
Come gestire i contenuti duplicati per i motori di ricerca IA
Scopri come gestire e prevenire i contenuti duplicati quando utilizzi strumenti di IA. Scopri tag canonici, reindirizzamenti, strumenti di rilevamento e best pr...
13 min di lettura

Scopri come gli URL canonici prevengono i problemi di contenuti duplicati nei sistemi di ricerca AI. Scopri le migliori pratiche per implementare i canonici, migliorare la visibilità AI e garantire una corretta attribuzione dei contenuti.
I modelli di linguaggio di grandi dimensioni e i sistemi di ricerca AI utilizzano sofisticati algoritmi di clustering per identificare e raggruppare URL quasi duplicati, trattando più versioni dello stesso contenuto come un’unica entità ai fini del ranking e della citazione. Quando i sistemi AI incontrano contenuti duplicati, devono selezionare quale versione dare priorità—una decisione che influisce direttamente su quale URL riceverà visibilità, segnali di autorevolezza e attribuzione da parte dell’utente. Il problema critico si manifesta quando l’AI seleziona la versione sbagliata: se il tuo URL canonico punta alla pagina preferita ma il sistema AI raggruppa e classifica invece un duplicato di qualità inferiore, i tuoi contenuti perdono visibilità e credito per la citazione. I segnali di intento si diluiscono tra le versioni duplicate, frammentando l’autorevolezza che dovrebbe concentrarsi su un unico URL e causando a ciascun duplicato il ricevimento di segnali di ranking più deboli rispetto a una situazione in cui tutta l’autorevolezza fosse unificata sulla versione canonica.
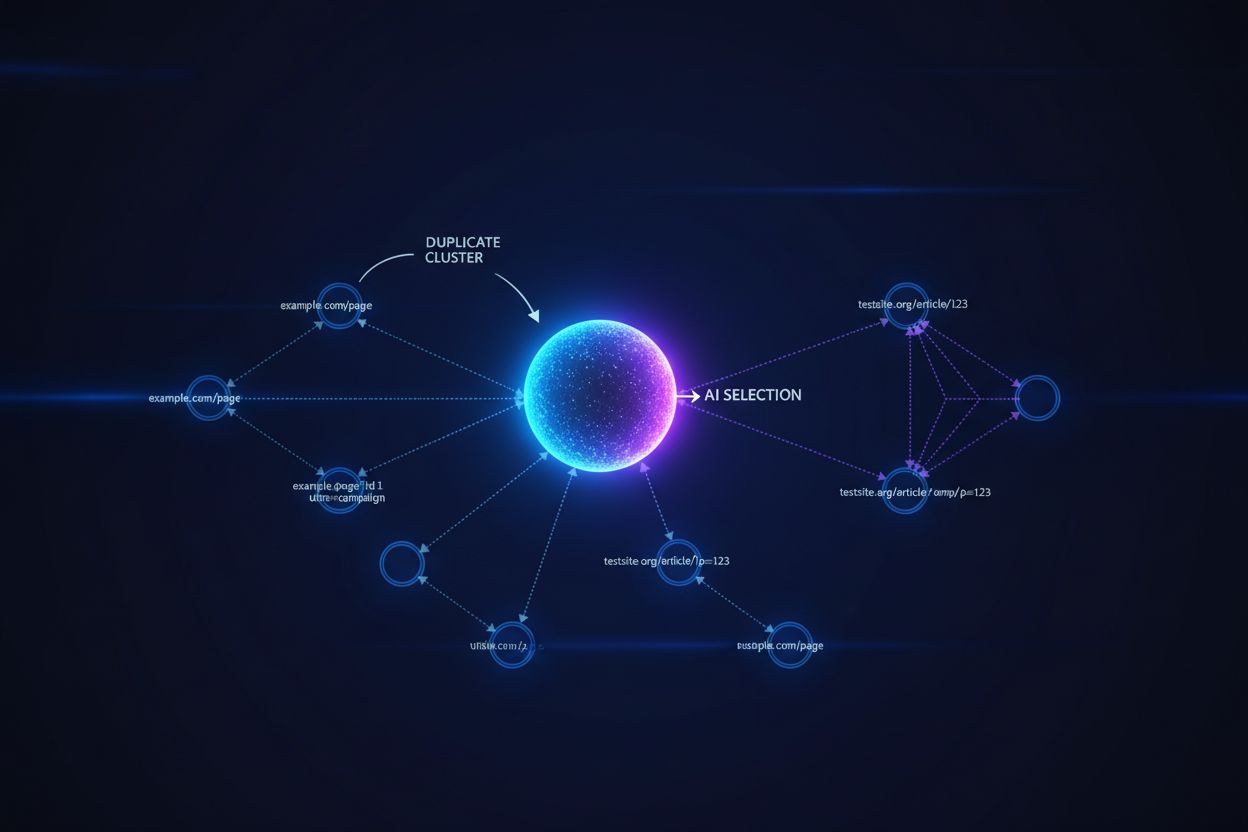
I tag canonici fungono da segnali espliciti per i sistemi AI su quale versione di un contenuto duplicato debba essere considerata autorevole, influenzando direttamente se il tuo URL preferito appare nelle risposte generate dall’AI e riceve la corretta attribuzione. Senza tag canonici, i sistemi AI devono prendere decisioni di clustering autonomamente, basandosi su similarità dei contenuti, pattern di link e segnali di freschezza—spesso selezionando la versione sbagliata come fonte canonica. Quando esistono contenuti duplicati senza una corretta implementazione canonica, le risposte AI potrebbero citare una versione sindacata, una copia cache o una variante di qualità inferiore invece del tuo contenuto originale, frammentando la tua visibilità su più URL. Gli URL canonici assicurano che, quando i sistemi AI incontrano i tuoi contenuti su diversi domini, parametri o versioni, comprendano quale unico URL debba ricevere credito ed essere mostrato nelle risposte.
