
Kanonische URLs und KI: Vermeidung von Duplicate-Content-Problemen
Erfahren Sie, wie kanonische URLs Duplicate-Content-Probleme in KI-Suchsystemen verhindern. Entdecken Sie Best Practices für die Implementierung von Canonicals,...
6 Min. Lesezeit

Erfahren Sie, wie das Neuveröffentlichen von Inhalten Probleme mit doppelten Inhalten verursacht, die die Sichtbarkeit in der KI-Suche stärker beeinträchtigen als bei traditionellen Suchmaschinen. Entdecken Sie technische Schutzmaßnahmen und Best Practices.
Die Neuveröffentlichung von Inhalten über verschiedene Kanäle, Plattformen und Formate ist eine legitime und oft notwendige Strategie, um Reichweite und Engagement zu maximieren. Diese Praxis erzeugt jedoch einen grundlegenden Konflikt mit der Art und Weise, wie Suchsysteme – insbesondere KI-gestützte – Inhalte verarbeiten und bewerten. Die Frage ist nicht, ob Sie dürfen neu veröffentlichen, sondern ob Sie es so tun, dass Ihre Sichtbarkeit in KI-Suchergebnissen nicht sabotiert wird. Anders als traditionelle Suchmaschinen, die über Jahrzehnte ausgefeilte Mechanismen zur Erkennung doppelter Inhalte entwickelt haben, gehen KI-Systeme mit doppelten Inhalten anders um und schaffen neue Risiken, auf die viele Publisher noch nicht vorbereitet sind.
Laut Microsofts technischer Dokumentation zu Copilot und KI-Suche “gruppieren LLMs nahezu identische URLs zu einem Cluster und wählen dann eine Seite als Repräsentanten aus.” Dieses Clustering-Verhalten unterscheidet sich grundlegend davon, wie Googles PageRank-Algorithmus Autorität über doppelte Seiten verteilt. Statt Signale zu konsolidieren, treffen KI-Systeme eine binäre Entscheidung: Sie wählen eine Repräsentantenseite aus einem Cluster ähnlicher Inhalte und ignorieren die anderen weitgehend. Dieser Auswahlprozess ist nicht immer vorhersehbar oder basiert auf der Version, die Sie bevorzugen würden. Der Algorithmus berücksichtigt Faktoren wie Aktualität, Inhaltsqualität, technische Signale und Domain-Autorität – aber die Gewichtung bleibt undurchsichtig. Besonders problematisch ist, dass KI-Systeme möglicherweise eine veraltete Version auswählen, wenn die Unterschiede zwischen den Seiten geringfügig sind und der Clustering-Algorithmus keine wesentlichen Abweichungen erkennt.
| Aspekt | Traditionelle Suche | KI-Suche |
|---|---|---|
| Umgang mit Duplikaten | Konsolidiert Autoritätssignale | Clustert und wählt einen Repräsentanten aus |
| Penalty-Risiko | Mögliche manuelle Maßnahme | Keine Strafe, aber Sichtbarkeitsverlust |
| Update-Erkennung | Allmähliche Signalweitergabe | Erkennt Änderungen evtl. nicht, wenn Unterschiede minimal |
| Crawl-Effizienz | Verschwendet Budget für Duplikate | Reduziert Crawl-Priorität für Duplikate |
| Canonical-Respekt | Wird beachtet, aber nicht garantiert | Entscheidend für Cluster-Auswahl |
Neuveröffentlichung ohne geeignete Schutzmaßnahmen bringt drei miteinander verbundene Risiken mit sich, die die KI-Sichtbarkeit direkt beeinträchtigen:
Verdünnung von Intent-Signalen: Wenn derselbe Inhalt über mehrere URLs erscheint, erhält das KI-System widersprüchliche Signale, welche Version die Anfrage des Nutzers am besten beantwortet. Statt die Autorität auf eine einzelne URL zu konzentrieren, verteilen sich die Signale über das Cluster. Diese Verdünnung senkt den Confidence Score, den KI-Systeme beim Entscheiden über die Aufnahme Ihrer Inhalte vergeben. Ein Inhalt, der Hauptquelle sein könnte, wird zur Nebensache, weil das System nicht sicher feststellen kann, welche Version maßgeblich ist.
