
Entity Recognition
Entity Recognition ist eine KI-NLP-Fähigkeit zur Identifizierung und Kategorisierung benannter Entitäten im Text. Erfahren Sie, wie sie funktioniert, ihre Anwen...
9 Min. Lesezeit

Entitätsdisambiguierung ist der Prozess der Bestimmung, auf welche spezifische Entität eine bestimmte Erwähnung verweist, wenn mehrere Entitäten denselben Namen teilen. Sie hilft KI-Systemen, Inhalte durch die Auflösung von Mehrdeutigkeiten bei Entitätsreferenzen korrekt zu verstehen und zu zitieren, sodass Erwähnungen von „Apple“ eindeutig identifizieren, ob sich die Referenz auf Apple Inc., die Frucht oder eine andere Entität mit demselben Namen bezieht.
Entitätsdisambiguierung ist der Prozess der Bestimmung, auf welche spezifische Entität eine bestimmte Erwähnung verweist, wenn mehrere Entitäten denselben Namen teilen. Sie hilft KI-Systemen, Inhalte durch die Auflösung von Mehrdeutigkeiten bei Entitätsreferenzen korrekt zu verstehen und zu zitieren, sodass Erwähnungen von „Apple“ eindeutig identifizieren, ob sich die Referenz auf Apple Inc., die Frucht oder eine andere Entität mit demselben Namen bezieht.
Entitätsdisambiguierung ist der Prozess der Bestimmung, auf welche spezifische Entität eine bestimmte Erwähnung verweist, wenn mehrere Entitäten denselben Namen oder ähnliche Referenzen teilen. Im Kontext von künstlicher Intelligenz und natürlicher Sprachverarbeitung (NLP) stellt die Entitätsdisambiguierung sicher, dass ein KI-System bei der Begegnung mit einer benannten Entität im Text korrekt erkennt, auf welches reale Objekt, welche Person, Organisation oder welchen Ort Bezug genommen wird. Dies unterscheidet sich grundlegend von der benannten Entitätenerkennung (NER), die lediglich feststellt, dass eine Entität existiert und sie einer Kategorie wie „Person“, „Organisation“ oder „Ort“ zuordnet. Während NER die Frage „Gibt es hier eine Entität?“ beantwortet, stellt die Entitätsdisambiguierung die Frage „Welche spezifische Entität ist das?“. Beispielsweise identifiziert NER im Satz „Apple war das Gehirnkind von Steve Jobs“ „Apple“ als Organisation, aber die Entitätsdisambiguierung bestimmt, ob sich dies auf Apple Inc., das Technologieunternehmen, oder möglicherweise auf eine andere Entität mit demselben Namen bezieht. Diese Unterscheidung ist für KI-Systeme, die Inhalte genau verstehen und zitieren müssen, entscheidend. Deshalb überwacht AmICited.com, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews die Entitätsdisambiguierung bei der Generierung von Antworten über Marken und Organisationen handhaben.
