
Google-Extended: Was es macht und sollten Sie es blockieren?
Erfahren Sie, was Google-Extended ist, wie es funktioniert und ob Sie es in Ihrer robots.txt blockieren sollten. Verstehen Sie den Unterschied zwischen KI-Train...
7 Min. Lesezeit
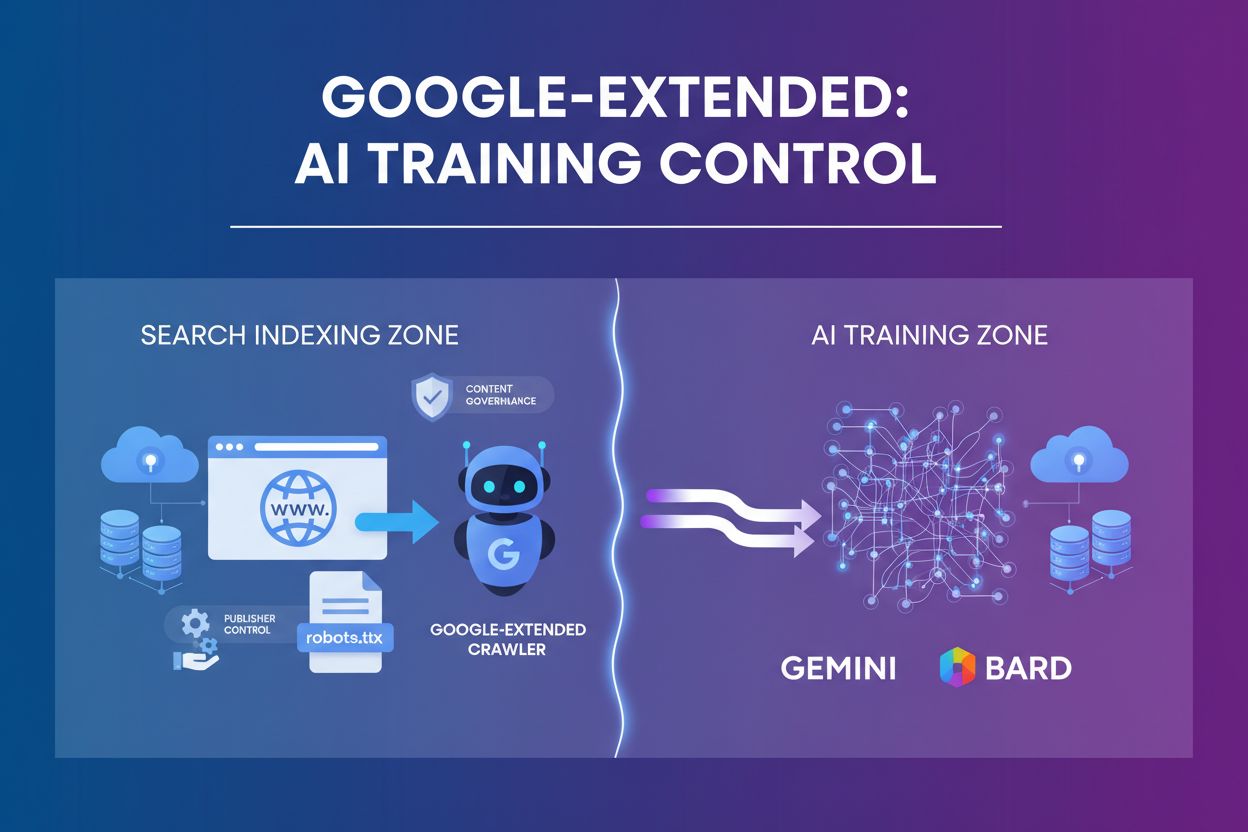
Google-Extended ist ein User-Agent-Token, das steuert, ob Website-Inhalte zur Verbesserung von Gemini und anderen Google-AI-Produkten verwendet werden, unabhängig vom normalen Googlebot-Crawling. Es ermöglicht Publishern, den Zugriff auf AI-Training über robots.txt zu verwalten, ohne die Sichtbarkeit in der Suche zu beeinflussen. Eingeführt im September 2023, adressiert es die Bedenken von Publishern bezüglich der Inhaltsnutzung bei der Entwicklung von AI-Modellen. Google-Extended hat keinen Einfluss auf SEO-Rankings oder die Aufnahme in die Suche.
