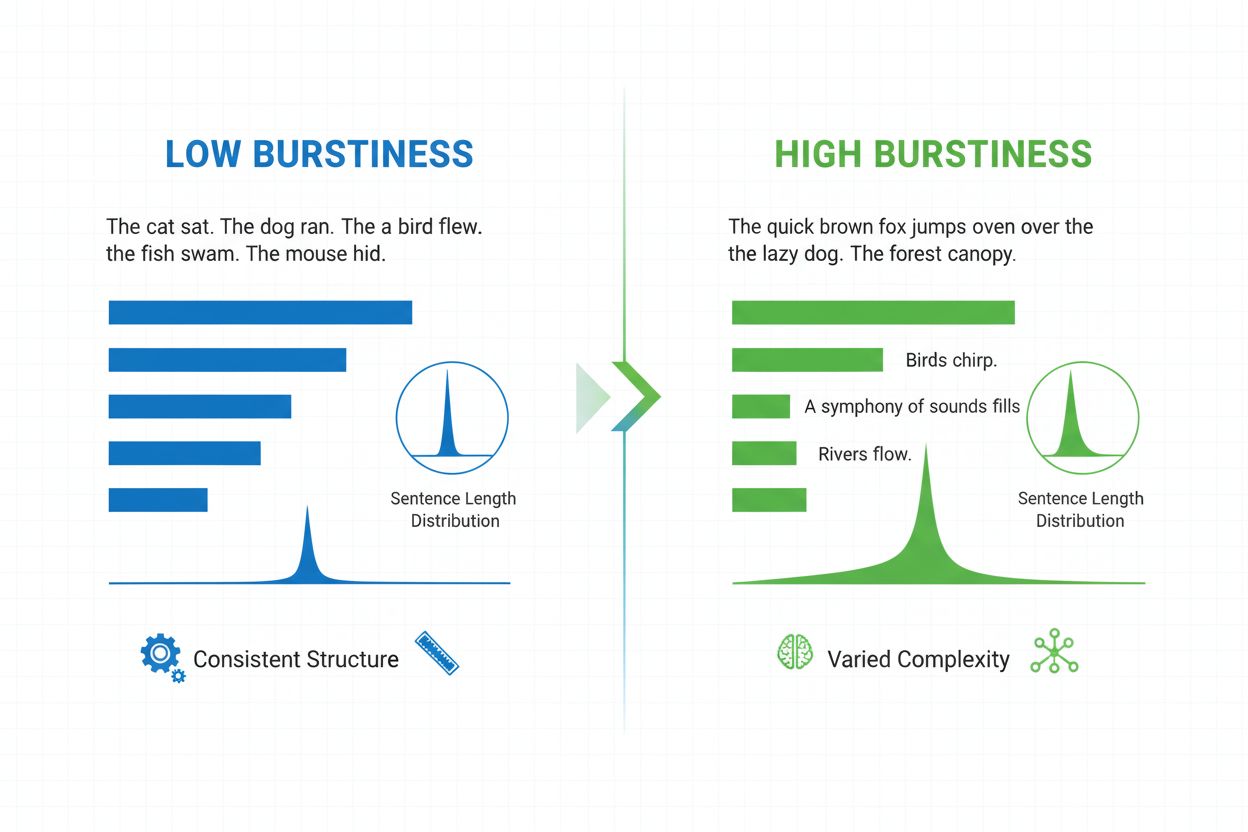
Definition von Burstiness
Burstiness ist eine quantifizierbare linguistische Metrik, die die Variabilität und Schwankung der Satzlänge, -struktur und -komplexität in einem geschriebenen Dokument oder Textabschnitt misst. Der Begriff stammt aus dem Konzept von „Bursts“ unterschiedlicher Satzmuster – dem Wechsel zwischen kurzen, prägnanten und längeren, komplexeren Sätzen. Im Kontext der Verarbeitung natürlicher Sprache und der Erkennung von KI-Inhalten dient Burstiness als entscheidender Indikator dafür, ob ein Text von einem Menschen geschrieben oder von einem KI-System generiert wurde. Menschliche Autoren erzeugen von Natur aus Texte mit hoher Burstiness, da sie ihre Satzkonstruktionen instinktiv je nach Betonung, Tempo und stilistischer Absicht variieren. Im Gegensatz dazu weisen KI-generierte Texte typischerweise eine geringe Burstiness auf, weil Sprachmodelle auf statistischen Mustern trainiert werden, die auf Konsistenz und Vorhersehbarkeit abzielen. Das Verständnis von Burstiness ist für Content-Ersteller, Lehrkräfte, Forschende und Organisationen, die KI-generierte Inhalte auf Plattformen wie ChatGPT, Perplexity, Google AI Overviews und Claude überwachen, essenziell.
