
Multimodale KI-Suche: Optimierung für Bild- und Sprachabfragen
Meistern Sie die Optimierung für multimodale KI-Suche. Lernen Sie, wie Sie Bilder und Sprachanfragen für KI-gestützte Suchergebnisse optimieren, mit Strategien ...
8 Min. Lesezeit

KI-Systeme, die Anfragen verarbeiten und beantworten, die gleichzeitig Text, Bilder, Audio und Video umfassen, um ein umfassenderes Verständnis und kontextbewusste Antworten über mehrere Datentypen hinweg zu ermöglichen.
KI-Systeme, die Anfragen verarbeiten und beantworten, die gleichzeitig Text, Bilder, Audio und Video umfassen, um ein umfassenderes Verständnis und kontextbewusste Antworten über mehrere Datentypen hinweg zu ermöglichen.
Multimodale KI-Suche bezeichnet künstliche Intelligenzsysteme, die Informationen aus mehreren Datentypen oder Modalitäten – wie Text, Bilder, Audio und Video – gleichzeitig verarbeiten und integrieren, um umfassendere und kontextuell relevantere Ergebnisse zu liefern. Im Gegensatz zur unimodalen KI, die sich auf einen einzigen Eingabetyp stützt (zum Beispiel reine Textsuchmaschinen), nutzen multimodale Systeme die komplementären Stärken verschiedener Datenformate, um ein tieferes Verständnis und genauere Resultate zu erzielen. Dieses Vorgehen spiegelt die menschliche Kognition wider, bei der wir visuelle, auditive und textuelle Informationen kombinieren, um unsere Umgebung zu begreifen. Durch die gemeinsame Verarbeitung unterschiedlicher Eingabetypen können multimodale KI-Suchsysteme Nuancen und Zusammenhänge erfassen, die für Ansätze mit nur einer Modalität unsichtbar bleiben.
Multimodale KI-Suche arbeitet mit ausgefeilten Fusionstechniken, die Informationen aus verschiedenen Modalitäten auf unterschiedlichen Verarbeitungsebenen kombinieren. Das System extrahiert zunächst unabhängig voneinander Merkmale aus jeder Modalität und verschmilzt diese Repräsentationen anschließend gezielt, um ein einheitliches Verständnis zu schaffen. Zeitpunkt und Methode der Fusion haben erheblichen Einfluss auf die Leistung, wie der folgende Vergleich zeigt:
| Fusionstyp | Wann angewendet | Vorteile | Nachteile |
|---|---|---|---|
| Frühe Fusion | Eingabestufe | Erfasst Korrelationen auf niedriger Ebene | Weniger robust bei nicht ausgerichteten Daten |
| Mittlere Fusion | Vorverarbeitungsstufen | Ausgewogener Ansatz | Komplexer |
| Späte Fusion | Ausgabestufe | Modulares Design | Weniger Kontextzusammenhalt |
Bei der frühen Fusion werden Rohdaten sofort kombiniert, wodurch feingranulare Interaktionen erfasst werden, sie aber bei nicht synchronisierten Eingaben Schwierigkeiten hat. Mittlere Fusion erfolgt während der Zwischenstufen der Verarbeitung und bietet einen ausgewogenen Kompromiss zwischen Komplexität und Leistung. Die späte Fusion arbeitet auf Ausgabebene, ermöglicht eine unabhängige Modalitätenverarbeitung, verliert aber möglicherweise wichtigen bereichsübergreifenden Kontext. Die Wahl der Fusionsstrategie hängt von den jeweiligen Anwendungsanforderungen und der Art der zu verarbeitenden Daten ab.
Mehrere Schlüsseltechnologien treiben moderne multimodale KI-Suchsysteme an und ermöglichen ihnen, verschiedene Datentypen effektiv zu verarbeiten und zu integrieren:
Diese Technologien arbeiten synergetisch zusammen, um Systeme zu schaffen, die komplexe Beziehungen zwischen unterschiedlichen Informationsarten verstehen können.
