
Cómo el RAG Cambia las Citaciones de la IA
Descubre cómo la Generación Aumentada por Recuperación transforma las citaciones de la IA, permitiendo una atribución precisa de fuentes y respuestas fundamenta...
9 min de lectura

Descubre cómo el grounding en LLMs y la búsqueda web permiten a los sistemas de IA acceder a información en tiempo real, reducir alucinaciones y proporcionar citas precisas. Aprende sobre RAG, estrategias de implementación y mejores prácticas empresariales.
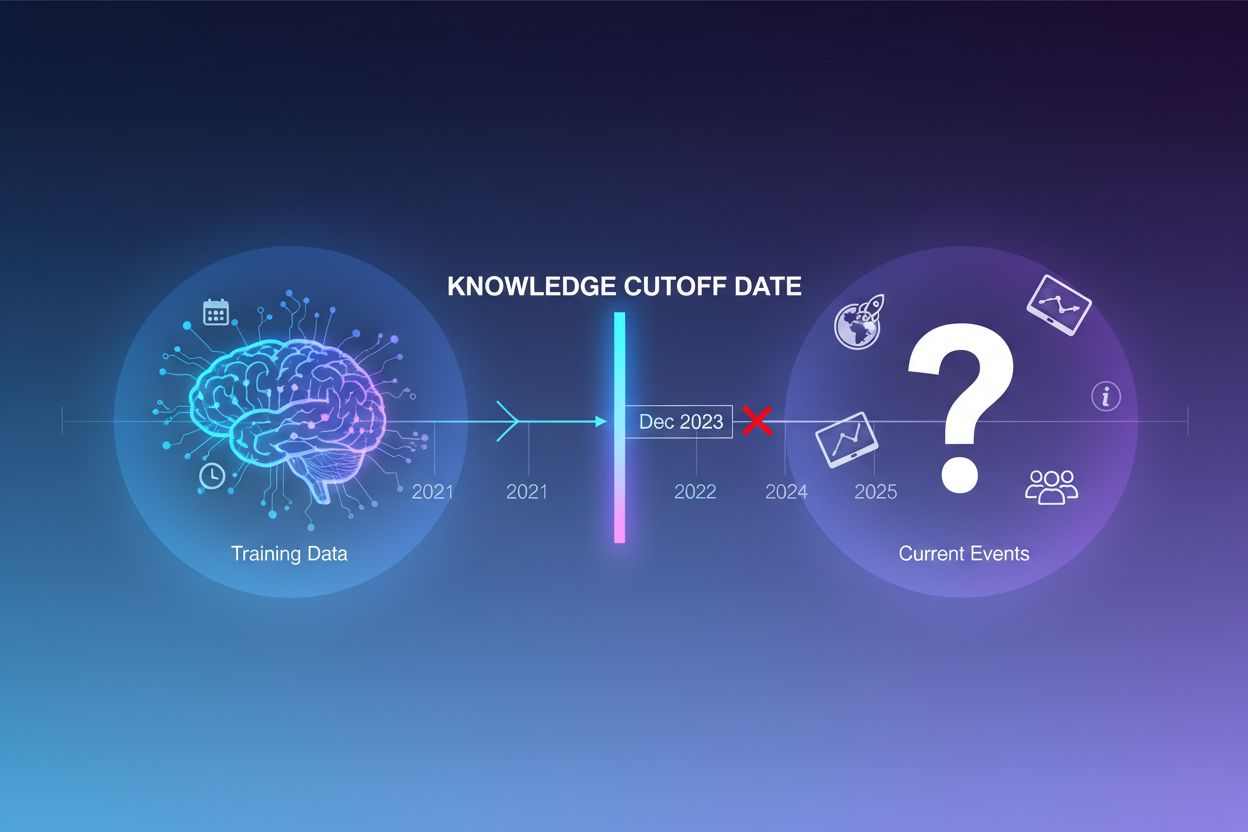
Los grandes modelos de lenguaje se entrenan con enormes cantidades de datos textuales, pero este proceso tiene una limitación crítica: solo captura información disponible hasta un punto específico en el tiempo, conocido como la fecha de corte de conocimiento. Por ejemplo, si un LLM fue entrenado con datos hasta diciembre de 2023, no tiene conocimiento de eventos, descubrimientos o desarrollos ocurridos después de esa fecha. Cuando los usuarios hacen preguntas sobre eventos actuales, lanzamientos recientes de productos o noticias de última hora, el modelo no puede acceder a esta información desde sus datos de entrenamiento. En lugar de admitir incertidumbre, los LLMs suelen generar respuestas que suenan plausibles pero son incorrectas—un fenómeno conocido como alucinación. Esta tendencia se vuelve especialmente problemática en aplicaciones donde la precisión es crítica, como soporte al cliente, asesoría financiera o información médica, donde información desactualizada o inventada puede tener graves consecuencias.
