Eine Retrieval-Augmented Generation (RAG)-Pipeline ist ein Workflow, der es KI-Systemen ermöglicht, externe Quellen beim Generieren von Antworten zu finden, zu bewerten und zu zitieren. Sie kombiniert Dokumentenabruf, semantisches Ranking und LLM-Generierung, um genaue, kontextuell relevante Antworten zu liefern, die auf realen Daten basieren. RAG-Systeme reduzieren Halluzinationen, indem sie vor der Antwortgenerierung externe Wissensdatenbanken konsultieren, was sie für Anwendungen, die faktische Genauigkeit und Quellenangaben erfordern, unverzichtbar macht.
RAG-Pipeline
Eine Retrieval-Augmented Generation (RAG)-Pipeline ist ein Workflow, der es KI-Systemen ermöglicht, externe Quellen beim Generieren von Antworten zu finden, zu bewerten und zu zitieren. Sie kombiniert Dokumentenabruf, semantisches Ranking und LLM-Generierung, um genaue, kontextuell relevante Antworten zu liefern, die auf realen Daten basieren. RAG-Systeme reduzieren Halluzinationen, indem sie vor der Antwortgenerierung externe Wissensdatenbanken konsultieren, was sie für Anwendungen, die faktische Genauigkeit und Quellenangaben erfordern, unverzichtbar macht.
Was ist eine RAG-Pipeline?
Eine Retrieval-Augmented Generation (RAG)-Pipeline ist eine KI-Architektur, die Informationsabruf mit der Generierung durch große Sprachmodelle (LLMs) kombiniert, um genauere, kontextuell relevante und überprüfbare Antworten zu erstellen. Anstatt sich ausschließlich auf die Trainingsdaten eines LLM zu verlassen, holen RAG-Systeme vor der Antwortgenerierung relevante Dokumente oder Daten aus externen Wissensdatenbanken, was Halluzinationen deutlich