
Suchmaschinenspam
Erfahren Sie, was Suchmaschinenspam ist, einschließlich Black-Hat-SEO-Taktiken wie Keyword-Stuffing, Cloaking und Linkfarmen. Verstehen Sie, wie Google Spam erk...
9 Min. Lesezeit

Eine Scraper-Seite ist eine Website, die automatisch Inhalte von anderen Quellen ohne Erlaubnis kopiert und wiederveröffentlicht, oft mit minimalen Änderungen. Diese Seiten verwenden automatisierte Bots, um Daten, Texte, Bilder und andere Inhalte von seriösen Websites zu sammeln und ihre eigenen Seiten zu füllen, typischerweise zu betrügerischen Zwecken, für Plagiate oder um Werbeeinnahmen zu erzielen.
Eine Scraper-Seite ist eine Website, die automatisch Inhalte von anderen Quellen ohne Erlaubnis kopiert und wiederveröffentlicht, oft mit minimalen Änderungen. Diese Seiten verwenden automatisierte Bots, um Daten, Texte, Bilder und andere Inhalte von seriösen Websites zu sammeln und ihre eigenen Seiten zu füllen, typischerweise zu betrügerischen Zwecken, für Plagiate oder um Werbeeinnahmen zu erzielen.
Eine Scraper-Seite ist eine Website, die automatisch Inhalte von anderen Quellen ohne Erlaubnis kopiert und wiederveröffentlicht, oft mit minimalen Änderungen oder Umformulierungen. Diese Seiten nutzen automatisierte Bots, um Daten, Texte, Bilder, Produktbeschreibungen und andere Inhalte von seriösen Websites zu sammeln und ihre eigenen Seiten zu füllen. Diese Praxis ist technisch gesehen nach dem Urheberrecht illegal und verstößt gegen die Nutzungsbedingungen der meisten Websites. Content Scraping unterscheidet sich grundlegend von legitimen Web-Scraping-Aktivitäten, da es sich um das unbefugte Kopieren veröffentlichter Inhalte zu böswilligen Zwecken handelt, darunter Betrug, Plagiate, Generierung von Werbeeinnahmen und Diebstahl geistigen Eigentums. Die automatisierte Natur des Scraping ermöglicht es den Tätern, Tausende von Seiten in wenigen Minuten zu kopieren, was massive Probleme mit doppelten Inhalten im gesamten Internet verursacht.
Content Scraping existiert seit den frühen Tagen des Internets, aber das Problem hat sich mit dem Fortschritt der Automatisierungstechnologie und künstlicher Intelligenz dramatisch verschärft. In den frühen 2000er Jahren waren Scraper relativ einfach und leicht zu erkennen. Moderne Scraper-Bots sind jedoch zunehmend raffiniert und nutzen Techniken wie Paraphrasierungsalgorithmen, rotierende IP-Adressen und Browserautomatisierung, um die Erkennung zu umgehen. Der Aufstieg der KI-gestützten Inhaltserstellung hat das Problem verschärft, da Scraper jetzt maschinelles Lernen einsetzen, um gestohlene Inhalte so umzuschreiben, dass sie schwieriger als Duplikate zu erkennen sind. Laut Branchenberichten machen Scraper-Seiten einen erheblichen Teil des bösartigen Bot-Traffics aus, wobei einige Schätzungen davon ausgehen, dass automatisierte Bots über 40 % des gesamten Internet-Traffics ausmachen. Das Aufkommen von KI-Suchmaschinen wie ChatGPT, Perplexity und Google AI Overviews hat neue Herausforderungen geschaffen, da diese Systeme möglicherweise versehentlich Scraper-Seiten anstelle der ursprünglichen Content-Ersteller zitieren und so das Problem weiter verstärken.
