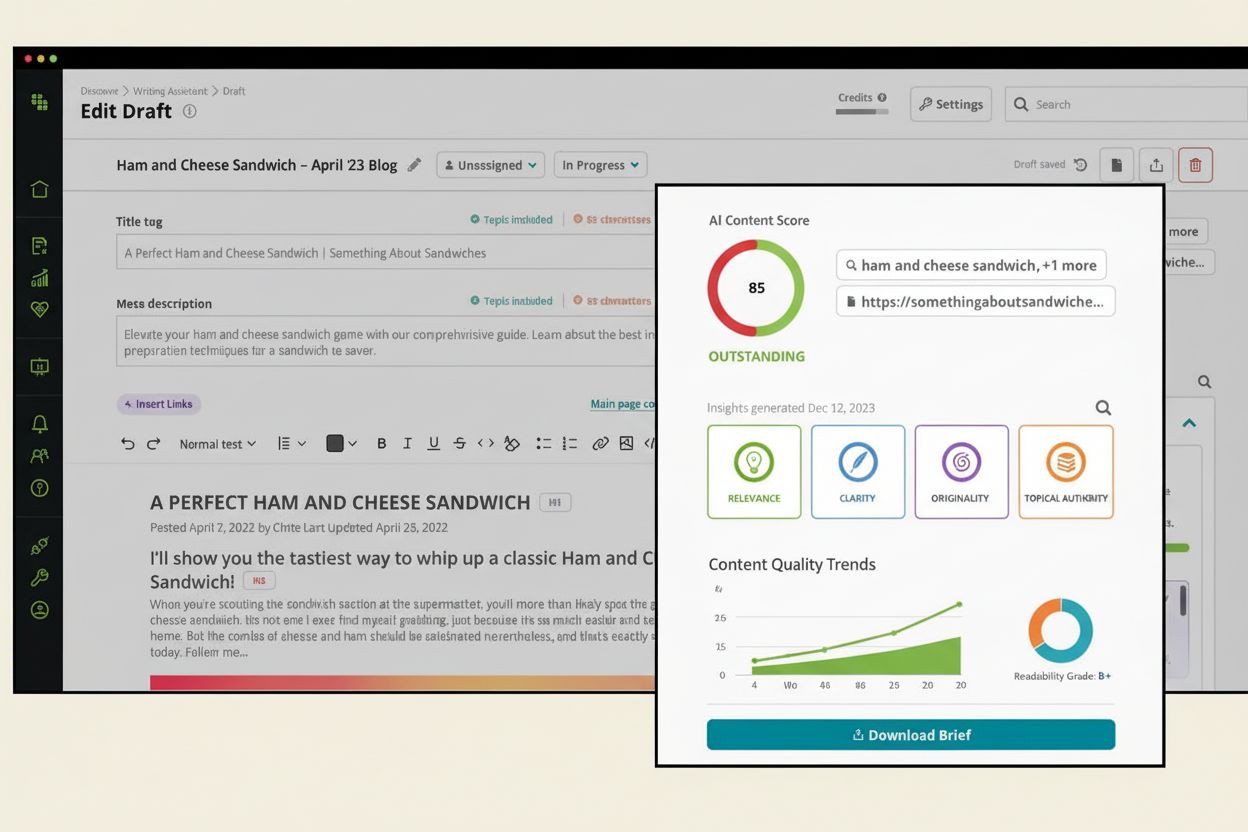
AI-Content-Score
Erfahren Sie, was ein AI-Content-Score ist, wie er die Inhaltsqualität für KI-Systeme bewertet und warum er für die Sichtbarkeit in ChatGPT, Perplexity und ande...
11 Min. Lesezeit

KI-Retrieval-Scoring ist der Prozess der Quantifizierung der Relevanz und Qualität abgerufener Dokumente oder Passagen in Bezug auf eine Benutzeranfrage. Es verwendet ausgefeilte Algorithmen, um semantische Bedeutung, kontextuelle Angemessenheit und Informationsqualität zu bewerten und bestimmt, welche Quellen an Sprachmodelle zur Antwortgenerierung in RAG-Systemen weitergegeben werden.
