
Prompt-Bibliotheken für manuelles AI-Visibility-Testing
Erfahren Sie, wie Sie Prompt-Bibliotheken für manuelles AI-Visibility-Testing aufbauen und nutzen. DIY-Anleitung zum Testen, wie AI-Systeme Ihre Marke in ChatGP...
10 Min. Lesezeit

Erfahren Sie, wie Sie die Präsenz Ihrer Marke in KI-Engines mit Prompt-Testing testen. Entdecken Sie manuelle und automatisierte Methoden, um die KI-Sichtbarkeit in ChatGPT, Perplexity und Google AI zu überwachen.
Prompt-Testen ist der Prozess, bei dem systematisch Anfragen an KI-Engines gestellt werden, um zu messen, ob Ihre Inhalte in deren Antworten erscheinen. Im Gegensatz zum klassischen SEO-Testen, das sich auf Suchrankings und Klickraten konzentriert, bewertet das KI-Sichtbarkeits-Testen Ihre Präsenz auf generativen KI-Plattformen wie ChatGPT, Perplexity und Google AI Overviews. Diese Unterscheidung ist entscheidend, da KI-Engines andere Ranking-Mechanismen, Abrufsysteme und Zitiermuster als klassische Suchmaschinen verwenden. Das Testen Ihrer Präsenz in KI-Antworten erfordert daher einen grundsätzlich anderen Ansatz – einen, der berücksichtigt, wie große Sprachmodelle Informationen aus dem Web abrufen, zusammenführen und zuordnen.
Manuelles Prompt-Testen bleibt der zugänglichste Einstieg, um Ihre KI-Sichtbarkeit zu verstehen, erfordert jedoch Disziplin und Dokumentation. So funktioniert das Testen auf den wichtigsten KI-Plattformen:
| KI-Engine | Testschritte | Vorteile | Nachteile |
|---|---|---|---|
| ChatGPT | Prompts eingeben, Antworten prüfen, Erwähnungen/Zitate notieren, Ergebnisse dokumentieren | Direkter Zugang, ausführliche Antworten, Zitier-Tracking | Zeitaufwendig, inkonsistente Ergebnisse, begrenzte historische Daten |
| Perplexity | Anfragen eingeben, Quell-Zuordnung analysieren, Zitierplatzierung verfolgen | Klare Quell-Zuordnung, Echtzeitdaten, benutzerfreundlich | Manuelle Dokumentation nötig, begrenzte Abfragemenge |
| Google AI Overviews | Suchanfragen bei Google, KI-generierte Zusammenfassungen prüfen, Quelleneinbindung notieren | Mit Suche integriert, hohes Traffic-Potenzial, natürliches Nutzerverhalten | Begrenzte Kontrolle über Varianten, inkonsistentes Erscheinen |
| Google AI Mode | Zugriff über Google Labs, spezifische Anfragen testen, Featured Snippets protokollieren | Neue Plattform, direkter Testzugang | Frühes Stadium, begrenzte Verfügbarkeit |
ChatGPT-Testing und Perplexity-Testing sind das Fundament der meisten manuellen Teststrategien, da diese Plattformen die größten Nutzerbasen und die transparentesten Zitiermechanismen bieten.
Obwohl manuelles Testen wertvolle Einblicke liefert, wird es in größerem Umfang schnell unpraktisch. Bereits das Testen von 50 Prompts auf vier KI-Engines bedeutet über 200 Einzelabfragen – jede erfordert manuelle Dokumentation, Screenshot-Erfassung und Ergebnisanalyse, was pro Testzyklus 10–15 Stunden in Anspruch nimmt. Die Grenzen des manuellen Testens gehen über den Zeitaufwand hinaus: Menschliche Tester dokumentieren oft inkonsistent, kämpfen mit der Einhaltung regelmäßiger Testintervalle und können keine Daten über Hunderte Prompts hinweg aggregieren, um Muster zu erkennen. Das Skalierungsproblem wird besonders deutlich, wenn gebrandete und ungebbrandete Varianten, Long-Tail-Anfragen und Benchmarking parallel getestet werden sollen. Hinzu kommt: Manuelles Testen liefert nur Momentaufnahmen; ohne Automatisierung können Sie weder wöchentliche Sichtbarkeitsveränderungen verfolgen noch erkennen, welche Content-Updates Ihre KI-Präsenz tatsächlich verbessert haben.