Scraper-Bots funktionieren über einen mehrstufigen automatisierten Prozess, der nur minimale menschliche Intervention erfordert. Zuerst durchsucht der Bot Ziel-Websites, indem er Links folgt und Seiten aufruft, den HTML-Code und alle zugehörigen Inhalte herunterlädt. Anschließend analysiert der Bot das HTML, um relevante Daten wie Artikeltitel, Bilder, Metadaten und Produktinformationen zu extrahieren. Diese extrahierten Inhalte werden in einer Datenbank gespeichert, wo sie weiterverarbeitet werden können, beispielsweise durch Paraphrasierungstools oder KI-gestützte Umformulierung, um Varianten zu erzeugen, die sich vom Original unterscheiden. Schließlich werden die gescrapten Inhalte auf der Scraper-Seite wiederveröffentlicht, oft mit minimaler Namensnennung oder mit falschen Autorenangaben. Einige fortschrittliche Scraper verwenden rotierende Proxys und User-Agent-Spoofing, um ihre Anfragen als legitimen menschlichen Traffic zu tarnen und so schwerer erkennbar und blockierbar zu machen. Der gesamte Prozess kann vollständig automatisiert ablaufen, sodass eine einzelne Scraper-Operation täglich Tausende von Seiten aus mehreren Websites kopieren kann.
| Aspekt | Scraper-Seite | Original-Content-Seite | Legitimer Datenaggregator |
|---|---|---|---|
| Herkunft der Inhalte | Ohne Erlaubnis kopiert | Original erstellt | Kuratiert mit Namensnennung und Links |
| Rechtlicher Status | Illegal (Urheberrechtsverletzung) | Urheberrechtlich geschützt | Legal (mit entsprechender Lizenzierung) |
| Namensnennung | Minimal oder falsch | Ursprünglicher Autor genannt | Quellen genannt und verlinkt |
| Zweck | Betrug, Plagiate, Werbeeinnahmen | Mehrwert für die Zielgruppe | Informationen aggregieren und organisieren |
| SEO-Auswirkung | Negativ (doppelter Inhalt) | Positiv (Originalinhalt) | Neutral bis positiv (mit korrekter Kanonisierung) |
| Nutzererlebnis | Schlecht (minderwertiger Inhalt) | Hoch (einzigartiger, wertvoller Inhalt) | Gut (organisierter, quellierter Inhalt) |
| Nutzungsbedingungen | Verstößt gegen ToS | Entspricht eigenen ToS | Respektiert ToS und robots.txt von Websites |
| Erkennungsmethoden | IP-Tracking, Bot-Signaturen | N/A | Transparente Crawling-Muster |
Scraper-Seiten operieren nach mehreren unterschiedlichen Geschäftsmodellen, die alle darauf ausgelegt sind, mit gestohlenen Inhalten Einnahmen zu erzielen. Das gängigste Modell ist die werbebasierte Monetarisierung, bei der Scraper ihre Seiten mit Werbung von Netzwerken wie Google AdSense oder anderen Anbietern füllen. Durch das Wiederveröffentlichen beliebter Inhalte ziehen Scraper organischen Such-Traffic an und generieren Werbeeinblendungen und Klicks, ohne eigenen Mehrwert zu schaffen. Ein weiteres häufiges Modell ist der E-Commerce-Betrug, bei dem Scraper gefälschte Online-Shops erstellen, die seriöse Händler nachahmen und Produktbeschreibungen, Bilder und Preise kopieren. Nichtsahnende Kunden kaufen auf diesen betrügerischen Seiten ein, erhalten entweder gefälschte Produkte oder ihre Zahlungsinformationen werden gestohlen. E-Mail-Harvesting ist ein weiteres bedeutendes Geschäftsmodell von Scraper-Seiten, bei dem Kontaktinformationen von Websites extrahiert und an Spammer verkauft oder für gezielte Phishing-Kampagnen verwendet werden. Einige Scraper betreiben auch Affiliate-Marketing-Betrug, indem sie Produktbewertungen und Inhalte kopieren und eigene Affiliate-Links einfügen, um Provisionen zu verdienen. Die niedrigen Betriebskosten des Scraping—es werden nur Serverplatz und automatisierte Software benötigt—machen diese Geschäftsmodelle trotz ihrer Illegalität sehr profitabel.