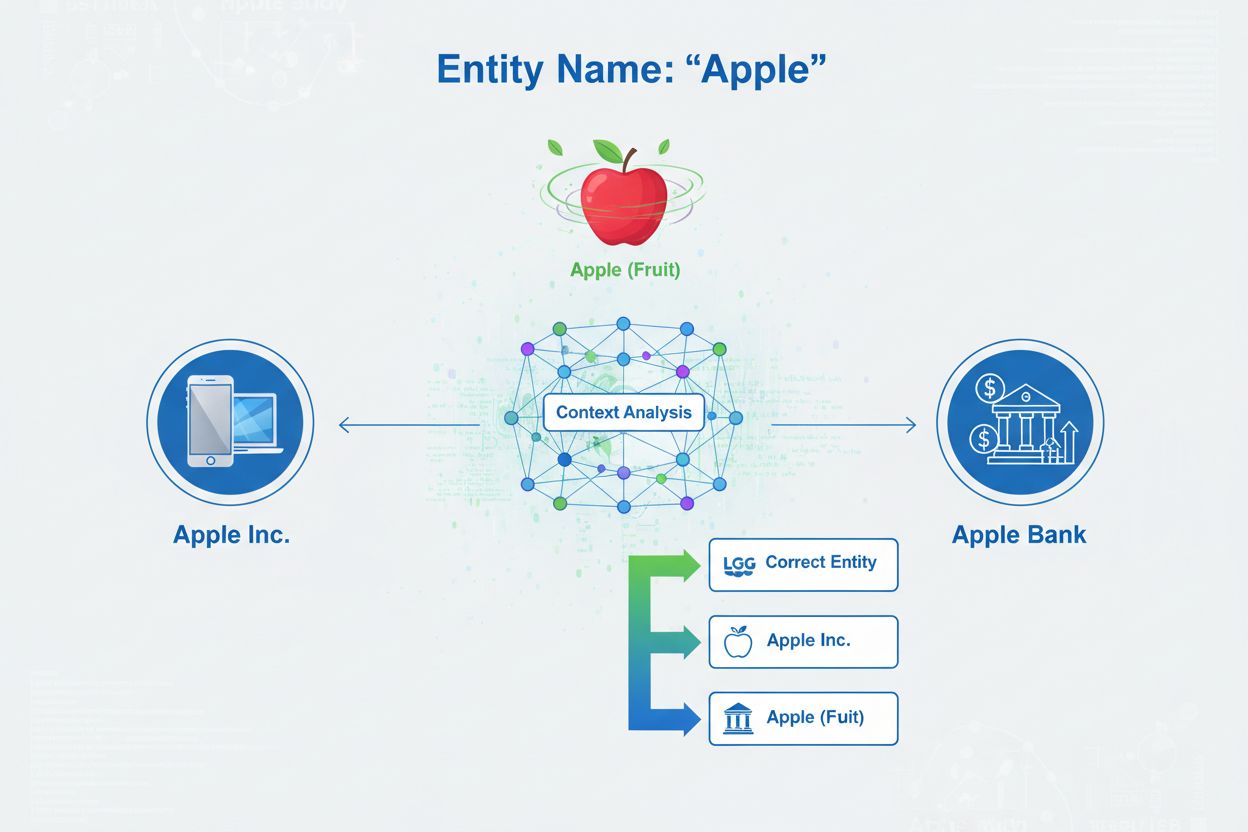
Das grundlegende Problem, das die Entitätsdisambiguierung löst, ist die Mehrdeutigkeit – die Tatsache, dass viele Entitätsnamen auf verschiedene reale Objekte verweisen können. Diese Mehrdeutigkeit stellt KI-Systeme vor große Herausforderungen, wenn sie versuchen, Inhalte korrekt zu verstehen und zu generieren. Laut dem Stanford AI Index 2024 enthalten über 18 % der LLM-Ausgaben, die Markenentitäten betreffen, entweder Halluzinationen oder Fehlzuordnungen von Entitäten, was bedeutet, dass KI-Systeme häufig eine Entität mit einer anderen verwechseln oder falsche Informationen über Entitäten generieren. Diese Fehlerquote hat ernsthafte Auswirkungen auf die Markenrepräsentation und Inhaltsgenauigkeit. Wenn ein KI-System eine Entität falsch identifiziert, kann es falsche Informationen liefern, Aussagen der falschen Organisation zuschreiben oder die korrekte Quelle nicht angeben.
| Entitätsname | Mögliche Bedeutungen | KI-Verwechslungsrate |
|---|---|---|
| Apple | Tech-Unternehmen / Frucht / Bank | Hoch |
| Delta | Fluggesellschaft / Armaturenhersteller / griechischer Buchstabe | Hoch |
| Jaguar | Automobilhersteller / Tierart | Mittel |
| Amazon | E-Commerce-Unternehmen / Regenwald / Fluss | Hoch |
| Orange | Farbe / Frucht / Telekommunikationsunternehmen | Mittel |
Die Folgen einer schlechten Entitätsdisambiguierung gehen über einfache Faktenfehler hinaus. Für Content-Ersteller und Marken kann eine Fehlidentifikation in KI-generierten Antworten zu Sichtbarkeitsverlust, falscher Zuordnung und Rufschädigung führen. Wenn ein Nutzer ein KI-System nach „Delta“ fragt, sucht er möglicherweise Informationen über Delta Airlines, aber wenn das System es mit Delta Faucet Company verwechselt, erhält der Nutzer irrelevante Informationen. Genau deshalb überwacht AmICited.com, wie KI-Systeme Entitäten disambiguieren – um Marken zu helfen zu verstehen, ob sie in KI-generierten Inhalten auf mehreren Plattformen korrekt identifiziert und zitiert werden.
Die Entitätsdisambiguierung erfolgt durch einen systematischen Prozess, der mehrere NLP-Techniken kombiniert, um Mehrdeutigkeiten aufzulösen und Entitäten korrekt zu identifizieren. Das Verständnis dieses Prozesses verdeutlicht, warum einige KI-Systeme die Zitiergenauigkeit besser aufrechterhalten als andere.
