
Wie man doppelten Content für KI-Suchmaschinen handhabt
Erfahren Sie, wie Sie doppelten Content beim Einsatz von KI-Tools verwalten und vermeiden. Entdecken Sie kanonische Tags, Weiterleitungen, Erkennungstools und B...
12 Min. Lesezeit

Erfahren Sie, wie kanonische URLs Duplicate-Content-Probleme in KI-Suchsystemen verhindern. Entdecken Sie Best Practices für die Implementierung von Canonicals, um die KI-Sichtbarkeit zu verbessern und eine korrekte Inhaltszuordnung sicherzustellen.
Große Sprachmodelle und KI-Suchsysteme verwenden ausgeklügelte Clustering-Algorithmen, um nahezu identische URLs zu erkennen und zu gruppieren. Sie behandeln mehrere Versionen desselben Inhalts als eine einzige Entität für Ranking- und Zitatzwecke. Wenn KI-Systeme Duplicate Content entdecken, müssen sie entscheiden, welche Version sie priorisieren – eine Entscheidung, die direkt beeinflusst, welche URL Sichtbarkeit, Autoritätssignale und Benutzerzuordnung erhält. Ein kritisches Problem entsteht, wenn die KI die falsche Version auswählt: Wenn Ihre kanonische URL auf die bevorzugte Seite zeigt, das KI-System jedoch einen minderwertigen Duplikat-Content clustert und bewertet, verliert Ihr Inhalt an Sichtbarkeit und Zitatwürdigkeit. Intentsignale werden über Duplikate verteilt, fragmentieren die Autorität, die sich eigentlich auf eine URL konzentrieren sollte, und jede Duplikat-Version erhält schwächere Rankingsignale, als wenn alle Autorität auf der kanonischen Version vereint worden wäre.
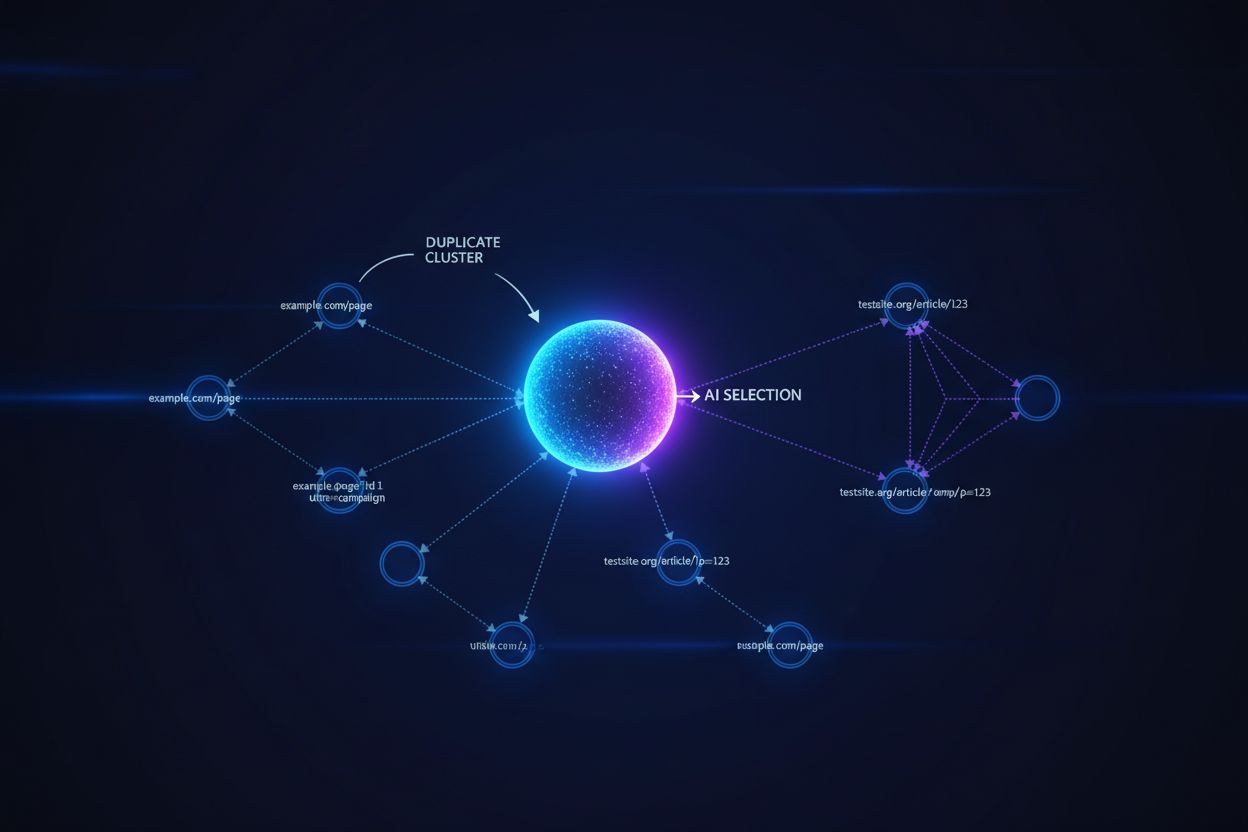
Kanonische Tags dienen als explizite Signale für KI-Systeme, welche Version von Duplicate Content als maßgeblich betrachtet werden soll. Sie beeinflussen direkt, ob Ihre bevorzugte URL in KI-generierten Antworten erscheint und korrekt zugeordnet wird. Ohne Canonical-Tags müssen KI-Systeme ihre eigenen Cluster-Entscheidungen auf Basis von Inhaltsähnlichkeiten, Linkmustern und Aktualitätssignalen treffen – was häufig dazu führt, dass die falsche Version als Canonical-Quelle ausgewählt wird. Wenn Duplicate Content ohne korrekte Canonical-Implementierung existiert, kann es sein, dass KI-Antworten stattdessen eine syndizierte Version, eine zwischengespeicherte Kopie oder eine minderwertige Variante anstelle Ihres Originalinhalts zitieren, wodurch Ihre Sichtbarkeit über mehrere URLs fragmentiert wird. Kanonische URLs sorgen dafür, dass, wenn KI-Systeme Ihre Inhalte auf verschiedenen Domains, über unterschiedliche Parameter oder Versionen hinweg entdecken, sie verstehen, welche einzelne URL die Anerkennung erhalten und in Antworten erscheinen soll.
