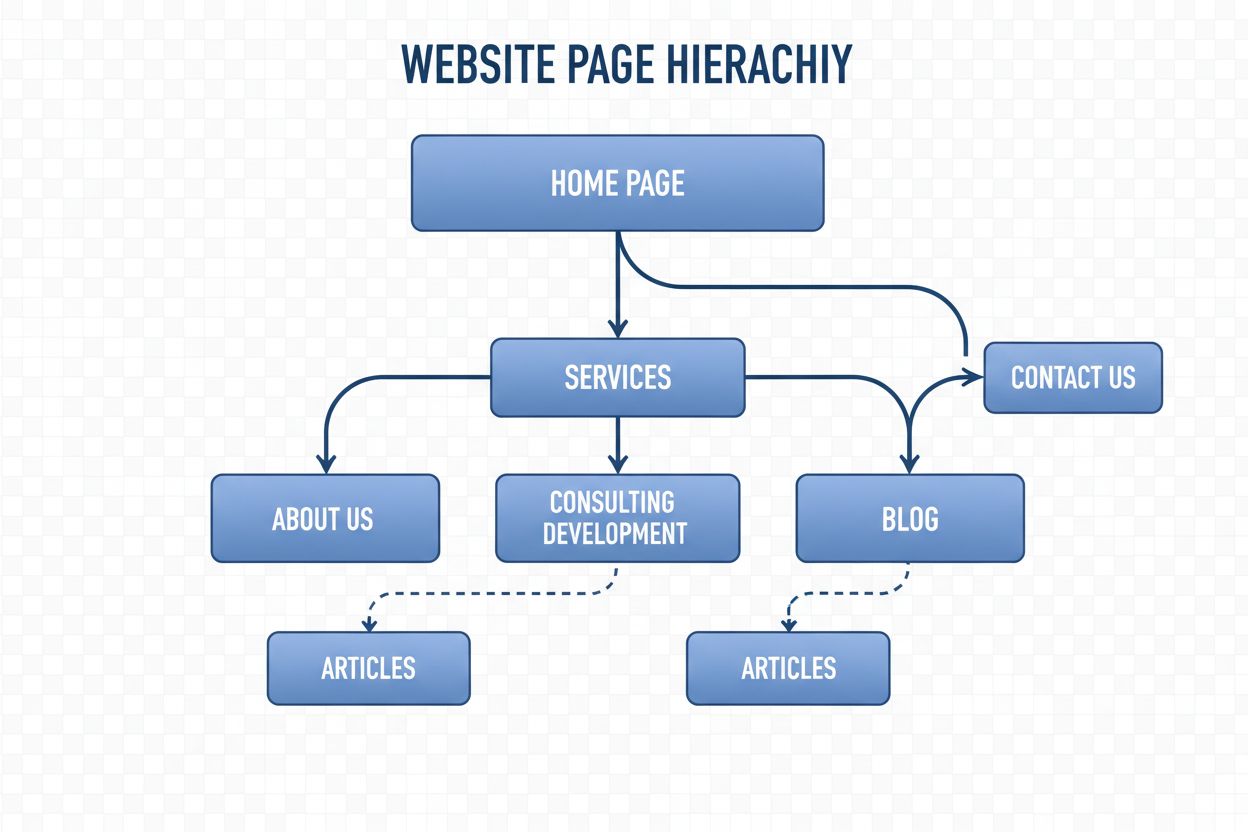
Navigationsstruktur
Navigationsstruktur ist das System, das Webseiten und Links organisiert, um Nutzer und KI-Crawler zu führen. Erfahren Sie, wie sie SEO, Nutzererlebnis und KI-In...
