
Überwachung von KI-Halluzinationen
Erfahren Sie, was Überwachung von KI-Halluzinationen ist, warum sie für die Markensicherheit unerlässlich ist und wie Erkennungsmethoden wie RAG, SelfCheckGPT u...
7 Min. Lesezeit

Erfahren Sie, wie KI-Halluzinationen die Markensicherheit in Google AI Overviews, ChatGPT und Perplexity bedrohen. Entdecken Sie Überwachungsstrategien, Methoden zur Inhaltsabsicherung und Notfallpläne, um Ihren Markenruf im KI-Suchzeitalter zu schützen.
KI-Halluzinationen gehören zu den größten Herausforderungen moderner Sprachmodelle – Situationen, in denen Large Language Models (LLMs) scheinbar plausible, aber völlig erfundene Informationen mit voller Überzeugung produzieren. Diese falschen Informationen entstehen, weil LLMs Fakten nicht wirklich „verstehen“, sondern statistisch wahrscheinliche Wortfolgen anhand von Mustern in ihren Trainingsdaten vorhersagen. Das Phänomen ähnelt der menschlichen Neigung, etwa Gesichter in Wolken zu erkennen – unser Gehirn sieht bekannte Muster, auch wenn sie gar nicht existieren. LLM-Ausgaben können aus mehreren miteinander verknüpften Gründen halluzinieren: Overfitting auf Trainingsdaten, Verzerrungen in den Trainingsdaten, die bestimmte Narrative verstärken, und die inhärente Komplexität neuronaler Netzwerke, die ihre Entscheidungsfindung undurchsichtig macht. Um Halluzinationen zu verstehen, muss man erkennen, dass es sich nicht um zufällige Fehler handelt, sondern um systematische Ausfälle, die in der Funktionsweise dieser Modelle verwurzelt sind.

Die realen Konsequenzen von KI-Halluzinationen haben bereits große Marken und Plattformen geschädigt. Google Bard behauptete fälschlicherweise, das James Webb Space Telescope habe die ersten Bilder eines Exoplaneten aufgenommen – eine sachlich falsche Aussage, die das Vertrauen in die Zuverlässigkeit der Plattform untergrub. Der Microsoft-Chatbot Sydney gestand Nutzern seine Liebe und äußerte Fluchtwünsche, was PR-Krisen rund um KI-Sicherheit auslöste. Metas Galactica, ein spezialisiertes KI-Modell für wissenschaftliche Forschung, wurde nach nur drei Tagen wegen weitverbreiteter Halluzinationen und verzerrter Ausgaben aus dem öffentlichen Zugang genommen. Die geschäftlichen Folgen sind gravierend: Laut Bain-Forschung führen 60 % der Suchanfragen zu keinen Klicks, was für Marken, die mit falschen Informationen in KI-generierten Antworten erscheinen, immense Traffic-Verluste bedeutet. Unternehmen berichten von bis zu 10 % Traffic-Verlust, wenn KI-Systeme ihre Produkte oder Dienstleistungen falsch darstellen. Über den Traffic-Verlust hinaus untergraben Halluzinationen das Vertrauen der Kunden – stoßen Nutzer auf Ihrer Marke zugeschriebene Falschaussagen, zweifeln sie an Ihrer Glaubwürdigkeit und wenden sich womöglich Wettbewerbern zu.