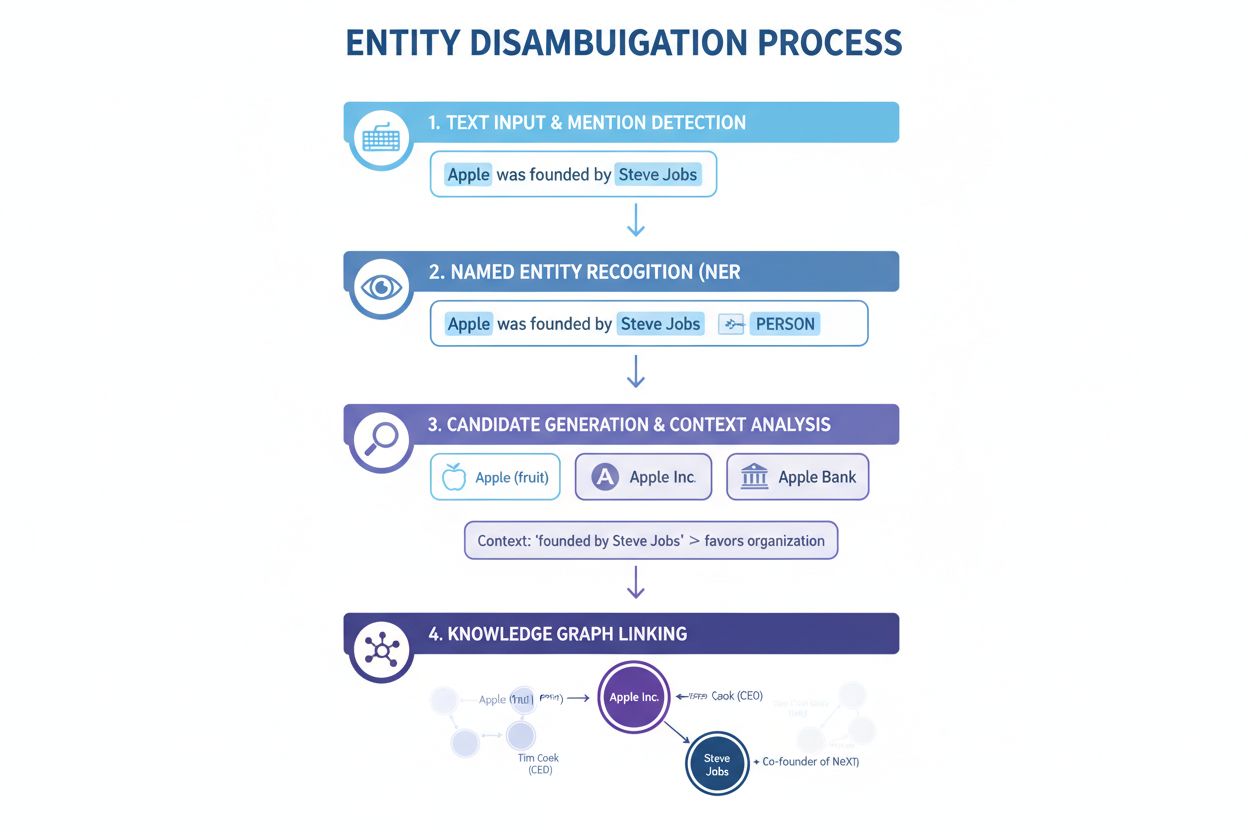
Benannte Entitätenerkennung (NER): Der erste Schritt besteht darin, benannte Entitäten im Text zu identifizieren und zu klassifizieren. NER-Systeme durchsuchen Textdaten und finden Erwähnungen von Entitäten, die sie vordefinierten Kategorien wie Person, Organisation, Ort, Produkt oder Datum zuordnen. Im Satz „Apple war das Gehirnkind von Steve Jobs“ erkennt NER sowohl „Apple“ als auch „Steve Jobs“ als Entitäten und klassifiziert sie als Organisation bzw. Person. Dieser grundlegende Schritt ist essentiell, da ohne die Identifikation der Entitäten keine Disambiguierung erfolgen kann.
Entitätskategorisierung: Nach der Identifikation müssen die Entitäten präziser kategorisiert werden. Dies beinhaltet nicht nur die grobe Klassifizierung, sondern auch das Verständnis des spezifischen Typs und Kontexts jeder Entität. Das System analysiert den umliegenden Text, um zu verstehen, ob „Apple“ in einem Technologiekontext (Apple Inc.), einem Lebensmittelkontext (die Frucht) oder einem Finanzkontext (Apple Bank) erscheint. Diese Kontextanalyse hilft, die Möglichkeiten vor dem eigentlichen Disambiguierungsschritt einzuschränken.