8 Min. Lesezeit
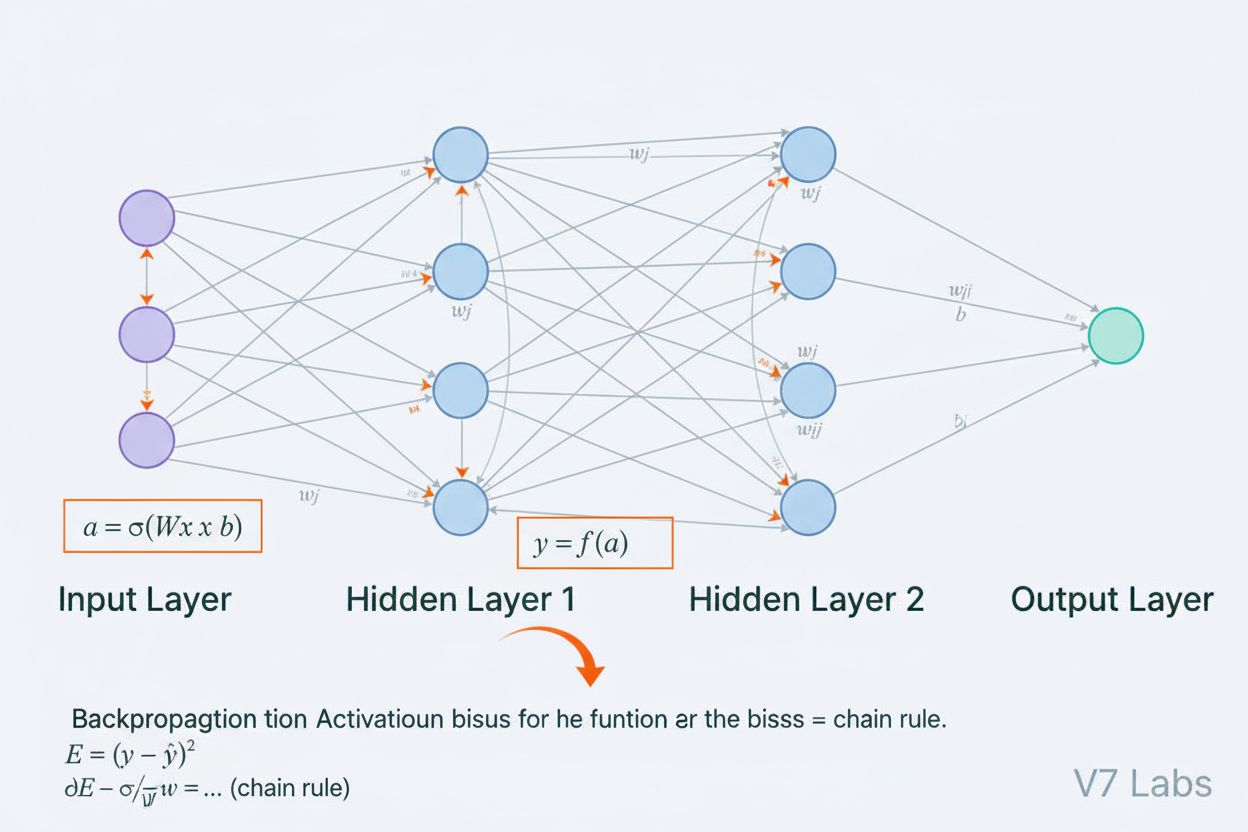
Ein neuronales Netzwerk ist ein Rechensystem, das von biologischen neuronalen Netzwerken inspiriert ist. Es besteht aus miteinander verbundenen künstlichen Neuronen, die in Schichten organisiert sind und in der Lage sind, Muster aus Daten durch einen Prozess namens Backpropagation zu erlernen. Diese Systeme bilden die Grundlage moderner künstlicher Intelligenz und des Deep Learnings und treiben Anwendungen von der Verarbeitung natürlicher Sprache bis zur Computer Vision an.
Ein neuronales Netzwerk ist ein Rechensystem, das von biologischen neuronalen Netzwerken inspiriert ist. Es besteht aus miteinander verbundenen künstlichen Neuronen, die in Schichten organisiert sind und in der Lage sind, Muster aus Daten durch einen Prozess namens Backpropagation zu erlernen. Diese Systeme bilden die Grundlage moderner künstlicher Intelligenz und des Deep Learnings und treiben Anwendungen von der Verarbeitung natürlicher Sprache bis zur Computer Vision an.