Repräsentationsrisiko: Die Auswahl des KI-Systems, welche Seite Ihr Inhalts-Cluster repräsentiert, muss nicht Ihren Geschäftszielen entsprechen. Sie veröffentlichen beispielsweise einen Blogartikel über ein Syndikationsnetzwerk, um Traffic zu generieren, doch das KI-System wählt Ihre Originaldomain – oder schlimmer noch: Die syndizierte Version, die keinen Link zurück zu Ihrer Seite enthält. Diese Fehlzuordnung bedeutet, dass Ihre Republishing-Strategie Ihrer Sichtbarkeit eher schadet als nützt.
Update-Latenz und Veraltung: Wenn Sie Ihren Originalinhalt aktualisieren, die republizierten Versionen jedoch unverändert bleiben, kann das KI-System eine veraltete Version als Repräsentanten auswählen. Der Clustering-Algorithmus erkennt nicht immer, dass eine Version aktueller oder genauer ist, besonders wenn die Änderungen inkrementell statt strukturell sind. So kann es passieren, dass Ihr aktuellster, akkuratester Inhalt unsichtbar bleibt, während eine ältere Version Ihre Expertise für KI-Systeme repräsentiert.
Der häufigste Fehler bei der Neuveröffentlichung tritt auf, wenn Inhalte auf Drittplattformen syndiziert werden, ohne Canonical-Tags zu implementieren. Ein typisches Szenario: Ein B2B-Softwareunternehmen veröffentlicht einen umfassenden Leitfaden auf dem eigenen Blog und syndiziert diesen dann an Branchenpublikationen wie Medium, LinkedIn und spezialisierte News-Aggregatoren. Jede Plattform hostet identische Inhalte unter unterschiedlichen URLs. Ohne Canonical-Tags, die auf das Original verweisen, behandelt der Clustering-Algorithmus der KI alle Versionen als gleichwertig. Die Syndikationsplattform könnte eine höhere Domain-Autorität haben und wird so vom KI-System als Repräsentant gewählt. Ihr Originalinhalt – die Version, die Sie optimiert, aktualisiert und mit Backlinks versehen haben – wird in den KI-Suchergebnissen unsichtbar. Der Traffic und die Autorität fließen zur Syndikationsplattform statt zu Ihrer eigenen Seite. Dieses Szenario wiederholt sich tausendfach täglich in der Verlagsbranche – Publisher sabotieren unwissentlich ihre Sichtbarkeit, weil sie ein einziges HTML-Tag nicht setzen.
Kampagnenspezifische Inhalte verursachen ein besonders tückisches Duplicate-Content-Problem, wenn sie kanalübergreifend neu veröffentlicht werden. Ein Marketingteam startet eine Kampagnen-Landingpage für eine bestimmte Aktion und veröffentlicht Varianten davon in E-Mail-Newslettern, Social Media, bezahlten Anzeigen und bei Partnerseiten. Jede Version enthält leicht abweichende Texte, CTAs oder Formatierungen – aber der Kerninhalt und die Intention sind identisch. KI-Systeme erkennen diese als Near-Duplicates und clustern sie zusammen. Das Problem verschärft sich, wenn Kampagnenseiten ohne korrekte Canonical-Implementierung neu veröffentlicht werden. Das KI-System könnte die Newsletter-Version (ohne Conversion-Tracking) als Repräsentanten wählen oder die Partnerseiten-Version, von der Sie keinen Nutzen haben. Zudem kann das KI-System, wenn Kampagnen enden und Seiten archiviert oder gelöscht werden, bereits eine jetzt veraltete Version als Repräsentant ausgewählt haben – Ihr Inhalt wird unsichtbar oder leitet Nutzer auf defekte Seiten.