Automatisierte KI-Sichtbarkeits-Tools nehmen Ihnen die manuelle Arbeit ab, indem sie fortlaufend Prompts an KI-Engines senden, Antworten erfassen und Ergebnisse in Dashboards bündeln. Diese Plattformen nutzen APIs und automatisierte Abläufe, um Hunderte oder Tausende Prompts nach Ihrem Zeitplan – täglich, wöchentlich oder monatlich – ohne menschliches Zutun zu testen. Automatisiertes Testen sammelt strukturierte Daten zu Erwähnungen, Zitaten, Zuordnungsgenauigkeit und Sentiment über alle wichtigen KI-Engines hinweg. Über Echtzeit-Monitoring erkennen Sie Sichtbarkeitsveränderungen sofort, können sie mit Inhalts-Updates oder Algorithmus-Änderungen verknüpfen und strategisch darauf reagieren. Die Datenaggregation dieser Plattformen deckt Muster auf, die manuell unsichtbar bleiben: Welche Themen generieren die meisten Zitate? Welche Inhaltsformate bevorzugen KI-Engines? Wie steht Ihr Share of Voice im Wettbewerb? Werden Ihre Zitate korrekt zugeordnet und verlinkt? Dieser systematische Ansatz verwandelt KI-Sichtbarkeit von einer gelegentlichen Prüfung in einen kontinuierlichen Informationsstrom, der Ihre Content-Strategie und Ihre Wettbewerbspositionierung steuert.
Erfolgreiche Prompt-Testing Best Practices erfordern eine durchdachte Auswahl und Ausgewogenheit der Testprompts. Diese Aspekte sind essenziell:
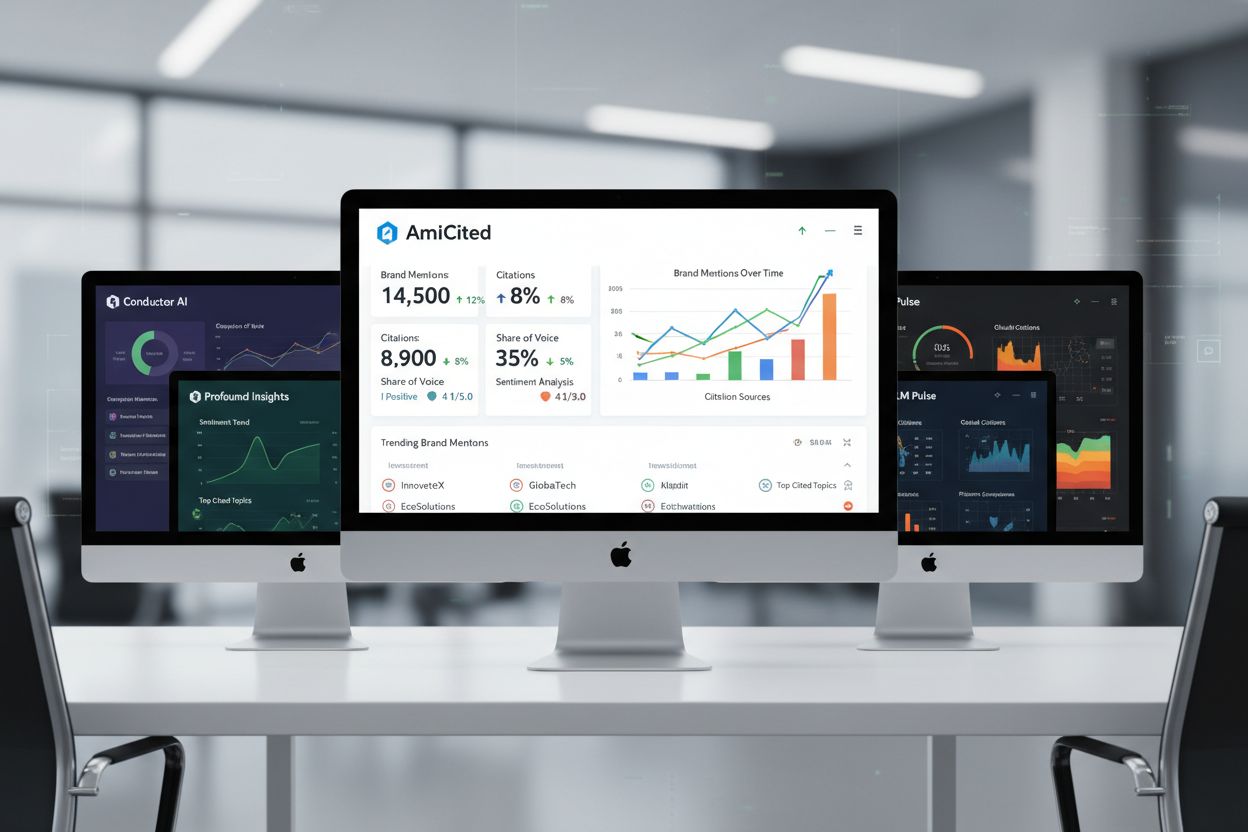
KI-Sichtbarkeitsmetriken liefern einen vielschichtigen Blick auf Ihre Präsenz auf generativen KI-Plattformen. Zitier-Tracking zeigt nicht nur, ob Sie erscheinen, sondern auch wie prominent – ob als Hauptquelle, eine von mehreren oder nur beiläufig erwähnt. Share of Voice vergleicht Ihre Zitierhäufigkeit mit der von Wettbewerbern im gleichen Themenfeld, zeigt Ihre Wettbewerbsposition und Content-Autorität. Sentiment-Analysen, vorangetrieben