Historischer Kontext und Entwicklung
Das Konzept der Burstiness entstand aus der Forschung in der Computerlinguistik und Informationstheorie, in der Wissenschaftler versuchten, die statistischen Eigenschaften natürlicher Sprache zu quantifizieren. Frühe Arbeiten in der Stilometrie – der statistischen Analyse von Schreibstilen – zeigten, dass menschliches Schreiben charakteristische Variationsmuster aufweist, die sich grundlegend von maschinell generierten Texten unterscheiden. Mit der zunehmenden Raffinesse von großen Sprachmodellen (LLMs) in den frühen 2020er Jahren erkannten Forscher, dass Burstiness in Kombination mit Perplexity (einem Maß für die Wortvorhersehbarkeit) als zuverlässiger Indikator für KI-generierte Inhalte dienen kann. Laut Forschungsergebnissen von QuillBot und akademischen Einrichtungen nutzen mittlerweile rund 78 % der Unternehmen KI-gestützte Content-Monitoring-Tools, die Burstiness-Analysen in ihre Erkennungsalgorithmen einbinden. Die Stanford-Studie von 2023 zu TOEFL-Aufsätzen zeigte, dass Burstiness-basierte Erkennungsmethoden zwar nützlich sind, aber erhebliche Einschränkungen haben – insbesondere hinsichtlich Fehlalarmen bei nicht-muttersprachlichem Englisch. Diese Forschung trieb die Entwicklung fortschrittlicher, mehrschichtiger KI-Erkennungssysteme voran, die Burstiness zusammen mit anderen sprachlichen Markern, semantischer Kohärenz und Kontextangemessenheit berücksichtigen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technische Erklärung der Burstiness-Messung
Burstiness wird berechnet, indem die statistische Verteilung von Satzlängen und Strukturmustern innerhalb eines Textes analysiert wird. Die Metrik quantifiziert die Varianz – sie misst also, wie stark einzelne Sätze von der durchschnittlichen Satzlänge in einem Dokument abweichen. Ein Dokument mit hoher Burstiness enthält Sätze, die sich stark in ihrer Länge unterscheiden; ein Autor könnte beispielsweise auf einen Dreiwortsatz („Na?“) einen 25-Wörter-Satz mit mehreren Nebensätzen folgen lassen. Geringe Burstiness bedeutet hingegen, dass die meisten Sätze eine ähnliche Länge haben, typischerweise zwischen zwölf und achtzehn Wörtern, was einen monotonen Rhythmus erzeugt. Die Berechnung erfolgt in mehreren Schritten: Zunächst wird die Länge jedes Satzes in Wörtern gemessen, dann der Mittelwert (Durchschnitt) der Satzlänge berechnet und schließlich die Standardabweichung ermittelt, die anzeigt, wie stark einzelne Sätze vom Mittelwert abweichen. Eine höhere Standardabweichung steht für größere Variation und damit höhere Burstiness. Moderne KI-Detektoren wie Winston AI und Pangram verwenden ausgefeilte Algorithmen, die nicht nur Wörter zählen, sondern auch die syntaktische Komplexität – also die Anordnung von Teilsätzen, Phrasen und grammatischen Elementen – analysieren. Diese tiefergehende Analyse zeigt, dass menschliche Autoren vielfältige Satzstrukturen (einfache, zusammengesetzte, komplexe und zusammengesetzt-komplexe Sätze) in unvorhersehbaren Mustern einsetzen, während KI-Modelle dazu neigen, bestimmte Strukturvorlagen zu bevorzugen, die in ihren Trainingsdaten häufig vorkommen.