Ein neuronales Netzwerk ist ein Rechensystem, das grundlegend von der Struktur und Funktion biologischer neuronaler Netzwerke in tierischen Gehirnen inspiriert ist. Es besteht aus miteinander verbundenen künstlichen Neuronen, die in Schichten organisiert sind – typischerweise einer Eingabeschicht, einer oder mehreren versteckten Schichten und einer Ausgabeschicht –, die zusammenarbeiten, um Daten zu verarbeiten, Muster zu erkennen und Vorhersagen zu treffen. Jedes Neuron erhält Eingaben, wendet mathematische Transformationen durch Gewichte und Biases an und gibt das Ergebnis durch eine Aktivierungsfunktion weiter, um einen Ausgang zu erzeugen. Das entscheidende Merkmal neuronaler Netzwerke ist ihre Fähigkeit, durch einen iterativen Prozess namens Backpropagation aus Daten zu lernen, wobei das Netzwerk seine internen Parameter anpasst, um Vorhersagefehler zu minimieren. Diese Lernfähigkeit, kombiniert mit der Fähigkeit, komplexe nichtlineare Zusammenhänge zu modellieren, macht neuronale Netzwerke zur grundlegenden Technologie moderner KI-Systeme – von großen Sprachmodellen bis hin zu Anwendungen der Computer Vision.
Das Konzept künstlicher neuronaler Netzwerke entstand aus frühen Versuchen, mathematisch zu modellieren, wie biologische Neuronen kommunizieren und Informationen verarbeiten. 1943 stellten Warren McCulloch und Walter Pitts das erste mathematische Modell eines Neurons vor und zeigten, dass einfache Recheneinheiten logische Operationen ausführen können. Auf dieser theoretischen Grundlage folgte 1958 Frank Rosenblatts Einführung des Perzeptrons, eines Algorithmus zur Mustererkennung, der als historischer Vorfahre heutiger komplexer neuronaler Netzwerkarchitekturen gilt. Das Perzeptron war im Wesentlichen ein lineares Modell mit begrenztem Ausgang, das einfache Entscheidungsgrenzen erlernen konnte. In den 1970er Jahren erlitt das Fachgebiet jedoch erhebliche Rückschläge, als Forscher feststellten, dass einlagige Perzeptrons keine nichtlinearen Probleme wie die XOR-Funktion lösen konnten – dies führte zum sogenannten „KI-Winter“. Der Durchbruch gelang in den 1980er Jahren mit der Wiederentdeckung und Verfeinerung der Backpropagation, eines Algorithmus, der das Training mehrschichtiger Netzwerke ermöglichte. Diese Wiederbelebung beschleunigte sich in den 2010er Jahren dramatisch durch die Verfügbarkeit riesiger Datensätze, leistungsstarker GPUs und verbesserter Trainingstechniken und führte zur Deep-Learning-Revolution, die die künstliche Intelligenz grundlegend veränderte.
Die Architektur eines neuronalen Netzwerks besteht aus mehreren essenziellen Komponenten, die zusammenarbeiten. Die Eingabeschicht nimmt Rohdatenmerkmale aus externen Quellen auf, wobei jedem Neuron in dieser Schicht ein Merkmal entspricht. Versteckte Schichten übernehmen die Hauptberechnung, indem sie Eingaben über gewichtete Kombinationen und nichtlineare Aktivierungsfunktionen in immer abstraktere Repräsentationen transformieren. Die Anzahl und Größe der versteckten Schichten bestimmen die Fähigkeit des Netzwerks, komplexe Muster zu erlernen – tiefere Netzwerke können anspruchsvollere Zusammenhänge erfassen, benötigen aber mehr Daten und Rechenressourcen. Die Ausgabeschicht erzeugt die endgültigen Vorhersagen, wobei ihre Struktur von der Aufgabe abhängt: ein einzelnes Neuron für Regression, mehrere Neuronen für Multiklassenklassifikation oder spezialisierte Architekturen für andere Anwendungen. Jede Verbindung zwischen Neuronen trägt ein Gewicht, das die Stärke des Einflusses bestimmt, während jedes Neuron einen Bias besitzt, der die Aktivierungsschwelle verschiebt. Diese Gewichte und Biases sind die lernbaren Parameter, die das Netzwerk während des Trainings anpasst. Die Aktivierungsfunktion, die an jedem Neuron angewendet wird, bringt entscheidende Nichtlinearität ein und ermöglicht es dem Netzwerk, komplexe Entscheidungsgrenzen und Muster zu erlernen, die lineare Modelle nicht erfassen können.