durch Plattformen wie Profound, bewerten, ob Ihre Zitate in KI-Antworten positiv, neutral oder negativ dargestellt werden – ein entscheidender Kontext, der durch bloße Erwähnungszahlen verborgen bleibt. Die Genauigkeit der Attribution ist ebenso wichtig: Wird Ihr Inhalt von der KI korrekt mit Link zitiert oder nur paraphrasiert? Diese Metriken erfordern Kontext – eine einzelne Erwähnung bei einer stark nachgefragten Abfrage kann mehr wert sein als zehn Erwähnungen bei wenig gesuchten Themen. Benchmarking mit Wettbewerbern stellt den Vergleich her: Wenn Sie bei 40% relevanter Prompts erscheinen, die Konkurrenz aber bei 60%, haben Sie eine Sichtbarkeitslücke identifiziert, die es zu schließen gilt.
Der Markt für KI-Sichtbarkeitsplattformen bietet mehrere spezialisierte Tools – jedes mit eigenen Stärken. AmICited liefert umfassendes Zitier-Tracking über ChatGPT, Perplexity und Google AI Overviews mit detaillierter Attribution und Wettbewerbs-Benchmarking. Conductor fokussiert auf Prompt-Ebene und Themenautorität, um zu erkennen, welche Themen die meiste KI-Sichtbarkeit generieren. Profound legt den Schwerpunkt auf Sentiment-Analyse und Genauigkeit der Quellenzuordnung – entscheidend, um zu verstehen, wie KI-Engines Ihre Inhalte präsentieren. LLM Pulse bietet Hilfestellung für manuelles Testen und deckt neue Plattformen ab – ideal für Teams, die ihre Testprozesse neu aufbauen. Welche Lösung passt, hängt von Ihren Prioritäten ab: Ist umfassende Automatisierung und Wettbewerbsanalyse wichtig, ist AmICited führend; steht Themenautorität im Vordergrund, passt Conductors Ansatz; ist Ihnen die Darstellung Ihrer Inhalte durch KI besonders wichtig, sticht Profounds Sentiment-Analyse hervor. Die meisten fortschrittlichen Teams nutzen mehrere Plattformen, um sich ergänzende Einblicke zu sichern.