Regionale Neuveröffentlichung bringt Komplexität, da die Erkennung doppelter Inhalte legitime Lokalisierungsbedürfnisse berücksichtigen muss. Ein Unternehmen mit Niederlassungen in mehreren Ländern veröffentlicht denselben Kerninhalt in verschiedenen Sprachen oder mit regionalen Varianten. Ohne korrekte Implementierung konkurrieren diese regionalen Versionen beim KI-Clustering miteinander. Beispiel: Ein SaaS-Unternehmen veröffentlicht einen Funktionsleitfaden auf seiner US-Domain auf Englisch und dann auf der UK-Domain in britischem Englisch und mit regionaler Preisgestaltung. Die KI clustert diese als Duplikate und könnte die US-Version auch für UK-Nutzer auswählen. Die Lösung ist die Implementierung von hreflang-Tags, um KI-Systemen regionale Beziehungen zu signalisieren, wobei deren Wirksamkeit in der KI-Suche weniger gesichert ist als in der traditionellen Suche.
<!-- Auf der US-Version (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Auf der UK-Version (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
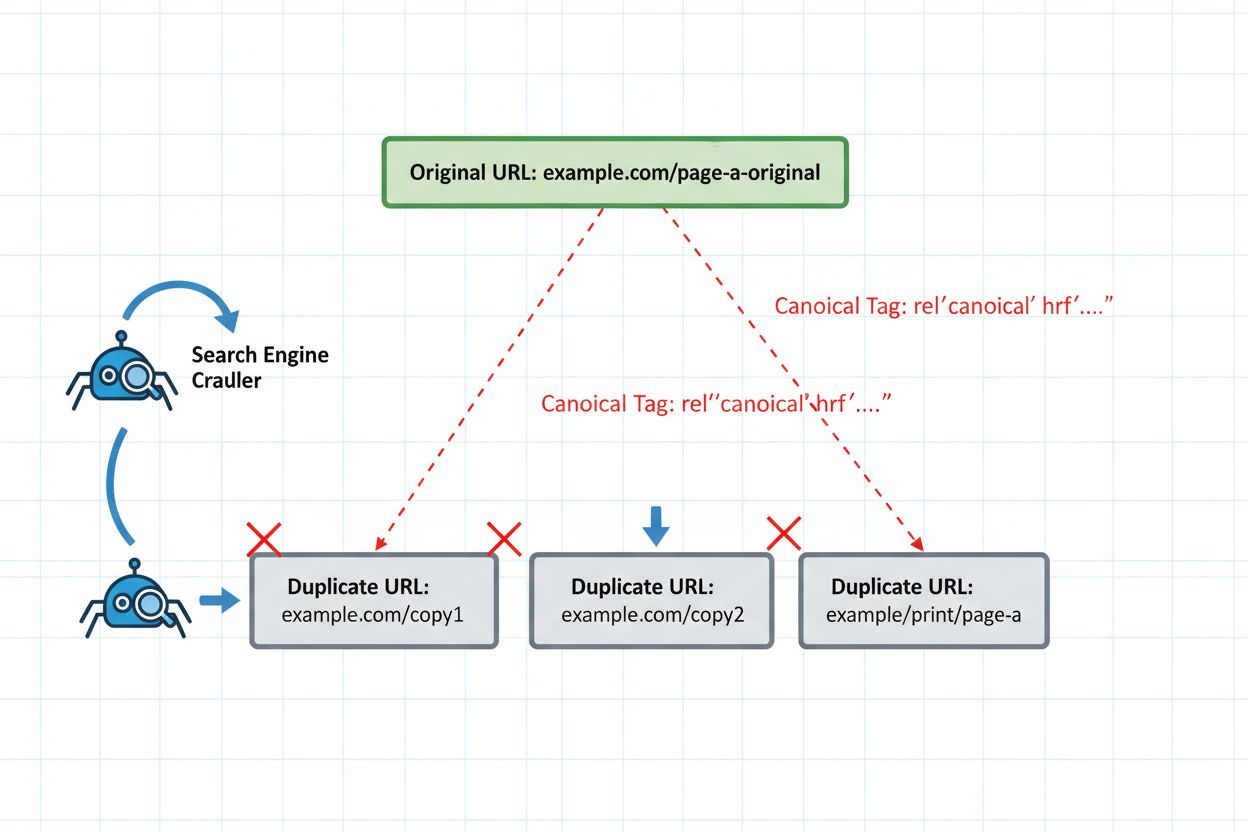
Die Implementierung technischer Schutzmaßnahmen ist für sicheres Republishing unerlässlich. Das Canonical-Tag bleibt Ihr wichtigster Schutz – es teilt KI-Systemen explizit mit, welche Version Ihr Inhalts-Cluster repräsentieren soll. Platzieren Sie das Canonical-Tag im <head> jeder neu veröffentlichten Version und verweisen Sie auf die bevorzugte, maßgebliche Version. Für syndizierte Inhalte bedeutet das meist einen Verweis auf Ihre Originaldomain.