| Szenario | Ohne Canonical | Mit Canonical |
|---|---|---|
| Einfluss auf KI | KI clustert Duplikate eigenständig; kann die falsche Version fürs Ranking auswählen | KI erkennt eine maßgebliche Quelle; alle Signale werden auf die kanonische URL konsolidiert |
| Zitatzuschreibung | Zuordnung verteilt sich auf mehrere URLs; geringere Autorität pro URL | Alle Zitate und Autorität fließen zur kanonischen URL; stärkere Sichtbarkeit |
| Ergebnis | Inhalt erscheint in KI-Antworten, aber die falsche URL erhält die Anerkennung; fragmentierte Sichtbarkeit | Bevorzugte URL erscheint in KI-Antworten mit konsolidierten Autoritätssignalen |
Canonical-Tags und Weiterleitungen erfüllen unterschiedliche Aufgaben beim Management von Duplicate Content für KI-Systeme: Canonical-Tags teilen Suchmaschinen und KI mit, welche Version bevorzugt wird, während beide URLs zugänglich bleiben, während Weiterleitungen Nutzer und Crawler dauerhaft von einer URL zu einer anderen schicken. Weiterleitungen (301 für dauerhaft, 302 für temporär) sind stärkere Signale, da sie alle Autorität auf eine einzige URL konsolidieren und das Duplikat vollständig aus dem Web entfernen – ideal, wenn Sie eine URL dauerhaft außer Betrieb nehmen oder Domains konsolidieren. Canonical-Tags sind vorzuziehen, wenn Sie mehrere URLs aus geschäftlichen Gründen beibehalten müssen – etwa Tracking-Parameter für Analysen, Legacy-URLs für Benutzer-Lesezeichen oder verschiedene Versionen für unterschiedliche Zielgruppen – und dennoch KI-Systemen signalisieren wollen, welche Version maßgeblich ist. Verwenden Sie Weiterleitungen bei Domainkonsolidierungen nach Migrationen, beim Entfernen veralteter Versionen oder beim Eliminieren von Parameter-Varianten ohne eigenen Zweck. Verwenden Sie Canonical-Tags, wenn Sie mehrere URLs beibehalten müssen, aber Duplicate-Content-Strafen vermeiden und sicherstellen wollen, dass KI-Systeme Ihre bevorzugte Version verstehen.