Neuronale Netzwerke lernen durch einen zweiphasigen iterativen Prozess. Während der Vorwärtspropagation fließen Eingabedaten vom Eingabeschicht durch das Netzwerk bis zur Ausgabeschicht. Bei jedem Neuron wird die gewichtete Summe der Eingaben plus Bias berechnet (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b) und anschließend durch eine Aktivierungsfunktion geführt, um den Ausgang des Neurons zu erzeugen. Dieser Prozess wiederholt sich durch jede versteckte Schicht bis zur Ausgabeschicht, die die Vorhersage des Netzwerks liefert. Das Netzwerk berechnet dann den Fehler zwischen der Vorhersage und dem tatsächlichen Label mit einer Verlustfunktion, die misst, wie weit die Vorhersage von der korrekten Antwort abweicht. In der Backpropagation wird dieser Fehler mithilfe der Kettenregel der Differentialrechnung rückwärts durch das Netzwerk geleitet. Für jedes Neuron berechnet der Algorithmus das Gradientenmaß des Fehlers bezüglich jedes Gewichts und Bias und bestimmt, wie stark jeder Parameter zum Gesamtfehler beigetragen hat. Diese Gradienten leiten die Parameteranpassungen: Gewichte und Biases werden entgegengesetzt zum Gradienten, skaliert mit einer Lernrate, angepasst. Dieser Prozess wiederholt sich über viele Iterationen durch das Trainingsdatenset und reduziert schrittweise den Verlust und verbessert die Vorhersagen des Netzwerks. Die Kombination aus Vorwärtspropagation, Verlustberechnung, Backpropagation und Parameteranpassung bildet den vollständigen Trainingszyklus, der neuronalen Netzwerken das Lernen aus Daten ermöglicht.
| Architekturtyp | Primärer Anwendungsfall | Schlüsseleigenschaft | Stärken | Einschränkungen |
|---|---|---|---|---|
| Feedforward-Netzwerke | Klassifikation, Regression auf strukturierten Daten | Information fließt nur in eine Richtung | Einfach, schnelles Training, interpretierbar | Kann sequenzielle oder räumliche Daten schlecht verarbeiten |
| Convolutional Neural Networks (CNNs) | Bilderkennung, Computer Vision | Faltungs-Schichten erkennen räumliche Merkmale | Hervorragend im Erfassen lokaler Muster, parametereffizient | Erfordert große, gelabelte Bilddatensätze |
| Recurrent Neural Networks (RNNs) | Sequenzielle Daten, Zeitreihen, NLP | Versteckter Zustand speichert Informationen über Zeitschritte | Kann Sequenzen variabler Länge verarbeiten | Leidet unter vanishing/exploding gradients |
| Long Short-Term Memory (LSTM) | Langzeitabhängigkeiten in Sequenzen | Speichereinheiten mit Eingabe-/Vergessens-/Ausgangstoren | Effektive Verarbeitung von Langzeitabhängigkeiten | Komplexer, langsameres Training als RNNs |
| Transformer-Netzwerke | Verarbeitung natürlicher Sprache, große Sprachmodelle | Multi-Head Attention, parallele Verarbeitung | Hochgradig parallelisierbar, erfasst Langzeitabhängigkeiten | Erfordert enorme Rechenressourcen |
| Generative Adversarial Networks (GANs) | Bildgenerierung, Erstellung synthetischer Daten | Generator- und Diskriminator-Netzwerke konkurrieren | Kann realistische synthetische Daten erzeugen | Schwer zu trainieren, Mode-Kollaps-Probleme |