Disambiguierung: Dies ist der Kernschritt, bei dem das System bestimmt, auf welche spezifische Entität verwiesen wird. Das System bewertet mehrere Kandidatenentitäten, die mit dem erkannten Namen übereinstimmen, und nutzt verschiedene Signale – darunter Kontext, Entitätsbeschreibungen, semantische Beziehungen und Wissensgraphinformationen –, um die wahrscheinlich korrekte Entität auszuwählen. Für „Apple war das Gehirnkind von Steve Jobs“ erkennt das System, dass Steve Jobs stark mit Apple Inc. assoziiert ist, was die richtige Disambiguierungsentscheidung darstellt.
Verlinkung mit der Wissensbasis: Im letzten Schritt wird die disambiguierte Entität mit einer eindeutigen Kennung in einer externen Wissensbasis oder einem Wissensgraphen wie Wikidata, Wikipedia oder einer proprietären Datenbank verknüpft. Diese Verlinkung bestätigt die Identität der Entität und reichert den Text mit semantischen Informationen an, die für weitere Verarbeitung und Analyse genutzt werden können. Der Entität wird eine eindeutige URI (Uniform Resource Identifier) zugewiesen, die als endgültiger Bezugspunkt dient.
Im Laufe der Zeit haben sich verschiedene Ansätze zur Entitätsdisambiguierung entwickelt, die jeweils eigene Vorteile und Einschränkungen aufweisen. Das Verständnis dieser Ansätze erklärt, warum moderne KI-Systeme in ihrer Disambiguierungsgenauigkeit variieren.
Regelbasierte Ansätze: Diese Systeme nutzen vordefinierte sprachliche Regeln und Heuristiken zur Disambiguierung von Entitäten. Sie könnten Regeln anwenden wie „Wenn ‚Apple‘ in der Nähe von ‚iPhone‘ oder ‚MacBook‘ erscheint, bezieht es sich auf Apple Inc.“ oder „Wenn ‚Delta‘ in der Nähe von ‚Fluggesellschaft‘ oder ‚Flug‘ erscheint, bezieht es sich auf Delta Airlines.“ Regelbasierte Systeme sind interpretierbar und benötigen keine großen Trainingsdatensätze, haben aber Schwierigkeiten mit neuen Kontexten und können sich ohne manuelle Regelanpassungen nicht an neue Entitätsbedeutungen anpassen.
Maschinelles Lernen: Überwachtes maschinelles Lernen nutzt annotierte Trainingsdaten, um anhand kontextueller Merkmale die korrekte Entität vorherzusagen. Diese Systeme extrahieren Merkmale aus dem umgebenden Text und nutzen Algorithmen wie Support Vector Machines oder Random Forests, um die wahrscheinlichste Entität zu klassifizieren. Maschinelles Lernen ist flexibler als regelbasierte Systeme, erfordert jedoch umfangreiche gelabelte Trainingsdaten und generalisiert möglicherweise nicht gut auf Entitäten, die im Training nicht gesehen wurden.
Deep Learning und Transformer-Modelle: Moderne Entitätsdisambiguierung basiert zunehmend auf Transformer-Architekturen wie BERT, RoBERTa und spezialisierten Modellen wie GENRE und BLINK. Diese Modelle nutzen neuronale Netze, um Kontext auf tieferer Ebene zu verstehen und semantische Beziehungen sowie feine sprachliche Muster zu erfassen. Transformer-Modelle erreichen überlegene Leistungen in Standard-Benchmarks und können komplexe Disambiguierungsszenarien besser handhaben. Beispielsweise verwendet Ontotexts CEEL (Common English Entity Linking) eine Transformer-basierte Architektur, die auf CPU-Effizienz und hohe Genauigkeit optimiert ist und 96 % Entitätenerkennungsgenauigkeit sowie 76 % Entitätsverlinkungsgenauigkeit auf Standard-Benchmarks erreicht.
Integration von Wissensgraphen: Moderne Systeme kombinieren zunehmend maschinelles Lernen mit Wissensgraphen – strukturierten Datenbanken, die Entitäten und deren Beziehungen abbilden. Wissensgraphen liefern umfangreiche Kontextinformationen zu Entitäten, ihren Eigenschaften und ihren Beziehungen zu anderen Entitäten. Durch die Abfrage von Wissensgraphen während der Disambiguierung können Systeme auf Metadaten, Beschreibungen und Beziehungsinformationen zugreifen, was die Auflösung von Mehrdeutigkeiten verbessert.
Entitätsdisambiguierung ist in zahlreichen Branchen und Anwendungsfällen unverzichtbar geworden und bringt überall Vorteile durch die genaue Identifikation und Zitierung von Entitäten.