verringert und die faktische Genauigkeit verbessert. Die Pipeline fungiert als Brücke zwischen statischen Trainingsdaten und Echtzeitinformationen und ermöglicht KI-Systemen den Zugriff auf aktuelle, domänenspezifische oder proprietäre Inhalte. Dieser Ansatz ist für Organisationen unerlässlich geworden, die zitierfähige Antworten, Einhaltung von Genauigkeitsstandards und Transparenz bei KI-generierten Inhalten verlangen. RAG-Pipelines sind besonders wertvoll bei der Überwachung von KI-Systemen, bei denen Rückverfolgbarkeit und Quellenangabe entscheidende Anforderungen sind.
Zentrale Komponenten
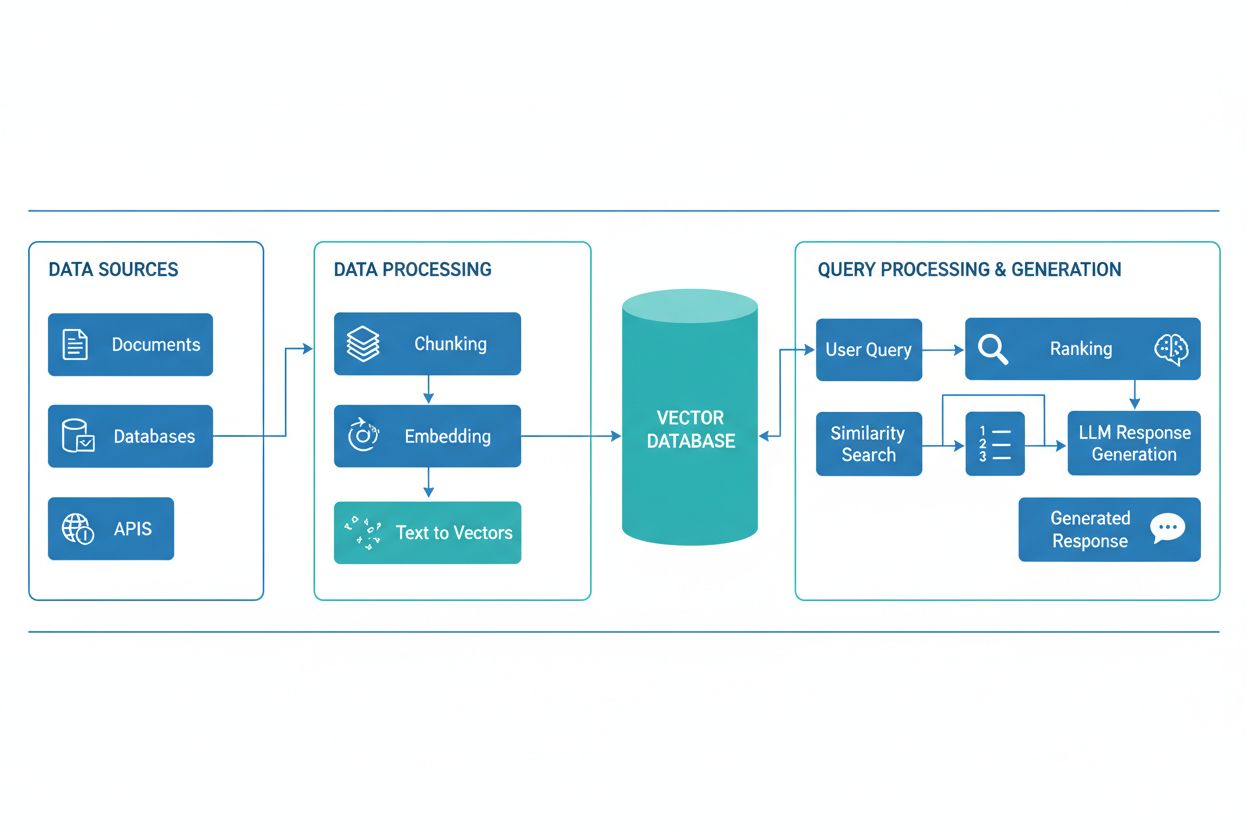
Eine RAG-Pipeline besteht aus mehreren miteinander verbundenen Komponenten, die gemeinsam relevante Informationen abrufen und fundierte Antworten generieren. Die Architektur umfasst typischerweise eine Dokumentenaufnahme-Schicht, die Rohdaten verarbeitet und vorbereitet, eine Vektordatenbank oder Wissensbasis, die Einbettungen und indizierte Inhalte speichert, einen Abrufmechanismus, der relevante Dokumente basierend auf Nutzeranfragen identifiziert, ein Rankingsystem, das die relevantesten Ergebnisse priorisiert, sowie ein Generierungsmodul, das von einem LLM betrieben wird und abgerufene Informationen in kohärente Antworten umwandelt. Weitere Komponenten sind Module zur Anfrageverarbeitung und -vorverarbeitung, die Nutzereingaben normalisieren, Einbettungsmodelle, die Text in Zahlen repräsentieren, und Regelkreise, die die Abrufgenauigkeit kontinuierlich verbessern. Das Zusammenspiel dieser Komponenten bestimmt die Gesamteffektivität und Effizienz des RAG-Systems.