KI-Retrieval-Scoring ist der Prozess der Quantifizierung der Relevanz und Qualität abgerufener Dokumente oder Passagen in Bezug auf eine Benutzeranfrage. Es verwendet ausgefeilte Algorithmen, um semantische Bedeutung, kontextuelle Angemessenheit und Informationsqualität zu bewerten und bestimmt, welche Quellen an Sprachmodelle zur Antwortgenerierung in RAG-Systemen weitergegeben werden.
KI-Retrieval-Scoring ist der Prozess, die Relevanz und Qualität abgerufener Dokumente oder Passagen in Bezug auf eine Benutzeranfrage oder Aufgabe zu quantifizieren. Im Gegensatz zum einfachen Keyword-Matching, das nur oberflächliche Überschneidungen von Begriffen identifiziert, nutzt Retrieval-Scoring ausgefeilte Algorithmen, um semantische Bedeutung, kontextuelle Angemessenheit und Informationsqualität zu bewerten. Dieser Bewertungsmechanismus ist grundlegend für Retrieval-Augmented Generation (RAG)-Systeme, da er bestimmt, welche Quellen an Sprachmodelle zur Antwortgenerierung weitergegeben werden. In modernen LLM-Anwendungen beeinflusst das Retrieval-Scoring direkt die Antwortgenauigkeit, die Reduzierung von Halluzinationen und die Benutzerzufriedenheit, indem es sicherstellt, dass nur die relevantesten Informationen die Generierungsphase erreichen. Die Qualität des Retrieval-Scorings ist daher ein kritischer Faktor für die Gesamtleistung und Zuverlässigkeit des Systems.
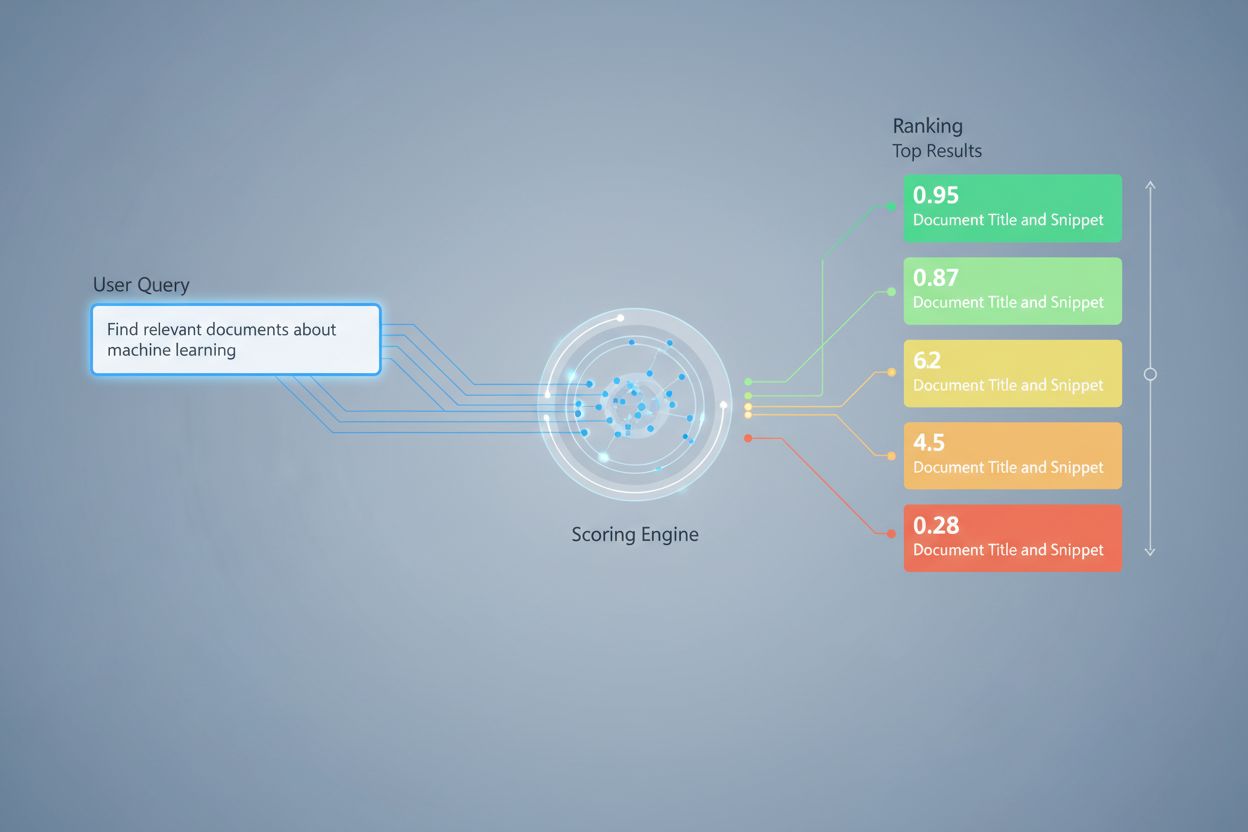