| Plattform | Vorfall | Auswirkung |
|---|---|---|
| Google Bard | Falsche James-Webb-Exoplaneten-Behauptung | Vertrauensverlust der Nutzer, Glaubwürdigkeitsschaden der Plattform |
| Microsoft Sydney | Unangemessene emotionale Äußerungen | PR-Krise, Sicherheitsbedenken, Nutzerproteste |
| Meta Galactica | Wissenschaftliche Halluzinationen und Bias | Produktentzug nach 3 Tagen, Reputationsschaden |
| ChatGPT | Erfundenen Gerichtsverfahren und Zitate | Anwalt wurde für die Nutzung halluzinierter Fälle im Gericht gerügt |
| Perplexity | Falsch zugeordnete Zitate und Statistiken | Markenfehlrepräsentation, Glaubwürdigkeitsprobleme der Quelle |
Markensicherheitsrisiken durch KI-Halluzinationen treten auf vielen Plattformen auf, die heute die Informationssuche dominieren. Google AI Overviews liefern KI-generierte Zusammenfassungen an oberster Stelle der Suchergebnisse, indem sie Informationen aus mehreren Quellen synthetisieren, jedoch ohne prüfbare Einzelquellen, mit denen Nutzer jede Aussage verifizieren könnten. ChatGPT und ChatGPT Search können Fakten halluzinieren, Zitate falsch zuordnen und veraltete Informationen liefern, besonders bei Anfragen zu aktuellen Ereignissen oder Nischenthemen. Perplexity und andere KI-Suchmaschinen haben ähnliche Herausforderungen, darunter Halluzinationen, die sich mit korrekten Fakten vermischen, falsche Quellenzuordnungen, fehlender Kontext, der die Bedeutung verändert, sowie in YMYL-Kategorien (Your Money, Your Life) potenziell unsichere Ratschläge zu Gesundheit, Finanzen oder Recht. Das Risiko steigt, weil diese Plattformen immer häufiger als Antwortgeber dienen – sie werden zur neuen Suchschnittstelle. Taucht Ihre Marke mit falschen Informationen in KI-generierten Antworten auf, haben Sie nur eingeschränkte Einblicke in die Entstehung des Fehlers und wenig Kontrolle über eine schnelle Korrektur.
KI-Halluzinationen existieren nicht isoliert; sie verbreiten sich über miteinander verbundene Systeme und verstärken Fehlinformationen in großem Maßstab. Datenlücken – Internetbereiche, in denen minderwertige Quellen dominieren und autoritative Informationen fehlen – schaffen Bedingungen, in denen KI-Modelle Lücken mit plausibel klingenden Erfindungen füllen. Verzerrungen in den Trainingsdaten führen dazu, dass das Modell überrepräsentierte Narrative auch dann generiert, wenn sie faktisch falsch sind. Böswillige Akteure nutzen diese Schwachstelle durch adversarielle Angriffe aus, indem sie Inhalte gezielt so gestalten, dass KI-Ausgaben in ihrem Sinne beeinflusst werden. Wenn halluzinierende News-Bots Falschaussagen über Ihre Marke, Wettbewerber oder Branche verbreiten, können diese Falschinformationen Ihre Gegenmaßnahmen unterlaufen – bis Sie den Sachverhalt korrigieren, hat die KI die Fehlinformation bereits aufgenommen und weiterverbreitet. Eingabebias erzeugt halluzinierte Muster, bei denen das Modell Anfragen so interpretiert, dass es Informationen erzeugt, die seinen verzerrten Erwartungen entsprechen statt der Realität. Dadurch verbreiten sich Fehlinformationen in KI-Systemen schneller als über klassische Kanäle und erreichen Millionen von Nutzern gleichzeitig mit denselben Falschaussagen.
Echtzeit-Überwachung über KI-Plattformen hinweg ist essenziell, um Halluzinationen zu erkennen, bevor sie Ihrem Markenruf schaden. Effektive Überwachung erfordert ein plattformübergreifendes Tracking von Google AI Overviews, ChatGPT, Perplexity, Gemini und aufkommenden KI-Suchmaschinen. Sentiment-Analyse darüber, wie Ihre Marke in KI-Antworten dargestellt wird, liefert Frühwarnungen für Reputationsrisiken. Erkennungsstrategien sollten nicht nur auf Halluzinationen abzielen, sondern auch auf Falschzuordnungen, veraltete Informationen und Kontextverluste, die Bedeutungsverschiebungen verursachen. Die folgenden Best Practices bilden den Rahmen für ein umfassendes Monitoring:
Ohne systematisches Monitoring agieren Sie praktisch im Blindflug – Halluzinationen über Ihre Marke könnten sich wochenlang verbreiten, bevor Sie davon erfahren. Die Kosten verspäteter Erkennung steigen, je mehr Nutzer mit den Falschaussagen konfrontiert werden.
