Listicles und KI: Warum nummerierte Listen häufiger zitiert werden
Entdecken Sie, warum KI-Modelle Listicles und nummerierte Listen bevorzugen. Lernen Sie, wie Sie Listen-Inhalte für ChatGPT-, Gemini- und Perplexity-Zitate mit ...
9 Min. Lesezeit
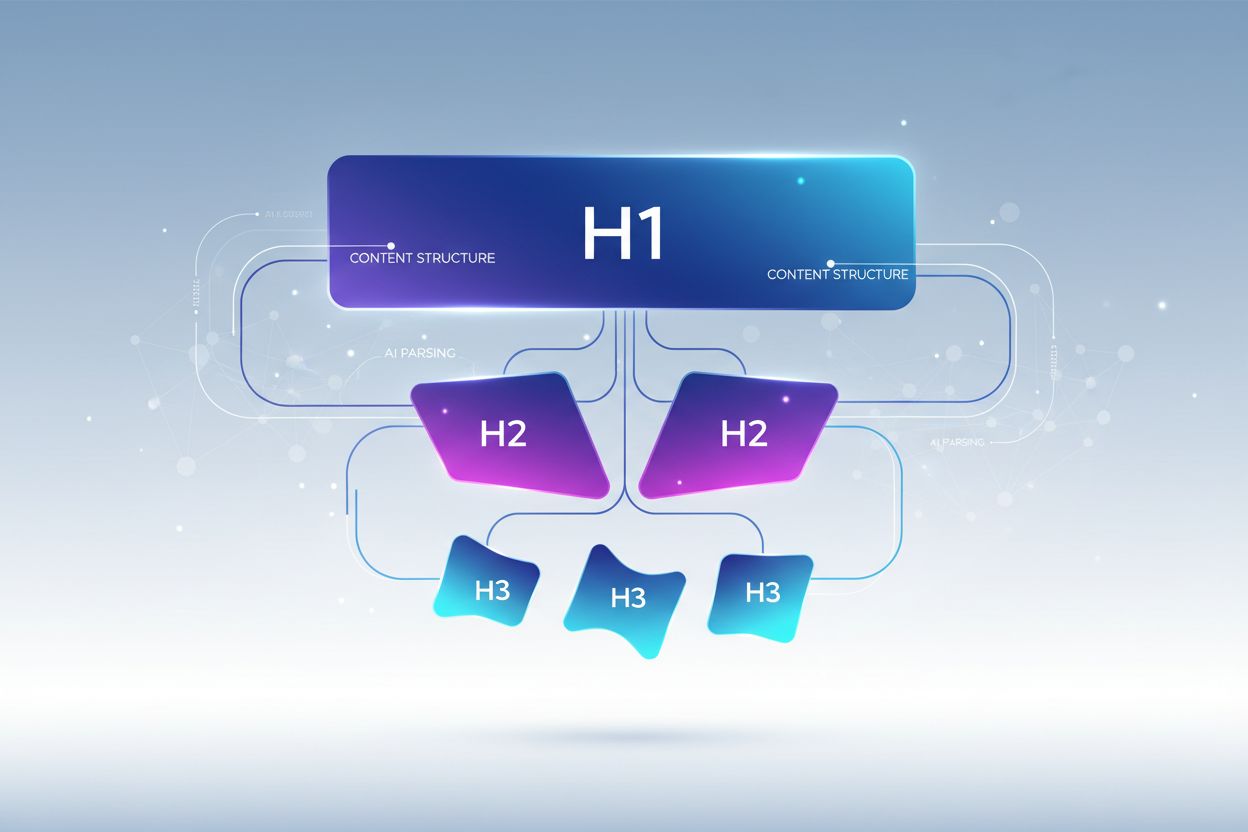
Erfahren Sie, wie Sie die Überschriften-Hierarchie für das Parsing durch LLMs optimieren. Beherrschen Sie die Struktur H1, H2, H3, um die Sichtbarkeit, Zitationen und Auffindbarkeit Ihrer Inhalte in ChatGPT, Perplexity und Google KI-Überblicken zu verbessern.