Wichtige Unterschiede zwischen Canonicals und Weiterleitungen:
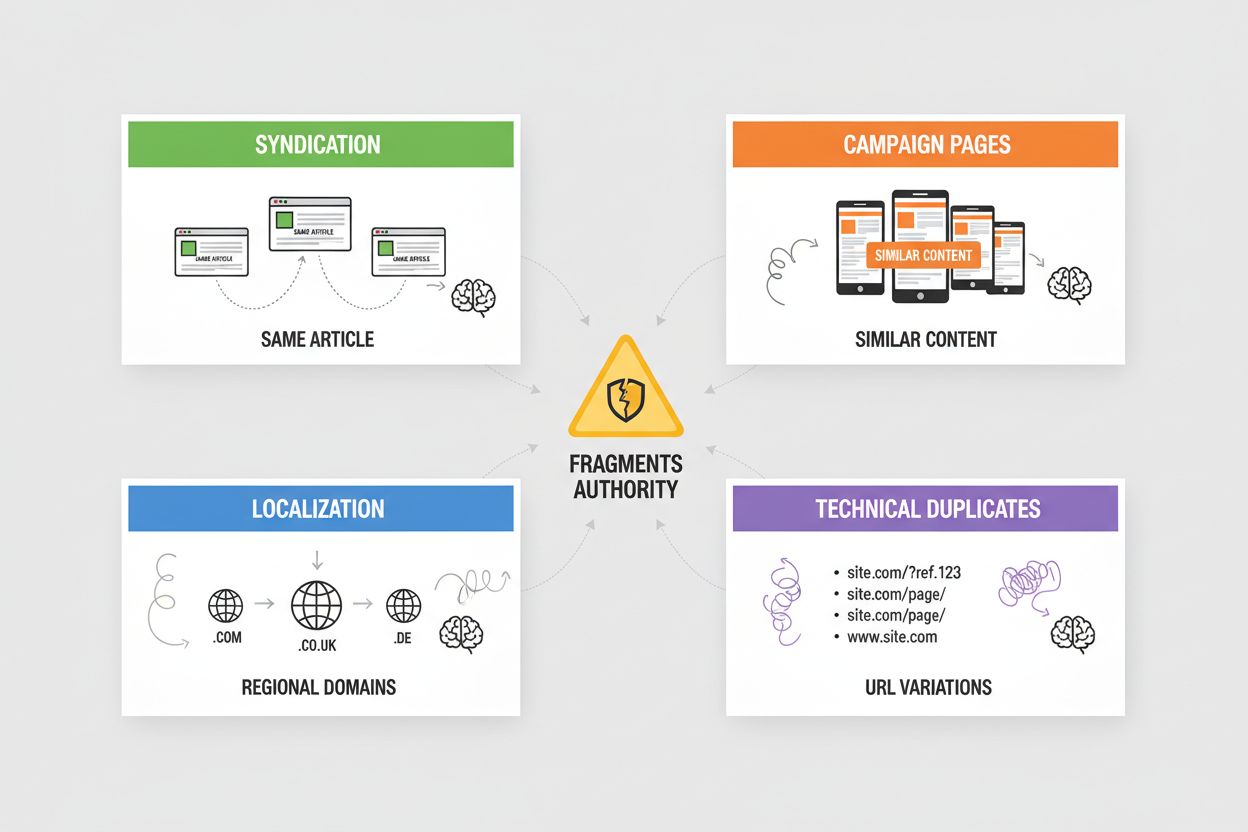
Syndizierung erzeugt weit verbreiteten Duplicate Content, wenn Ihre Artikel auf Partnerseiten, News-Aggregatoren oder Content-Netzwerken erneut veröffentlicht werden – KI-Systeme müssen entscheiden, ob sie die Originalquelle oder die syndizierte Version anerkennen, und wählen häufig die zuerst gecrawlte Version. Kampagnenseiten erzeugen Duplikate, wenn Sie mehrere Landingpages mit identischen oder nahezu identischen Inhalten für verschiedene Marketingkanäle, UTM-Parameter oder A/B-Tests erstellen, wodurch KI-Systeme die Autorität auf Varianten fragmentieren, die eigentlich konsolidiert werden sollten. Lokalisierung und Internationalisierung erzeugen Duplikate, wenn Sie ähnliche Inhalte auf regionalen Domains (example.com, example.co.uk, example.de) oder Sprachversionen anbieten – hier sind hreflang-Tags und Canonical-Implementierung nötig, um zu verhindern, dass KI-Systeme diese als Duplicate Content statt als beabsichtigte Varianten interpretieren. Technische Duplikate entstehen durch Sitzungs-IDs, Tracking-Parameter, druckerfreundliche Versionen und URL-Varianten (www vs. non-www, http vs. https, abschließende Schrägstriche), die mehrere URLs mit identischem Inhalt erzeugen – KI-Systeme sehen dies als Duplikate und müssen entscheiden, welche Version priorisiert wird. Jede dieser Situationen verdünnt die Autorität, die sich eigentlich auf Ihre bevorzugte URL konzentrieren sollte, verringert Ihre Sichtbarkeit in KI-generierten Antworten und führt dazu, dass Zitatzuschreibung auf mehrere Versionen verteilt wird.