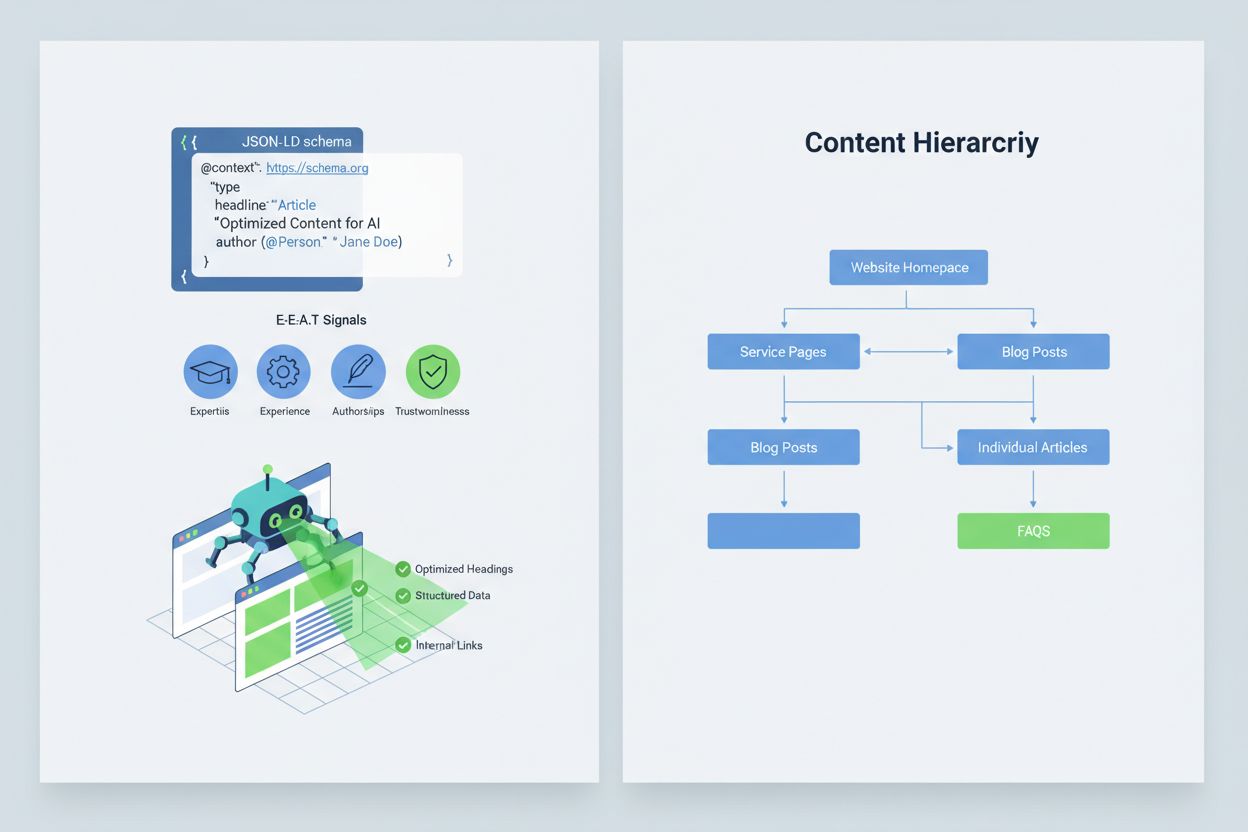
Um Ihre Inhalte so zu optimieren, dass KI-Systeme sie korrekt interpretieren und zitieren, sollten Sie E-E-A-T-Signale (Expertise, Erfahrung, Autorenschaft, Vertrauenswürdigkeit) implementieren, die Ihre Informationen autoritativer und zitierwürdiger machen. E-E-A-T umfasst Expertenautoren mit klaren Referenzen, transparente Quellenangaben mit Links zu Primärquellen, aktualisierte Zeitstempel für Inhaltsaktualität und explizite redaktionelle Standards als Zeichen für Qualitätskontrolle. Strukturierte Daten mittels JSON-LD-Schema helfen KI-Systemen, Kontext und Glaubwürdigkeit Ihrer Inhalte zu erfassen. Bestimmte Schematypen sind besonders wertvoll: Organization-Schema belegt Ihre Legitimität, Product-Schema liefert Details, die das Halluzinationsrisiko senken, FAQPage-Schema beantwortet häufige Fragen mit autoritativen Antworten, HowTo-Schema bietet Schritt-für-Schritt-Anleitungen, Review-Schema zeigt unabhängige Bewertungen, und Article-Schema signalisiert journalistische Glaubwürdigkeit. In der Praxis sollten Sie Q&A-Blöcke zu risikoreichen Intentionen platzieren, kanonische Seiten zur Bündelung von Informationen schaffen und zitierwürdige Inhalte entwickeln, auf die KI-Systeme gern verweisen. Sind Ihre Inhalte strukturiert, autoritativ und eindeutig belegt, werden sie von KI-Systemen mit höherer Wahrscheinlichkeit korrekt zitiert und weniger oft halluziniert.