Burstiness vs. Perplexity: Vergleichende Analyse
| Metrik | Burstiness | Perplexity | Messfokus |
|---|
| Definition | Variation in Satzlänge und -struktur | Vorhersehbarkeit einzelner Wörter | Satzebene vs. Wortebene |
| Menschliches Schreiben | Hoch (abwechslungsreiche Strukturen) | Hoch (unvorhersehbare Wörter) | Natürlicher Rhythmus und Wortschatz |
| KI-generierter Text | Niedrig (einheitliche Strukturen) | Niedrig (vorhersehbare Wörter) | Statistische Konsistenz |
| Erkennungsanwendung | Erkennt strukturelle Monotonie | Erkennt Muster in der Wortwahl | Komplementäre Erkennungsmethoden |
| Fehlalarmrisiko | Höher bei Nicht-Muttersprachlern | Höher bei technischem/akademischem Schreiben | Beide haben Einschränkungen |
| Berechnungsmethode | Standardabweichung der Satzlängen | Analyse von Wahrscheinlichkeitsverteilungen | Verschiedene mathematische Ansätze |
| Verlässlichkeit allein | Nicht ausreichend für eindeutige Erkennung | Nicht ausreichend für eindeutige Erkennung | Am effektivsten in Kombination |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wie KI-Sprachmodelle niedrige Burstiness erzeugen
Große Sprachmodelle wie ChatGPT, Claude und Google Gemini werden durch einen Prozess namens Next-Token-Prediction trainiert, bei dem das Modell lernt, das statistisch wahrscheinlichste nächste Wort nach einer bestimmten Sequenz vorherzusagen. Während des Trainings werden diese Modelle explizit darauf optimiert, die Perplexity auf ihren Trainingsdatensätzen zu minimieren, was als Nebenprodukt eine niedrige Burstiness erzeugt. Wenn ein Modell eine bestimmte Satzstruktur in seinen Trainingsdaten wiederholt antrifft, lernt es, diese Struktur mit hoher Wahrscheinlichkeit zu reproduzieren, was zu konsistenten, vorhersehbaren Satzlängen führt. Forschungen von Netus AI und Winston AI zeigen, dass KI-Modelle einen charakteristischen stilometrischen Fingerabdruck aufweisen, der sich durch einheitliche Satzkonstruktionen, Übernutzung von Übergangsphrasen (wie „Außerdem“, „Daher“, „Zusätzlich“) und eine Vorliebe für das Passiv statt des Aktivs auszeichnet. Die Abhängigkeit der Modelle von Wahrscheinlichkeitsverteilungen führt dazu, dass sie zu den häufigsten Mustern in ihren Trainingsdaten tendieren, anstatt das gesamte Spektrum möglicher Satzkonstruktionen auszuschöpfen. Das schafft eine paradoxe Situation: Je mehr Daten ein Modell trainiert, desto mehr lernt es, gängige Muster zu reproduzieren, und desto niedriger wird seine Burstiness. Zudem fehlt KI-Modellen die Spontaneität und emotionale Variation, die menschliches Schreiben kennzeichnet – sie schreiben nicht anders, wenn sie begeistert, verärgert oder einen bestimmten Punkt betonen wollen. Stattdessen behalten sie eine konsistente stilistische Grundlinie bei, die das statistische Zentrum ihrer Trainingsverteilung widerspiegelt.