Die Folgen von Content Scraping für die Urheber sind schwerwiegend und vielschichtig. Wenn Scraper Ihre Inhalte auf ihren Domains wiederveröffentlichen, entsteht doppelter Inhalt, der Suchmaschinen verwirrt, welche Version das Original ist. Der Google-Algorithmus kann Schwierigkeiten haben, die maßgebliche Quelle zu identifizieren, was dazu führen kann, dass sowohl die Original- als auch die Scraper-Versionen in den Suchergebnissen niedriger ranken. Dies wirkt sich direkt auf den organischen Traffic aus, da Ihre sorgfältig optimierten Inhalte an Sichtbarkeit verlieren und Scraper-Seiten profitieren, ohne zum Inhalt beigetragen zu haben. Über Suchrankings hinaus verfälschen Scraper Ihre Website-Analysen durch gefälschten Bot-Traffic, was die Interpretation des echten Nutzerverhaltens und Engagements erschwert. Auch Ihre Serverressourcen werden durch Anfragen von Scraper-Bots beansprucht, was die Bandbreitenkosten erhöht und die Website für echte Besucher verlangsamen kann. Der negative SEO-Effekt erstreckt sich auf Ihre Domain-Autorität und Ihr Backlink-Profil, da Scraper möglicherweise minderwertige Links zu Ihrer Seite erstellen oder Ihre Inhalte in Spam-Kontexten verwenden. Wenn Scraper in den Suchergebnissen besser ranken als Ihre Originalinhalte, verlieren Sie außerdem die Möglichkeit, sich als Thought Leader und Autorität in Ihrer Branche zu etablieren, was Ihrem Markenruf und Ihrer Glaubwürdigkeit schadet.
Die Identifizierung von Scraper-Seiten erfordert eine Kombination aus manuellen und automatisierten Ansätzen. Google Alerts ist eines der effektivsten kostenlosen Tools, mit dem Sie Ihre Artikeltitel, einzigartige Phrasen und Ihren Markennamen auf unbefugte Wiederveröffentlichung überwachen können. Wenn Sie über Google Alerts benachrichtigt werden, können Sie prüfen, ob es sich um eine legitime Zitation oder eine Scraper-Seite handelt. Pingback-Überwachung ist besonders für WordPress-Seiten nützlich, da Pingbacks generiert werden, wenn eine andere Website auf Ihre Inhalte verlinkt. Wenn Sie Pingbacks von unbekannten oder verdächtigen Domains erhalten, könnte es sich um Scraper-Seiten handeln, die Ihre internen Links kopiert haben. SEO-Tools wie Ahrefs, SEM Rush und Grammarly bieten Funktionen zur Erkennung doppelter Inhalte, die das Netz nach Seiten durchsuchen, die mit Ihren Inhalten übereinstimmen. Diese Tools können sowohl exakte Duplikate als auch umformulierte Versionen Ihrer Artikel identifizieren. Server-Log-Analysen liefern technische Einblicke in Bot-Traffic-Muster und können verdächtige IP-Adressen, ungewöhnliche Anfrageraten und Bot-User-Agent-Strings aufdecken. Eine umgekehrte Bildersuche mit Google Images oder TinEye kann helfen, nachzuvollziehen, wo Ihre Bilder ohne Erlaubnis wiederveröffentlicht wurden. Die regelmäßige Überwachung Ihrer Google Search Console kann Indexierungsanomalien und Probleme mit doppelten Inhalten aufdecken, die auf Scraping-Aktivitäten hindeuten.
Content Scraping verstößt gegen mehrere Ebenen des rechtlichen Schutzes und ist eine der am einfachsten verfolgbaren Formen von Online-Betrug. Das Urheberrecht schützt automatisch alle Originalinhalte, egal ob online oder in gedruckter Form veröffentlicht, und gibt den Urhebern das ausschließliche Recht zur Vervielfältigung, Verbreitung und Darstellung ihrer Werke. Das Scrapen von Inhalten ohne Erlaubnis ist eine direkte Urheberrechtsverletzung und setzt Scraper einer zivilrechtlichen Haftung aus, einschließlich Schadensersatz und Unterlassungsansprüchen. Der Digital Millennium Copyright Act (DMCA) bietet zusätzlichen Schutz, indem er das Umgehen technischer Maßnahmen, die den Zugang zu urheberrechtlich geschützten Werken kontrollieren, verbietet. Wenn Sie Zugangskontrollen oder Anti-Scraping-Maßnahmen implementieren, macht der DMCA es illegal, diese zu umgehen. Der Computer Fraud and Abuse Act (CFAA) kann ebenfalls auf Scraping angewendet werden, insbesondere wenn Bots Systeme ohne Autorisierung oder über die erlaubte Nutzung hinaus betreten. Die Nutzungsbedingungen von Websites verbieten Scraping ausdrücklich, und ein Verstoß dagegen kann rechtliche Schritte wegen Vertragsbruchs nach sich ziehen. Viele Content-Ersteller haben erfolgreich rechtliche Schritte gegen Scraper eingeleitet und gerichtliche Anordnungen zur Entfernung von Inhalten und zur Einstellung von Scraping-Aktivitäten erwirkt. In einigen Rechtsordnungen wird Scraping auch als Form des unlauteren Wettbewerbs anerkannt, wodurch Unternehmen Schadenersatz für entgangene Einnahmen und Marktschäden geltend machen können.