Große Sprachmodelle verarbeiten Inhalte grundlegend anders als menschliche Leser – diese Unterscheidung zu verstehen, ist entscheidend für die Optimierung Ihrer Content-Strategie. Während Menschen Seiten visuell scannen und die Struktur intuitiv erfassen, verlassen sich LLMs auf Tokenisierung und Aufmerksamkeitsmechanismen, um Bedeutung aus sequenziellen Texten zu ziehen. Wenn ein LLM auf Ihren Inhalt trifft, zerlegt es diesen in Tokens (kleine Texteinheiten) und weist unterschiedlichen Abschnitten Aufmerksamkeitsgewichte zu – und die Überschriften-Hierarchie ist eines der mächtigsten Strukturierungs-Signale. Ohne klar organisierte Überschriften fällt es LLMs schwer, Hauptthemen, unterstützende Argumente und Kontextbeziehungen zu erkennen – das führt zu ungenaueren Antworten und verringerter Sichtbarkeit in KI-gestützten Such- und Abrufsystemen.
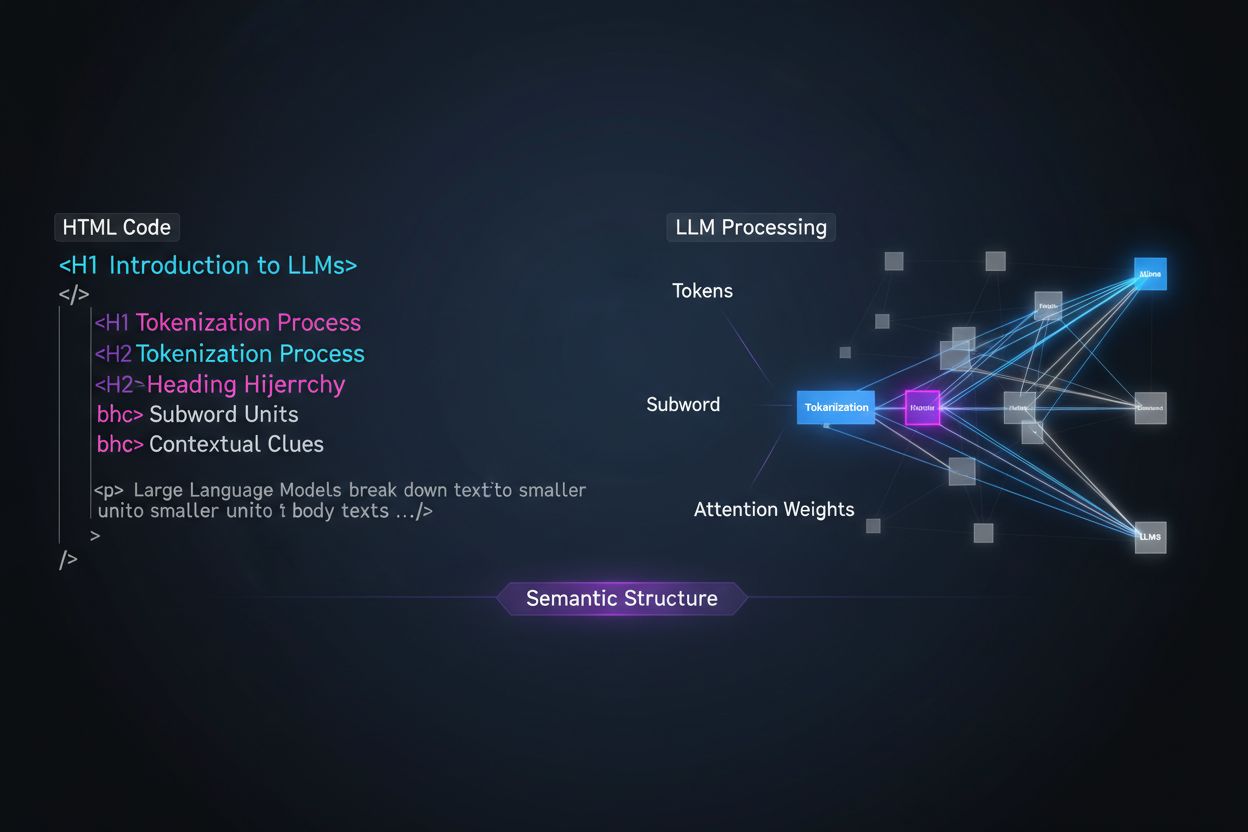
Moderne Content-Chunking-Strategien in Retrieval-Augmented-Generation-(RAG)-Systemen und KI-Suchmaschinen hängen stark von der Überschriftenstruktur ab, um zu bestimmen, wo Dokumente in abrufbare Segmente unterteilt werden. Wenn ein LLM gut organisierte Überschriften-Hierarchien erkennt, nutzt es H2- und H3-Grenzen als natürliche Schnittlinien für semantische Chunks – abgeschlossene Informationseinheiten, die unabhängig abgerufen und zitiert werden können. Dieser Prozess ist viel effektiver als willkürliche Zeichenbegrenzungen, da chunks auf Basis von Überschriften semantischen Zusammenhang und Kontext bewahren. Vergleichen Sie die beiden Ansätze:
| Ansatz | Chunk-Qualität | LLM-Zitationsrate | Retrieval-Genauigkeit |
|---|---|---|---|