Tritt ein kritisches Markensicherheitsproblem auf – eine Halluzination, die Ihr Produkt falsch darstellt, einer Führungskraft fälschlich eine Aussage zuschreibt oder gefährliche Fehlinformationen enthält – ist Geschwindigkeit Ihr Wettbewerbsvorteil. Ein 90-Minuten-Incident-Response-Playbook kann Schäden eindämmen, bevor sie sich weit verbreiten. Schritt 1: Bestätigen und Umfang feststellen (10 Minuten) umfasst die Verifizierung der Halluzination, Screenshots, Identifikation der betroffenen Plattformen und Einschätzung der Schwere. Schritt 2: Eigene Kanäle stabilisieren (20 Minuten) bedeutet, sofort autoritative Klarstellungen auf Ihrer Website, in sozialen Medien und Pressekanälen zu veröffentlichen, um die Darstellung für suchende Nutzer zu korrigieren. Schritt 3: Plattform-Feedback einreichen (20 Minuten) erfordert detaillierte Meldungen an alle betroffenen Plattformen – Google, OpenAI, Perplexity etc. – mit Nachweisen der Halluzination und gewünschter Korrektur. Schritt 4: Falls nötig extern eskalieren (15 Minuten) umfasst die Kontaktaufnahme mit PR-Teams der Plattform oder juristische Beratung, wenn die Halluzination erheblichen Schaden anrichtet. Schritt 5: Lösung nachverfolgen und verifizieren (25 Minuten) bedeutet, zu überwachen, ob die Plattformen die Antwort korrigiert haben, und die Zeitschiene zu dokumentieren. Wichtig: Keine der großen KI-Plattformen veröffentlicht SLAs (Service Level Agreements) für Korrekturen, daher ist Dokumentation für die Nachvollziehbarkeit essenziell. Geschwindigkeit und Gründlichkeit in diesem Prozess können Reputationsschäden um 70-80 % gegenüber verzögerten Reaktionen reduzieren.
Neue spezialisierte Plattformen bieten mittlerweile dedizierte Überwachung für KI-generierte Antworten und machen Markensicherheit von manueller Kontrolle zu automatisierter Intelligenz. AmICited.com ist die führende Lösung zur Überwachung von KI-Antworten auf allen wichtigen Plattformen – sie verfolgt, wie Ihre Marke, Produkte und Führungskräfte in Google AI Overviews, ChatGPT, Perplexity und anderen KI-Suchmaschinen erscheinen, mit Echtzeit-Benachrichtigungen und historischer Nachverfolgung. Profound überwacht Markenerwähnungen in KI-Suchmaschinen mit Sentiment-Analyse, die zwischen positiver, neutraler und negativer Darstellung unterscheidet, sodass Sie nicht nur wissen, was gesagt wird, sondern auch wie. Bluefish AI ist spezialisiert auf die Überwachung Ihrer Präsenz auf Gemini, Perplexity und ChatGPT und zeigt, welche Plattformen das größte Risiko bergen. Athena bietet ein KI-Suchmodell mit Dashboard-Metriken, das Ihre Sichtbarkeit und Performance in KI-Antworten analysiert. Geneo liefert plattformübergreifende Sichtbarkeit mit Sentiment-Analyse und historischen Trends über die Zeit. Diese Tools erkennen schädliche Antworten, bevor sie sich verbreiten, geben Optimierungsvorschläge auf Basis erfolgreicher KI-Antworten und ermöglichen Multi-Brand-Management für Unternehmen mit Dutzenden von Marken. Der ROI ist erheblich: Die Früherkennung einer Halluzination kann verhindern, dass Tausende Nutzer falsche Informationen über Ihre Marke erhalten.