Burstiness in KI-Erkennungssystemen
KI-Erkennungsplattformen haben Burstiness-Analysen als zentralen Bestandteil ihrer Algorithmen integriert, allerdings mit unterschiedlicher Ausgereiftheit. Frühere Erkennungssysteme stützten sich stark auf Burstiness und Perplexity als Hauptmetriken, doch Forschungen zeigten erhebliche Einschränkungen dieses Ansatzes. Nach Pangram Labs erzeugen Detektoren, die auf Perplexity und Burstiness basieren, Fehlalarme, wenn sie Texte aus den Trainingsdatensätzen von Sprachmodellen analysieren – insbesondere wird die Unabhängigkeitserklärung häufig als KI-generiert eingestuft, da sie so oft in den Trainingsdaten erscheint, dass das Modell eine durchgängig niedrige Perplexity zuweist. Moderne Erkennungssysteme wie Winston AI und Pangram nutzen heute hybride Ansätze, die Burstiness-Analysen mit Deep-Learning-Modellen kombinieren, die auf vielfältigen, menschlich und KI-generierten Textproben trainiert wurden. Diese Systeme analysieren mehrere sprachliche Dimensionen gleichzeitig: Variation der Satzstruktur, lexikalische Vielfalt (Wortschatzreichtum), Interpunktionsmuster, Kontextkohärenz und semantische Übereinstimmung. Die Integration von Burstiness in umfassendere Erkennungsframeworks hat die Genauigkeit erheblich gesteigert – Winston AI berichtet über 99,98 % Genauigkeit bei der Unterscheidung von KI-generierten und menschlich geschriebenen Inhalten, indem mehrere Marker analysiert werden statt sich allein auf Burstiness zu verlassen. Dennoch bleibt die Metrik als Bestandteil einer umfassenden Erkennungsstrategie wertvoll, besonders in Kombination mit der Analyse von Perplexity, stilometrischen Mustern und semantischer Konsistenz.
Praktische Anwendungen und Best Practices
- Content-Erstellung: Autoren können Satzlänge und -struktur gezielt variieren, um ansprechendere, menschlich klingende Inhalte zu schaffen, die Leser fesseln und KI-Erkennungsmarkierungen vermeiden
- Akademisches Schreiben: Studierende und Forschende sollten unterschiedliche Satzkonstruktionen einsetzen, um ihre Schreibkompetenz zu zeigen und Fehlalarme durch KI-Erkennungssysteme in Bildungseinrichtungen zu vermeiden
- SEO und Content Marketing: Verlage können die Qualität ihrer Inhalte und das Ranking in Suchmaschinen verbessern, indem sie die Burstiness steigern, was mit höheren Lesbarkeitswerten und besseren Nutzungsmetriken korreliert
- Marken-Monitoring: Organisationen, die Plattformen wie AmICited nutzen, können Burstiness-Muster in KI-generierten Antworten analysieren, um festzustellen, ob ihre Marken-Nennungen in authentisch menschlich geschriebenen oder maschinell generierten Texten erscheinen
- KI-Erkennung und Verifikation: Lehrkräfte, Verlage und Content-Moderatoren können Burstiness-Analysen als eines von mehreren Signalen nutzen, um potenziell KI-generierte Einreichungen zu identifizieren und die Authentizität von Inhalten zu bewahren
- Schreibverbesserung: Autoren können Burstiness-Metriken als Feedback nutzen, um ihren Stil zu verfeinern und das Leserengagement durch natürlichen Rhythmus und abwechslungsreiche Satzkonstruktionen zu erhalten
- Sprachlernen: Lehrende im Bereich Englisch als Fremdsprache können Lernenden vermitteln, dass abwechslungsreiche Satzstrukturen eine fortgeschrittene Sprachkompetenz darstellen und zu natürlicherem, authentischerem Englisch beitragen
Burstiness und Lesbarkeitsmetriken