Komponente
Funktion
Schlüsseltechnologien
Dokumentenaufnahme
Verarbeitung und Vorbereitung von Rohdaten
Apache Kafka, LangChain, Unstructured
Vektordatenbank
Speicherung von Einbettungen und indizierten Inhalten
Die RAG-Pipeline arbeitet in zwei klar getrennten Phasen: der Abrufphase und der Generierungsphase. In der Abrufphase wandelt das System die Nutzeranfrage mit demselben Einbettungsmodell, das auch für die Wissensbasis genutzt wurde, in eine Einbettung um und durchsucht dann die Vektordatenbank, um die semantisch ähnlichsten Dokumente oder Passagen zu finden. Diese Phase liefert typischerweise eine sortierte Liste von Kandidatendokumenten, die durch Re-Ranking-Algorithmen mit Cross-Encodern oder LLM-basierter Bewertung weiter verfeinert werden können, um die Relevanz sicherzustellen. In der Generierungsphase werden die am höchsten bewerteten, abgerufenen Dokumente in ein Kontextfenster formatiert und dem LLM zusammen mit der Originalanfrage übergeben, sodass das Modell Antworten erzeugen kann, die auf tatsächlichem Quellenmaterial beruhen. Dieser Zwei-Phasen-Ansatz stellt sicher, dass Antworten sowohl kontextuell passend als auch auf konkrete Quellen zurückführbar sind – ideal für Anwendungen, bei denen Zitate und Nachvollziehbarkeit wichtig sind. Die Qualität des Endergebnisses hängt entscheidend sowohl von der Relevanz der abgerufenen Dokumente als auch von der Fähigkeit des LLMs ab, die Informationen kohärent zusammenzufassen.
Schlüsseltechnologien & Werkzeuge
Das RAG-Ökosystem umfasst eine breite Palette spezialisierter Werkzeuge und Frameworks, die den Aufbau und die Implementierung von Pipelines vereinfachen. Moderne RAG-Implementierungen nutzen mehrere Technologiekategorien:
Orchestrierungsframeworks: LangChain, LlamaIndex (früher GPT Index) und Haystack bieten Abstraktionsschichten für den Aufbau von RAG-Workflows, ohne jede Komponente einzeln verwalten zu müssen
Vektordatenbanken: Pinecone, Weaviate, Milvus, Qdrant und Chroma ermöglichen skalierbare Speicherung und schnellen Abruf hochdimensionaler Einbettungen mit Abfragezeiten im Millisekundenbereich
Einbettungsmodelle: OpenAIs text-embedding-3, Cohere’s Embed API und Open-Source-Modelle wie all-MiniLM-L6-v2 wandeln Text in semantische Repräsentationen um