Verwenden Sie immer absolute URLs in Ihren Canonical-Tags statt relativer URLs, damit KI-Systeme und Suchmaschinen das Ziel eindeutig identifizieren können – unabhängig davon, wo das Tag erscheint. Fügen Sie selbstreferenzierende Canonicals auf Ihren bevorzugten Seiten ein – auch Seiten ohne Duplikate sollten sich selbst als Canonical referenzieren, damit KI-Systeme nicht aufgrund von Linkmustern oder Inhaltsähnlichkeit Canonicals ableiten. Platzieren Sie Canonical-Tags im <head>-Bereich Ihres HTML-Dokuments und verwenden Sie für nicht-HTML-Inhalte (PDFs, Bilder) Canonicals via HTTP-Header, damit KI-Crawler Ihre Präferenz unabhängig vom Inhaltstyp erkennen.
<!-- Korrekte Canonical-Implementierung im HTML-Head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Fügen Sie kanonische URLs in Ihre XML-Sitemaps ein, um zu unterstreichen, welche Versionen maßgeblich sind, und kombinieren Sie Canonicals mit hreflang-Tags beim Management internationaler oder lokalisierter Inhalte, um zu verhindern, dass KI-Systeme regionale Varianten als Duplicate Content einstufen. Vermeiden Sie typische Fehler: Erstellen Sie niemals Canonical-Ketten (A→B→C), verweisen Sie nicht auf noindexierte Seiten und verwenden Sie Canonicals nicht zur Manipulation von Rankings, indem Sie auf nicht verwandte Inhalte zeigen. Überwachen Sie Ihre Canonical-Implementierung mit Tools wie Google Search Console, Bing Webmaster Tools und AmICited.com, um zu prüfen, ob KI-Systeme Ihre bevorzugten URLs erkennen und Inhalte korrekt zuordnen.