Google-Extended ist ein User-Agent-Token, das steuert, ob Website-Inhalte zur Verbesserung von Gemini und anderen Google-AI-Produkten verwendet werden, unabhängig vom normalen Googlebot-Crawling. Es ermöglicht Publishern, den Zugriff auf AI-Training über robots.txt zu verwalten, ohne die Sichtbarkeit in der Suche zu beeinflussen. Eingeführt im September 2023, adressiert es die Bedenken von Publishern bezüglich der Inhaltsnutzung bei der Entwicklung von AI-Modellen. Google-Extended hat keinen Einfluss auf SEO-Rankings oder die Aufnahme in die Suche.
Google-Extended ist ein User-Agent-Token, mit dem Website-Betreiber steuern können, ob ihre Inhalte zum Training von Googles generativen AI-Modellen wie Gemini, Bard und Vertex AI verwendet werden. Im Gegensatz zum Googlebot, der Websites für die Indexierung von Suchergebnissen crawlt, arbeitet Google-Extended unabhängig und sammelt Daten speziell zum Trainieren und zur Fundierung von AI-Modellen. Dieses User-Agent-Token ist kein separater HTTP-Crawler – es fungiert vielmehr als Steuermechanismus innerhalb der robots.txt-Datei, mit dem Publisher strategische Entscheidungen über die Rolle ihrer Inhalte in der AI-Entwicklung treffen können. Die Einführung von Google-Extended stellt einen bedeutenden Wandel darin dar, wie Webpublisher ihr geistiges Eigentum im Zeitalter der künstlichen Intelligenz verwalten können.
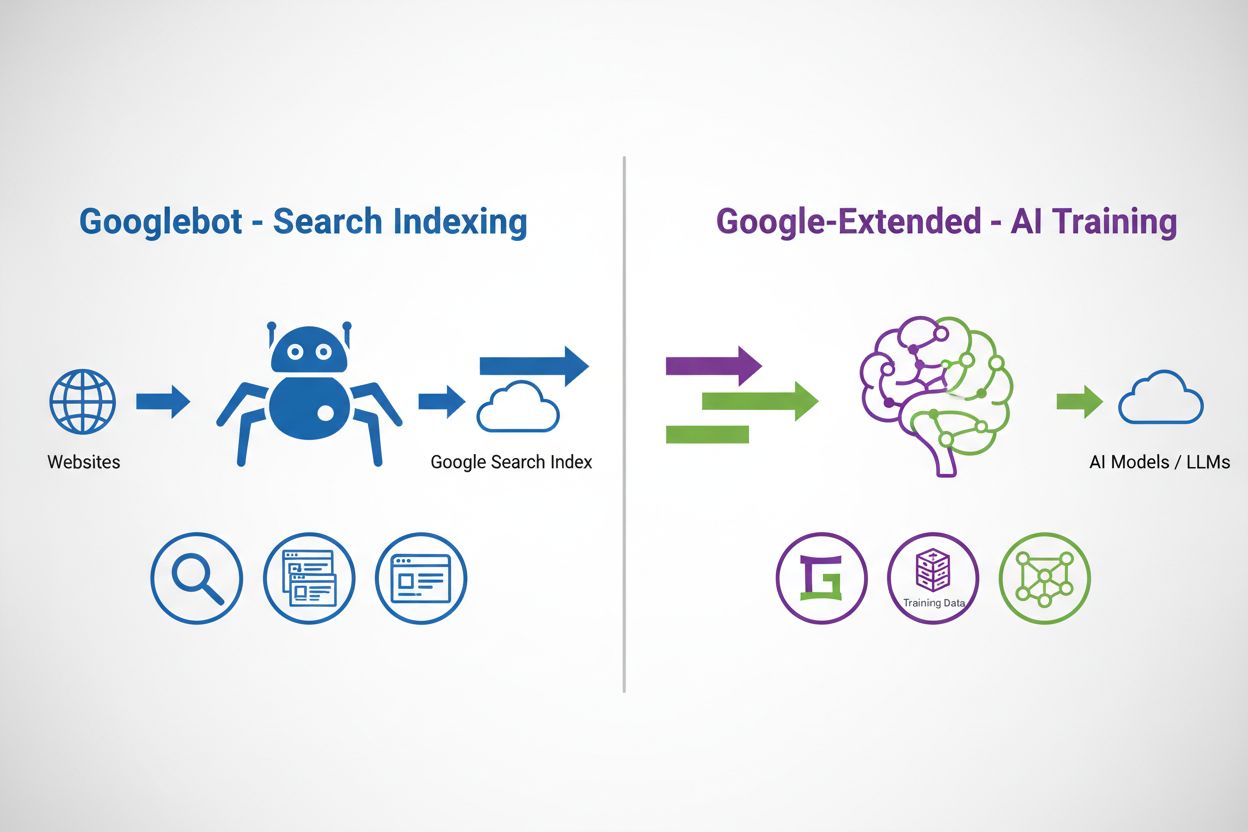
Google-Extended nutzt das bekannte robots.txt-Protokoll, eine Klartextdatei im Root-Verzeichnis einer Website, die Anweisungen für Webcrawler enthält. Anders als andere Google-Crawler wie Googlebot oder Googlebot-Image hat Google-Extended keinen eigenen HTTP-User-Agent-String – Google verwendet bestehende User-Agent-Strings, aber das robots.txt-Token dient gezielt als Steuerung für AI-Training. Wenn Sie eine Direktive für Google-Extended in Ihre robots.txt aufnehmen, teilen Sie Google mit, ob Inhalte Ihrer Seite für die nächsten Generationen von Gemini-Modellen und zur Fundierung (also zur Bereitstellung von Echtzeitinformationen zur Verbesserung der AI-Antworten) genutzt werden dürfen. Diese Trennung erlaubt es Publishern, die Sichtbarkeit in der Suche zu erhalten und gleichzeitig den Zugriff für AI-Training unabhängig davon zu steuern.
| Crawler | User-Agent-Token | HTTP-Anfragemethode | Betroffene Produkte |
|---|---|---|---|
| Googlebot | Googlebot | Eigener User-Agent-String | Google Suche, Bilder, News, Discover |