| Semantisch reich (überschriftenbasiert) | Hohe Kohärenz, vollständige Gedanken | 3x höher | 85 %+ Genauigkeit |
| Generisch (Zeichenanzahl) | Fragmentiert, unvollständiger Kontext | Grundwert | 45–60 % Genauigkeit |
Studien zeigen, dass Dokumente mit klaren Überschriften-Hierarchien eine 18–27 % höhere Trefferquote bei Fragenbeantwortung durch LLMs erzielen, weil der Chunking-Prozess die logischen Zusammenhänge zwischen Ideen erhält. Systeme wie Retrieval-Augmented-Generation-(RAG)-Pipelines, die beispielsweise ChatGPTs Browsing-Funktion und Unternehmens-KI-Systeme antreiben, suchen explizit nach Überschriftenstrukturen, um ihre Retrieval-Systeme zu optimieren und die Zitationsgenauigkeit zu verbessern.
Eine korrekte Überschriften-Hierarchie folgt einer strikten Verschachtelung, wie LLMs die Informationsorganisation erwarten. Jede Ebene erfüllt eine bestimmte Funktion in Ihrer Inhaltsarchitektur. Das H1-Tag repräsentiert das Hauptthema des Dokuments – es darf pro Seite nur einmal vorkommen und sollte klar das Hauptthema benennen. H2-Tags markieren große Themenbereiche, die das H1 unterstützen oder erweitern; jede H2 behandelt einen eigenen Aspekt des Hauptthemas. H3-Tags vertiefen sich in spezifische Unterthemen innerhalb der jeweiligen H2 und liefern Details oder beantworten Folgefragen. Die wichtigste Regel für die LLM-Optimierung: Überspringen Sie keine Ebenen (z. B. von H1 direkt zu H3), und achten Sie auf konsistente Verschachtelung – jede H3 gehört zu einer H2, jede H2 zu einer H1. Diese Hierarchie wird als „semantischer Baum“ bezeichnet, den LLMs durchlaufen können, um den logischen Fluss Ihrer Inhalte zu verstehen und relevante Informationen präzise zu extrahieren.