LLM-Anbieter: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) und Mistral bieten verschiedene Modellgrößen und Fähigkeiten für Generierungsaufgaben
Re-Ranking-Lösungen: Cohere’s Rerank API, Cross-Encoder-Modelle von Hugging Face und proprietäre, LLM-basierte Reranker verbessern die Abrufpräzision
Datenvorbereitungstools: Unstructured, Apache Kafka und individuelle ETL-Pipelines übernehmen die Dokumentenaufnahme, das Chunking und die Vorverarbeitung
Monitoring und Evaluation: Werkzeuge wie Ragas, TruLens und individuelle Bewertungsframeworks überprüfen die Leistung von RAG-Systemen und identifizieren Schwachstellen
Diese Tools können modular kombiniert werden, sodass Organisationen RAG-Systeme individuell auf ihre Anforderungen und Infrastruktur zuschneiden können.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Abrufmechanismen
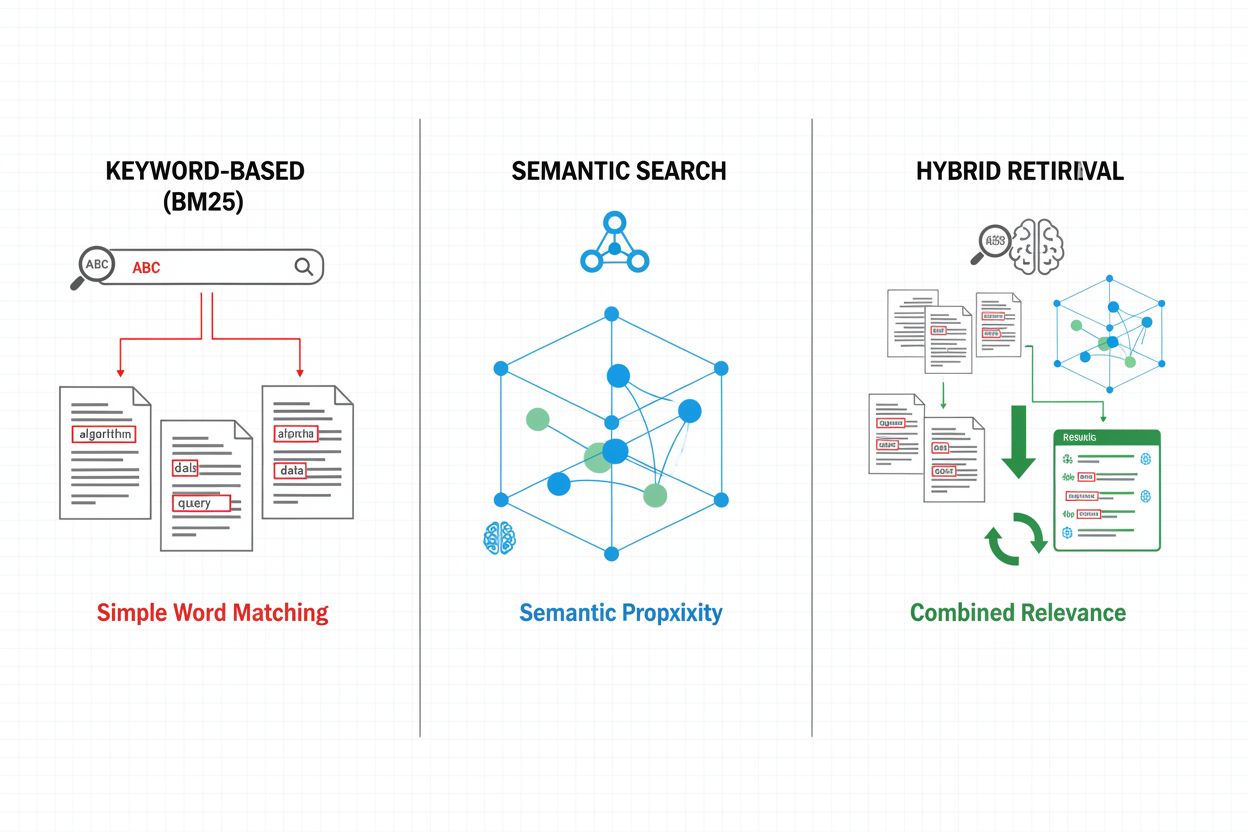
Abrufmechanismen bilden das Fundament der Effektivität einer RAG-Pipeline und reichen von einfachen Stichwortverfahren bis zu komplexen semantischen Suchmethoden. Traditioneller, stichwortbasierter Abruf mit BM25-Algorithmen bleibt recheneffizient und bei exakten Treffern wirksam, kann jedoch keine semantischen Zusammenhänge oder Synonyme erfassen. Dense Passage Retrieval (DPR) und andere neuronale Abrufmethoden begegnen diesen Einschränkungen, indem sie sowohl Anfragen als auch Dokumente in dichte Vektoreinbettungen kodieren, sodass semantische Ähnlichkeiten jenseits bloßer Schlüsselwörter erkannt werden können. Hybride Abrufansätze kombinieren Stichwort- und semantische Suche und nutzen so die Stärken beider Methoden, um Recall und Präzision für verschiedene Anfragearten zu verbessern. Fortschrittliche Abrufmechanismen nutzen Query Expansion, bei der die ursprüngliche Anfrage um verwandte Begriffe oder Umformulierungen ergänzt wird, um mehr relevante Dokumente zu erfassen. Re-Ranking-Schichten verfeinern die Ergebnisse durch den Einsatz aufwändigerer Modelle, die Kandidatendokumente nach tieferem semantischem Verständnis oder aufgabenspezifischen Kriterien bewerten. Die Wahl des Abrufmechanismus beeinflusst maßgeblich sowohl die Genauigkeit des abgerufenen Kontexts als auch die Rechenkosten der RAG-Pipeline – hier gilt es, sorgfältig zwischen Geschwindigkeit und Qualität abzuwägen.