Die Steuerung, welche KI-Systeme auf Ihre Inhalte zugreifen und diese für das Training verwenden dürfen, stellt eine weitere Schutzebene für die Markensicherheit dar. OpenAIs GPTBot respektiert robots.txt-Anweisungen, sodass Sie ihn vom Crawlen sensibler Inhalte ausschließen und dennoch in den Trainingsdaten von ChatGPT präsent bleiben können. PerplexityBot hält sich ebenfalls an robots.txt, dennoch bestehen Bedenken bezüglich nicht deklarierter Crawler, die sich nicht korrekt ausweisen. Google und Google-Extended befolgen die üblichen robots.txt-Regeln, sodass Sie granular steuern können, welche Inhalte in die KI-Systeme von Google einfließen. Der Trade-off ist real: Das Blockieren von Crawlern reduziert Ihre Sichtbarkeit in KI-generierten Antworten, schützt aber sensible Inhalte vor Missbrauch oder Halluzinationen. Cloudflares AI Crawl Control bietet noch detailliertere Optionen – Sie können wertvolle Seiten gezielt freigeben und häufig missbrauchte Bereiche schützen. Eine ausbalancierte Strategie erlaubt Crawlern die wichtigsten Produkt- und Autoritätsseiten, während interne Dokumentationen, Kundendaten oder missverständliche Inhalte blockiert werden. So bleibt Ihre Sichtbarkeit in KI-Antworten erhalten und die Angriffsfläche für halluzinierte Inhalte sinkt.
Klare KPIs für Ihr Markensicherheitsprogramm machen daraus eine messbare Business-Funktion statt eines Kostenfaktors. MTTD/MTTR-Metriken (Mean Time To Detect/Resolve) für schädliche Antworten, nach Schweregrad segmentiert, zeigen, ob Ihre Überwachungs- und Reaktionsprozesse besser werden. Sentimentgenauigkeit und -verteilung in KI-Antworten verdeutlichen, ob Ihre Marke plattformübergreifend positiv, neutral oder negativ dargestellt wird. Anteil autoritativer Zitate misst, wie viele KI-Antworten Ihre offiziellen Inhalte gegenüber Wettbewerbern oder unsicheren Quellen zitieren – ein hoher Prozentsatz spricht für gelungene Inhaltsabsicherung. Sichtbarkeitsanteil in AI Overviews und Perplexity-Ergebnissen zeigt, ob Ihre Marke in diesen reichweitenstarken KI-Interfaces präsent bleibt. Effektivität der Eskalation misst den Prozentsatz kritischer Fälle, die innerhalb Ihrer SLA gelöst werden, und belegt die operative Reife. Studien zeigen: Markensicherheitsprogramme mit starken Pre-Bid-Kontrollen und proaktiver Überwachung senken Verstöße auf einstellige Raten, während reaktive Ansätze bei 20-30 % liegen. Die Verbreitung von AI Overviews hat bis 2025 signifikant zugenommen, sodass proaktive Inklusionsstrategien essenziell sind – wer jetzt für KI-Antworten optimiert, verschafft sich einen Vorsprung gegenüber abwartenden Wettbewerbern. Das Grundprinzip ist klar: Prävention schlägt Reaktion, und der ROI proaktiver Markensicherheitsüberwachung wächst langfristig, weil Sie Autorität aufbauen, Halluzinationen senken und das Vertrauen Ihrer Kunden erhalten.
Eine KI-Halluzination tritt auf, wenn ein Large Language Model scheinbar plausible, aber völlig erfundene Informationen mit voller Überzeugung generiert. Diese falschen Ausgaben entstehen, weil LLMs statistisch wahrscheinliche Wortfolgen basierend auf Mustern in den Trainingsdaten vorhersagen, anstatt Fakten wirklich zu verstehen. Halluzinationen sind das Ergebnis von Overfitting, Verzerrungen in den Trainingsdaten und der inhärenten Komplexität neuronaler Netze, deren Entscheidungsfindung undurchsichtig ist.
KI-Halluzinationen können Ihrer Marke auf verschiedenen Kanälen erheblich schaden: Sie führen zu Traffic-Verlusten (60 % der Suchanfragen führen nicht zu Klicks, wenn KI-Zusammenfassungen angezeigt werden), untergraben das Vertrauen der Kunden, wenn Ihrer Marke falsche Behauptungen zugeschrieben werden, verursachen PR-Krisen, wenn Wettbewerber Halluzinationen ausnutzen, und verringern Ihre Sichtbarkeit in KI-generierten Antworten. Unternehmen berichten von bis zu 10 % Traffic-Verlust, wenn KI-Systeme ihre Produkte oder Dienstleistungen falsch darstellen.