Suchmaschinen: Google, Bing und andere Suchmaschinen verlassen sich stark auf Entitätsdisambiguierung, um relevante Ergebnisse zu liefern. Wenn ein Nutzer nach „Apple“ sucht, muss die Suchmaschine bestimmen, ob er Apple Inc., die Frucht oder eine andere Entität meint. Suchmaschinen nutzen den Anfragekontext, Nutzerhistorie und Wissensgraphen zur Disambiguierung und liefern so die relevantesten Ergebnisse. Deshalb zeigen die Suchergebnisse für „Apple“ in der Regel das Technologieunternehmen zuerst an – das System hat gelernt, dass dies die am häufigsten gemeinte Entität ist.
Medien und Verlage: Nachrichtenorganisationen und Content-Plattformen nutzen Entitätsdisambiguierung, um die Auffindbarkeit von Inhalten zu verbessern und verwandte Artikel zu verlinken. Wenn in einem Nachrichtenartikel „Apple“ erwähnt wird, kann das System automatisch auf den Wissensbasiseintrag von Apple Inc. verlinken und dem Leser zusätzlichen Kontext sowie verwandte Artikel bieten. Das steigert die Nutzerbindung und hilft, den Gesamtzusammenhang besser zu verstehen.
Gesundheitswesen: Medizinische Einrichtungen verwenden Entitätsdisambiguierung, um Arzneimittel, Krankheiten und medizinische Verfahren in Patientenakten und Fachliteratur korrekt zu identifizieren. Besonders bei Medikamentennamen ist Disambiguierung kritisch – „Aspirin“ kann das generische Medikament, einen bestimmten Markennamen oder eine Dosierungsvariante bezeichnen. Eine genaue Disambiguierung stellt sicher, dass medizinisches Fachpersonal korrekte Informationen erhält und Patientenakten richtig organisiert werden.
Finanzdienstleistungen: Investmentgesellschaften und Finanzanalysten nutzen Entitätsdisambiguierung, um Unternehmensnennungen in Nachrichten, Geschäftsberichten und Marktdaten zu verfolgen. Bei der Marktrisikobewertung muss ein Unternehmen alle Nennungen einer bestimmten Firma in unterschiedlichen Datenquellen exakt identifizieren. Die Entitätsdisambiguierung stellt sicher, dass „Apple“-Nennungen Apple Inc. und nicht anderen Entitäten zugeordnet werden, womit Risikoeinschätzungen und Portfolioanalysen korrekt möglich sind.
E-Commerce: Online-Händler verwenden Entitätsdisambiguierung, um Produktnennungen mit tatsächlichen Produkten im Katalog abzugleichen. Sucht ein Kunde nach „Apple Laptop“, muss das System „Apple“ als Unternehmen disambiguieren und passende Produkte anzeigen. Das verbessert die Suchgenauigkeit und hilft Kunden, Produkte schneller zu finden.
AmICited.com wendet die Prinzipien der Entitätsdisambiguierung an, um zu überwachen, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews Markennennungen behandeln. Indem überprüft wird, ob diese Systeme Marken korrekt disambiguieren und zitieren, hilft AmICited Marken, ihre Sichtbarkeit und Repräsentation in KI-generierten Inhalten zu verstehen.
Wissensgraphen sind heute ein Grundpfeiler moderner Entitätsdisambiguierungssysteme und liefern strukturierte Abbildungen von Entitäten und deren Beziehungen. Ein Wissensgraph ist im Grunde eine Datenbank aus Entitäten (Knoten) und deren Beziehungen (Kanten). Jeder Entitätsknoten enthält Metadaten wie Name, Beschreibung, Typ und Eigenschaften der Entität. So könnte der Knoten „Apple Inc.“ Eigenschaften wie „gegründet 1976“, „Sitz in Cupertino“, „Branche: Technologie“ und Beziehungen wie „gegründet von Steve Jobs“ und „produziert iPhone“ aufweisen.
Wenn ein Disambiguierungssystem auf eine mehrdeutige Entität trifft, kann es den Wissensgraphen abfragen, um umfangreiche Kontextinformationen über die Kandidatenentitäten zu erhalten. Diese Informationen helfen dem System, fundiertere Disambiguierungsentscheidungen zu treffen. Versucht das System beispielsweise „Apple“ zu disambiguieren und findet im Kontext „Steve Jobs“, kann es im Graphen ermitteln, dass Steve Jobs stark mit Apple Inc. verbunden ist, was diese Entität zur wahrscheinlich korrekten macht. Wissensgraphen wie Wikidata und Wikipedia bieten öffentlich zugängliche Entitätsinformationen, die viele KI-Systeme während der Inferenz nutzen. Proprietäre Wissensgraphen von Unternehmen wie Google oder Microsoft liefern weitere domänenspezifische Informationen. Die Integration von Wissensgraphen und maschinellem Lernen hat die Genauigkeit der Entitätsdisambiguierung deutlich gesteigert, da Systeme nun erlernte Muster mit strukturiertem Faktenwissen kombinieren können.