Organisationen untergraben ihre Testergebnisse oft durch vermeidbare Fehler. Zu starke Fokussierung auf gebbrandete Prompts erzeugt eine Scheinsichtbarkeit – Sie schneiden gut bei “Firmenname”-Suchen ab, bleiben aber bei Branchenthemen, die tatsächlich Reichweite und Traffic bringen, unsichtbar. Unregelmäßige Tests führen zu unzuverlässigen Daten: Wer nur sporadisch testet, kann echte Trends nicht von normalen Schwankungen unterscheiden. Wer Sentiment-Analysen ignoriert, interpretiert die Ergebnisse falsch – erscheinen Sie in KI-Antworten, die Ihre Marke negativ darstellen oder Konkurrenz bevorzugen, schadet das Ihrer Positionierung. Fehlende Page-Level-Daten verhindern gezielte Optimierung: Zu wissen, dass Sie für ein Thema erscheinen, ist gut – aber erst das Wissen, welche Seiten angezeigt werden und wie sie zugeordnet werden, ermöglicht gezielte Verbesserungen. Ein weiterer Fehler ist das Testen ausschließlich aktueller Inhalte; auch ältere Seiten sollten geprüft werden, um zu erkennen, ob sie noch KI-Sichtbarkeit erzeugen oder bereits durch neuere Quellen abgelöst wurden. Letztlich verhindert fehlende Verknüpfung von Testresultaten mit Inhaltsänderungen, dass Sie lernen, welche Updates wirklich zu besserer KI-Sichtbarkeit führen – damit bleibt kontinuierliche Optimierung aus.
Prompt-Test-Ergebnisse sollten Ihre Content-Strategie und KI-Optimierungs-Prioritäten direkt steuern. Zeigt das Testing, dass Wettbewerber ein stark nachgefragtes Thema dominieren, in dem Sie kaum sichtbar sind, wird dieses Thema zur Content-Priorität – sei es durch neue Inhalte oder Optimierungen. Das Testing zeigt, welche Content-Formate KI-Engines bevorzugen: Wenn Listenartikel der Konkurrenz öfter erscheinen als Ihre Longform-Guides, kann Format-Optimierung Ihre Sichtbarkeit verbessern. Themenautorität wird durch Testdaten sichtbar: Themen, in denen Sie bei vielen Prompt-Varianten konstant erscheinen, zeigen etablierte Autorität; tauchen Sie nur sporadisch auf, gibt es Lücken oder Schwächen. Nutzen Sie Tests, um Strategie zu validieren, bevor Sie viel investieren: Wenn Sie ein neues Thema anvisieren, prüfen Sie zunächst die aktuelle Sichtbarkeit, um Wettbewerbsintensität und Potenzial realistisch einzuschätzen. Tests offenbaren auch Attributionstrends: Werden Ihre Inhalte von KI zitiert, aber ohne Link, sollten Sie auf einzigartige Daten, eigene Studien und unverwechselbare Perspektiven setzen, die zur Attribution zwingen. Integrieren Sie das Testing schließlich in Ihren Redaktionsplan – legen Sie Testzyklen rund um große Content-Launches, um Wirkung zu messen und die Strategie auf Basis realer KI-Sichtbarkeit statt Annahmen auszurichten.
Manuelles Testen bedeutet, Prompts einzeln an KI-Engines zu übermitteln und die Ergebnisse per Hand zu dokumentieren – das ist zeitaufwendig und schwierig zu skalieren. Automatisiertes Testen nutzt Plattformen, die Hunderte von Prompts nach Zeitplan kontinuierlich an mehrere KI-Engines senden, strukturierte Daten erfassen und Ergebnisse für Trendanalysen sowie Wettbewerbsvergleiche in Dashboards aggregieren.
Etablieren Sie einen konsistenten Test-Rhythmus – mindestens wöchentlich oder zweiwöchentlich –, um aussagekräftige Trends zu verfolgen und Sichtbarkeitsveränderungen mit Inhalts-Updates oder Algorithmus-Änderungen zu korrelieren. Häufigeres Testen (täglich) ist bei besonders wichtigen Themen oder in wettbewerbsintensiven Märkten sinnvoll, während weniger häufiges Testen (monatlich) für stabile, ausgereifte Themenfelder ausreichen kann.