Die Einführung von Aktivierungsfunktionen stellt eine der wichtigsten Innovationen im Design neuronaler Netzwerke dar. Ohne Aktivierungsfunktionen wäre ein neuronales Netzwerk mathematisch äquivalent zu einer einzigen linearen Transformation, unabhängig von der Anzahl der Schichten. Das liegt daran, dass die Verkettung linearer Funktionen selbst linear bleibt, was die Fähigkeit des Netzwerks, komplexe Muster zu erlernen, stark einschränkt. Aktivierungsfunktionen lösen dieses Problem, indem sie an jedem Neuron Nichtlinearität einführen. Die ReLU (Rectified Linear Unit) Funktion, definiert als f(x) = max(0, x), ist heute die beliebteste Wahl im Deep Learning aufgrund ihrer rechnerischen Effizienz und Effektivität beim Training tiefer Netzwerke. Die Sigmoid-Funktion, f(x) = 1/(1 + e^(-x)), transformiert Ausgaben in den Bereich zwischen 0 und 1 und ist nützlich für binäre Klassifikationsaufgaben. Die Tanh-Funktion, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), liefert Werte zwischen -1 und 1 und ist in versteckten Schichten häufig leistungsfähiger als die Sigmoidfunktion. Die Wahl der Aktivierungsfunktion hat großen Einfluss auf die Lerndynamik, Konvergenzgeschwindigkeit und die Endleistung des Netzwerks. Moderne Architekturen verwenden oft ReLU in versteckten Schichten für Effizienz und Sigmoid oder Softmax in Ausgabeschichten zur Wahrscheinlichkeitsabschätzung. Die durch Aktivierungsfunktionen eingeführte Nichtlinearität ermöglicht es neuronalen Netzwerken, jede stetige Funktion zu approximieren – ein als Universal Approximation Theorem bekanntes Prinzip, das ihre bemerkenswerte Vielseitigkeit über verschiedene Anwendungsgebiete hinweg erklärt.
Der Markt für neuronale Netzwerke hat ein explosives Wachstum erlebt, was die zentrale Rolle dieser Technologie in der modernen künstlichen Intelligenz widerspiegelt. Laut aktuellen Marktforschungen wurde der globale Markt für neuronale Netzwerksoftware im Jahr 2025 auf etwa 34,76 Milliarden US-Dollar geschätzt und soll bis 2030 auf 139,86 Milliarden US-Dollar anwachsen, was einer jährlichen Wachstumsrate (CAGR) von 32,10 % entspricht. Der breitere Markt für neuronale Netzwerke zeigt sogar noch dramatischere Expansion, mit Schätzungen von 34,05 Milliarden US-Dollar im Jahr 2024 auf 385,29 Milliarden US-Dollar bis 2033 bei einer CAGR von 31,4 %. Dieses rasante Wachstum wird durch mehrere Faktoren angetrieben: die zunehmende Verfügbarkeit großer Datensätze, die Entwicklung effizienterer Trainingsalgorithmen, die Verbreitung von GPUs und spezialisierter KI-Hardware sowie die breite Einführung neuronaler Netzwerke in allen Branchen. Laut dem AI Index Report von Stanford 2025 berichteten 78 % der Unternehmen, dass sie 2024 KI einsetzen, gegenüber 55 % im Vorjahr, wobei neuronale Netzwerke das Rückgrat der meisten KI-Implementierungen in Unternehmen bilden. Die Anwendung reicht von Gesundheitswesen, Finanzwesen, Fertigung, Einzelhandel bis praktisch in alle anderen Sektoren, da Organisationen den Wettbewerbsvorteil neuronaler Netzwerksysteme für Mustererkennung, Vorhersagen und Entscheidungsfindung erkennen.