Vorteile von RAG-Pipelines
RAG-Pipelines bieten erhebliche Vorteile gegenüber reinen LLM-Lösungen, insbesondere für Anwendungen, die Genauigkeit, Aktualität und Nachvollziehbarkeit verlangen. Durch das Fundieren von Antworten auf abgerufenen Dokumenten reduzieren RAG-Systeme Halluzinationen drastisch – also Fälle, in denen LLMs plausibel klingende, aber faktisch falsche Informationen erzeugen – und eignen sich so für kritische Bereiche wie Gesundheitswesen, Recht oder Finanzdienstleistungen. Der Zugriff auf externe Wissensdatenbanken ermöglicht es RAG-Systemen, aktuelle Informationen zu liefern, ohne Modelle neu trainieren zu müssen, sodass Organisationen ihre Antworten stets aktuell halten können. RAG-Pipelines unterstützen domänenspezifische Anpassungen durch die Integration proprietärer Dokumente, interner Wissensbasen und spezieller Terminologie – so entstehen relevantere und besser kontextualisierte Antworten. Die Abrufkomponente sorgt für Transparenz und Nachprüfbarkeit, indem sie explizit zeigt, welche Quellen jede Antwort beeinflusst haben – ein entscheidender Faktor für Compliance und Nutzervertrauen. Die Kosteneffizienz steigt, weil kleinere, effizientere LLMs hochwertige Antworten liefern können, wenn sie mit relevantem Kontext versorgt werden, wodurch der Rechenaufwand im Vergleich zu größeren Modellen sinkt. Diese Vorteile machen RAG besonders wertvoll für Organisationen, die KI-Überwachungssysteme einsetzen, bei denen Zitiergenauigkeit und Inhaltsnachvollziehbarkeit im Mittelpunkt stehen.
Herausforderungen und Einschränkungen
Trotz aller Vorteile stehen RAG-Pipelines vor mehreren technischen und betrieblichen Herausforderungen, die sorgfältig gemanagt werden müssen. Die Qualität der abgerufenen Dokumente bestimmt direkt die Antwortqualität – Fehler beim Abruf lassen sich schwer ausgleichen, was als “garbage in, garbage out” bezeichnet wird: Irrelevante oder veraltete Dokumente in der Wissensbasis schlagen sich unmittelbar in den Antworten nieder. Einbettungsmodelle können Schwierigkeiten mit domänenspezifischer Terminologie, seltenen Sprachen oder hochspezifischem Fachwissen haben, was zu schlechter semantischer Zuordnung und übersehenen relevanten Dokumenten führt. Der Rechenaufwand für Abruf, Einbettungserstellung und Re-Ranking kann im großen Maßstab erheblich sein, besonders bei großen Wissensbasen oder hohem Anfragevolumen. Begrenzungen des Kontextfensters in LLMs schränken die Menge an abgerufenen Informationen ein, die in Prompts eingebunden werden können, was eine sorgfältige Auswahl und Zusammenfassung relevanter Passagen erfordert. Die Aktualität und Konsistenz der Wissensbasis zu gewährleisten ist operativ herausfordernd – insbesondere in dynamischen Umgebungen mit häufig wechselnden oder aus verschiedenen Quellen stammenden Informationen. Die Bewertung der RAG-Leistung erfordert umfassende Metriken jenseits traditioneller Genauigkeitsmessungen, darunter Abrufpräzision, Antwortrelevanz und Zitierkorrektheit – was sich oft nur schwer automatisiert erfassen lässt.