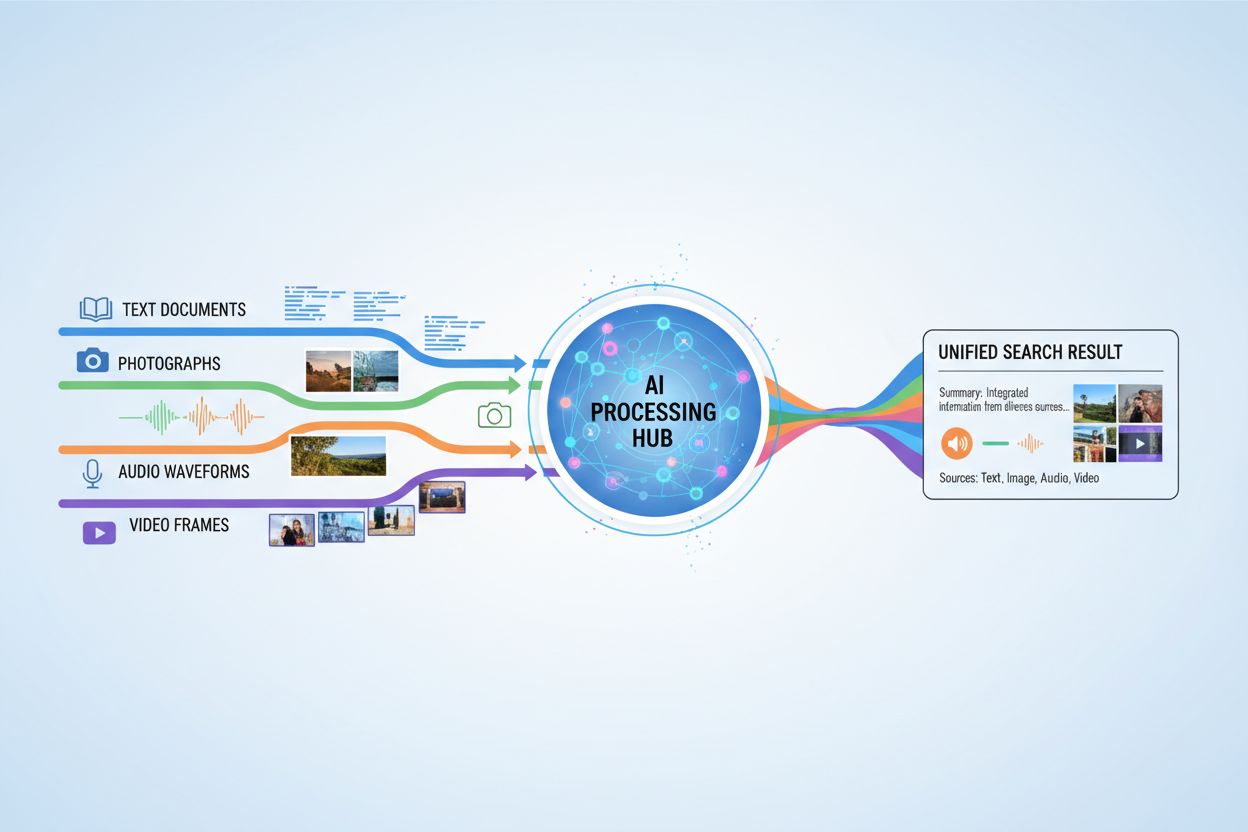
Multimodale KI-Suche hat transformative Anwendungen in zahlreichen Branchen und Bereichen. Im Gesundheitswesen analysieren Systeme medizinische Bilder zusammen mit Patientendaten und klinischen Notizen, um die Diagnosesicherheit und Therapieempfehlungen zu verbessern. E-Commerce-Plattformen nutzen multimodale Suche, damit Kunden Produkte durch die Kombination aus Textbeschreibungen und visuellen Referenzen oder sogar Skizzen finden können. Autonome Fahrzeuge verlassen sich auf die multimodale Fusion von Kamerabildern, Radardaten und Sensoreingaben, um sicher zu navigieren und Entscheidungen in Echtzeit zu treffen. Inhaltsmoderationssysteme kombinieren Bilderkennung, Textanalyse und Audioprozessierung, um schädliche Inhalte effektiver zu erkennen als einmodalige Ansätze. Darüber hinaus verbessert multimodale Suche die Barrierefreiheit, indem Nutzer mit ihrer bevorzugten Eingabemethode – Sprache, Bild oder Text – suchen können, während das System die Intention in allen Formaten versteht.

Multimodale KI-Suche bietet wesentliche Vorteile, die den erhöhten Aufwand und die höheren Rechenanforderungen rechtfertigen. Verbesserte Genauigkeit entsteht durch die Nutzung komplementärer Informationsquellen, wodurch Fehler reduziert werden, wie sie bei einmodaligen Systemen auftreten können. Erweitertes Kontextverständnis ergibt sich, wenn visuelle, textuelle und auditive Informationen kombiniert werden, um reichere semantische Bedeutung zu liefern. Überlegene Nutzererfahrung wird durch intuitivere Suchschnittstellen erreicht, die verschiedene Eingabetypen akzeptieren und relevantere Ergebnisse liefern. Domänenübergreifendes Lernen wird möglich, da Wissen aus einer Modalität das Verständnis in einer anderen unterstützen kann, was Transferlernen über verschiedene Datentypen hinweg erlaubt. Erhöhte Robustheit bedeutet, dass das System auch dann leistungsfähig bleibt, wenn eine Modalität beeinträchtigt oder nicht verfügbar ist, da andere Modalitäten fehlende Informationen kompensieren können.