Trotz erheblicher Fortschritte stehen Entitätsdisambiguierungssysteme weiterhin vor mehreren Herausforderungen, die ihre Genauigkeit und Anwendbarkeit einschränken.
Polysemie und Mehrdeutigkeit: Viele Entitätsnamen haben mehrere legitime Bedeutungen, und der Kontext reicht oft nicht aus, sie zu unterscheiden. „Bank“ kann ein Finanzinstitut oder ein Flussufer bezeichnen. „Kran“ kann einen Vogel oder eine Baumaschine meinen. Manche Namen sind so mehrdeutig, dass selbst Menschen ohne Zusatzinformationen Schwierigkeiten haben. KI-Systeme müssen erkennen, wann der Kontext nicht ausreicht, und solche Fälle angemessen behandeln.
Neue und aufkommende Entitäten: Wissensbasen und Trainingsdaten werden durch neu entstehende Entitäten schnell veraltet. Wird ein neues Unternehmen gegründet oder ein neues Produkt eingeführt, haben Disambiguierungssysteme möglicherweise keine Informationen dazu. Zero-Shot-Entity-Linking – die Fähigkeit, mit bisher unbekannten Entitäten umzugehen – bleibt eine Herausforderung. Systeme müssen erkennen, wenn eine Entität neu ist, und sie korrekt behandeln, statt sie fälschlich einer bestehenden zuzuordnen.
Namensvarianten und Schreibfehler: Entitäten haben oft mehrere Namen, Abkürzungen und Varianten. „Vereinigte Staaten“, „USA“, „U.S.“ und „Amerika“ meinen alle dieselbe Entität. Schreibfehler erschweren die Disambiguierung zusätzlich. Systeme müssen diese Varianten erkennen und der kanonischen Entität zuordnen. Besonders bei nutzergenerierten Inhalten sind Fehler häufig.
Unvollständige oder veraltete Daten: Wissensbasen können unvollständige Informationen zu Entitäten enthalten oder Daten werden veraltet, wenn sich Entitäten weiterentwickeln. Ein Firmensitz kann wechseln, die Leitung sich ändern oder das Unternehmen übernommen werden. Wird die Wissensbasis nicht schnell aktualisiert, treffen Disambiguierungssysteme Entscheidungen auf Basis veralteter Informationen.
Skalierbarkeit und Performance: Die Verarbeitung großer Textmengen mit hoher Disambiguierungsgenauigkeit erfordert erhebliche Rechenressourcen. Echtzeit-Disambiguierung für Web-Scale-Anwendungen ist rechenintensiv. Systeme müssen Genauigkeit, Geschwindigkeit und Kosten abwägen, was oft zu Kompromissen auf Kosten der Disambiguierungsqualität führt.
Für Marken und Content-Ersteller ist das Verständnis der Entitätsdisambiguierung entscheidend, um eine korrekte Darstellung in KI-generierten Inhalten sicherzustellen. Da KI-Systeme immer mehr Einfluss auf die Informationssuche und -vermittlung haben, müssen Marken proaktiv Maßnahmen ergreifen, um korrekt disambiguiert und zitiert zu werden.
Pre-Disambiguierungs-Strategien: Marken können Maßnahmen ergreifen, die es KI-Systemen erleichtern, ihre Entität eindeutig zu erkennen. Dazu gehört die Implementierung strukturierter Daten mit Schema.org-Markup und JSON-LD auf der Markenwebsite. Diese strukturierten Daten teilen KI-Systemen explizit die Identität der Marke mit – einschließlich offiziellem Namen, Beschreibung, Logo, Sitz und anderen Unterscheidungsmerkmalen. Bei der Erwähnung der Marke im Text können KI-Systeme auf diese Daten zurückgreifen, um die korrekte Entität zu bestätigen.
Optimierung des Wissensgraphen: Marken sollten auf eine starke Präsenz in wichtigen Wissensgraphen wie Wikidata und Wikipedia achten. Dazu gehören genaue, aktuelle Wikipedia-Artikel, vollständige Wikidata-Einträge und der Aufbau von Beziehungen zu verwandten Entitäten. Je umfassender und präziser der Wissensgraph-Auftritt einer Marke ist, desto mehr Informationen stehen KI-Systemen für die Disambiguierung zur Verfügung.
Kontextuelle Content-Strategie: Durch die Erstellung von Inhalten, die die eigene Identität klar machen und von gleichnamigen Entitäten abgrenzen, helfen Marken KI-Systemen, die Unterscheidungsmerkmale besser zu erfassen. Inhalte, die Branche, Produkte, Gründer und Alleinstellungsmerkmale explizit erwähnen, werden Teil des Trainings- und Kontextmaterials für die Disambiguierung.
