere autentisk og samtalende. Lav burstiness, karakteriseret ved ensartede sætningslængder, kan få tekst til at virke robotagtig og svær at følge, hvilket mindsker både læsbarhed og publikumsengagement.
Selvom burstiness bevidst kan øges gennem bevidst variation i sætningsstruktur, resulterer det ofte i unaturligt klingende tekst, som kan udløse andre detektionsmekanismer. Moderne AI-detektorer analyserer flere sproglige træk ud over burstiness, inklusiv semantisk sammenhæng, kontekstuel hensigtsmæssighed og stilometriske mønstre. Ægte burstiness opstår naturligt i menneskelig skrivning og afspejler forfatterens unikke stemme, mens tvungen variation typisk mangler den organiske kvalitet, der kendetegner ægte menneskeskabt indhold.
Ikke-indfødte engelsktalende udviser ofte lavere burstiness-score, fordi deres skrivemønstre afspejler et mere begrænset ordforråd og enklere sætningsopbygning. Sprogindlærere bruger typisk mere ensartede, forudsigelige sætningsstrukturer, mens de opbygger færdigheder, og undgår komplekse ledsætninger og varierede syntaktiske mønstre. Dette skaber en stilometrisk profil, der ligner AI-genereret tekst, hvilket fører til falske positiver i AI-detekteringssystemer. Forskning fra Stanford Universitys 2023-undersøgelse af TOEFL-essays bekræftede denne bias og fremhævede en kritisk begrænsning ved burstiness-baserede detektionsmetoder.
Store sprogmodeller trænes på enorme datasæt, hvor de lærer at forudsige det næste ord baseret på statistiske mønstre. Under træningen optimeres modellerne til at minimere perpleksitet på deres træningsdata, hvilket utilsigtet skaber ensartede sætningsstrukturer og forudsigelige ordsekvenser. Dette resulterer i konsekvent lav burstiness, fordi modellerne genererer tekst ved at vælge statistisk sandsynlige ordkombinationer frem for at bruge den varierede, spontane sætningskonstruktion, der kendetegner menneskelig skrivning. Modellernes afhængighed af sandsynlighedsfordelinger skaber en homogen stilistisk signatur.
AmICited sporer, hvordan brands og domæner optræder i AI-genererede svar på tværs af platforme som ChatGPT, Perplexity og Google AI Overviews. Forståelse af burstiness hjælper AmICiteds overvågningssystem med at skelne mellem ægte menneskeskabte citater og AI-genereret indhold, der nævner dit brand. Ved at analysere burstiness-mønstre sammen med andre sproglige markører kan AmICited give mere præcise indsigter i, om dit brand nævnes i ægte menneskeskabt indhold eller i AI-genererede svar, hvilket muliggør bedre brand management.
Forfattere kan forbedre burstiness organisk ved bevidst at variere deres sætningskonstruktion, samtidig med at de bevarer klarhed og formål. Teknikker inkluderer at veksle mellem enkle deklarative sætninger og komplekse sætninger med flere ledsætninger, bruge retoriske virkemidler som fragmenter og tankestreger for at fremhæve, samt variere afsnitslængder. Nøglen er at sikre, at variationen tjener indholdets betydning frem for blot at eksistere for variationens skyld. At læse teksten højt, studere forskellige skrivestile og revidere med fokus på rytme udvikler naturligt evnen til at skabe tekst med høj burstiness, der lyder autentisk og engagerende.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvad burstiness betyder i AI-genereret indhold, hvordan det adskiller sig fra menneskelige skrivevaner, og hvorfor det har betydning for AI-detektion og ind...
Fællesskabsdiskussion om burstiness i AI-indholdsdetektion – hvad betyder det, hvordan påvirker det AI-synlighed, og om indholdsskabere bør optimere for det....
Lær hvad informationsdensitet er, og hvordan det forbedrer sandsynligheden for AI-citation. Opdag praktiske teknikker til at optimere indhold for AI-systemer so...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.