Das Aufkommen von KI-Suchmaschinen und großen Sprachmodellen (LLMs) hat dem Scraper-Problem eine neue Dimension verliehen. Wenn KI-Systeme wie ChatGPT, Perplexity, Google AI Overviews und Claude das Internet nach Trainingsdaten durchsuchen oder Antworten generieren, können sie sowohl auf Scraper-Seiten als auch auf Originalinhalte stoßen. Wenn die Scraper-Seite häufiger erscheint oder eine bessere technische SEO aufweist, kann das KI-System den Scraper statt der Originalquelle zitieren. Das ist besonders problematisch, weil KI-Zitationen maßgeblich zur Marken-Sichtbarkeit und Autorität beitragen. Wenn eine Scraper-Seite anstelle Ihrer Originalinhalte in einer KI-Antwort genannt wird, verlieren Sie die Chance, Ihre Marke als maßgebliche Quelle in KI-gesteuerten Suchergebnissen zu etablieren. Darüber hinaus können Scraper Ungenauigkeiten oder veraltete Informationen in KI-Trainingsdaten einbringen, was dazu führen kann, dass KI-Systeme falsche oder irreführende Antworten generieren. Das Problem wird verstärkt, weil viele KI-Systeme keine transparente Quellennennung bieten und es für Nutzer schwierig ist zu erkennen, ob sie Original- oder gescrapten Inhalt lesen. Monitoring-Tools wie AmICited helfen Content-Erstellern dabei, nachzuvollziehen, wo ihre Marke und ihre Inhalte auf KI-Plattformen erscheinen und zu erkennen, wann Scraper um Sichtbarkeit in KI-Antworten konkurrieren.
Der Schutz Ihrer Inhalte vor Scraping erfordert einen mehrschichtigen technischen und organisatorischen Ansatz. Bot-Erkennungs- und Blockierungstools wie Bot Zapping von ClickCease können bösartige Bots identifizieren und blockieren, bevor sie auf Ihre Inhalte zugreifen und sie auf Fehlerseiten umleiten. Robots.txt-Konfiguration ermöglicht es Ihnen, den Bot-Zugriff auf bestimmte Verzeichnisse oder Seiten einzuschränken, auch wenn hartnäckige Scraper diese Anweisungen ignorieren können. Noindex-Tags können auf sensible Seiten oder automatisch generierte Inhalte (wie WordPress-Tag- und Kategorieseiten) angewendet werden, um deren Indexierung und Scraping zu verhindern. Content Gating erfordert, dass Nutzer Formulare ausfüllen oder sich anmelden, um auf Premium-Inhalte zuzugreifen, was es Bots erschwert, Informationen in großem Umfang zu sammeln. Rate Limiting auf Ihrem Server begrenzt die Anzahl der Anfragen von einer einzelnen IP-Adresse in einem bestimmten Zeitraum, verlangsamt Scraper-Bots und macht deren Betrieb ineffizienter. CAPTCHA-Challenges können sicherstellen, dass Anfragen von Menschen und nicht von Bots kommen, auch wenn fortschrittliche Bots diese manchmal umgehen können. Serverseitige Überwachung der Anfrage-Muster hilft, verdächtige Aktivitäten zu erkennen, sodass Sie problematische IP-Adressen proaktiv blockieren können. Regelmäßige Backups Ihrer Inhalte stellen sicher, dass Sie Nachweise über das ursprüngliche Erstellungsdatum haben, was im Fall rechtlicher Schritte gegen Scraper von Vorteil ist.