Trotz ihrer Vorteile steht die multimodale KI-Suche vor erheblichen technischen und praktischen Herausforderungen. Datenabgleich und Synchronisation sind schwierig, da verschiedene Modalitäten oft unterschiedliche zeitliche Eigenschaften und Qualitätsstufen haben, die sorgfältig verwaltet werden müssen. Rechnerische Komplexität steigt erheblich an, wenn mehrere Datenströme gleichzeitig verarbeitet werden, was erhebliche Ressourcen und spezialisierte Hardware erfordert. Fairness- und Verzerrungsprobleme treten auf, wenn Trainingsdaten über Modalitäten hinweg unausgewogen sind oder bestimmte Gruppen in spezifischen Datentypen unterrepräsentiert sind. Datenschutz und Sicherheit werden mit mehreren Datenströmen komplexer, wodurch die Angriffsfläche für potenzielle Verstöße steigt und ein sorgfältiger Umgang mit sensiblen Informationen erforderlich ist. Enorme Datenanforderungen bedeuten, dass das Training effektiver multimodaler Systeme deutlich größere und vielfältigere Datensätze als einmodale Alternativen erfordert, was mit hohen Kosten und zeitlichem Aufwand für Erhebung und Annotation verbunden ist.
Multimodale KI-Suche überschneidet sich besonders mit KI-Monitoring und Zitier-Tracking, da KI-Systeme zunehmend Antworten generieren, die Informationen aus mehreren Quellen referenzieren oder zusammenführen. Plattformen wie AmICited.com konzentrieren sich darauf, zu überwachen, wie KI-Systeme Informationen zitieren und Originalquellen zuordnen, um Transparenz und Verantwortlichkeit bei KI-generierten Antworten zu gewährleisten. Ebenso verfolgt FlowHunt.io die KI-Content-Generierung und hilft Organisationen zu verstehen, wie ihre markenspezifischen Inhalte von multimodalen KI-Systemen verarbeitet und referenziert werden. Mit der zunehmenden Verbreitung multimodaler KI-Suche wird das Tracking, wie diese Systeme Marken, Produkte und Originalquellen zitieren, für Unternehmen, die ihre Sichtbarkeit in KI-generierten Ergebnissen verstehen wollen, immer wichtiger. Diese Monitoring-Fähigkeit hilft Organisationen, zu überprüfen, dass ihre Inhalte korrekt dargestellt und ordnungsgemäß zugeordnet werden, wenn multimodale KI-Systeme Informationen aus Text, Bild und anderen Modalitäten zusammenführen.
Die Zukunft der multimodalen KI-Suche weist auf eine immer einheitlichere und nahtlosere Integration verschiedener Datentypen hin und geht über aktuelle Fusionsansätze hinaus zu ganzheitlicheren Modellen, die alle Modalitäten als von Natur aus verbunden verarbeiten. Echtzeitfähigkeiten werden sich erweitern, sodass multimodale Suche gleichzeitig auf Live-Videostreams, kontinuierliche Audiodaten und dynamische Texte ohne Latenzbeschränkungen zugreifen kann. Fortschrittliche Datenaugmentierungstechniken werden aktuelle Herausforderungen der Datenknappheit durch synthetische Generierung multimodaler Trainingsbeispiele mit gleichbleibender semantischer Konsistenz zwischen den Modalitäten adressieren. Zu den aufkommenden Entwicklungen zählen Foundation-Modelle, die auf riesigen multimodalen Datensätzen trainiert werden und effizient an spezifische Aufgaben angepasst werden können, neuromorphe Computing-Ansätze, die biologische multimodale Verarbeitung besser nachahmen, und föderiertes multimodales Lernen, das ein Training über verteilte Datenquellen bei gleichzeitigem Datenschutz ermöglicht. Diese Fortschritte werden multimodale KI-Suche zugänglicher, effizienter und in der Lage machen, zunehmend komplexe reale Szenarien zu bewältigen.
Unimodale KI-Systeme verarbeiten nur einen Datentyp, wie etwa reine Textsuchmaschinen. Multimodale KI-Systeme hingegen verarbeiten und integrieren mehrere Datentypen – Text, Bilder, Audio und Video – gleichzeitig und erzielen durch die Nutzung der komplementären Stärken verschiedener Datenformate ein tieferes Verständnis sowie genauere Ergebnisse.