| Googlebot-Image | Googlebot-Image | Eigener User-Agent-String | Google Bilder, Discover, Video |
| Google-Extended | Google-Extended | Verwendet bestehende Google-User-Agents | Gemini-Apps, Vertex AI, Fundierung |
| Google-CloudVertexBot | Google-CloudVertexBot | Eigener User-Agent-String | Vertex AI Agents (auf Wunsch des Seitenbetreibers) |
Eine der wichtigsten Klarstellungen zu Google-Extended ist, dass es keinerlei Einfluss auf das Ranking Ihrer Website oder deren Sichtbarkeit in der Google-Suche hat. Im April 2025 hat Google seine Dokumentation explizit aktualisiert: “Google-Extended beeinflusst weder die Aufnahme einer Seite in die Google-Suche noch dient es als Ranking-Signal.” Das bedeutet, Sie können Google-Extended blockieren, ohne organischen Traffic, Sichtbarkeit oder vorhandene SEO-Vorteile zu verlieren. Der Unterschied ist entscheidend: Das Blockieren von Google-Extended verhindert nur, dass Ihre Inhalte für AI-Training und Fundierung genutzt werden – es beeinflusst nicht, wie Googles Suchalgorithmen Ihre Seiten bewerten oder ranken. Diese Trennung ermöglicht es Publishern, Governance-Entscheidungen auf Basis ihres Geschäftsmodells und ihrer Werte zu treffen, statt zwischen Sichtbarkeit in der Suche und AI-Training wählen zu müssen.
Die Implementierung der Google-Extended-Kontrolle ist einfach und erfordert nur wenige Zeilen in Ihrer robots.txt-Datei. Um Google-Extended den Zugriff auf Ihre Inhalte zu verweigern, fügen Sie am Root Ihrer Website folgende Direktive ein:
User-agent: Google-Extended
Disallow: /
Damit teilen Sie Googles AI-Trainingscrawler mit, dass er auf keinen Bereich Ihrer Website zugreifen darf. Wenn Sie möchten, dass normale Suchcrawler wie Googlebot Ihre Seite weiterhin indexieren, während Sie den Zugriff für AI-Training sperren, sollte Ihre vollständige robots.txt wie folgt aussehen:
User-agent: Google-Extended
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
Sie können auch selektives Blockieren umsetzen, indem Sie bestimmte Verzeichnisse oder Dateitypen angeben. Wenn Sie zum Beispiel nur Ihre Premium-Inhalte vor AI-Training schützen, allgemeine Inhalte aber freigeben möchten, könnten Sie Folgendes nutzen:
User-agent: Google-Extended
Disallow: /premium/
Disallow: /subscription/
User-agent: Googlebot
Disallow:
So erhalten Sie eine feingranulare Kontrolle darüber, welche Teile Ihrer Seite zum AI-Training beitragen, während Sie die komplette Sichtbarkeit in Suchmaschinen für Ihre Domain beibehalten.