RAG im Vergleich zu anderen Ansätzen
RAG ist eine von mehreren Strategien zur Verbesserung von LLM-Genauigkeit und -Relevanz – jede hat eigene Stärken und Schwächen. Fine-Tuning bedeutet das Nachtrainieren von LLMs mit domänenspezifischen Daten. Dies ermöglicht tiefe Modellanpassung, erfordert aber viel Rechenleistung, gelabelte Trainingsdaten und laufende Wartung bei Informationsänderungen. Prompt Engineering optimiert Instruktionen und Kontext für LLMs, ohne Modellgewichte zu verändern – das ist flexibel und kostengünstig, aber durch Trainingsdaten und Kontextfenstergröße limitiert. In-Context Learning nutzt wenige Beispiele direkt im Prompt, um das Modellverhalten schnell zu beeinflussen – das ist rasch umsetzbar, verbraucht aber wertvolle Kontexteinheiten und verlangt sorgfältige Beispielauswahl. Im Vergleich dazu bietet RAG einen Mittelweg: Es ermöglicht dynamischen Zugriff auf aktuelle Informationen ohne Neutraining, schafft Transparenz durch explizite Quellenangabe und skaliert effizient über viele Wissensbereiche. Allerdings bringt RAG zusätzliche Komplexität durch Abruf-Infrastruktur und potenzielle Abruffehler mit sich, während Fine-Tuning domänenspezifisches Wissen stärker ins Modell integriert. Oft ist die optimale Lösung eine Kombination mehrerer Ansätze – zum Beispiel RAG mit feinabgestimmten Modellen und sorgfältig gestalteten Prompts – um für einen bestimmten Anwendungsfall maximale Genauigkeit und Relevanz zu erzielen.
Aufbau und Einsatz von RAG
Die Implementierung einer produktiven RAG-Pipeline erfordert systematische Planung in Bezug auf Datenvorbereitung, Architekturdesign und Betrieb. Der Prozess beginnt mit der Vorbereitung der Wissensbasis: relevante Dokumente sammeln, Formate bereinigen und standardisieren und Inhalte in passend große Abschnitte unterteilen, um Kontexttreue und Abrufpräzision auszubalancieren. Danach wählen Organisationen Einbettungsmodelle und Vektordatenbanken basierend auf Leistungsanforderungen, Latenz- und Skalierbarkeitsaspekten – Faktoren wie Einbettungsdimensionalität, Abfragedurchsatz und Speicherkapazität sind hier entscheidend. Das Abrufsystem wird konfiguriert, unter anderem hinsichtlich der eingesetzten Algorithmen (Stichwort, semantisch oder hybrid), Re-Ranking-Strategien und Filterkriterien. Anschließend erfolgt die Integration mit LLM-Anbietern, das Aufsetzen von Generierungsmodellen und die Definition von Prompt-Vorlagen, die den abgerufenen Kontext optimal einbinden. Test und Evaluation sind kritisch – dazu gehören Metriken für Abrufqualität (Präzision, Recall, MRR), Generierungsqualität (Relevanz, Kohärenz, Faktentreue) und die Gesamtleistung des Systems. Für die Bereitstellung sind Überwachung der Abrufgenauigkeit und Generierungsqualität, Feedback-Schleifen zur Fehleridentifikation und die Organisation regelmäßiger Aktualisierungen der Wissensbasis zentral. Kontinuierliche Optimierung umfasst die Analyse von Nutzerinteraktionen, das Erkennen häufiger Fehler und die iterative Verbesserung von Abrufmechanismen, Re-Ranking-Strategien und Prompt Engineering zur Steigerung der Systemleistung.