Das Scraper-Umfeld entwickelt sich mit dem technischen Fortschritt und neuen Möglichkeiten ständig weiter. KI-gestützte Paraphrasierung wird immer ausgefeilter, wodurch gescrapte Inhalte durch herkömmliche Plagiatserkennung schwerer als Duplikate zu identifizieren sind. Scraper investieren in fortschrittlichere Proxy-Rotation und Browserautomatisierung, um Bot-Erkennungssysteme zu umgehen. Der Aufstieg von KI-Trainingsdaten-Scraping ist ein neues Feld, in dem Scraper gezielt Inhalte für das Training von Machine-Learning-Modellen sammeln, oft ohne jegliche Vergütung für die Urheber. Einige Scraper nutzen mittlerweile Headless Browser und JavaScript-Rendering, um dynamische Inhalte zu erreichen, die früher für klassische Scraper unerreichbar waren. Die Integration von Scraping mit Affiliate-Marketing-Netzwerken und Werbebetrugs-Schemata führt zu komplexeren und schwerer erkennbaren Scraper-Operationen. Es gibt aber auch positive Entwicklungen: KI-Erkennungssysteme werden immer besser darin, gescrapte Inhalte zu identifizieren, und Suchmaschinen bestrafen Scraper-Seiten zunehmend in ihren Algorithmen. Das Google-Core-Update vom November 2024 zielte speziell auf Scraper-Seiten ab und führte zu erheblichen Sichtbarkeitsverlusten für viele Scraper-Domains. Content-Ersteller setzen außerdem Watermarking-Technologien und blockchainbasierte Verifizierung ein, um die ursprüngliche Erstellung und das Eigentum zu belegen. Mit der Weiterentwicklung von KI-Suchmaschinen werden bessere Mechanismen zur Quellennennung und Transparenz implementiert, damit Urheber angemessen gewürdigt und sichtbar werden.
Für Content-Ersteller und Markenverantwortliche geht die Herausforderung durch Scraper-Seiten über klassische Suchmaschinen hinaus und betrifft zunehmend auch KI-gestützte Such- und Antwortsysteme. AmICited bietet spezialisierte Überwachung, um zu verfolgen, wo Ihre Marke, Ihre Inhalte und Ihre Domain auf KI-Plattformen wie Perplexity, ChatGPT, Google AI Overviews und Claude erscheinen. Durch die Überwachung Ihrer Sichtbarkeit in der KI können Sie erkennen, wann Scraper-Seiten um Zitationen in KI-Antworten konkurrieren, wann Ihre Originalinhalte korrekt genannt werden und wann unbefugte Kopien an Sichtbarkeit gewinnen. Dieses Wissen ermöglicht es Ihnen, proaktiv Maßnahmen zum Schutz Ihres geistigen Eigentums zu ergreifen und Ihre Markenautorität in KI-gesteuerten Suchergebnissen zu verteidigen. Die Unterscheidung zwischen legitimer Content-Aggregation und böswilligem Scraping ist im KI-Zeitalter entscheidend, da der Wert von Markenpräsenz und Autorität nie höher war.
Ja, Content Scraping ist technisch gesehen in den meisten Ländern illegal. Es verstößt gegen Urheberrechtsgesetze, die digitale Inhalte genauso schützen wie physische Veröffentlichungen. Darüber hinaus verstößt Scraping oft gegen die Nutzungsbedingungen von Websites und kann rechtliche Schritte nach dem Digital Millennium Copyright Act (DMCA) und dem Computer Fraud and Abuse Act (CFAA) auslösen. Website-Betreiber können zivil- und strafrechtliche Haftung gegen Scraper geltend machen.
Scraper-Seiten wirken sich auf verschiedene Weise negativ auf SEO aus. Wenn doppelte Inhalte von Scraper-Seiten höher ranken als das Original, verringert dies die Sichtbarkeit und den organischen Traffic der Originalseite. Googles Algorithmus hat Schwierigkeiten zu erkennen, welche Version das Original ist, was dazu führen kann, dass alle Versionen niedriger ranken. Außerdem verschwenden Scraper Ihr Crawl-Budget und verfälschen Ihre Analysen, wodurch es schwierig wird, echtes Nutzerverhalten und Leistungskennzahlen zu verstehen.