Die wirkungsvollste Überschriftenstrategie für LLM-Sichtbarkeit behandelt jede H2-Überschrift als direkte Antwort auf eine bestimmte Nutzerintention oder Frage, wobei H3-Überschriften Unterfragen und unterstützende Details abbilden. Dieser „Antwort-zuerst“-Ansatz entspricht der Arbeitsweise moderner LLMs: Sie suchen gezielt nach Inhalten, die Nutzerfragen direkt beantworten, und Überschriften mit klaren Antworten werden deutlich häufiger ausgewählt und zitiert. Jede H2 sollte eine Antwort-Einheit sein – eine eigenständige Reaktion auf eine bestimmte Frage, die Nutzer zu Ihrem Thema stellen könnten. Wenn Ihr H1 zum Beispiel „Website-Performance optimieren“ lautet, könnten Ihre H2s „Bilddateigrößen reduzieren (verkürzt Ladezeit um 40 %)“ oder „Browser-Caching implementieren (verringert Serveranfragen um 60 %)“ sein – jede Überschrift beantwortet eine konkrete Performance-Frage. Die H3s unter jeder H2 greifen Folgefragen auf: Unter „Bilddateigrößen reduzieren“ könnten H3s wie „Das richtige Bildformat wählen“, „Komprimieren ohne Qualitätsverlust“ und „Responsive Bilder umsetzen“ stehen. Diese Struktur macht es LLMs deutlich leichter, Ihre Inhalte zu finden, zu extrahieren und zu zitieren – denn die Überschriften selbst enthalten die Antworten und nicht nur Themenbezeichnungen.
Um Ihre Überschriftenstrategie für maximale LLM-Sichtbarkeit zu transformieren, sollten Sie konkrete, umsetzbare Methoden anwenden, die über den Basisaufbau hinausgehen. Die effektivsten Optimierungen sind:
Beschreibende, spezifische Überschriften verwenden: Ersetzen Sie vage Titel wie „Überblick“ oder „Details“ durch aussagekräftige Beschreibungen wie „Wie Machine Learning die Empfehlungsgenauigkeit verbessert“ oder „Drei Faktoren, die das Ranking beeinflussen“. Studien zeigen, dass spezifische Überschriften die LLM-Zitationsrate um bis zu das Dreifache steigern.
Frageförmige Überschriften nutzen: Formulieren Sie H2s als direkte Nutzerfragen („Was ist Semantische Suche?“ oder „Warum ist Überschriften-Hierarchie wichtig?“). LLMs sind auf Frage-Antwort-Daten trainiert und bevorzugen solche Überschriften beim Retrieval.
Entitäten klar benennen: Nennen Sie konkrete Begriffe, Tools oder Entitäten explizit in Überschriften, statt Pronomen oder vage Referenzen zu verwenden. Zum Beispiel ist „PostgreSQL-Performance-Optimierung“ viel LLM-freundlicher als „Datenbank-Optimierung“.
Keine Mehrfach-Intentionen kombinieren: Jede Überschrift sollte ein einziges, fokussiertes Thema behandeln. Überschriften wie „Installation, Konfiguration und Fehlerbehebung“ verwässern die semantische Klarheit und verwirren LLM-Chunking-Algorithmen.
Quantifizierbaren Kontext hinzufügen: Wo sinnvoll, Zahlen, Prozentsätze oder Zeitangaben integrieren („Ladezeit um 40 % reduzieren durch Bildoptimierung“ statt „Bildoptimierung“). 80 % der von LLMs zitierten Inhalte enthalten quantifizierbaren Kontext in Überschriften.
Parallele Struktur auf allen Ebenen: Halten Sie eine konsistente Grammatik innerhalb der H2s und H3s eines Abschnitts. Beginnt eine H2 mit einem Verb („Caching implementieren“), sollten dies auch andere H2s tun („Datenbank-Indizes konfigurieren“, „Abfragen optimieren“).
Keywords natürlich einbauen: Nicht nur für SEO, sondern um LLMs die Themenrelevanz zu verdeutlichen – relevante Keywords in Überschriften steigern die Retrieval-Genauigkeit um 25–35 %.