RAG in KI-Monitoring und Zitierung
RAG-Pipelines sind die Grundlage moderner KI-Monitoring-Plattformen wie AmICited.com, bei denen die Nachverfolgung von Quellen und die Überprüfung der Genauigkeit KI-generierter Inhalte essenziell sind. Durch den expliziten Abruf und die Zitierung von Quelldokumenten erzeugen RAG-Systeme eine auditierbare Spur, die es Monitoring-Plattformen ermöglicht, Aussagen zu überprüfen, Faktentreue zu beurteilen und potenzielle Halluzinationen oder Fehlnennungen zu identifizieren. Diese Zitationsfähigkeit schließt eine entscheidende Lücke in Sachen KI-Transparenz: Nutzer und Prüfer können Antworten bis zu den Originalquellen zurückverfolgen, sie unabhängig verifizieren und so Vertrauen in KI-generierte Inhalte aufbauen. Für Content-Ersteller und Organisationen, die KI-Tools verwenden, ermöglicht RAG-basiertes Monitoring Einblick, welche Quellen einzelne Antworten beeinflusst haben und unterstützt so die Einhaltung von Zitationspflichten und Content-Governance-Regeln. Die Abrufkomponente von RAG-Pipelines erzeugt reichhaltige Metadaten – darunter Relevanzbewertungen, Dokumentenrankings und Abrufvertrauensmetriken –, die von Monitoring-Systemen zur Beurteilung der Antwortzuverlässigkeit analysiert werden können und anzeigen, wann KI-Systeme außerhalb ihres Wissensgebiets operieren. Die Integration von RAG mit Monitoring-Plattformen ermöglicht die Erkennung von Zitations-Drift, also dem allmählichen Entfernen von autoritativen zu weniger vertrauenswürdigen Quellen, und unterstützt die Durchsetzung von Content-Richtlinien zu Quellenqualität und -vielfalt. Da KI-Systeme zunehmend in kritische Workflows integriert werden, schafft die Verbindung von RAG-Pipelines mit umfassender Überwachung Verantwortungsmechanismen, die Nutzer, Organisationen und das gesamte Informationsökosystem vor KI-generierter Fehlinformation schützen.
Häufig gestellte Fragen
Was ist der Unterschied zwischen RAG und Fine-Tuning?
RAG und Fine-Tuning sind komplementäre Ansätze zur Verbesserung der LLM-Leistung. RAG ruft externe Dokumente zur Abfragezeit ab, ohne das Modell zu verändern, was Echtzeit-Datenzugriff und einfache Aktualisierungen ermöglicht. Fine-Tuning trainiert das Modell mit domänenspezifischen Daten nach, was tiefere Anpassung ermöglicht, aber erhebliche Rechenressourcen und manuelle Aktualisierungen bei Informationsänderungen erfordert. Viele Organisationen nutzen beide Techniken gemeinsam für optimale Ergebnisse.
Wie reduziert RAG Halluzinationen in KI-Antworten?
RAG reduziert Halluzinationen, indem LLM-Antworten auf abgerufenen, faktischen Dokumenten beruhen. Anstatt sich ausschließlich auf Trainingsdaten zu verlassen, ruft das System relevante Quellen vor der Generierung ab und liefert dem Modell konkrete Belege. Dieser Ansatz stellt sicher, dass Antworten auf tatsächlichen Informationen basieren statt auf erlernten Mustern des Modells, was die faktische Genauigkeit deutlich verbessert und falsche oder irreführende Aussagen reduziert.
Was sind Vektoreinbettungen und warum sind sie in RAG wichtig?
Vektoreinbettungen sind numerische Darstellungen von Text, die semantische Bedeutung in einem mehrdimensionalen Raum erfassen. Sie ermöglichen es RAG-Systemen, semantische Suchen durchzuführen und Dokumente mit ähnlicher Bedeutung zu finden, selbst wenn unterschiedliche Wörter verwendet werden. Einbettungen sind entscheidend, da sie RAG erlauben, über reine Stichwortsuche hinauszugehen und konzeptionelle Zusammenhänge zu verstehen, was die Relevanz des Abrufs verbessert und genauere Antwortgenerierung ermöglicht.
Können RAG-Pipelines mit Echtzeitdaten arbeiten?
Ja, RAG-Pipelines können Echtzeitdaten durch kontinuierliche Aufnahme- und Indexierungsprozesse integrieren. Organisationen können automatisierte Pipelines einrichten, die die Vektordatenbank regelmäßig mit neuen Dokumenten aktualisieren und so sicherstellen, dass die Wissensbasis aktuell bleibt. Diese Fähigkeit macht RAG ideal für Anwendungen, die aktuelle Informationen erfordern, wie Nachrichtenanalysen, Preisintelligenz und Marktüberwachung, ohne das zugrundeliegende LLM neu trainieren zu müssen.