Retrieval-Scoring nutzt verschiedene algorithmische Ansätze, die jeweils unterschiedliche Stärken für verschiedene Anwendungsfälle bieten. Semantisches Ähnlichkeitsscoren verwendet Embedding-Modelle, um die konzeptuelle Übereinstimmung zwischen Anfragen und Dokumenten im Vektorraum zu messen und so Bedeutungen jenseits von Keywords zu erfassen. BM25 (Best Matching 25) ist eine probabilistische Ranking-Funktion, die Termfrequenz, inverse Dokumentfrequenz und Dokumentlängennormalisierung berücksichtigt und sich für klassische Textsuche als sehr effektiv erwiesen hat. TF-IDF (Termfrequenz-Inverse Dokumentfrequenz) gewichtet Begriffe nach ihrer Bedeutung innerhalb eines Dokuments und in der Gesamtheit der Sammlung, hat jedoch keine semantische Tiefe. Hybride Ansätze kombinieren mehrere Methoden – etwa die Zusammenführung von BM25- und semantischen Scores – um sowohl lexikalische als auch semantische Signale zu nutzen. Neben den Bewertungsmethoden liefern Evaluationsmetriken wie Precision@k (Prozentsatz relevanter Ergebnisse unter den Top-k), Recall@k (Prozentsatz aller relevanten Dokumente in den Top-k), NDCG (Normalized Discounted Cumulative Gain, berücksichtigt die Position im Ranking) und MRR (Mean Reciprocal Rank) quantitative Messungen der Retrieval-Qualität. Das Verständnis der jeweiligen Vor- und Nachteile – etwa die Effizienz von BM25 im Vergleich zum tieferen Verständnis des semantischen Scorings – ist entscheidend für die Auswahl der passenden Methode für spezifische Anwendungen.