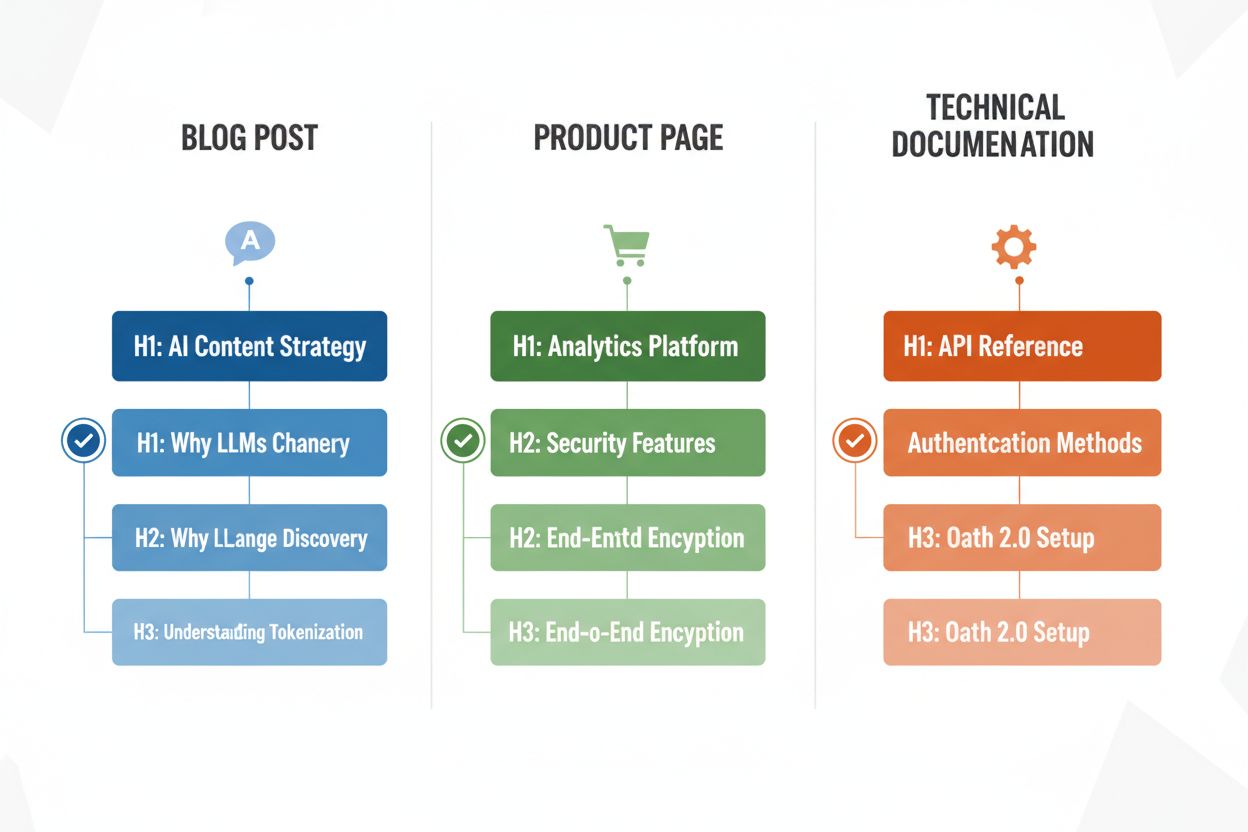
Je nach Inhaltstyp sind unterschiedliche Überschriftenstrategien nötig, um das Parsing durch LLMs zu maximieren. Blogbeiträge profitieren von erzählerisch aufgebauten Überschriften-Hierarchien: H2s führen logisch durch Argumente oder Erklärungen, H3s liefern Belege, Beispiele oder tiefergehende Analysen – etwa bei einem Beitrag zu „KI-Content-Strategie“: H2s wie „Warum LLMs die Content-Entdeckung verändern“, „So optimieren Sie für KI-Sichtbarkeit“ und „Ihre KI-Content-Performance messen“. Produktseiten sollten H2s direkt an Nutzerbedürfnissen und Entscheidungsfaktoren ausrichten („Sicherheit und Compliance“, „Integrationsmöglichkeiten“, „Preise und Skalierbarkeit“), während H3s spezifische Feature-Fragen oder Anwendungsfälle ansprechen. Technische Dokumentation erfordert die granularste Überschriftenstruktur: H2s für Hauptfunktionen oder Workflows, H3s für einzelne Aufgaben, Parameter oder Konfigurationsoptionen – diese Struktur ist entscheidend, da Dokus häufig von LLMs bei technischen Nutzerfragen zitiert werden. FAQ-Seiten sollten H2s als echte Fragen und H3s für Folgefragen oder verwandte Themen verwenden, da diese Struktur optimal mit dem Retrieval- und Antwortschema von LLMs harmoniert. Jeder Inhaltstyp hat eigene Nutzerintentionen – Ihre Überschriften-Hierarchie sollte diese widerspiegeln, um Relevanz und Zitationswahrscheinlichkeit zu maximieren.