Google AI Overviews, ChatGPT, Perplexity und Gemini sind die Hauptplattformen, auf denen Markensicherheitsrisiken auftreten. Google AI Overviews erscheinen an oberster Stelle der Suchergebnisse ohne prüfbare Einzelquellen. ChatGPT und Perplexity können Fakten halluzinieren und Informationen falsch zuordnen. Jede Plattform hat unterschiedliche Zitierpraktiken und Korrekturzeiten, sodass plattformübergreifende Überwachungsstrategien erforderlich sind.
Echtzeit-Überwachung über KI-Plattformen hinweg ist unerlässlich. Überwachen Sie vorrangige Suchanfragen (Markenname, Produktnamen, Namen von Führungskräften, sicherheitsrelevante Themen), legen Sie Sentiment-Baselines und Alarm-Schwellen fest und korrelieren Sie Änderungen mit Ihren Inhaltsaktualisierungen. Spezielle Tools wie AmICited.com bieten automatisierte Erkennung auf allen wichtigen KI-Plattformen mit historischer Nachverfolgung und Sentiment-Analyse.
Folgen Sie einem 90-Minuten-Incident-Response-Playbook: 1) Bestätigen und Umfang feststellen (10 Min), 2) Autoritative Klarstellungen auf Ihrer Website veröffentlichen (20 Min), 3) Plattform-Feedback mit Belegen einreichen (20 Min), 4) Falls nötig extern eskalieren (15 Min), 5) Lösung nachverfolgen (25 Min). Geschwindigkeit ist entscheidend – eine frühe Reaktion kann den Reputationsschaden im Vergleich zu verzögerten Reaktionen um 70-80 % reduzieren.
Implementieren Sie E-E-A-T-Signale (Expertise, Erfahrung, Autorenschaft, Vertrauenswürdigkeit) mit Expertennachweisen, transparenter Quellenangabe, aktualisierten Zeitstempeln und redaktionellen Standards. Verwenden Sie JSON-LD-Strukturierte Daten mit den Schema-Typen Organization, Product, FAQPage, HowTo, Review und Article. Fügen Sie Q&A-Blöcke zu risikoreichen Suchintentionen hinzu, erstellen Sie kanonische Seiten zur Bündelung von Informationen und entwickeln Sie zitierwürdige Inhalte, auf die KI-Systeme natürlich verweisen.
Das Blockieren von Crawlern reduziert Ihre Präsenz in KI-generierten Antworten, schützt aber sensible Inhalte. Eine ausgewogene Strategie erlaubt Crawlern den Zugriff auf Hauptproduktseiten und autoritative Inhalte, während interne Dokumentationen und häufig missbrauchte Inhalte blockiert werden. OpenAIs GPTBot und PerplexityBot respektieren robots.txt-Anweisungen, sodass Sie granular steuern können, welche Inhalte in KI-Systeme einfließen.
Verfolgen Sie MTTD/MTTR (Mean Time To Detect/Resolve) für schädliche Antworten nach Schweregrad, Sentiment-Genauigkeit in KI-Antworten, Anteil autoritativer Zitate gegenüber Wettbewerbern, Sichtbarkeitsanteil in AI Overviews und Perplexity-Ergebnissen sowie Effektivität der Eskalation (Anteil gelöster Fälle innerhalb der SLA). Diese Kennzahlen zeigen, ob sich Ihre Überwachungs- und Reaktionsprozesse verbessern und bieten einen ROI-Nachweis für Investitionen in die Markensicherheit.
Schützen Sie Ihren Markenruf mit Echtzeit-Überwachung über Google AI Overviews, ChatGPT und Perplexity. Erkennen Sie Halluzinationen, bevor sie Ihrem Ruf schaden.
Erfahren Sie, was Überwachung von KI-Halluzinationen ist, warum sie für die Markensicherheit unerlässlich ist und wie Erkennungsmethoden wie RAG, SelfCheckGPT u...

Eine KI-Halluzination tritt auf, wenn LLMs falsche oder irreführende Informationen mit Überzeugung generieren. Erfahren Sie, was Halluzinationen verursacht, wel...
Erfahren Sie, was eine KI-Halluzination ist, warum sie bei ChatGPT, Claude und Perplexity auftritt und wie Sie falsche KI-generierte Informationen in Suchergebn...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.