El grounding es el proceso de aumentar el conocimiento preentrenado de un LLM con información externa y contextual en tiempo de inferencia. En lugar de depender solo de los patrones aprendidos durante el entrenamiento, el grounding conecta el modelo a fuentes de datos del mundo real—ya sean páginas web, documentos internos, bases de datos o APIs. Este concepto proviene de la psicología cognitiva, en particular la teoría de la cognición situada, que plantea que el conocimiento es más efectivo cuando está fundamentado en el contexto donde se aplicará. En términos prácticos, el grounding transforma el problema de “generar una respuesta desde la memoria” a “sintetizar una respuesta a partir de la información provista”. Una definición estricta desde la investigación reciente requiere que el LLM use todo el conocimiento esencial del contexto proporcionado y se ciña a su alcance sin alucinar información adicional.
| Aspecto | Respuesta No Fundamentada | Respuesta Fundamentada |
|---|---|---|
| Fuente de Información | Solo conocimiento preentrenado | Conocimiento preentrenado + datos externos |
| Precisión para Eventos Recientes | Baja (límite de conocimiento) | Alta (acceso a información actual) |
| Riesgo de Alucinación | Alto (el modelo adivina) | Bajo (restringido por el contexto dado) |
| Capacidad de Citar | Limitada o imposible | Trazabilidad total a las fuentes |
| Escalabilidad | Fija (tamaño del modelo) | Flexible (puede agregar nuevas fuentes) |
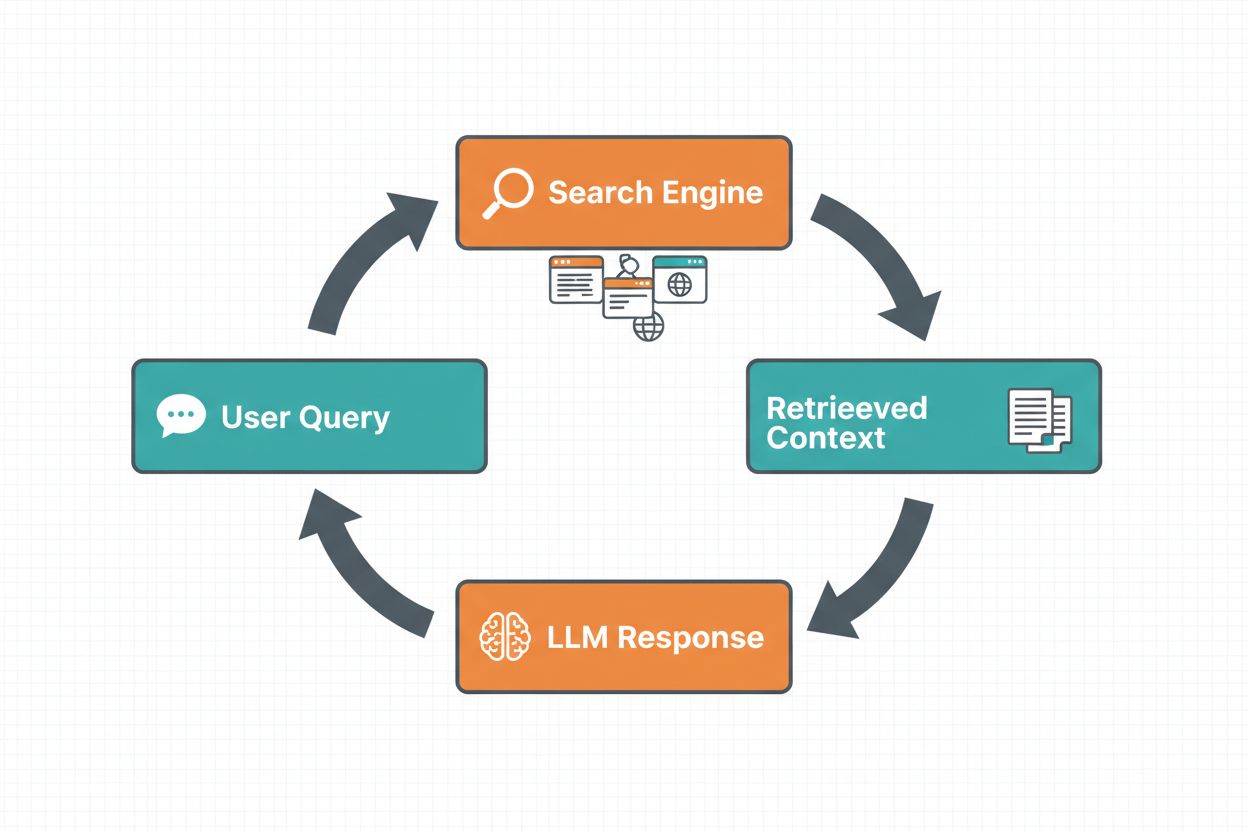
El grounding mediante búsqueda web permite a los LLMs acceder a información en tiempo real buscando automáticamente en la web e incorporando los resultados en el proceso de generación de respuestas. El flujo de trabajo sigue una secuencia estructurada: primero, el sistema analiza el prompt del usuario para determinar si una búsqueda web mejoraría la respuesta; segundo, genera una o varias consultas optimizadas para recuperar información relevante; tercero, ejecuta estas consultas en un motor de búsqueda (como Google Search o DuckDuckGo); cuarto, procesa los resultados de la búsqueda y extrae el contenido relevante; y finalmente, proporciona este contexto al LLM como parte del prompt, permitiendo que el modelo genere una respuesta fundamentada. El sistema también devuelve metadatos de grounding—información estructurada sobre qué consultas se ejecutaron, qué fuentes se recuperaron y cómo partes específicas de la respuesta están sustentadas por esas fuentes. Estos metadatos son esenciales para generar confianza y permitir a los usuarios verificar afirmaciones.