Was ist der Unterschied zwischen semantischer Suche und RAG?
Semantische Suche ist eine Abruftechnik, die Dokumente auf Basis semantischer Ähnlichkeit mittels Vektoreinbettungen findet. RAG ist eine vollständige Pipeline, die semantische Suche mit LLM-Generierung kombiniert, um Antworten zu liefern, die auf abgerufenen Dokumenten basieren. Während sich die semantische Suche auf das Auffinden relevanter Informationen konzentriert, fügt RAG die Generierungskomponente hinzu, die abgerufene Inhalte zu kohärenten Antworten mit Zitaten zusammenfasst.
Wie entscheiden RAG-Systeme, welche Quellen zitiert werden?
RAG-Systeme nutzen mehrere Mechanismen zur Auswahl von Quellen für Zitate. Sie verwenden Abrufalgorithmen zur Suche relevanter Dokumente, Re-Ranking-Modelle zur Priorisierung der relevantesten Ergebnisse und Verifizierungsprozesse, um sicherzustellen, dass Zitate die getroffenen Aussagen tatsächlich stützen. Einige Systeme nutzen 'Zitieren beim Schreiben', wobei Aussagen nur gemacht werden, wenn sie durch abgerufene Quellen gestützt werden, während andere Zitate nach der Generierung überprüfen und unbelegte Aussagen entfernen.
Was sind die wichtigsten Herausforderungen beim Aufbau von RAG-Pipelines?
Wichtige Herausforderungen sind die Aufrechterhaltung der Aktualität und Qualität der Wissensbasis, die Optimierung der Abrufgenauigkeit über verschiedene Inhaltstypen hinweg, das Management der Rechenkosten im großen Maßstab, der Umgang mit domänenspezifischer Terminologie, die Einbettungsmodelle möglicherweise nicht gut verstehen, sowie die Bewertung der Systemleistung mit umfassenden Metriken. Organisationen müssen außerdem Begrenzungen des Kontextfensters in LLMs berücksichtigen und sicherstellen, dass abgerufene Dokumente mit dem aktuellen Informationsstand übereinstimmen.
Wie überwacht AmICited RAG-Zitate in KI-Systemen?
AmICited verfolgt, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews Inhalte durch RAG-Pipelines abrufen und zitieren. Die Plattform überwacht, welche Quellen für Zitate ausgewählt werden, wie oft Ihre Marke in KI-Antworten erscheint und ob die Zitate korrekt sind. Diese Transparenz hilft Organisationen, ihre Präsenz in KI-vermittelten Suchen zu verstehen und eine ordnungsgemäße Zuordnung ihrer Inhalte sicherzustellen.
Überwachen Sie Ihre Marke in KI-Antworten
Verfolgen Sie, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews auf Ihre Inhalte verweisen. Erhalten Sie Einblicke in RAG-Zitate und die Überwachung von KI-Antworten.
Was ist RAG in der KI-Suche: Vollständiger Leitfaden zur Retrieval-Augmented Generation
Erfahren Sie, was RAG (Retrieval-Augmented Generation) in der KI-Suche ist. Entdecken Sie, wie RAG die Genauigkeit verbessert, Halluzinationen reduziert und Cha...
Wie Retrieval-Augmented Generation funktioniert: Architektur und Prozess
Erfahren Sie, wie RAG LLMs mit externen Datenquellen kombiniert, um präzise KI-Antworten zu generieren. Verstehen Sie den fünfstufigen Prozess, die Komponenten ...
Erfahren Sie, was Retrieval-Augmented Generation (RAG) ist, wie es funktioniert und warum es für präzise KI-Antworten unerlässlich ist. Entdecken Sie die RAG-Ar...
10 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.