| Bewertungsmethode | Funktionsweise | Am besten geeignet für | Hauptvorteil |
|---|---|---|---|
| Semantische Ähnlichkeit | Vergleicht Embeddings mit Kosinus-Ähnlichkeit oder anderen Distanzmetriken | Konzeptbedeutung, Synonyme, Paraphrasen | Erkennt semantische Beziehungen jenseits von Keywords |
| BM25 | Probabilistisches Ranking, berücksichtigt Termfrequenz und Dokumentlänge | Exakte Phrasenübereinstimmung, Keyword-basierte Anfragen | Schnell, effizient, bewährt in Produktionssystemen |
| TF-IDF | Gewichtet Begriffe nach Häufigkeit im Dokument und Seltenheit in der Sammlung | Klassisches Information Retrieval | Einfach, interpretierbar, ressourcenschonend |
| Hybrides Scoring | Kombiniert semantische und schlüsselwortbasierte Ansätze mit gewichteter Fusion | Allgemeine Suche, komplexe Anfragen | Verbindet die Stärken mehrerer Methoden |
| LLM-basiertes Scoring | Nutzt Sprachmodelle zur Beurteilung der Relevanz mit eigenen Prompts | Komplexe Kontextbewertung, domänenspezifische Aufgaben | Erkennt nuancierte semantische Beziehungen |
In RAG-Systemen erfolgt das Retrieval-Scoring auf mehreren Ebenen, um die Generierungsqualität sicherzustellen. Das System bewertet meist einzelne Chunks oder Passagen innerhalb von Dokumenten, was eine fein abgestufte Relevanzbewertung ermöglicht, anstatt ganze Dokumente als atomare Einheiten zu betrachten. Diese Relevanzbewertung pro Chunk erlaubt es, nur die relevantesten Informationssegmente zu extrahieren und so Störgeräusche und irrelevanten Kontext zu reduzieren, die das Sprachmodell verwirren könnten. RAG-Systeme implementieren häufig Scoring-Schwellenwerte oder Cutoff-Mechanismen, um schlecht bewertete Ergebnisse vor der Generierung auszufiltern und so zu verhindern, dass minderwertige Quellen die finale Antwort beeinflussen. Die Qualität des abgerufenen Kontexts korreliert direkt mit der Generierungsqualität – hoch bewertete, relevante Passagen führen zu genaueren, fundierten Antworten, während minderwertige Retrievals Halluzinationen und Faktenfehler einbringen. Die Überwachung von Retrieval-Scores liefert Frühwarnsignale für Systemverschlechterungen und ist eine wichtige Kennzahl für das KI-Antwortmonitoring und die Qualitätssicherung in Produktionssystemen.
Re-Ranking dient als zweite Filterstufe, die die initialen Retrieval-Ergebnisse verfeinert und oft die Rankinggenauigkeit deutlich erhöht. Nachdem ein erster Retriever Kandidatenergebnisse mit vorläufigen Scores erzeugt hat, wendet ein Re-Ranker ausgefeiltere Bewertungslogiken an, um diese Kandidaten neu zu ordnen oder zu filtern – meist mit rechenintensiveren Modellen, die eine tiefergehende Analyse erlauben. Reciprocal Rank Fusion (RRF) ist eine beliebte Technik, die Rankings mehrerer Retriever kombiniert, indem sie Scores basierend auf der Ergebnisposition vergibt und diese zu einem einheitlichen Ranking zusammenführt, das oft die Einzelretriever übertrifft. Score-Normalisierung ist entscheidend, wenn Ergebnisse verschiedener Retrieval-Methoden kombiniert werden, da rohe Scores von BM25, semantischer Ähnlichkeit und anderen Ansätzen auf unterschiedlichen Skalen arbeiten und auf vergleichbare Bereiche kalibriert werden müssen. Ensemble-Retriever-Ansätze nutzen gleichzeitig mehrere Retrieval-Strategien, wobei das Re-Ranking die finale Sortierung auf Basis der kombinierten Evidenz bestimmt. Dieser mehrstufige Ansatz verbessert Genauigkeit und Robustheit des Rankings erheblich gegenüber einstufigem Retrieval – besonders in komplexen Domänen, in denen unterschiedliche Methoden komplementäre Relevanzsignale erfassen.