Die Beziehung zwischen Burstiness und Lesbarkeit ist in der linguistischen Forschung gut belegt. Die Flesch Reading Ease- und Flesch-Kincaid Grade Level-Werte, die die Zugänglichkeit von Texten messen, korrelieren stark mit Burstiness-Mustern. Texte mit höherer Burstiness erreichen tendenziell bessere Lesbarkeitswerte, da die Variation der Satzlänge kognitive Ermüdung verhindert und die Aufmerksamkeit der Leser aufrechterhält. Wenn Leser auf einen gleichmäßigen Rhythmus ähnlich langer Sätze treffen, gewöhnt sich das Gehirn an ein vorhersehbares Muster, was zu Desinteresse und vermindertem Verständnis führen kann. Hohe Burstiness erzeugt hingegen einen Wechsel aus Spannung und Entspannung, der die Leser mental durch wechselnde kognitive Belastung aktiviert – kurze Sätze bieten schnell verdauliche Informationen, während längere Sätze komplexe Ideen und Nuancen vermitteln. Untersuchungen von Metrics Masters zeigen, dass hohe Burstiness etwa 15–20 % bessere Gedächtnisleistung im Vergleich zu Texten mit niedriger Burstiness erzeugt, da das abwechslungsreiche Rhythmusgefühl Informationen effektiver im Langzeitgedächtnis verankert. Dieses Prinzip gilt für alle Textsorten: Blogbeiträge, wissenschaftliche Artikel, Werbetexte und technische Dokumentationen profitieren von strategischer Burstiness. Allerdings ist die Beziehung nicht linear – übermäßige Burstiness, die Variation über Klarheit stellt, kann Texte abgehackt und schwer verständlich machen. Der optimale Ansatz besteht in zielgerichteter Variation, bei der die Wahl der Satzstruktur dem Inhalt und der Absicht des Autors dient und nicht allein einer Metrik.
Einschränkungen und Kritik an Burstiness-basierter Erkennung
Trotz ihrer weiten Verbreitung in KI-Erkennungssystemen hat die Burstiness-basierte Erkennung erhebliche Einschränkungen, die Forschende und Praktiker kennen sollten. Pangram Labs veröffentlichte umfassende Forschung, die fünf Hauptschwächen zeigt: Erstens werden Texte aus KI-Trainingsdatensätzen fälschlicherweise als KI-generiert klassifiziert, da Modelle darauf optimiert sind, die Perplexity auf Trainingsdaten zu minimieren; zweitens sind Burstiness-Werte modellabhängig, sodass verschiedene Modelle unterschiedliche Perplexity-Profile erzeugen; drittens geben proprietäre Modelle wie ChatGPT keine Token-Wahrscheinlichkeiten preis, wodurch die Berechnung der Perplexity unmöglich wird; viertens werden Nicht-Muttersprachler im Englischen überproportional als KI-generiert eingestuft, da ihre Satzstrukturen gleichförmiger sind; und fünftens können Burstiness-basierte Detektoren sich nicht iterativ mit zusätzlichen Daten selbst verbessern. Die Stanford-Studie 2023 zu TOEFL-Aufsätzen fand heraus, dass etwa 26 % der nicht-muttersprachlichen englischen Texte fälschlicherweise als KI-generiert durch Perplexity- und Burstiness-Detektoren eingestuft wurden, verglichen mit nur 2 % Fehlalarme bei muttersprachlichen Texten. Diese Voreingenommenheit wirft in Bildungskontexten, in denen KI-Erkennung zur Bewertung studentischer Leistungen eingesetzt wird, erhebliche ethische Fragen auf. Darüber hinaus weisen vorlagenbasierte Inhalte im Marketing, wissenschaftlichen Schreiben und in technischer Dokumentation naturgemäß eine geringere Burstiness auf, da Styleguides und Strukturkonventionen Konsistenz verlangen – auch hier entstehen Fehlalarme. Diese Einschränkungen haben zur Entwicklung fortschrittlicher Erkennungsansätze geführt, die Burstiness als ein Signal unter vielen und nicht als endgültigen Indikator für KI-Generierung betrachten.