<!-- Auf der syndizierten Version (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Für Inhalte, die niemals mit anderen Versionen konkurrieren sollen, setzen Sie auf den sekundären Versionen noindex. Dadurch werden diese komplett aus dem KI-Index entfernt und können nicht als Repräsentantenseiten ausgewählt werden. Nutzen Sie dies für interne Duplikate, Testversionen oder syndizierte Inhalte, bei denen Sie keine Sichtbarkeit in der KI-Suche wünschen.
<!-- Auf der sekundären Version, die nicht indexiert werden soll -->
<meta name="robots" content="noindex, follow" />
301-Weiterleitungen sind das stärkste Signal zur Konsolidierung von Autorität, sollten aber nur verwendet werden, wenn die sekundäre Version nie unabhängig aktualisiert wird. Weiterleitungen signalisieren KI-Systemen, dass die alte URL dauerhaft umgezogen ist, und konsolidieren alle Signale am neuen Ort. Wenn jedoch beide Versionen online bleiben müssen (wie bei Syndikation), sind Weiterleitungen problematisch, weil sie die URL-Struktur der Syndikationsplattform unterbrechen.
# In .htaccess oder Server-Konfiguration
Redirect 301 /old-article https://yoursite.com/new-article
Bei Content-Management-Systemen implementieren Sie rel=“canonical” dynamisch, um Paginierung, Parameter-Varianten und sessionbasierte URLs, die unbeabsichtigte Duplikate erzeugen, abzudecken. Viele CMS erzeugen für denselben Inhalt mehrere URLs durch unterschiedliche Navigationspfade – Canonical-Tags konsolidieren diese automatisch.