Precision@k: Misst den Anteil relevanter Dokumente unter den Top-k-Ergebnissen; nützlich zur Beurteilung, ob die abgerufenen Ergebnisse vertrauenswürdig sind (z. B. Precision@5 = 4/5 bedeutet, 80% der Top-5-Ergebnisse sind relevant)
Recall@k: Berechnet den Prozentsatz aller relevanten Dokumente, die in den Top-k-Ergebnissen gefunden wurden; wichtig für eine umfassende Abdeckung aller relevanten Informationen
Hit Rate: Binäre Metrik, die anzeigt, ob mindestens ein relevantes Dokument unter den Top-k-Ergebnissen ist; nützlich für schnelle Qualitätschecks in Produktivsystemen
NDCG (Normalized Discounted Cumulative Gain): Berücksichtigt die Rankingposition, indem relevante Dokumente an früherer Stelle höher bewertet werden; reicht von 0–1 und ist ideal zur Bewertung der Rankingqualität
MRR (Mean Reciprocal Rank): Misst die durchschnittliche Position des ersten relevanten Ergebnisses über mehrere Anfragen hinweg; besonders nützlich, um zu beurteilen, ob das relevanteste Dokument hoch eingestuft wird
F1-Score: Harmonisches Mittel von Precision und Recall; bietet eine ausgewogene Bewertung, wenn sowohl False Positives als auch False Negatives gleich wichtig sind
MAP (Mean Average Precision): Mittelt die Precision-Werte an jeder Position, an der ein relevantes Dokument gefunden wird; umfassende Metrik für die Gesamtqualität des Rankings über mehrere Anfragen hinweg
LLM-basiertes Relevanz-Scoring nutzt Sprachmodelle selbst als Richter für die Dokumentenrelevanz und bietet eine flexible Alternative zu klassischen algorithmischen Ansätzen. In diesem Paradigma geben sorgfältig gestaltete Prompts einem LLM die Anweisung, zu bewerten, ob eine abgerufene Passage eine bestimmte Anfrage beantwortet. Das Modell erzeugt entweder binäre Relevanzwerte (relevant/nicht relevant) oder numerische Werte (z. B. eine Skala von 1–5 zur Angabe der Relevanzstärke). Dieser Ansatz erfasst nuancierte semantische Beziehungen und domänenspezifische Relevanz, die klassische Algorithmen möglicherweise übersehen – insbesondere bei komplexen Anfragen, die tiefes Verständnis erfordern. LLM-basiertes Scoring birgt jedoch Herausforderungen wie hohe Rechenkosten (LLM-Inferenz ist deutlich teurer als Embedding-Ähnlichkeit), potenzielle Inkonsistenzen zwischen verschiedenen Prompts und Modellen sowie den Bedarf an Kalibrierung mit menschlichen Labels, um die Scores an die tatsächliche Relevanz anzugleichen. Trotz dieser Einschränkungen hat sich LLM-basiertes Scoring als wertvoll für die Bewertung der RAG-Systemqualität und zur Erstellung von Trainingsdaten für spezialisierte Bewertungsmodelle erwiesen und ist damit ein wichtiges Werkzeug im KI-Monitoring zur Beurteilung der Antwortqualität.
Die effektive Umsetzung von Retrieval-Scoring erfordert die sorgfältige Berücksichtigung mehrerer praktischer Faktoren. Die Wahl der Methode hängt von den Anforderungen des Anwendungsfalls ab: Semantisches Scoring ist unschlagbar im Erfassen von Bedeutungen, benötigt aber Embedding-Modelle, während BM25 Geschwindigkeit und Effizienz für lexikalische Übereinstimmungen bietet. Der Trade-off zwischen Geschwindigkeit und Genauigkeit ist entscheidend – Scoring auf Basis von Embeddings liefert eine überlegene Relevanzbewertung, verursacht aber höhere Latenz, während BM25 und TF-IDF schneller, aber semantisch weniger ausgereift sind. Rechenkosten umfassen Modell-Inferenzzeiten, Speicherbedarf und Infrastruktur-Skalierung, was insbesondere bei großvolumigen Produktionssystemen wichtig ist. Parametertuning beinhaltet das Anpassen von Schwellenwerten, Gewichten in hybriden Ansätzen und Re-Ranking-Cutoffs zur Optimierung der Performance für bestimmte Domänen und Anwendungsfälle. Die kontinuierliche Überwachung der Bewertungsleistung mit Metriken wie NDCG und Precision@k trägt dazu bei, Verschlechterungen frühzeitig zu erkennen, proaktive Verbesserungen zu ermöglichen und eine gleichbleibend hohe Antwortqualität in Produktiv-RAG-Systemen sicherzustellen.