Scraper-Seiten verfolgen mehrere böswillige Zwecke: das Erstellen gefälschter E-Commerce-Shops zum Betrug, das Hosten von nachgeahmten Websites, die legitime Marken imitieren, das Generieren von Werbeeinnahmen durch betrügerischen Traffic, das Plagiieren von Inhalten zur Füllung von Seiten ohne Aufwand und das Sammeln von E-Mail-Listen und Kontaktinformationen für Spam-Kampagnen. Einige Scraper zielen auch auf Preisinformationen, Produktdetails und Social-Media-Inhalte für Wettbewerbsanalysen oder den Weiterverkauf ab.
Sie können gescrapten Inhalt mit verschiedenen Methoden erkennen: Richten Sie Google Alerts für Ihre Artikeltitel oder einzigartige Phrasen ein, suchen Sie Ihre Titel in Google, um zu sehen, ob Duplikate erscheinen, prüfen Sie auf Pingbacks bei internen Links (besonders bei WordPress), nutzen Sie SEO-Tools wie Ahrefs oder SEM Rush, um doppelte Inhalte zu finden, und überwachen Sie die Traffic-Muster Ihrer Website auf ungewöhnliche Bot-Aktivitäten. Regelmäßige Überwachung hilft, Scraper schnell zu identifizieren.
Web Scraping ist ein weiter gefasster technischer Begriff für das Extrahieren von Daten aus Websites, was legitim sein kann, wenn es mit Erlaubnis zu Forschungs- oder Analysezwecken geschieht. Content Scraping bezieht sich speziell auf das unbefugte Kopieren veröffentlichter Inhalte wie Artikel, Produktbeschreibungen und Bilder zur Wiederveröffentlichung. Während Web Scraping legal sein kann, ist Content Scraping grundsätzlich böswillig und illegal, da es gegen Urheberrecht und Nutzungsbedingungen verstößt.
Scraper-Bots nutzen automatisierte Software, um Websites zu durchsuchen, HTML-Inhalte herunterzuladen, Texte und Bilder zu extrahieren und sie in Datenbanken zu speichern. Diese Bots simulieren menschliches Surfverhalten, um grundlegende Erkennungsmethoden zu umgehen. Sie können sowohl öffentlich sichtbare Inhalte als auch manchmal versteckte Datenbanken erreichen, wenn die Sicherheit schwach ist. Die gesammelten Daten werden dann verarbeitet, manchmal mit KI-Tools umformuliert, und mit minimalen Änderungen auf Scraper-Seiten wiederveröffentlicht, um die exakte Duplikaterkennung zu vermeiden.
Effektive Präventionsstrategien umfassen den Einsatz von Bot-Erkennungs- und Blockierungstools, die Verwendung von robots.txt zur Einschränkung des Bot-Zugriffs, das Hinzufügen von noindex-Tags zu sensiblen Seiten, das Sperren von Premium-Inhalten hinter Login-Formularen, die regelmäßige Überwachung Ihrer Website mit Google Alerts und SEO-Tools, den Einsatz von CAPTCHA-Challenges, die Implementierung von Rate Limiting auf Ihrem Server und die Überwachung Ihrer Serverprotokolle auf verdächtige IP-Adressen und Traffic-Muster. Ein mehrschichtiger Ansatz ist am effektivsten.
Scraper-Seiten stellen eine erhebliche Herausforderung für KI-Suchmaschinen wie ChatGPT, Perplexity und Google AI Overviews dar. Wenn KI-Systeme das Web nach Trainingsdaten durchsuchen oder Antworten generieren, können sie auf gescrapte Inhalte stoßen und Scraper-Seiten statt der Originalquellen zitieren. Dies verringert die Sichtbarkeit legitimer Content-Ersteller in KI-Antworten und kann dazu führen, dass KI-Systeme Fehlinformationen verbreiten. Überwachungstools wie AmICited helfen dabei, nachzuverfolgen, wo Ihre Marke und Ihre Inhalte auf KI-Plattformen erscheinen.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Erfahren Sie, was Suchmaschinenspam ist, einschließlich Black-Hat-SEO-Taktiken wie Keyword-Stuffing, Cloaking und Linkfarmen. Verstehen Sie, wie Google Spam erk...