<!-- Korrekte Implementierung mit hreflang für internationale Inhalte -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Prüfen Sie Ihre kanonischen URLs, indem Sie Ihre gesamte Website mit Tools wie Screaming Frog, SEMrush oder Ahrefs crawlen, um Seiten mit fehlenden Canonicals, fehlerhaften Canonical-Ketten oder Canonicals, die auf noindexierte Seiten verweisen, zu identifizieren – solche Probleme verhindern, dass KI-Systeme die Autorität korrekt konsolidieren. Verwenden Sie den Coverage-Bericht der Google Search Console, um Seiten mit Duplicate-Content-Problemen zu finden und zu überprüfen, ob Google Ihre Canonical-Präferenzen erkennt; vergleichen Sie anschließend mit Bing Webmaster Tools, um Konsistenz über KI-Suchsysteme hinweg sicherzustellen. Implementieren Sie IndexNow, um Suchmaschinen und KI-Crawler sofort zu benachrichtigen, wenn Sie Canonical-Tags hinzufügen, aktualisieren oder entfernen, und beschleunigen Sie die Entdeckung Ihrer Canonical-Präferenzen, anstatt auf natürliche Crawl-Zyklen zu warten. Überwachen Sie KI-Zitate mit Tools wie AmICited.com und manuellen Suchen in ChatGPT, Claude und Perplexity, um zu prüfen, ob Ihre bevorzugten URLs in KI-generierten Antworten zitiert werden – falls stattdessen Duplikate genannt werden, überprüfen Sie Ihre Canonical-Implementierung und stellen Sie sicher, dass die Tags korrekt formatiert und platziert sind. Prüfen Sie regelmäßig auf neuen Duplicate Content, der durch Syndizierungspartnerschaften, Kampagnenstarts oder technische Änderungen entsteht, und implementieren Sie Canonicals proaktiv, um eine konsistente KI-Sichtbarkeit aufrechtzuerhalten.
Eine kanonische URL ist die bevorzugte Version einer Seite, die Sie möchten, dass Suchmaschinen und KI-Systeme als maßgeblich erkennen. Sie ist für die KI-Suche wichtig, da LLMs nahezu identische URLs gruppieren und eine Version auswählen, die das Set repräsentiert. Ohne eine ordnungsgemäße Canonical-Implementierung kann es sein, dass KI-Systeme die falsche Version Ihrer Inhalte zitieren, wodurch Ihre Sichtbarkeit und Zuordnung auf mehrere URLs fragmentiert wird.
KI-Systeme verwenden Clustering-Algorithmen, um nahezu identische URLs zu einer einzigen Entität zu gruppieren, und wählen dann eine Version aus, die den gesamten Cluster repräsentiert. Das unterscheidet sich von herkömmlichen Suchmaschinen, da KI-Antworten eine einzige Quell-URL für die Zuordnung benötigen. Wenn Ihr Canonical nicht ordnungsgemäß implementiert ist, kann die KI stattdessen eine syndizierte Version, einen zwischengespeicherten Inhalt oder eine minderwertige Variante auswählen, anstatt Ihrer bevorzugten URL.
Verwenden Sie Canonical-Tags, wenn Sie aus geschäftlichen Gründen mehrere URLs beibehalten müssen (Tracking-Parameter, Legacy-URLs, verschiedene Zielgruppen), während Sie KI-Systemen Ihre Präferenz signalisieren. Verwenden Sie Weiterleitungen, wenn Sie eine URL dauerhaft außer Betrieb nehmen, Domains konsolidieren oder Parameter-Varianten entfernen, die keinen Zweck erfüllen. Weiterleitungen sind stärkere Signale, da sie die gesamte Autorität konsolidieren, während Canonicals die Autorität verteilen, aber eine Präferenz signalisieren.