Neuronale Netzwerke treiben die derzeit fortschrittlichsten KI-Systeme an, darunter ChatGPT, Perplexity, Google AI Overviews und Claude. Diese großen Sprachmodelle basieren auf transformerbasierten neuronalen Netzwerkarchitekturen, die Aufmerksamkeitsmechanismen nutzen, um menschliche Sprache mit bemerkenswerter Raffinesse zu verarbeiten und zu generieren. Die Transformer-Architektur, eingeführt 2017, revolutionierte die Verarbeitung natürlicher Sprache, indem sie die parallele Verarbeitung ganzer Sequenzen – statt sequentieller Verarbeitung – ermöglichte, was die Trainingseffizienz und Modellleistung erheblich steigerte. Im Kontext von Markenüberwachung und KI-Zitations-Tracking ist das Verständnis neuronaler Netzwerke entscheidend, weil diese Systeme neuronale Netzwerke nutzen, um Kontext zu erfassen, relevante Informationen abzurufen und Antworten zu generieren, die Ihre Marke, Domain oder Inhalte referenzieren können. AmICited nutzt das Wissen darüber, wie neuronale Netzwerke Informationen verarbeiten und abrufen, um zu überwachen, wo Ihre Marke in KI-generierten Antworten auf verschiedenen Plattformen erscheint. Da neuronale Netzwerke immer besser darin werden, semantische Bedeutungen zu verstehen und relevante Informationen abzurufen, wird das Monitoring Ihrer Markenpräsenz in KI-Antworten immer entscheidender, um Sichtbarkeit und Reputation im Zeitalter KI-basierter Suche und Content-Generierung zu sichern.
Das effektive Training neuronaler Netzwerke stellt Forscher und Praktiker vor einige große Herausforderungen. Overfitting tritt auf, wenn ein Netzwerk die Trainingsdaten zu gut lernt – einschließlich deren Rauschen und Besonderheiten – und dadurch auf neuen, unbekannten Daten schlecht abschneidet. Dies ist besonders problematisch bei tiefen Netzwerken mit vielen Parametern im Verhältnis zur Trainingsdatengröße. Underfitting ist das Gegenstück, bei dem das Netzwerk nicht genug Kapazität oder Training hat, um die zugrundeliegenden Muster in den Daten zu erfassen. Das Vanishing-Gradient-Problem tritt in sehr tiefen Netzwerken auf, wenn Gradienten beim Rückwärtsdurchlauf exponentiell kleiner werden und die Gewichte in frühen Schichten sich kaum noch ändern. Das Exploding-Gradient-Problem ist das Gegenteil und führt zu instabilen Trainingsprozessen. Moderne Lösungen umfassen Batch-Normalisierung, um Eingaben von Schichten zu normalisieren und stabile Gradientenflüsse zu erhalten; ResNet-Verbindungen (skip connections), die Gradienten direkt durch Schichten leiten; sowie Gradient Clipping, das die Gradienten auf einen Maximalbetrag begrenzt. Regularisierungstechniken wie L1- und L2-Regularisierung fügen Strafwerte für große Gewichte hinzu und fördern so einfachere Modelle mit besserer Generalisierung. Dropout deaktiviert während des Trainings zufällig Neuronen, um Ko-Adaptation zu verhindern und die Generalisierung zu verbessern. Die Wahl des Optimierers (wie Adam, SGD oder RMSprop) und der Lernrate hat großen Einfluss auf Trainingseffizienz und die endgültige Modellleistung. Praktiker müssen Modellkomplexität, Trainingsdatengröße, Regularisierungsstärke und Optimierungsparameter sorgfältig ausbalancieren, um Netzwerke zu erreichen, die effektiv lernen, ohne zu überanpassen.
Die Entwicklung neuronaler Netzwerkarchitekturen folgt einer klaren Tendenz zu immer ausgefeilteren Mechanismen der Informationsverarbeitung. Frühe Feedforward-Netzwerke waren auf Eingaben fester Größe beschränkt und konnten keine zeitlichen oder sequentiellen Abhängigkeiten erfassen. Rekurrente neuronale Netzwerke (RNNs) führten Rückkopplungsschleifen ein, sodass Informationen über Zeitpunkte hinweg erhalten bleiben konnten – und damit auch variable Längen von Sequenzen verarbeitbar wurden. RNNs litten jedoch unter Gradientenproblemen und waren inhärent sequentiell, was die Parallelisierung auf moderner Hardware verhinderte. Long Short-Term Memory (LSTM)-Netzwerke adressierten einige dieser Probleme mit Speichereinheiten und Gate-Mechanismen, blieben aber grundsätzlich sequentiell. Den Durchbruch brachten Transformer-Netzwerke, die Rekurrenz vollständig durch Aufmerksamkeitsmechanismen ersetzten. Der Attention-Mechanismus ermöglicht es dem Netzwerk, dynamisch auf unterschiedliche Teile der Eingabe zu fokussieren und gewichtete Kombinationen aller Elemente in der Eingabe parallel zu berechnen. So können Transformer effizient Langzeitabhängigkeiten erfassen und gleichzeitig vollständige Parallelisierung auf GPU-Clustern ermöglichen. Die Transformer-Architektur, kombiniert mit enormer Skalierung (moderne große Sprachmodelle enthalten Milliarden bis Billionen Parameter), hat sich für die Verarbeitung natürlicher Sprache, Computer Vision und multimodale Aufgaben als äußerst effektiv erwiesen. Der Erfolg der Transformer führte zu ihrer Übernahme als Standardarchitektur für modernste KI-Systeme, einschließlich aller großen Sprachmodelle. Diese Entwicklung zeigt, wie architektonische Innovationen, kombiniert mit wachsender Rechenleistung und größeren Datensätzen, die Leistungsfähigkeit neuronaler Netzwerke immer weiter vorantreiben.