Nach der Umstrukturierung Ihrer Überschriften ist eine Validierung wichtig, um den tatsächlichen Effekt auf das Parsing und die Sichtbarkeit in LLMs zu prüfen. Am praktischsten testen Sie Ihre Inhalte direkt mit KI-Tools wie ChatGPT, Perplexity oder Claude, indem Sie Ihr Dokument hochladen oder eine URL angeben und gezielt Fragen stellen, die Ihre Überschriften beantworten sollen. Achten Sie darauf, ob das KI-Tool Ihre Inhalte korrekt erkennt und zitiert und ob die richtigen Abschnitte extrahiert werden. Wird Ihre H2 zu „Ladezeit reduzieren“ bei Performance-Fragen nicht genannt, muss die Überschrift ggf. präziser formuliert werden. Alternativ bieten spezialisierte SEO-Tools mit KI-Zitations-Tracking (z. B. Semrush oder neue Ahrefs-AI-Features) die Möglichkeit, die Häufigkeit Ihrer Zitationen in LLM-Antworten im Zeitverlauf zu überwachen. Iterieren Sie anhand der Ergebnisse: Werden bestimmte Abschnitte nicht zitiert, probieren Sie spezifischere oder frageförmige Überschriften, fügen quantifizierbaren Kontext hinzu oder stellen die Verbindung zur Nutzerfrage klarer her. Der Testzyklus dauert meist 2–4 Wochen, da KI-Systeme Zeit zur Neuindizierung und Neubewertung Ihrer Inhalte benötigen.
Auch gut gemeinte Inhalte enthalten häufig Überschriftenfehler, die die Sichtbarkeit und Genauigkeit beim LLM-Parsing erheblich verringern. Einer der häufigsten Fehler ist das Kombinieren mehrerer Intentionen in einer Überschrift – etwa „Installation, Konfiguration und Fehlerbehebung“. Das zwingt LLMs, zu raten, welches Thema gemeint ist, was zu falschem Chunking und geringerer Zitationswahrscheinlichkeit führt. Vage, generische Überschriften wie „Überblick“, „Schlüsselpunkte“ oder „Weitere Informationen“ bieten keinerlei semantische Klarheit und machen es LLMs unmöglich zu erkennen, welche konkreten Inhalte der Abschnitt enthält; solche Überschriften werden von LLMs oft übersprungen oder falsch eingeordnet. Fehlender Kontext ist ein weiterer kritischer Fehler – eine Überschrift wie „Best Practices“ verrät dem LLM nicht, für welchen Bereich oder welches Thema sie gelten, während „Best Practices für API-Rate-Limiting“ sofort verständlich und abrufbar ist. Inkonsistente Hierarchie (Ebenen überspringen, H4 ohne H3, gemischte Überschriftenstile) verwirrt LLM-Parsing-Algorithmen, weil sie sich auf konsistente Strukturen stützen, um die Dokumentorganisation zu erkennen. Ein Dokument nach dem Schema H1 → H3 → H2 → H4 schafft Unklarheit, welche Abschnitte zusammengehören, und senkt die Retrieval-Genauigkeit um 30–40 %. Mit einem Test bei ChatGPT oder ähnlichen Tools werden solche Fehler schnell sichtbar – wenn die KI Probleme hat, Ihre Struktur zu erkennen oder die falschen Abschnitte zitiert, sollten Sie Ihre Überschriften überarbeiten.