Das Verständnis des Unterschieds zwischen AI-Trainingszugriff und Suchindexierung ist essenziell, um fundierte Entscheidungen über Google-Extended zu treffen. Wenn Sie Google-Extended erlauben, können Ihre Inhalte zum Training der Gemini-Modelle und als fundierende Informationen für AI-Antworten genutzt werden – Ihre Inhalte könnten also in Bard-Antworten, Gemini-Apps und Vertex AI-Anwendungen erscheinen. Wenn Sie Google-Extended blockieren, bleiben Ihre Inhalte weiterhin vollständig in der Google-Suche indexiert und erscheinen in klassischen Suchergebnissen, werden aber nicht für AI-Trainingsdatensätze oder zur Fundierung von AI-Antworten verwendet. So sehen die verschiedenen Szenarien aus:
Der entscheidende Punkt: Beide Crawler arbeiten unabhängig voneinander, sodass Publisher eine nie dagewesene Kontrolle darüber haben, wie ihre Inhalte in verschiedenen Google-Produkten und -Diensten genutzt werden.
Google hat Google-Extended eingeführt, um wachsenden Bedenken von Website-Betreibern, Journalisten und Content Creators entgegenzutreten, deren Werke ohne explizite Zustimmung oder Vergütung zum Training von AI-Modellen genutzt wurden. Publisher stellten berechtigte Fragen zu Urheberrechten, Inhaltszuschreibung, Markenverwässerung und Wettbewerbskonflikten – insbesondere, wenn AI-Systeme, die mit ihren Inhalten trainiert wurden, irgendwann mit den Originalangeboten konkurrieren könnten. Viele Content Creators hatten das Gefühl, ihr geistiges Eigentum würde unsichtbar geerntet, ohne Transparenz darüber, wie ihr Werk zur AI-Entwicklung beiträgt oder wie sie sich abmelden können. Google-Extended adressiert diese Bedenken direkt, indem es einen klaren, dokumentierten Weg bietet, wie Publisher steuern können, ob ihre Inhalte am AI-Training teilnehmen. Das stellt ein bedeutendes Bekenntnis von Google dar, dass Content Creators Entscheidungsfreiheit über ihr geistiges Eigentum und eine Stimme bei der Gestaltung der AI-Zukunft verdienen.
Ihre Entscheidung, Google-Extended zuzulassen oder zu blockieren, sollte im Einklang mit Geschäftsmodell, Content-Strategie und langfristiger Vision stehen. Content Creators und Bildungseinrichtungen, die maximale Sichtbarkeit und Thought Leadership anstreben, sollten Google-Extended in der Regel erlauben, denn Auftritte in Gemini-Antworten und AI-generierten Inhalten können die Markenbekanntheit und Autorität deutlich steigern. Nachrichtenportale und abonnementsbasierte Plattformen sollten Google-Extended gezielt blockieren, um ihr proprietäres Material zu schützen und den Wettbewerbsvorteil zu erhalten – vor allem, wenn das Geschäftsmodell auf exklusivem Zugang zu Originalberichten beruht. Unternehmenssoftware-Firmen und Beratungen könnten einen hybriden Ansatz wählen: Google-Extended für allgemeine Wissensinhalte erlauben, aber proprietäre Methoden und Fallstudien blockieren. Die strategische Frage ist nicht, ob AI-Training gut oder schlecht ist, sondern: Profitieren Ihre Inhalte mehr von breiter AI-Sichtbarkeit, oder müssen sie als Wettbewerbsvorteil geschützt werden? Berücksichtigen Sie Ihre Zielgruppe, Ihr Erlösmodell und ob ein Auftritt in AI-generierten Antworten Wert schafft oder Ihre Marke verwässert.