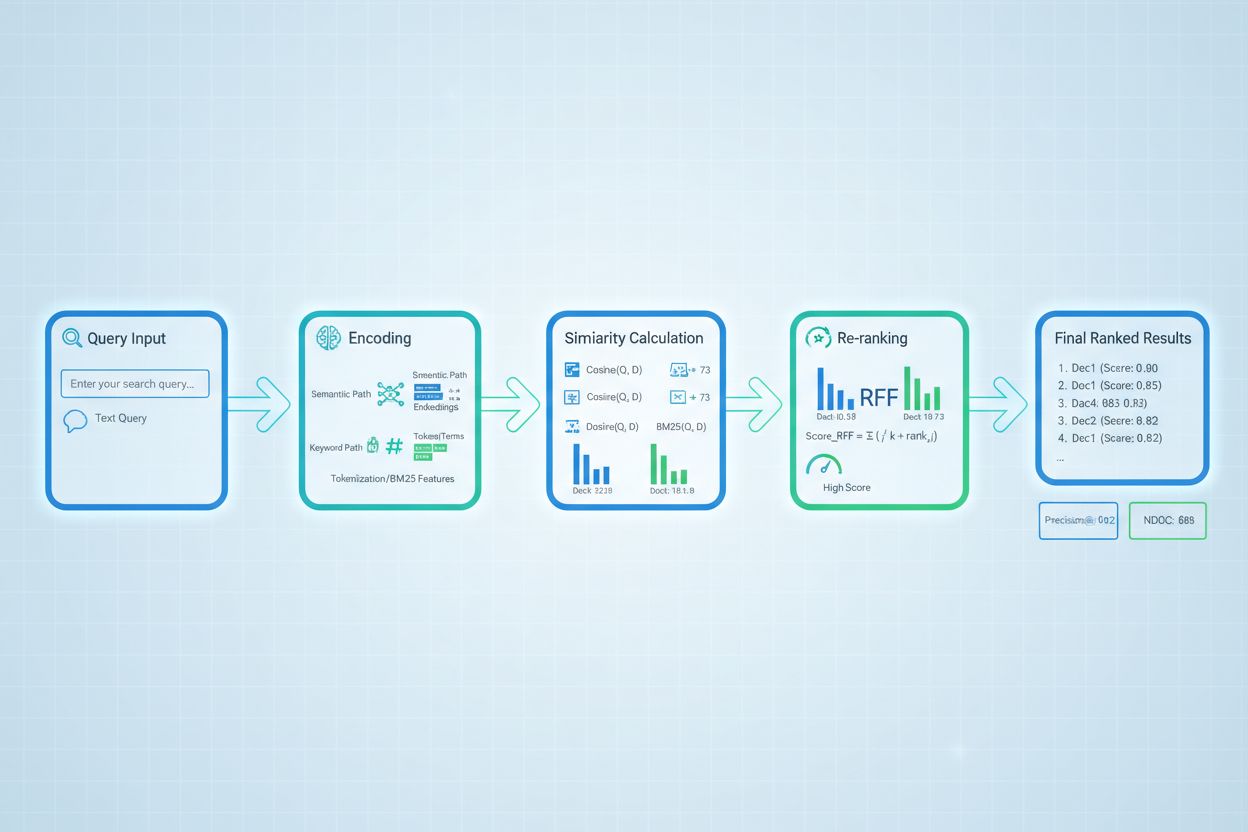
Fortgeschrittene Retrieval-Scoring-Techniken gehen über die grundlegende Relevanzbewertung hinaus und erfassen komplexe Kontextbeziehungen. Query Rewriting kann die Bewertung verbessern, indem Benutzeranfragen in mehrere semantisch gleichwertige Formen umgewandelt werden, sodass der Retriever relevante Dokumente findet, die bei wortwörtlicher Abfrage übersehen würden. Hypothetical Document Embeddings (HyDE) erzeugen synthetische relevante Dokumente aus Anfragen und nutzen diese Hypotheticals, um das Scoring zu verbessern, indem reale Dokumente gefunden werden, die dem idealisierten Inhalt ähneln. Multi-Query-Ansätze reichen mehrere Varianten einer Anfrage beim Retriever ein und aggregieren die Scores, was die Robustheit und Abdeckung gegenüber Einzelabfragen erhöht. Domänenspezifische Bewertungsmodelle, die auf gelabelten Daten aus bestimmten Branchen oder Wissensbereichen trainiert wurden, erzielen oft eine überlegene Performance gegenüber Generalistenmodellen – besonders wertvoll für spezialisierte Anwendungen wie medizinische oder juristische KI-Systeme. Kontextuelle Score-Anpassungen berücksichtigen Faktoren wie Aktualität des Dokuments, Autorität der Quelle und Nutzerkontext und ermöglichen so eine anspruchsvollere Relevanzbewertung, die über reine semantische Ähnlichkeit hinausgeht und reale Relevanzfaktoren für KI-Systeme im Produktionseinsatz einbezieht.