Die häufigsten Probleme sind: Syndizierung (wiederveröffentlichte Artikel auf Partnerseiten), Kampagnenseiten (mehrere Landingpages mit identischen Inhalten), Lokalisierung (ähnliche Inhalte auf regionalen Domains) und technische Duplikate (URL-Parameter, Sitzungs-IDs, abschließende Schrägstriche). Jedes dieser Probleme fragmentiert die Autorität auf mehrere URLs, was die Sichtbarkeit in KI-generierten Antworten reduziert.
Verwenden Sie immer absolute URLs (https://example.com/page, nicht /page), platzieren Sie Canonical-Tags im HTML-Head-Bereich, fügen Sie selbstreferenzierende Canonicals auf allen Seiten ein und vermeiden Sie Canonical-Ketten (A→B→C). Für nicht-HTML-Inhalte wie PDFs verwenden Sie HTTP-Header. Fügen Sie Canonicals in Ihre XML-Sitemap ein und kombinieren Sie sie mit hreflang-Tags für internationale Inhalte.
Verwenden Sie die Google Search Console und Bing Webmaster Tools, um die Erkennung der Canonicals zu überprüfen, überwachen Sie KI-Zitate mit AmICited.com und führen Sie manuelle Suchen in ChatGPT/Claude/Perplexity durch, und überprüfen Sie Ihre Website mit Crawling-Tools wie Screaming Frog oder SEMrush. Wenn Duplikate anstelle Ihres Canonicals zitiert werden, überprüfen Sie Ihre Implementierung und stellen Sie sicher, dass die Tags korrekt formatiert und im HTML-Head platziert sind.
IndexNow ist ein Protokoll, das Suchmaschinen und KI-Crawler sofort benachrichtigt, wenn Sie Canonical-Tags hinzufügen, aktualisieren oder entfernen, anstatt auf natürliche Crawling-Zyklen zu warten. Dadurch wird die Entdeckung Ihrer Canonical-Präferenzen beschleunigt und sichergestellt, dass KI-Systeme Ihre bevorzugten URLs schneller erkennen, wodurch die Zeit, in der Duplikate in KI-Antworten erscheinen, reduziert wird.
Ja, Canonical-Tags sind starke Signale, aber keine Direktiven. KI-Systeme können Ihre Canonical-Präferenz überschreiben, wenn sie feststellen, dass eine andere Version aufgrund von Inhaltsqualität, Link-Mustern, Aktualität oder anderen Signalen maßgeblicher ist. Deshalb ist eine korrekte Implementierung in Kombination mit starken Content- und Autoritätssignalen wichtig – das erhöht die Wahrscheinlichkeit, dass KI-Systeme Ihre Canonical-Präferenz respektieren.
Verfolgen Sie, wie KI-Systeme wie ChatGPT, Claude und Perplexity Ihre Inhalte zitieren. Stellen Sie sicher, dass Ihre kanonischen URLs ordnungsgemäß erkannt werden und Ihre Marke in KI-generierten Antworten korrekt zugeordnet wird.
Erfahren Sie, wie Sie doppelten Content beim Einsatz von KI-Tools verwalten und vermeiden. Entdecken Sie kanonische Tags, Weiterleitungen, Erkennungstools und B...
Community-Diskussion darüber, wie KI-Systeme Duplicate Content anders behandeln als traditionelle Suchmaschinen. SEO-Profis teilen Erkenntnisse zur Content-Einz...
Erfahren Sie, was KI-Content-Kannibalisierung ist, wie sie sich von doppeltem Inhalt unterscheidet, warum sie das Ranking beeinträchtigt und welche Strategien I...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.