Burstiness in verschiedenen Schreibkontexten
Burstiness-Muster unterscheiden sich deutlich zwischen Schreibgenres und Kontexten, was die unterschiedlichen kommunikativen Zwecke und Publikumserwartungen jeder Domäne widerspiegelt. Akademisches Schreiben, insbesondere in MINT-Fächern, weist tendenziell eine geringere Burstiness auf, da Autoren strengen Styleguides folgen und einheitliche Strukturvorlagen zur Klarheit und Präzision nutzen. Juristische Dokumente, technische Spezifikationen und wissenschaftliche Arbeiten legen Wert auf Konsistenz und Vorhersehbarkeit statt auf stilistische Variation, was zu von Natur aus geringeren Burstiness-Werten führt. Im Gegensatz dazu zeigen kreatives Schreiben, Journalismus und Marketingtexte meist hohe Burstiness, da diese Genres durch abwechslungsreiches Tempo und Rhythmus das Engagement und die emotionale Wirkung beim Leser steigern wollen. Besonders die literarische Belletristik nutzt dramatische Wechsel in der Satzlänge, um Akzente zu setzen, Spannung aufzubauen und das Erzähltempo zu steuern. Geschäftskommunikation nimmt eine Mittelstellung ein – professionelle E-Mails und Berichte weisen eine moderate Burstiness auf, um Klarheit und Engagement auszubalancieren. Der Flesch-Kincaid Grade Level-Wert zeigt, dass akademische Texte für ein hochgebildetes Publikum oft längere, komplexere Sätze verwenden, was scheinbar die Burstiness reduziert; dennoch erzeugen Variation in Nebensatzstrukturen und Unterordnungsmustern bedeutende Burstiness. Das Verständnis dieser kontextuellen Unterschiede ist für KI-Erkennungssysteme essenziell, um genrespezifische Schreibkonventionen zu berücksichtigen und Fehlalarme zu vermeiden. Ein technisches Handbuch mit durchweg langen Sätzen sollte nicht allein wegen niedriger Burstiness als KI-generiert eingestuft werden – die niedrige Burstiness spiegelt angemessene stilistische Entscheidungen für das Genre wider, nicht maschinelle Generierung.
Zukünftige Entwicklung und strategische Implikationen
Die Zukunft der Burstiness-Analyse in der KI-Erkennung entwickelt sich hin zu ausgefeilteren, kontextsensitiven Ansätzen, die die Begrenzungen der Metrik anerkennen und gleichzeitig ihre Erkenntnisse nutzen. Da große Sprachmodelle immer fortschrittlicher werden, beginnen sie, Burstiness-Variation in ihre Ausgaben zu integrieren, wodurch die Erkennung ausschließlich anhand dieser Metrik weniger zuverlässig wird. Forschende entwickeln adaptive Erkennungssysteme, die Burstiness zusammen mit semantischer Kohärenz, Faktengenauigkeit und Kontextangemessenheit analysieren. Das Aufkommen von KI-Humanisierungstools, die gezielt Burstiness und andere menschenähnliche Charakteristika erhöhen, stellt ein fortlaufendes Wettrüsten zwischen Erkennungs- und Umgehungstechnologien dar. Fachleute gehen jedoch davon aus, dass wirklich zuverlässige KI-Erkennung letztlich auf kryptographischen Verifikationsmethoden und Herkunftsnachweisen beruhen wird, statt allein auf linguistischer Analyse. Für Content-Ersteller und Organisationen ist die strategische Konsequenz klar: Statt Burstiness als zu manipulierende Metrik zu betrachten, sollten Autoren authentische, abwechslungsreiche Schreibstile entwickeln, die natürliche menschliche Kommunikationsmuster widerspiegeln. AmICiteds Monitoring-Plattform steht für eine neue Generation in diesem Bereich, indem sie erfasst, wie Marken in KI-generierten Antworten erscheinen und die sprachlichen Charakteristika dieser Nennungen analysiert. Mit der zunehmenden Verbreitung von KI-Systemen in der Inhaltserstellung und -verbreitung wird das Verständnis von Burstiness und verwandten Metriken immer wichtiger, um Marken-Authentizität zu bewahren, akademische Integrität zu gewährleisten und die Unterscheidung zwischen menschlichen und maschinellen Inhalten zu erhalten. Die Entwicklung hin zu multisignalbasierten Erkennungsansätzen deutet darauf hin, dass Burstiness als ein Bestandteil umfassender KI-Monitoringsysteme relevant bleibt, auch wenn seine Rolle nuancierter und kontextabhängiger wird.