| Scenario | Senza Canonico | Con Canonico |
|---|---|---|
| Impatto sull’AI | L’AI raggruppa i duplicati in autonomia; può selezionare la versione sbagliata per il ranking | L’AI riconosce un’unica fonte autorevole; consolida tutti i segnali sull’URL canonico |
| Credito di Citazione | Attribuzione dispersa su più URL; autorevolezza più debole per URL | Tutte le citazioni e autorevolezza confluiscono nell’URL canonico; visibilità più forte |
| Risultato | I contenuti appaiono nelle risposte AI ma l’URL sbagliato riceve il credito; visibilità frammentata | L’URL preferito appare nelle risposte AI con segnali di autorevolezza consolidati |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
I tag canonici e i redirect hanno scopi diversi nella gestione dei contenuti duplicati per i sistemi AI: i tag canonici indicano ai motori di ricerca e ai sistemi AI quale versione è preferita mantenendo entrambi gli URL accessibili, mentre i redirect inviano in modo permanente utenti e crawler da un URL a un altro. I redirect (301 per spostamenti permanenti, 302 per temporanei) sono segnali più forti perché consolidano tutta l’autorevolezza in un unico URL ed eliminano completamente il duplicato dal web, rendendoli ideali quando stai ritirando definitivamente un URL o consolidando domini. I tag canonici sono preferibili quando hai bisogno di mantenere più URL per motivi aziendali—come parametri di tracciamento per l’analisi, mantenimento di URL legacy per i segnalibri degli utenti o la pubblicazione di versioni differenti per pubblici diversi—segnalando comunque ai sistemi AI quale versione è autorevole. Usa i redirect quando consolidi domini dopo una migrazione, rimuovi versioni obsolete o elimini variazioni di parametri che non hanno uno scopo specifico. Usa i tag canonici quando devi mantenere più URL ma vuoi prevenire penalità per contenuti duplicati e assicurarti che i sistemi AI comprendano la tua versione preferita.