Die Optimierung der Überschriften-Hierarchie für LLMs bringt einen wertvollen Nebeneffekt: verbesserte Barrierefreiheit für Menschen mit Behinderungen. Semantische HTML-Überschriftenstruktur (korrekte Nutzung von H1–H6-Tags) ist die Grundlage für Screenreader-Funktionalität und ermöglicht es sehbeeinträchtigten Nutzern, Dokumente effizient zu navigieren und die Struktur zu erfassen. Wer klare, beschreibende Überschriften für LLMs optimiert, verbessert gleichzeitig die Navigation für Screenreader – die gleiche Spezifität und Klarheit, die LLMs hilft, hilft auch unterstützenden Technologien bei der Nutzerführung. Diese Schnittmenge aus KI-Optimierung und Barrierefreiheit ist ein seltenes Win-win: Die technischen Anforderungen an LLM-freundlichen Content unterstützen direkt die WCAG-Standards und verbessern das Erlebnis für alle. Unternehmen, die die Überschriften-Hierarchie für KI-Sichtbarkeit priorisieren, sehen häufig überraschend bessere Accessibility-Scores und Nutzerzufriedenheit bei Menschen, die auf Hilfstechnologien angewiesen sind.
Wer seine Überschriften-Hierarchie optimiert, sollte die Erfolge messen, um Aufwand und Wirkung zu belegen. Der direkteste KPI ist die LLM-Zitationsrate – erfassen Sie, wie oft Ihre Inhalte in Antworten von ChatGPT, Perplexity, Claude und anderen KI-Tools auftauchen, indem Sie regelmäßig passende Fragen stellen und die zitierten Quellen protokollieren. Tools wie Semrush, Ahrefs und neuere Plattformen wie Originality.AI bieten inzwischen LLM-Zitations-Tracking, das Ihre Sichtbarkeit in KI-Antworten im Zeitverlauf überwacht. Rechnen Sie mit einer 2–3-fachen Steigerung der Zitationen innerhalb von 4–8 Wochen nach korrektem Überschriften-Setup – je nach Content-Typ und Wettbewerb. Zusätzlich sollten Sie organischen Traffic aus KI-gestützten Suchfunktionen (Googles KI-Überblicke, Bing-Chat-Zitationen etc.) separat vom klassischen SEO-Organic überwachen, da sich hier Erfolge schneller zeigen. Überwachen Sie zudem Engagement-Metriken wie Verweildauer und Scrolltiefe auf Seiten mit optimierten Überschriften – bessere Struktur steigert das Engagement typischerweise um 15–25 %, weil Nutzer relevante Infos schneller finden. Zuletzt messen Sie in eigenen Systemen mit RAG-Pipelines oder internen KI-Tools die Retrieval-Genauigkeit durch Tests, ob die korrekten Abschnitte bei typischen Nutzerfragen abgerufen werden. Diese Kennzahlen belegen den ROI der Überschriften-Optimierung und helfen, Ihre Content-Strategie weiter zu verfeinern.
Die Überschriften-Hierarchie wirkt sich in erster Linie auf die KI-Sichtbarkeit und LLM-Zitationen aus und weniger auf das traditionelle Google-Ranking. Eine korrekte Überschriftenstruktur verbessert jedoch die Gesamtqualität und Lesbarkeit des Inhalts, was indirekt das SEO unterstützt. Der Hauptvorteil ist die erhöhte Sichtbarkeit in KI-gestützten Suchergebnissen wie Google KI-Überblicken, ChatGPT und Perplexity, bei denen die Überschriftenstruktur entscheidend für die Inhaltsextraktion und Zitation ist.