Flujo de Grounding con Búsqueda Web:
La Generación Aumentada por Recuperación (RAG) se ha posicionado como la técnica de grounding dominante, combinando décadas de investigación en recuperación de información con las capacidades modernas de los LLMs. RAG funciona primero recuperando documentos o fragmentos relevantes de una fuente de conocimiento externa (normalmente indexada en una base de datos vectorial), luego proporcionando estos elementos como contexto al LLM. El proceso de recuperación suele involucrar dos etapas: un recuperador utiliza algoritmos eficientes (como BM25 o búsqueda semántica con embeddings) para identificar documentos candidatos, y un ranker usa modelos neuronales más sofisticados para reordenar estos candidatos según relevancia. El contexto recuperado se incorpora luego al prompt, permitiendo que el LLM sintetice respuestas fundamentadas en información autorizada. RAG ofrece ventajas significativas sobre el fine-tuning: es más rentable (no requiere reentrenar el modelo), más escalable (simplemente añade nuevos documentos a la base de conocimiento), y más mantenible (actualiza la información sin reentrenar). Por ejemplo, un prompt de RAG podría verse así:
Utiliza los siguientes documentos para responder la pregunta.
[Pregunta]
¿Cuál es la capital de Canadá?
[Documento 1]
Ottawa es la ciudad capital de Canadá, ubicada en Ontario...
[Documento 2]
Canadá es un país en Norteamérica con diez provincias...
Uno de los beneficios más destacados del grounding con búsqueda web es la capacidad de acceder e incorporar información en tiempo real en las respuestas de los LLMs. Esto es especialmente valioso para aplicaciones que requieren datos actuales—análisis de noticias, investigación de mercado, información de eventos o disponibilidad de productos. Más allá del simple acceso a datos frescos, el grounding provee citas y atribución de fuentes, lo cual es crucial para generar confianza y permitir la verificación. Cuando un LLM genera una respuesta fundamentada, devuelve metadatos estructurados que vinculan afirmaciones específicas a sus documentos fuente, permitiendo citas en línea tipo “[1] fuente.com” directamente en el texto de la respuesta. Esta capacidad está directamente alineada con la misión de plataformas como AmICited.com, que monitorea cómo los sistemas de IA referencian y citan fuentes en diferentes plataformas. Poder rastrear qué fuentes consultó un sistema de IA y cómo atribuyó la información está cobrando cada vez más importancia para el monitoreo de marca, la atribución de contenidos y el despliegue responsable de la IA.