Zitiermonitoring: Tools wie AmICited.com ermöglichen Marken, zu überwachen, wie KI-Systeme sie auf verschiedenen Plattformen disambiguieren und zitieren. Durch die Überprüfung, ob ChatGPT, Perplexity, Google AI Overviews und andere Systeme die Marke korrekt erkennen und zitieren, können Disambiguierungsfehler identifiziert und Gegenmaßnahmen ergriffen werden. Dieses Monitoring ist essenziell für die Sichtbarkeit der Marke im Zeitalter generativer KI.
Generative Engine Optimization (GEO): Da Entitätsdisambiguierung für die KI-Sichtbarkeit immer wichtiger wird, sollten Marken die Entitätsoptimierung in ihre umfassende Generative Engine Optimization-Strategie integrieren. Dazu gehört, die Marke klar zu definieren, gut zu dokumentieren und deutlich von konkurrierenden Entitäten abzugrenzen. GEO umfasst nicht nur klassische SEO, sondern auch Optimierung dafür, wie KI-Systeme Marken verstehen und darstellen.
Mit dem technischen Fortschritt und neuen Herausforderungen entwickelt sich die Entitätsdisambiguierung stetig weiter. Mehrere Trends prägen die Zukunft dieser wichtigen Fähigkeit.
Mehrsprachige Entitätsdisambiguierung: Da KI-Systeme immer globaler werden, steigt die Bedeutung der Disambiguierung von Entitäten über Sprachgrenzen hinweg. Ein Personenname kann je nach Sprache unterschiedlich geschrieben werden, und dieselbe Entität wird in unterschiedlichen sprachlichen Kontexten verschieden benannt. Fortschrittliche mehrsprachige Modelle werden entwickelt, um Entitätsdisambiguierung sprachübergreifend zu ermöglichen und wirklich globale KI-Systeme zu schaffen.
Echtzeit-Disambiguierung in großen Sprachmodellen: Moderne Large Language Models wie GPT-4 und Claude integrieren zunehmend eine Echtzeit-Entitätsdisambiguierung während der Textgenerierung. Sie verlassen sich dabei nicht nur auf Trainingsdaten, sondern können während der Inferenz Wissensgraphen und externe Datenbanken abfragen, um Entitätsinformationen zu überprüfen und Disambiguierung sicherzustellen. Dies verbessert die Zitiergenauigkeit und reduziert Halluzinationen.
Verbessertes Zero-Shot-Lernen: Zukünftige Entitätsdisambiguierungssysteme werden voraussichtlich bessere Leistungen bei bisher nicht gesehenen Entitäten erzielen. Fortschritte im Few-Shot- und Zero-Shot-Learning ermöglichen eine effektivere Disambiguierung neuer Entitäten ohne häufiges Nachtrainieren und machen Systeme anpassungsfähiger für neue Entwicklungen.
Integration mit Retrieval-Augmented Generation (RAG): Systeme, die Sprachmodelle mit Informationsabruf kombinieren, gewinnen an Bedeutung. Sie können während der Textgenerierung relevante Entitätsinformationen aus Wissensbasen abrufen und so die Disambiguierungs- und Zitiergenauigkeit verbessern. Diese Integration ist ein wichtiger Schritt für die korrekte Quellenangabe von KI-Systemen.
Standardisierung und Interoperabilität: Mit wachsender Bedeutung der Entitätsdisambiguierung für KI-Systeme dürften Branchenstandards für Entitätsrepräsentation und Disambiguierung entstehen. Sie ermöglichen eine bessere Interoperabilität zwischen Systemen und Wissensbasen, sodass KI-Systeme Entitätsinformationen plattformübergreifend konsistent nutzen können.
Die Entitätsdisambiguierung hat sich von einer Nischenaufgabe der NLP-Forschung zu einer Schlüsselkompetenz entwickelt, damit KI-Systeme Informationen korrekt verstehen und wiedergeben. Mit zunehmendem Einfluss von KI auf die Informationssuche wird die Bedeutung präziser Entitätsdisambiguierung weiter steigen. Für Marken, Content-Ersteller und Organisationen ist das Verständnis und die Optimierung der Entitätsdisambiguierung essenziell, um Sichtbarkeit und eine korrekte Darstellung im Zeitalter generativer KI zu sichern.