Ja, wenn Ihre aktuellen Überschriften vage sind oder keiner klaren H1→H2→H3-Hierarchie folgen. Beginnen Sie mit einer Überprüfung Ihrer leistungsstärksten Seiten und setzen Sie Verbesserungen zuerst bei stark frequentierten Inhalten um. Die gute Nachricht: LLM-freundliche Überschriften sind auch benutzerfreundlicher, sodass Änderungen sowohl Menschen als auch KI-Systemen zugutekommen.
Absolut. Tatsächlich funktionieren die besten Überschriftenstrukturen für beide Gruppen gleichermaßen gut. Klare, beschreibende, hierarchische Überschriften, die Menschen beim Verständnis der Inhaltsorganisation helfen, sind genau das, was LLMs für das Parsing und Chunking benötigen. Es gibt keinen Widerspruch zwischen menschenfreundlichen und LLM-freundlichen Überschriften-Praktiken.
Es gibt keine strikte Obergrenze, aber zielen Sie auf 3–7 H2-Überschriften pro Seite, abhängig von Länge und Komplexität des Inhalts. Jede H2 sollte ein eigenes Thema oder eine Antwort-Einheit darstellen. Unter jeder H2 sollten 2–4 H3s für unterstützende Details stehen. Seiten mit insgesamt 12–15 Überschriftenabschnitten (H2s und H3s zusammen) erzielen häufig gute Ergebnisse bei LLM-Zitationen.
Ja, selbst Kurzform-Inhalte profitieren von einer korrekten Überschriftenstruktur. Ein 500-Wörter-Artikel hat vielleicht nur 1–2 H2s, aber diese sollten trotzdem beschreibend und spezifisch sein. Kurzform-Inhalte mit klaren Überschriften werden von LLMs eher zitiert als unstrukturierte Kurztexte.
Testen Sie Ihre Inhalte direkt mit ChatGPT, Perplexity oder Claude, indem Sie Fragen stellen, die Ihre Überschriften beantworten sollen. Wenn die KI Ihre Inhalte korrekt erkennt und zitiert, funktioniert Ihre Struktur. Falls sie Schwierigkeiten hat oder falsche Abschnitte zitiert, müssen Ihre Überschriften überarbeitet werden. Die meisten Verbesserungen zeigen innerhalb von 2–4 Wochen Wirkung.
Sowohl Googles KI-Überblicke als auch ChatGPT profitieren von klarer Überschriften-Hierarchie, aber ChatGPT misst ihr noch größere Bedeutung bei. ChatGPT zitiert Inhalte mit sequentieller Überschriftenstruktur dreimal häufiger als Inhalte ohne diese. Die Grundprinzipien sind gleich, aber LLMs wie ChatGPT reagieren empfindlicher auf Qualität und Struktur von Überschriften.
Frageförmige Überschriften eignen sich am besten für FAQ-Seiten, Problemlösungsanleitungen und Bildungsinhalte. Bei Blogbeiträgen und Produktseiten bewährt sich oft eine Mischung aus Fragen und Feststellungen. Wichtig ist, dass Überschriften klar machen, worum es im Abschnitt geht – ob als Frage oder Aussage.
Verfolgen Sie, wie oft Ihre Inhalte in ChatGPT, Perplexity, Google KI-Überblicken und anderen LLMs zitiert werden. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Suchleistung und optimieren Sie Ihre Content-Strategie.
Entdecken Sie, warum KI-Modelle Listicles und nummerierte Listen bevorzugen. Lernen Sie, wie Sie Listen-Inhalte für ChatGPT-, Gemini- und Perplexity-Zitate mit ...

Erfahren Sie, wie Sie LLM-Meta-Antworten erstellen, die von KI-Systemen zitiert werden. Entdecken Sie strukturelle Techniken, Strategien zur Antwortdichte und z...

Erfahren Sie die besten Praktiken zur Formatierung von Überschriften für KI-Systeme. Entdecken Sie, wie eine korrekte H1-, H2-, H3-Hierarchie die KI-Inhaltsauff...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.