Retrieval-Scoring weist Dokumenten auf Basis ihrer Beziehung zu einer Anfrage numerische Relevanzwerte zu, während das Ranking Dokumente anhand dieser Werte anordnet. Scoring ist der Bewertungsprozess, Ranking das Sortierergebnis. Beide sind für RAG-Systeme unerlässlich, um präzise Antworten zu liefern.
Retrieval-Scoring bestimmt, welche Quellen das Sprachmodell zur Antwortgenerierung erreichen. Hochwertige Bewertungen sorgen dafür, dass relevante Informationen ausgewählt werden, reduzieren Halluzinationen und verbessern die Antwortgenauigkeit. Schlechte Bewertungen führen zu irrelevanten Kontexten und unzuverlässigen KI-Antworten.
Semantisches Scoring nutzt Embeddings, um konzeptuelle Bedeutungen zu verstehen und Synonyme sowie verwandte Konzepte zu erfassen. Schlüsselwortbasiertes Scoring (wie BM25) gleicht exakte Begriffe und Phrasen ab. Semantisches Scoring eignet sich besser zum Erfassen von Intentionen, während Keyword-Scoring beim Finden spezifischer Informationen glänzt.
Wichtige Metriken sind Precision@k (Genauigkeit der Top-Ergebnisse), Recall@k (Abdeckung relevanter Dokumente), NDCG (Ranking-Qualität) und MRR (Position des ersten relevanten Ergebnisses). Wählen Sie Metriken je nach Anwendungsfall: Precision@k für qualitätsorientierte Systeme, Recall@k für umfassende Abdeckung.
Ja, LLM-basiertes Scoring verwendet Sprachmodelle als Richter der Relevanz. Dieser Ansatz erfasst nuancierte semantische Beziehungen, ist jedoch rechnerisch aufwendig. Er ist wertvoll zur Bewertung der RAG-Qualität und zur Erstellung von Trainingsdaten, erfordert jedoch eine Kalibrierung mit menschlichen Labels.
Re-Ranking wendet eine zweite Filterung mit ausgefeilteren Modellen an, um die ersten Ergebnisse zu verfeinern. Techniken wie Reciprocal Rank Fusion kombinieren mehrere Retrieval-Methoden und verbessern Genauigkeit und Robustheit. Re-Ranking übertrifft einstufiges Retrieval deutlich in komplexen Domänen.
BM25 und TF-IDF sind schnell und ressourcenschonend, geeignet für Echtzeitsysteme. Semantisches Scoring benötigt Inferenz von Embedding-Modellen und erhöht die Latenz. LLM-basiertes Scoring ist am teuersten. Wählen Sie abhängig von Ihren Latenzanforderungen und verfügbaren Ressourcen.
Beachten Sie Ihre Prioritäten: Semantisches Scoring für bedeutungsorientierte Aufgaben, BM25 für Geschwindigkeit und Effizienz, hybride Ansätze für ausgewogene Leistung. Bewerten Sie in Ihrer Domäne mit Metriken wie NDCG und Precision@k. Testen Sie mehrere Methoden und messen Sie deren Einfluss auf die Antwortqualität.
Verfolgen Sie, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Ihre Marke referenzieren und die Qualität ihres Source Retrievals und Rankings bewerten. Stellen Sie sicher, dass Ihre Inhalte von KI-Systemen korrekt zitiert und eingestuft werden.