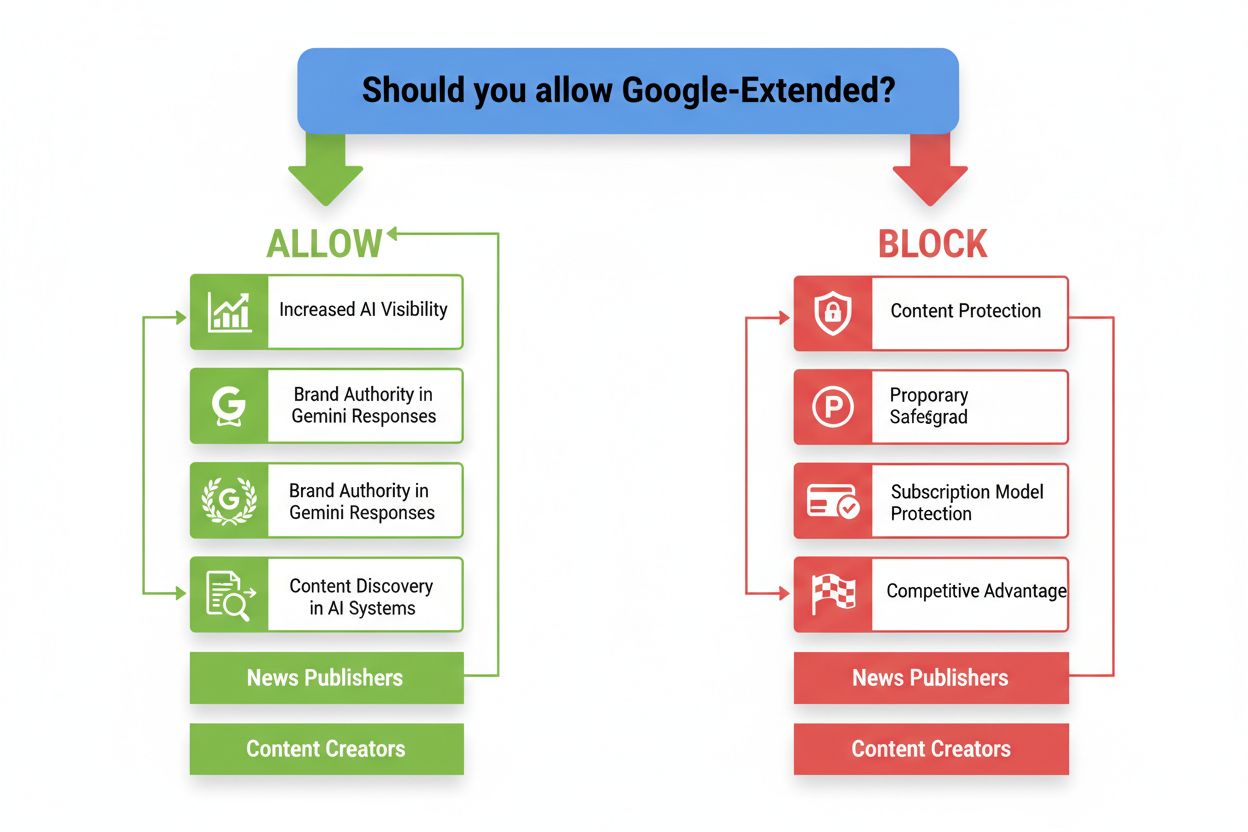
Derzeit gibt es kein leistungsfähiges öffentliches Tool, mit dem Sie exakt nachverfolgen können, wie Ihre Inhalte von Googles AI-Modellen genutzt werden, was ein erhebliches Transparenzdefizit darstellt. Während Google-Extended die Kontrolle über den Zugriff bietet, fehlt Publishern die detaillierte Sicht darauf, wie ihre Inhalte AI-Ausgaben beeinflussen oder in Gemini-Antworten erscheinen. Diese Lücke ruft nach besseren Monitoring-Lösungen – Tools wie AmICited.com entstehen, um Publishern dabei zu helfen, wie ihre Marke und Inhalte in AI-Systemen zitiert und referenziert werden, und so die dringend benötigte Transparenz zu schaffen. In Zukunft ist mit Branchenstandards zu AI-Zuschreibung, Content-Lizenzierung und Publisher-Vergütung zu rechnen – ähnlich den klassischen Medienlizenzen. Für den Moment empfiehlt sich ein hybrider Ansatz: Blockieren Sie Google-Extended für Ihre sensibelsten oder proprietären Inhalte, erlauben Sie es für Inhalte zur breiten Verbreitung und nutzen Sie Third-Party-Tools, um Ihre Markenpräsenz in AI-Content zu tracken. Mit der wachsenden Integration von AI in Suche und Informationsgewinnung wird die Fähigkeit, die Teilnahme Ihrer Inhalte an diesen Systemen zu steuern und zu überwachen, immer wertvoller.