Las alucinaciones ocurren porque los LLMs están diseñados fundamentalmente para predecir el siguiente token basándose en los anteriores y en patrones aprendidos, sin comprender los límites de su conocimiento. Cuando enfrentan preguntas fuera de sus datos de entrenamiento, siguen generando texto plausible en vez de admitir incertidumbre. El grounding resuelve esto cambiando fundamentalmente la tarea del modelo: en vez de generar desde la memoria, ahora sintetiza a partir de la información proporcionada. Desde una perspectiva técnica, cuando se incluye contexto externo relevante en el prompt, se desplaza la distribución de probabilidad de tokens hacia respuestas sustentadas en ese contexto, haciendo menos probables las alucinaciones. La investigación demuestra que el grounding puede reducir las tasas de alucinación entre un 30 y 50% dependiendo de la tarea e implementación. Por ejemplo, al preguntar “¿Quién ganó la Euro 2024?” sin grounding, un modelo antiguo podría dar una respuesta incorrecta; con grounding usando resultados web, identifica correctamente a España como el ganador con detalles específicos del partido. Este mecanismo funciona porque la atención del modelo puede enfocarse ahora en el contexto proporcionado en vez de patrones potencialmente incompletos o conflictivos del entrenamiento.
Implementar grounding con búsqueda web requiere integrar varios componentes: una API de búsqueda (como Google Search, DuckDuckGo vía Serp API o Bing Search), lógica para decidir cuándo se necesita grounding y prompt engineering para incorporar eficazmente los resultados de búsqueda. Una implementación práctica suele comenzar evaluando si la consulta del usuario requiere información actual—esto puede hacerse preguntándole al propio LLM si el prompt necesita información más reciente que su límite de conocimiento. Si se necesita grounding, el sistema ejecuta una búsqueda web, procesa los resultados para extraer fragmentos relevantes y construye un prompt que incluye tanto la pregunta original como el contexto de búsqueda. Las consideraciones de coste son importantes: cada búsqueda web implica costes de API, así que implementar grounding dinámico (buscar solo cuando sea necesario) puede reducir significativamente los gastos. Por ejemplo, una consulta como “¿Por qué el cielo es azul?” probablemente no requiere búsqueda web, mientras que “¿Quién es el presidente actual?” sí la necesita. Implementaciones avanzadas usan modelos más pequeños y rápidos para tomar la decisión de grounding, reduciendo latencia y costes mientras reservan modelos grandes para la generación final de respuestas.
Aunque el grounding es potente, introduce varios desafíos que deben ser gestionados cuidadosamente. La relevancia de los datos es crítica—si la información recuperada no responde la pregunta del usuario, el grounding no ayudará e incluso puede introducir contexto irrelevante. La cantidad de datos presenta una paradoja: aunque más información parece beneficiosa, la investigación muestra que el rendimiento de los LLM a menudo disminuye con exceso de entrada, un fenómeno llamado sesgo de “perdido en el medio” donde los modelos tienen dificultades para encontrar y usar información colocada en medio de contextos largos. La eficiencia de tokens se vuelve un factor, ya que cada fragmento de contexto recuperado consume tokens, aumentando latencia y coste. El principio de “menos es más” aplica: recupera solo los k resultados más relevantes (típicamente 3-5), trabaja con fragmentos pequeños en vez de documentos completos y considera extraer frases clave de pasajes largos.