Differenze chiave tra Canonical e Redirect:
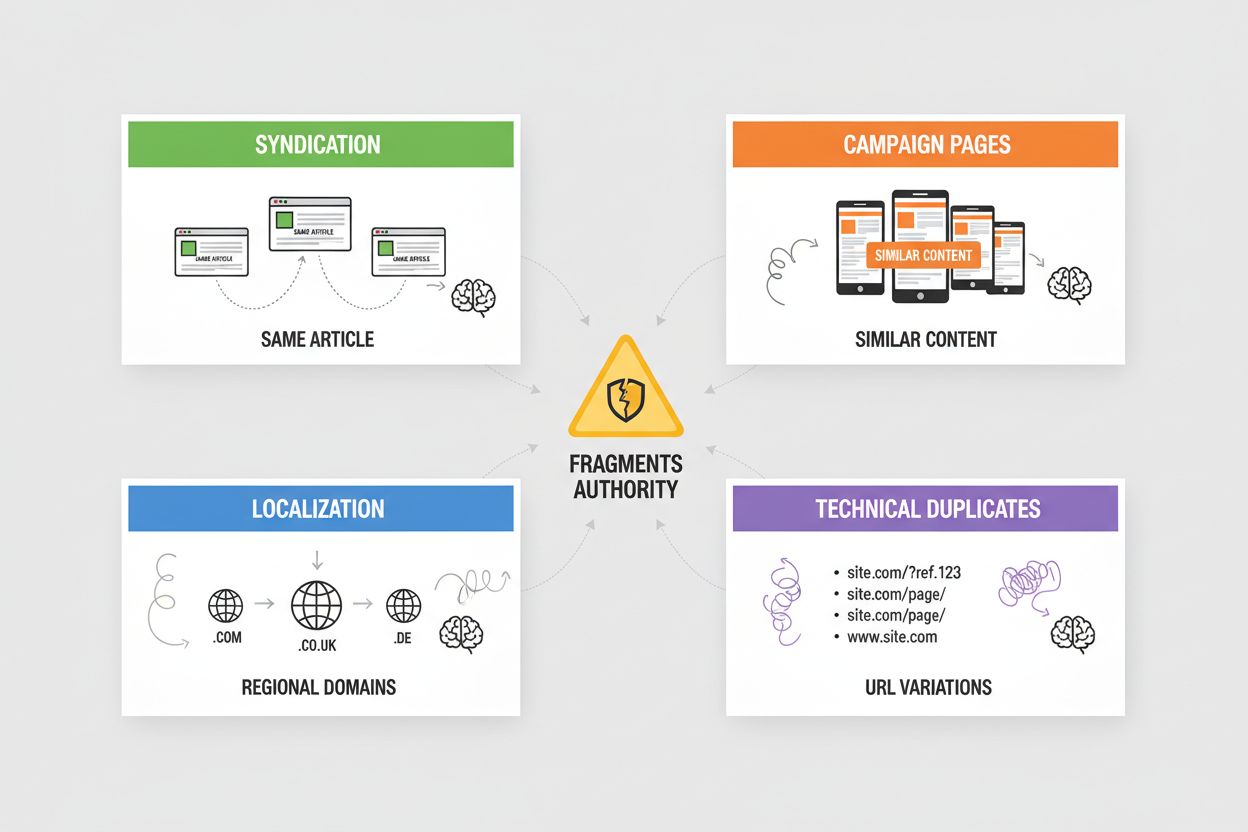
La sindacazione crea contenuti duplicati diffusi quando i tuoi articoli vengono ripubblicati su siti partner, aggregatori di notizie o network di contenuti—i sistemi AI devono decidere se attribuire la fonte originale o la versione sindacata, spesso predefinendo quella che appare per prima nella loro scansione. Le pagine di campagne generano duplicati quando crei più landing page con contenuti identici o quasi identici per diversi canali di marketing, parametri UTM o test A/B, portando i sistemi AI a frammentare l’autorevolezza tra varianti che dovrebbero essere consolidate. Localizzazione e internazionalizzazione producono duplicati quando offri contenuti simili su domini regionali (esempio.com, esempio.co.uk, esempio.de) o in più lingue, richiedendo l’uso dei tag hreflang e dei canonici per evitare che i sistemi AI trattino queste versioni come duplicati invece che variazioni intenzionali. I duplicati tecnici derivano da ID di sessione, parametri di tracciamento, versioni stampabili e variazioni di URL (www vs. non-www, http vs. https, slash finali) che creano più URL puntando agli stessi contenuti—i sistemi AI li vedono come duplicati e devono decidere quale versione dare priorità. Ciascuno di questi scenari diluisce l’autorevolezza che dovrebbe concentrarsi sull’URL preferito, riducendo la visibilità nelle risposte AI e provocando la dispersione del credito di citazione su più versioni.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Usa sempre URL assoluti nei tuoi tag canonici invece di URL relativi, garantendo che sistemi AI e motori di ricerca possano identificare senza ambiguità l’URL di destinazione indipendentemente da dove appare il tag. Includi canonici auto-referenziali sulle tue pagine preferite—anche le pagine senza duplicati dovrebbero riferirsi a se stesse come canoniche, impedendo ai sistemi AI di dedurre canonici basandosi su pattern di link o similarità dei contenuti. Inserisci i tag canonici nella sezione <head> del tuo documento HTML e, per i contenuti non HTML (PDF, immagini), implementa i canonici tramite header HTTP per assicurare il riconoscimento della preferenza da parte dei crawler AI indipendentemente dal tipo di contenuto.