Googlebot crawlt Websites, um Inhalte für die Google-Suchergebnisse zu indexieren, während Google-Extended ein User-Agent-Token ist, das steuert, ob Inhalte für das AI-Training in Gemini und Vertex AI verwendet werden. Googlebot beeinflusst die Sichtbarkeit in der Suche, Google-Extended nicht. Beide können unabhängig über robots.txt gesteuert werden, sodass Publisher Suchindexierung und AI-Training separat verwalten können.
Nein. Das Blockieren von Google-Extended hat absolut keinen Einfluss auf Ihr Ranking oder Ihre Sichtbarkeit in der Google-Suche. Google hat im April 2025 ausdrücklich bestätigt, dass Google-Extended kein Ranking-Signal ist und die Aufnahme in die Suche nicht beeinflusst. Sie können es bedenkenlos blockieren, ohne Angst vor Traffic-Verlust.
Fügen Sie diese Zeilen zu Ihrer robots.txt-Datei hinzu: User-agent: Google-Extended gefolgt von Disallow: /. Das verhindert, dass Googles AI-Trainingscrawler auf Ihre Inhalte zugreift. Sie können auch bestimmte Verzeichnisse oder Dateitypen blockieren. Beachten Sie, dass dies nur den AI-Trainingszugriff beeinflusst, nicht die Suchmaschinenindexierung.
Ja, absolut. Das Blockieren von Google-Extended verhindert nur, dass Ihre Inhalte für das AI-Training verwendet werden. Ihre Inhalte werden weiterhin vom Googlebot indexiert und erscheinen ganz normal in den Google-Suchergebnissen. Die beiden Crawler arbeiten unabhängig voneinander, sodass die Steuerung des einen den anderen nicht beeinflusst.
Wenn Sie Google-Extended erlauben, können Ihre Inhalte zur Schulung von Gemini-Modellen und als Grundlage für AI-generierte Antworten genutzt werden. Das bedeutet, Ihre Inhalte könnten in Bard-Antworten, Gemini-Apps und Vertex AI-Anwendungen erscheinen. Das kann die Markenbekanntheit steigern, bedeutet aber auch, dass Ihre Inhalte in nicht direkt kontrollierbaren Zusammenhängen erscheinen können.
Ja. Sie können selektives Blockieren in robots.txt nutzen, um bestimmte Verzeichnisse oder Dateitypen zu schützen. Beispielsweise können Sie Google-Extended den Zugriff auf /premium/ oder /subscription/ verweigern, während andere Bereiche Ihrer Seite zugänglich bleiben. So erhalten Sie eine feingranulare Kontrolle darüber, welche Inhalte am AI-Training teilnehmen.
Einige AI-Unternehmen haben eigene User-Agent-Tokens oder Crawler eingeführt, aber Google-Extended ist Googles spezifischer Mechanismus zur Kontrolle des AI-Trainingszugriffs. Andere AI-Plattformen wie OpenAI, Anthropic und Perplexity gehen unterschiedlich vor. Es gibt derzeit keinen universellen Standard, daher sollten Sie die jeweilige Dokumentation der AI-Anbieter prüfen.
Nein, Google-Extended ist optional. Sie müssen keine Anweisungen dafür in Ihrer robots.txt hinterlegen. Standardmäßig, wenn Sie nichts angeben, durchsucht Google-Extended Ihre Seite zu AI-Trainingszwecken. Sie müssen nur dann Anweisungen hinzufügen, wenn Sie es blockieren oder selektive Sperrungen für bestimmte Inhalte vornehmen möchten.
Verfolgen Sie Ihre Marken-Nennungen über AI-Plattformen wie Gemini, Perplexity und Google AI Overviews mit AmICited. Erhalten Sie Einblicke, wie AI-Systeme Ihre Inhalte referenzieren und messen Sie Ihre Sichtbarkeit in AI.
Erfahren Sie, was Google-Extended ist, wie es funktioniert und ob Sie es in Ihrer robots.txt blockieren sollten. Verstehen Sie den Unterschied zwischen KI-Train...
Erfahren Sie mehr über Applebot-Extended, Apples Web-Crawler für KI-Training. Verstehen Sie, wie er Inhalte für Apple Intelligence bewertet, wie Sie ihn blockie...
Erfahren Sie, was die Search Generative Experience (SGE) ist, wie Googles AI Overviews funktionieren und warum diese KI-gestützte Suchfunktion SEO und digitale ...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.