Folgen Sie der 75/25-Regel: Ungefähr 75% ungebbrandete Prompts (Branchenthemen, Problemstellungen, Informationsanfragen) und 25% gebrandete Prompts (Ihr Firmenname, Produktnamen, gebrandete Keywords). Dieses Gleichgewicht hilft Ihnen, sowohl die Entdeckungssichtbarkeit als auch die markenspezifische Präsenz zu verstehen, ohne die Ergebnisse mit Anfragen aufzublähen, bei denen Sie wahrscheinlich ohnehin schon dominieren.
Erste Signale sehen Sie bereits nach den ersten Testzyklen, aber aussagekräftige Muster entstehen meist nach 4–6 Wochen konsequenter Verfolgung. In diesem Zeitraum können Sie eine Basislinie festlegen, natürliche Schwankungen in KI-Antworten berücksichtigen und Sichtbarkeitsveränderungen mit konkreten Inhalts-Updates oder Optimierungsmaßnahmen verknüpfen.
Ja, Sie können manuelles Testen kostenlos durchführen, indem Sie direkt auf ChatGPT, Perplexity, Google AI Overviews und Google AI Mode zugreifen. Allerdings ist kostenloses, manuelles Testen in Umfang und Konsistenz begrenzt. Automatisierte Plattformen wie AmICited bieten kostenlose Testphasen oder Freemium-Optionen, um den Ansatz vor einem kostenpflichtigen Abo zu testen.
Die wichtigsten Metriken sind Zitate (wenn KI-Engines auf Ihre Inhalte verlinken), Erwähnungen (wenn Ihre Marke genannt wird), Share of Voice (Ihre Sichtbarkeit im Vergleich zu Wettbewerbern) und Sentiment (wie Ihre Zitate präsentiert werden). Die Genauigkeit der Attribution – ob KI-Engines Ihre Inhalte korrekt zuordnen – ist ebenso entscheidend, um die tatsächliche Sichtbarkeitswirkung zu verstehen.
Effektive Prompts generieren konsistente, umsetzbare Daten, die mit Ihren Unternehmenszielen korrelieren. Testen Sie, ob Ihre Prompts echtes Nutzerverhalten widerspiegeln, indem Sie sie mit Suchanfragedaten, Kundeninterviews und Verkaufsgesprächen vergleichen. Prompts, die Sichtbarkeitsveränderungen nach Inhalts-Updates erzeugen, sind besonders wertvoll für die Validierung Ihrer Teststrategie.
Starten Sie mit den wichtigsten Engines (ChatGPT, Perplexity, Google AI Overviews), die die größten Nutzerbasen und das meiste Traffic-Potenzial bieten. Wenn Ihr Programm reifer ist, erweitern Sie auf neue Engines wie Gemini, Claude und andere, die für Ihr Publikum relevant sind. Die Auswahl hängt davon ab, wo sich Ihre Zielkunden tatsächlich aufhalten und welche Engines den meisten Referral-Traffic auf Ihre Seite bringen.
Testen Sie die Präsenz Ihrer Marke in ChatGPT, Perplexity, Google AI Overviews und mehr mit dem umfassenden KI-Sichtbarkeits-Monitoring von AmICited.
Erfahren Sie, wie Sie Prompt-Bibliotheken für manuelles AI-Visibility-Testing aufbauen und nutzen. DIY-Anleitung zum Testen, wie AI-Systeme Ihre Marke in ChatGP...

Erfahren Sie, was Prompt Engineering ist, wie es mit KI-Suchmaschinen wie ChatGPT und Perplexity funktioniert, und entdecken Sie wichtige Techniken, um Ihre KI-...

Erfahren Sie, wie Sie eine effektive Prompt-Bibliothek erstellen und organisieren, um Ihre Marke über ChatGPT, Perplexity und Google AI hinweg zu verfolgen. Sch...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.