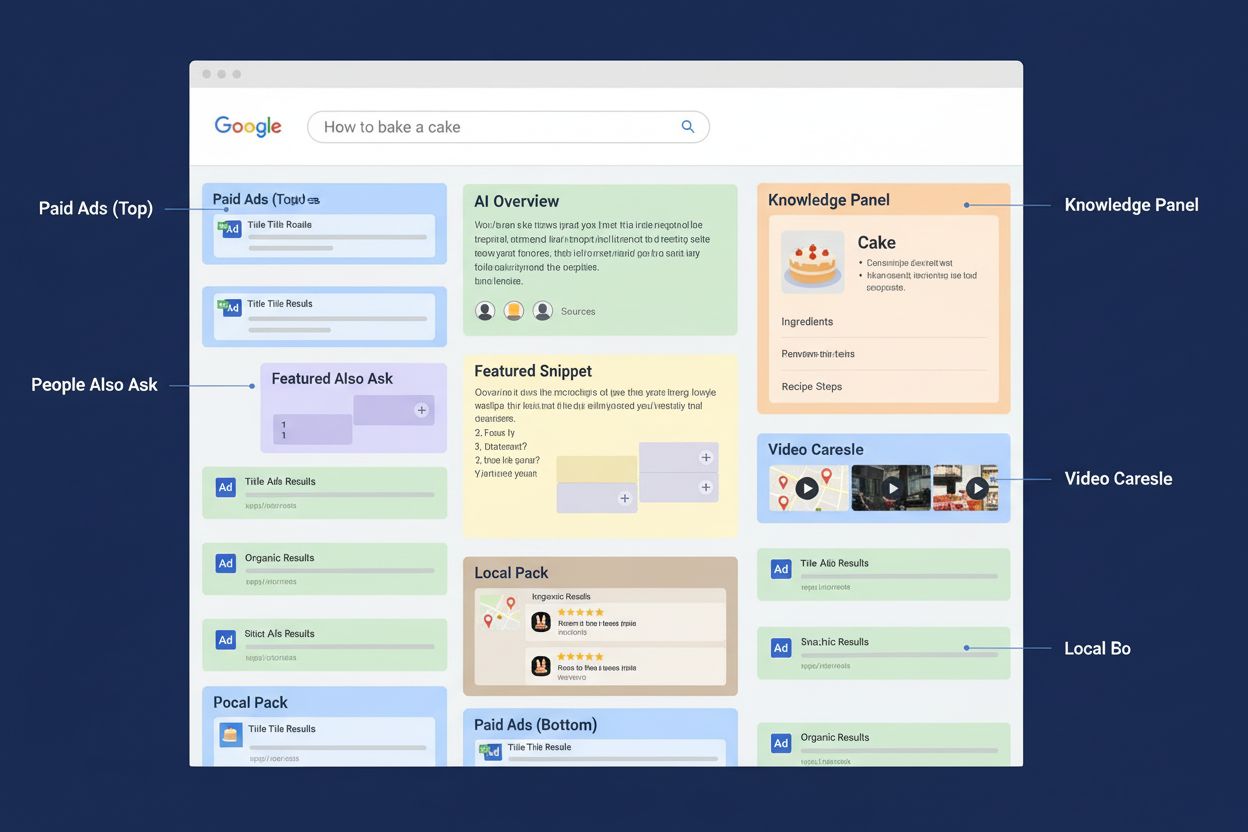
Erfahren Sie, was eine SERP ist, wie sie funktioniert und warum sie für SEO, KI-Monitoring und Markenpräsenz wichtig ist. Verstehen Sie SERP-Features und deren ...

Entdecken Sie die entscheidenden Unterschiede zwischen KI-Trainingscrawlern und Suchcrawlern. Erfahren Sie, wie sie die Sichtbarkeit Ihrer Inhalte, Optimierungs...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.