Das Feld der neuronalen Netzwerke entwickelt sich rasant weiter und es zeichnen sich mehrere vielversprechende Richtungen ab. Neuromorphes Computing zielt darauf ab, Hardware zu schaffen, die biologischen neuronalen Netzwerken noch näher kommt, um eine höhere Energieeffizienz und Rechenleistung zu erreichen. Few-shot- und Zero-shot-Learning erforschen, wie neuronale Netzwerke aus minimalen Beispielen lernen können – ähnlich wie Menschen es tun. Erklärbarkeit und Interpretierbarkeit gewinnen zunehmend an Bedeutung, da Forscher Methoden entwickeln, um zu verstehen und zu visualisieren, was neuronale Netzwerke tatsächlich lernen, was gerade in sicherheitskritischen Bereichen wie Medizin, Finanzen und Strafjustiz entscheidend ist. Federated Learning ermöglicht das Training neuronaler Netzwerke auf verteilten Daten, ohne sensible Informationen zentralisieren zu müssen, und begegnet so Datenschutzbedenken. Quantenneuronale Netzwerke kombinieren Prinzipien der Quanteninformatik mit neuronalen Netzwerkarchitekturen und könnten für bestimmte Probleme exponentielle Geschwindigkeitsvorteile bringen. Multimodale neuronale Netzwerke, die Text, Bilder, Audio und Video nahtlos integrieren, werden immer ausgefeilter und ermöglichen umfassendere KI-Systeme. Energieeffiziente neuronale Netzwerke werden entwickelt, um den Rechen- und Umweltaufwand für Training und Einsatz großer Modelle zu reduzieren. Während neuronale Netzwerke weiter voranschreiten, wird ihre Integration in KI-Überwachungssysteme wie AmICited für Unternehmen, die ihre Markenpräsenz in KI-generierten Inhalten und Antworten auf Plattformen wie ChatGPT, Perplexity, Google AI Overviews und Claude verstehen und steuern möchten, immer wichtiger.
Neuronale Netzwerke sind vom Aufbau und der Funktion biologischer Neuronen im menschlichen Gehirn inspiriert. Im Gehirn kommunizieren Neuronen über elektrische Signale durch Synapsen, die basierend auf Erfahrungen gestärkt oder geschwächt werden können. Künstliche neuronale Netzwerke ahmen dieses Verhalten nach, indem sie mathematische Modelle von Neuronen verwenden, die durch gewichtete Verbindungen verbunden sind. So kann das System in einer Weise aus Daten lernen und sich anpassen, die dem Informationsverarbeitungs- und Gedächtnisbildungsprozess biologischer Gehirne ähnelt.
Backpropagation ist der Hauptalgorithmus, der neuronalen Netzwerken das Lernen ermöglicht. Während der Vorwärtspropagation fließen Daten durch die Netzwerkschichten und erzeugen Vorhersagen. Das Netzwerk berechnet dann den Fehler zwischen den vorhergesagten und den tatsächlichen Ausgaben mithilfe einer Verlustfunktion. Im Rückwärtsdurchlauf wird dieser Fehler unter Verwendung der Kettenregel der Differentialrechnung durch das Netzwerk zurückpropagiert, wobei berechnet wird, wie stark jedes Gewicht und jeder Bias zum Fehler beigetragen hat. Die Gewichte werden dann in die Richtung angepasst, die den Fehler minimiert, typischerweise mithilfe von Gradientenabstiegsverfahren.