Die benannte Entitätenerkennung identifiziert, dass eine Entität im Text existiert, und klassifiziert sie in Kategorien wie Person, Organisation oder Ort. Die Entitätsdisambiguierung geht einen Schritt weiter, indem sie bestimmt, auf welche spezifische Entität verwiesen wird, wenn mehrere Entitäten denselben Namen teilen. Zum Beispiel erkennt NER „Apple“ als Organisation, während die Entitätsdisambiguierung bestimmt, ob damit Apple Inc., Apple Bank oder eine andere Entität gemeint ist.
Die Entitätsdisambiguierung stellt sicher, dass KI-Systeme genau verstehen, über welche Entität gesprochen wird, und diese korrekt zitieren. Laut dem Stanford AI Index 2024 enthalten über 18 % der LLM-Ausgaben, die Markenentitäten betreffen, Halluzinationen oder Fehlzuordnungen. Eine genaue Entitätsdisambiguierung verhindert, dass KI-Systeme eine Entität mit einer anderen verwechseln, was entscheidend für die Wahrung des Markenrufs und die Zitiergenauigkeit ist.
Wissensgraphen liefern strukturierte Informationen über Entitäten und deren Beziehungen. Wenn ein KI-System auf eine mehrdeutige Entitätenerwähnung stößt, kann es den Wissensgraphen abfragen, um Metadaten, Beschreibungen und Beziehungsinformationen zu den Kandidatenentitäten zu erhalten. Diese Kontextinformationen helfen dem System, fundiertere Disambiguierungsentscheidungen zu treffen und die richtige Entität auszuwählen.
Ja, durch Zero-Shot-Entity-Linking-Ansätze. Moderne Systeme können erkennen, wenn eine Entität neu ist, und sie angemessen behandeln, anstatt sie fälschlicherweise mit einer bestehenden Entität abzugleichen. Dies bleibt jedoch eine anspruchsvolle Aufgabe, und Systeme funktionieren besser, wenn neue Entitäten deutliche Kontextsignale aufweisen, die sie von bestehenden unterscheiden.
Eine genaue Entitätsdisambiguierung stellt sicher, dass Ihre Marke in KI-generierten Antworten korrekt identifiziert und zitiert wird. Wenn KI-Systeme Ihre Marke korrekt disambiguieren, erhalten Nutzer präzise Informationen über Ihr Unternehmen, was Sichtbarkeit und Ruf Ihrer Marke verbessert. Schlechte Disambiguierung kann dazu führen, dass Ihre Marke mit Wettbewerbern oder anderen Entitäten verwechselt wird, was die Sichtbarkeit mindert und dem Ruf schaden kann.
Zu den wichtigsten Herausforderungen zählen Polysemie (mehrere Bedeutungen für denselben Namen), neue Entitäten außerhalb der Trainingsdaten, Namensvarianten und Schreibfehler, unvollständige oder veraltete Wissensbasen sowie Skalierbarkeitsprobleme. Zudem sind einige Entitätsnamen von Natur aus mehrdeutig, und der Kontext allein reicht möglicherweise nicht aus, um die richtige Entität zu bestimmen.
Marken können strukturierte Daten mit Schema.org-Markup implementieren, genaue Wikipedia- und Wikidata-Einträge pflegen, kontextbezogene Inhalte erstellen, die ihre Marke klar abgrenzen, und überwachen, wie KI-Systeme ihre Marke mit Tools wie AmICited disambiguieren. Diese Strategien helfen KI-Systemen, Ihre Marke korrekt zu identifizieren und zu zitieren.
Der Kontext ist entscheidend für die Entitätsdisambiguierung. Der umgebende Text, verwandte Entitäten und semantische Beziehungen liefern Signale, die KI-Systemen helfen, zu bestimmen, auf welche Entität Bezug genommen wird. Wenn beispielsweise „Apple“ in der Nähe von „Steve Jobs“ und „Technologie“ erscheint, kann das System diesen Kontext nutzen, um es als Apple Inc. und nicht als die Frucht zu disambiguieren.
Verfolgen Sie die Genauigkeit der Entitätsdisambiguierung auf KI-Plattformen und stellen Sie sicher, dass Ihre Marke in KI-generierten Antworten korrekt identifiziert und zitiert wird.
Entity Recognition ist eine KI-NLP-Fähigkeit zur Identifizierung und Kategorisierung benannter Entitäten im Text. Erfahren Sie, wie sie funktioniert, ihre Anwen...

Erfahren Sie, wie Entity Linking Ihre Marke in KI-Systemen verbindet. Entdecken Sie Strategien, um die Markenwahrnehmung in ChatGPT, Perplexity und Google AI Ov...

Erfahren Sie, wie KI-Systeme Beziehungen zwischen Entitäten in Text erkennen, extrahieren und verstehen. Entdecken Sie Techniken zur Entitätsbeziehungsextraktio...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.