Erfahren Sie, was ein AI-Content-Score ist, wie er die Inhaltsqualität für KI-Systeme bewertet und warum er für die Sichtbarkeit in ChatGPT, Perplexity und ande...

Erfahren Sie, was ein KI-Sichtbarkeits-Score ist, wie er die Präsenz Ihrer Marke in KI-generierten Antworten auf Plattformen wie ChatGPT, Perplexity und anderen...
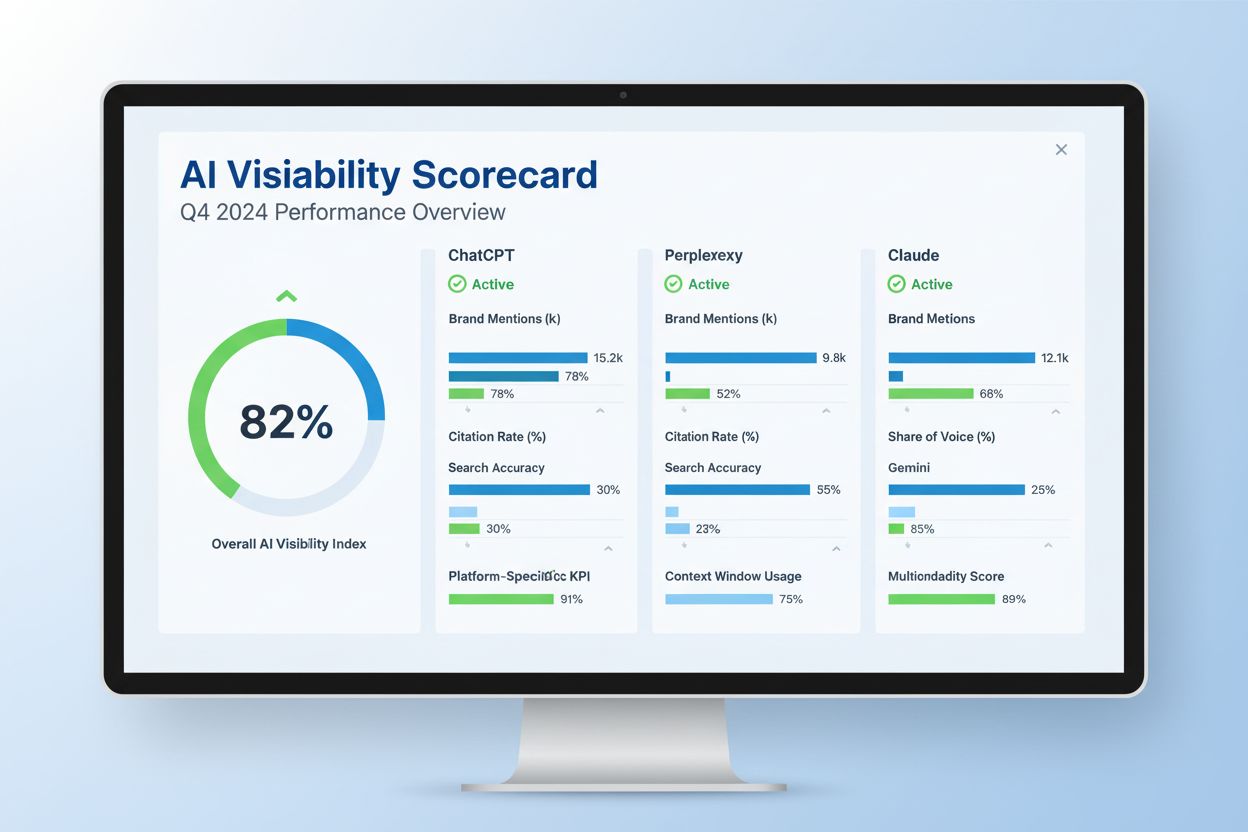
Erfahren Sie, was ein AI-Sichtbarkeits-Score ist und wie er die Präsenz Ihrer Marke auf ChatGPT, Perplexity, Claude und anderen KI-Plattformen misst. Ein unverz...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.