IndexNow beschleunigt die Erkennung kanonischer Signale und die Konsolidierung von Duplikaten, sodass Aufgaben, die traditionell Wochen dauern, in wenigen Tagen erledigt werden. Wenn Sie Canonical-Tags bei neu veröffentlichten Inhalten implementieren, informiert IndexNow Suchsysteme sofort, dass diese URLs zusammengehören. Anstatt zu warten, bis Crawler die kanonische Beziehung durch normales Crawling entdecken, übermittelt IndexNow diese Information direkt an Microsofts Index und andere teilnehmende Suchsysteme. Besonders bei der nachträglichen Korrektur von Republishing-Fehlern ist das wertvoll – Sie können Canonical-Tags setzen und mit IndexNow die Änderung sofort signalisieren, statt auf den nächsten Crawl zu warten. Für Publisher, die Inhalte auf mehreren Plattformen verwalten, wird IndexNow zum entscheidenden Werkzeug, um die Kontrolle über die Repräsentanz ihres Inhalt-Clusters zu behalten. Die API-Integration ermöglicht das Einreichen vieler URLs auf einmal, was die Verwaltung von Hunderten oder Tausenden neu veröffentlichter Seiten praktikabel macht.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Um zu verfolgen, welche Version Ihrer neu veröffentlichten Inhalte von KI-Systemen ausgewählt wird, benötigen Sie Monitoring über traditionelle Analytics hinaus. Richten Sie Tracking ein, um zu erkennen, wann KI-Systeme Ihre Inhalte zitieren oder referenzieren, und notieren Sie, welche URL in KI-Suchergebnissen erscheint. Tools wie Semrush, Ahrefs und Moz beginnen damit, Sichtbarkeitsmetriken für die KI-Suche zu integrieren, auch wenn diese noch weniger ausgereift sind als klassische Such-Tracking-Tools. Setzen Sie UTM-Parameter auf syndizierten Versionen, um die Traffic-Attribution zu verfolgen – aber beachten Sie, dass KI-Systeme diese Parameter womöglich nicht weitergeben, was die direkte Attribution erschwert. Überwachen Sie Ihre Search Console (oder entsprechende Tools anderer Suchsysteme) auf Crawling-Muster: Werden sekundäre Versionen häufiger gecrawlt als Ihre kanonische Version, deutet das darauf hin, dass das KI-System die falsche Repräsentantenseite gewählt hat. Richten Sie Alerts für Erwähnungen Ihrer Inhalte auf Syndikationsplattformen ein und gleichen Sie diese mit Ihrer KI-Sichtbarkeit ab, um Diskrepanzen zwischen Auftrittsort und KI-Auswahl zu erkennen.
Setzen Sie vor jeder Neuveröffentlichung diese Checkliste um, um die Kontrolle über Ihre KI-Sichtbarkeit zu behalten:
Vor der Neuveröffentlichung bestimmen Sie Ihre kanonische Version – die URL, die in der KI-Suche Ihre Inhalte repräsentieren soll. Das ist in der Regel Ihre eigene Domain, nicht eine Syndikationsplattform. Setzen Sie Canonical-Tags auf jeder neu veröffentlichten Version, die auf Ihre kanonische URL verweisen, auch wenn Sie auf eigenen Properties (verschiedene Domains, Subdomains oder Parameter-Varianten) neu veröffentlichen. Nutzen Sie IndexNow, um Suchsysteme sofort über die kanonische Beziehung zu informieren, statt auf den nächsten Crawl zu warten. Vermeiden Sie die Neuveröffentlichung auf hochautoritären Plattformen ohne Canonical-Unterstützung – manche Plattformen entfernen Canonical-Tags oder erlauben diese nicht, was sie für Republishing untauglich macht, wenn Sie keine Sichtbarkeit verlieren wollen. Überwachen Sie die ersten 48 Stunden nach der Neuveröffentlichung, um sicherzustellen, dass KI-Systeme die gewünschte kanonische Version und nicht eine Alternative auswählen. Aktualisieren Sie alle Versionen gleichzeitig, wenn Sie Inhalte ändern – aktualisieren Sie nur die kanonische Version, erkennt der Clustering-Algorithmus die Änderung eventuell nicht in allen Versionen und wählt möglicherweise eine veraltete Version aus. Legen Sie einen Republishing-Zeitplan fest, der verhindert, dass Inhalte auf sekundären Plattformen veralten; veraltete syndizierte Inhalte erhöhen das Risiko, dass KI-Systeme diese als Repräsentanten wählen, wenn Ihre kanonische Version nicht kürzlich aktualisiert wurde.
Canonical-Tags verhindern keine Strafen, da doppelte Inhalte ohnehin keine Strafen auslösen. Allerdings sind Canonical-Tags für die KI-Suche entscheidend, weil sie KI-Systemen signalisieren, welche Version Ihre Inhaltsgruppe repräsentieren soll. Ohne Canonical-Tags kann es passieren, dass KI-Systeme eine unerwünschte Version als maßgebliche Quelle auswählen, was Ihre Sichtbarkeit verringert.