<!-- Corretta implementazione canonica nell'head HTML -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Includi gli URL canonici nelle sitemap XML per rafforzare quali versioni sono autorevoli e abbina i canonici ai tag hreflang nella gestione di contenuti internazionali o localizzati per evitare che i sistemi AI trattino le variazioni regionali come duplicati. Evita errori comuni: non creare mai catene di canonici (A→B→C), non puntare mai canonici su pagine noindex e non usare mai i canonici per manipolare i ranking puntando a contenuti non correlati. Monitora la tua implementazione canonica con strumenti come Google Search Console, Bing Webmaster Tools e AmICited.com per verificare che i sistemi AI riconoscano i tuoi URL preferiti e attribuiscano correttamente i contenuti.
<!-- Corretta implementazione con hreflang per contenuti internazionali -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Analizza i tuoi URL canonici scansionando l’intero sito con strumenti come Screaming Frog, SEMrush o Ahrefs per identificare pagine prive di canonici, catene canoniche errate o canonici che puntano a pagine noindex—questi problemi impediscono ai sistemi AI di consolidare correttamente l’autorevolezza. Utilizza il report Copertura di Google Search Console per individuare pagine con problemi di contenuti duplicati e verificare che Google riconosca le tue preferenze canoniche, quindi incrocia con Bing Webmaster Tools per garantire coerenza tra i sistemi di ricerca AI. Implementa IndexNow per notificare immediatamente motori di ricerca e crawler AI quando aggiungi, aggiorni o rimuovi tag canonici, accelerando la scoperta delle tue preferenze canoniche invece di aspettare i cicli naturali di scansione. Monitora le citazioni AI con strumenti come AmICited.com e ricerche manuali in ChatGPT, Claude e Perplexity per verificare che i tuoi URL preferiti ricevano attribuzione nelle risposte generate dall’AI—se vengono citati duplicati invece, rivedi la tua implementazione canonica e assicurati che i tag siano correttamente formattati e posizionati. Analizza regolarmente la presenza di nuovi contenuti duplicati creati tramite partnership di sindacazione, lanci di campagne o modifiche tecniche, implementando i canonici in modo proattivo per mantenere una visibilità AI costante.
Traccia come i sistemi AI come ChatGPT, Claude e Perplexity citano i tuoi contenuti. Assicurati che i tuoi URL canonici siano riconosciuti correttamente e che il tuo marchio riceva la giusta attribuzione nelle risposte generate dall'AI.
Scopri come gestire e prevenire i contenuti duplicati quando utilizzi strumenti di IA. Scopri tag canonici, reindirizzamenti, strumenti di rilevamento e best pr...

Scopri come la ripubblicazione dei contenuti genera problemi di contenuto duplicato che danneggiano la visibilità nella ricerca AI più gravemente rispetto alla ...
Discussione della community su come i sistemi AI gestiscono i contenuti duplicati in modo diverso rispetto ai motori di ricerca tradizionali. I professionisti S...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.