Die primären neuronalen Netzwerkarchitekturen umfassen Feedforward-Netzwerke (Daten fließen nur in eine Richtung), Convolutional Neural Networks oder CNNs (optimiert für die Bildverarbeitung), Recurrent Neural Networks oder RNNs (entwickelt für sequenzielle Daten), Long Short-Term Memory Netzwerke oder LSTMs (verbesserte RNNs mit Speichereinheiten) und Transformer-Netzwerke (nutzen Aufmerksamkeitsmechanismen für parallele Verarbeitung). Jede Architektur ist auf unterschiedliche Datentypen und Aufgaben spezialisiert, von der Bilderkennung bis zur Verarbeitung natürlicher Sprache.
Moderne KI-Systeme wie ChatGPT, Perplexity und Claude basieren auf transformerbasierten neuronalen Netzwerken, die Aufmerksamkeitsmechanismen nutzen, um Sprache effizient zu verarbeiten. Diese neuronalen Netzwerke ermöglichen es den Systemen, Kontext zu verstehen, kohärente Texte zu generieren und komplexe Denkaufgaben zu lösen. Die Fähigkeit neuronaler Netzwerke, aus riesigen Datensätzen zu lernen und komplexe Muster in Sprache zu erfassen, macht sie unverzichtbar für die Entwicklung konversationeller KI, die menschliche Anfragen mit bemerkenswerter Genauigkeit verstehen und beantworten kann.
Gewichte in neuronalen Netzwerken steuern die Stärke der Verbindungen zwischen Neuronen und bestimmen, wie stark jeder Eingang das Ergebnis beeinflusst. Biases sind zusätzliche Parameter, die die Aktivierungsschwelle von Neuronen verschieben und es ihnen ermöglichen, auch bei schwachen Eingaben zu feuern. Zusammen bilden Gewichte und Biases die lernbaren Parameter des Netzwerks, die während des Trainings angepasst werden, um Vorhersagefehler zu minimieren und das Netzwerk in die Lage zu versetzen, komplexe Muster aus Daten zu erlernen.
Aktivierungsfunktionen bringen Nichtlinearität in neuronale Netzwerke und ermöglichen es ihnen, komplexe, nichtlineare Zusammenhänge in Daten zu erlernen. Ohne Aktivierungsfunktionen würden mehrere Schichten lediglich lineare Transformationen ergeben und die Lernfähigkeit des Netzwerks stark einschränken. Gängige Aktivierungsfunktionen sind ReLU (Rectified Linear Unit), Sigmoid und Tanh. Jede bringt eine andere Art von Nichtlinearität ein, die dem Netzwerk hilft, komplexe Muster zu erfassen und anspruchsvollere Vorhersagen zu ermöglichen.
Versteckte Schichten sind Zwischenschichten zwischen Eingabe- und Ausgabeschicht, in denen das Netzwerk den Großteil seiner Berechnungen durchführt. Diese Schichten extrahieren und transformieren Merkmale aus Rohdaten in immer abstraktere Repräsentationen. Die Tiefe und Breite der versteckten Schichten bestimmen die Fähigkeit des Netzwerks, komplexe Muster zu erlernen. Tiefere Netzwerke mit mehr versteckten Schichten können anspruchsvollere Zusammenhänge erfassen, benötigen jedoch mehr Rechenleistung und sorgfältiges Training, um Überanpassung zu vermeiden.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Navigationsstruktur ist das System, das Webseiten und Links organisiert, um Nutzer und KI-Crawler zu führen. Erfahren Sie, wie sie SEO, Nutzererlebnis und KI-In...
Erfahren Sie, was ein Private Blog Network (PBN) ist, wie es funktioniert, warum es gegen Google-Richtlinien verstößt und welche Risiken beim Einsatz von PBNs i...

Die Transformer-Architektur ist ein neuronales Netzwerkdesign, das Self-Attention-Mechanismen nutzt, um sequentielle Daten parallel zu verarbeiten. Sie treibt C...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.