Multimodale KI-Suche verbessert die Genauigkeit, indem sie komplementäre Informationsquellen kombiniert, die Nuancen und Zusammenhänge erfassen, die für Ansätze mit nur einer Modalität unsichtbar bleiben. Wenn visuelle, textuelle und auditive Informationen zusammengeführt werden, erreicht das System ein reichhaltigeres semantisches Verständnis und kann besser informierte Entscheidungen auf Basis verschiedener Perspektiven derselben Information treffen.
Zentrale Herausforderungen sind die Ausrichtung und Synchronisierung der Daten über verschiedene Modalitäten hinweg, erhebliche rechnerische Komplexität, Fragen der Fairness und Verzerrung bei unausgewogenen Trainingsdaten, Datenschutz- und Sicherheitsprobleme bei mehreren Datenströmen sowie ein enormer Datenbedarf für ein effektives Training. Jede Modalität hat unterschiedliche zeitliche Eigenschaften und Qualitätsstufen, die sorgfältig verwaltet werden müssen.
Das Gesundheitswesen profitiert von der Analyse medizinischer Bilder zusammen mit Patientendaten und klinischen Notizen. Der E-Commerce nutzt multimodale Suche für die visuelle Produktsuche. Autonome Fahrzeuge sind auf multimodale Fusion von Kameras, Radar und Sensoren angewiesen. Inhaltsmoderation kombiniert Bild-, Text- und Audioanalyse. Kundenservice-Systeme nutzen mehrere Eingabetypen für besseren Support und barrierefreie Anwendungen ermöglichen Nutzern die Suche mit ihrer bevorzugten Eingabemethode.
Embedding-Modelle wandeln verschiedene Modalitäten in numerische Repräsentationen um, die semantische Bedeutung erfassen. Vektordatenbanken speichern diese Embeddings in einem gemeinsamen mathematischen Raum, in dem Beziehungen zwischen verschiedenen Datentypen gemessen und verglichen werden können. So kann das System Verbindungen zwischen Text, Bild, Audio und Video finden, indem es deren Positionen in diesem gemeinsamen semantischen Raum vergleicht.
Multimodale KI-Systeme verarbeiten mehrere sensible Datentypen – aufgezeichnete Gespräche, Gesichtserkennungsdaten, schriftliche Kommunikation und medizinische Bilder – was das Risiko für Datenschutzverletzungen erhöht. Die Kombination verschiedener Modalitäten schafft mehr Möglichkeiten für Datenlecks und erfordert strikte Einhaltung von Vorschriften wie DSGVO und CCPA. Organisationen müssen robuste Sicherheitsmaßnahmen implementieren, um Benutzeridentität und sensible Informationen über alle Modalitäten hinweg zu schützen.
Plattformen wie AmICited.com überwachen, wie KI-Systeme Informationen zitieren und Originalquellen zuordnen, und sorgen so für Transparenz bei KI-generierten Antworten. Organisationen können ihre Sichtbarkeit in multimodalen KI-Suchergebnissen verfolgen, sicherstellen, dass ihre Inhalte korrekt dargestellt werden, und eine ordnungsgemäße Zuordnung bestätigen, wenn KI-Systeme Informationen aus Text, Bild und anderen Modalitäten zusammenführen.
Die Zukunft umfasst einheitliche Modelle, die alle Modalitäten als von Natur aus miteinander verbunden verarbeiten, Echtzeitverarbeitung von Live-Video- und Audiostreams, fortgeschrittene Datenaugmentierung zur Bewältigung von Datenknappheit, Foundation-Modelle, die auf riesigen multimodalen Datensätzen trainiert werden, neuromorphe Computing-Ansätze, die biologische Verarbeitung nachahmen, und föderiertes Lernen, das den Datenschutz beim Training über verteilte Quellen hinweg wahrt.
Verfolgen Sie, wie multimodale KI-Suchmaschinen Ihre Inhalte in Text, Bildern und anderen Modalitäten mit der umfassenden Monitoring-Plattform von AmICited zitieren und zuordnen.
Meistern Sie die Optimierung für multimodale KI-Suche. Lernen Sie, wie Sie Bilder und Sprachanfragen für KI-gestützte Suchergebnisse optimieren, mit Strategien ...

Erfahren Sie, was multimodaler Inhalt für KI ist, wie er funktioniert und warum er wichtig ist. Entdecken Sie Beispiele für multimodale KI-Systeme und deren Anw...

Erfahren Sie, wie Sie Text, Bilder und Videos für multimodale KI-Systeme optimieren. Entdecken Sie Strategien zur Verbesserung von KI-Zitaten und Sichtbarkeit i...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.