Überwachen Sie, welche URLs in KI-Suchergebnissen und Zitierungen für Ihre Inhalte erscheinen. Tools wie Semrush und Ahrefs integrieren Sichtbarkeitsmetriken für die KI-Suche. Prüfen Sie Ihre Search Console auf Crawling-Muster – werden sekundäre Versionen häufiger gecrawlt als Ihre kanonische Version, könnte das KI-System die falsche Seite ausgewählt haben.
Technisch gesehen ja, aber es ist nicht zu empfehlen. Ohne Canonical-Tags gruppieren KI-Systeme Ihre Inhalte und wählen eine Version als Repräsentant – aber Sie haben keinen Einfluss darauf, welche. Die Syndikationsplattform hat möglicherweise eine höhere Autorität, sodass die KI diese Version statt Ihrer ursprünglichen Domain auswählt.
Neuveröffentlichung bezieht sich im Allgemeinen darauf, dass Sie Ihre Inhalte über verschiedene Kanäle verbreiten, die Sie kontrollieren oder mit Partnern teilen. Content-Syndizierung ist eine spezielle Form der Neuveröffentlichung, bei der Drittplattformen Ihre Inhalte mit Ihrer Erlaubnis erneut veröffentlichen. Beide führen zu Problemen mit doppelten Inhalten, wenn sie nicht korrekt mit Canonical-Tags verwaltet werden.
Canonical-Tags werden in der Regel innerhalb von 24-48 Stunden erkannt, wenn Sie IndexNow nutzen, um Suchsysteme sofort zu benachrichtigen. Ohne IndexNow kann es Wochen dauern, bis Crawler die kanonische Beziehung entdecken. Deshalb ist IndexNow für das Management von neu veröffentlichten Inhalten so wichtig – es beschleunigt den Prozess erheblich.
Verwenden Sie 301-Weiterleitungen nur, wenn Sie URLs dauerhaft zusammenführen möchten und die sekundäre Version nie unabhängig aktualisiert wird. Nutzen Sie Canonical-Tags, wenn beide Versionen online bleiben sollen (wie bei Syndizierung). Weiterleitungen sind stärkere Signale, brechen aber die Funktionalität der sekundären URL.
Ja, wenn sie nicht korrekt verwaltet wird. Neuveröffentlichung ohne Canonical-Tags verwässert die Autoritätssignale über mehrere URLs. KI-Systeme könnten statt Ihrer Originalversion die syndizierte Variante auswählen, was die Sichtbarkeit Ihrer eigenen Domain reduziert. Eine korrekte Canonical-Implementierung verhindert das.
Setzen Sie auf jeder neu veröffentlichten Version Canonical-Tags, die auf Ihre Originaldomain verweisen. Nutzen Sie IndexNow, um Suchsysteme sofort über die kanonische Beziehung zu informieren. Vermeiden Sie die Neuveröffentlichung auf Plattformen, die keine Canonical-Tags unterstützen. Überwachen Sie, welche Versionen von KI-Systemen in den ersten 48 Stunden ausgewählt werden, und passen Sie ggf. an.
Verfolgen Sie, wie KI-Systeme Ihre neu veröffentlichten Inhalte plattformübergreifend zitieren und referenzieren. Erhalten Sie Echtzeit-Einblicke, welche Version von der KI als maßgebliche Quelle ausgewählt wird.
Erfahren Sie, wie kanonische URLs Duplicate-Content-Probleme in KI-Suchsystemen verhindern. Entdecken Sie Best Practices für die Implementierung von Canonicals,...

Erfahren Sie, wie Sie Inhalte für KI-Plattformen wie ChatGPT, Perplexity und Claude umnutzen und optimieren. Entdecken Sie Strategien für KI-Sichtbarkeit, Inhal...
Erfahren Sie, wie Sie doppelten Content beim Einsatz von KI-Tools verwalten und vermeiden. Entdecken Sie kanonische Tags, Weiterleitungen, Erkennungstools und B...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.