| Desafío | Impacto | Solución |
|---|---|---|
| Relevancia de los Datos | Contexto irrelevante confunde al modelo | Usar búsqueda semántica + rankers; probar calidad de recuperación |
| Sesgo Perdido en el Medio | El modelo omite información importante en el medio | Minimizar tamaño de entrada; colocar información crítica al inicio/final |
| Eficiencia de Tokens | Alta latencia y coste | Recuperar menos resultados; usar fragmentos más pequeños |
| Información Desactualizada | Contexto desactualizado en la base de conocimiento | Políticas de refresco; control de versiones |
| Latencia | Respuestas lentas por búsqueda + inferencia | Operaciones asíncronas; cachear consultas comunes |
Desplegar sistemas de grounding en entornos de producción requiere atención cuidadosa a la gobernanza, seguridad y operación. La garantía de calidad de los datos es fundamental—la información sobre la que se fundamenta debe ser precisa, actual y relevante para tus casos de uso. El control de acceso es crítico cuando se fundamenta sobre documentos propietarios o sensibles; debes asegurar que el LLM acceda solo a información adecuada para cada usuario según sus permisos. La gestión de actualización y desvío requiere establecer políticas sobre la frecuencia de actualización de las bases de conocimiento y cómo manejar información conflictiva entre fuentes. El registro de auditoría es esencial para cumplimiento y depuración—debes capturar qué documentos se recuperaron, cómo se rankearon y qué contexto se proporcionó al modelo. Otras consideraciones incluyen:
El campo del grounding en LLMs está evolucionando rápidamente más allá de la simple recuperación textual. Está surgiendo el grounding multimodal, donde los sistemas pueden fundamentar respuestas en imágenes, videos y datos estructurados junto al texto—especialmente importante en dominios como análisis legal, imágenes médicas y documentación técnica. Se está incorporando razonamiento automatizado sobre RAG, permitiendo que los agentes no solo recuperen información sino que sinteticen a través de múltiples fuentes, saquen conclusiones lógicas y expliquen su razonamiento. Se están integrando guardrails con grounding para asegurar que incluso con acceso a información externa los modelos mantengan restricciones de seguridad y cumplimiento de políticas. Los actualizaciones de modelo in situ representan otra frontera—en vez de depender totalmente de recuperación externa, investigadores exploran formas de actualizar los pesos del modelo directamente con nueva información, potencialmente reduciendo la necesidad de grandes bases de conocimiento externas. Estos avances sugieren que los sistemas de grounding del futuro serán más inteligentes, eficientes y capaces de manejar razonamiento complejo y de varios pasos, manteniendo la precisión factual y la trazabilidad.
El grounding complementa un LLM con información externa en tiempo de inferencia sin modificar el propio modelo, mientras que el fine-tuning reentrena el modelo con nuevos datos. El grounding es más rentable, rápido de implementar y fácil de actualizar con nueva información. El fine-tuning es mejor cuando necesitas cambiar fundamentalmente el comportamiento del modelo o cuando tienes patrones específicos de un dominio por aprender.
El grounding reduce las alucinaciones al proporcionar al LLM un contexto factual del que extraer información en lugar de depender solo de sus datos de entrenamiento. Cuando se incluye información externa relevante en el prompt, se desplaza la distribución de probabilidad de tokens del modelo hacia respuestas fundamentadas en ese contexto, haciendo menos probable la generación de información inventada. La investigación muestra que el grounding puede reducir las tasas de alucinación en un 30-50%.
La Generación Aumentada por Recuperación (RAG) es una técnica de grounding que recupera documentos relevantes de una fuente de conocimiento externa y los proporciona como contexto al LLM. RAG es importante porque es escalable, rentable y permite actualizar la información sin reentrenar el modelo. Se ha convertido en el estándar de la industria para construir aplicaciones de IA fundamentadas.
Implementa grounding con búsqueda web cuando tu aplicación necesita acceso a información actual (noticias, eventos, datos recientes), cuando la precisión y las citas son críticas, o cuando el límite de conocimiento de tu LLM es una limitación. Usa grounding dinámico para buscar solo cuando sea necesario, reduciendo costes y latencia para consultas que no requieren información fresca.
Los desafíos clave incluyen asegurar la relevancia de los datos (la información recuperada debe realmente responder la pregunta), manejar la cantidad de datos (más no siempre es mejor), lidiar con el sesgo de 'perdido en el medio', donde los modelos ignoran información en contextos largos, y optimizar la eficiencia de tokens. Las soluciones incluyen usar búsqueda semántica con rankers, recuperar menos pero mejores resultados y colocar la información crítica al inicio o final del contexto.
El grounding es directamente relevante para el monitoreo de respuestas de IA porque permite a los sistemas proporcionar citas y atribución de fuentes. Plataformas como AmICited rastrean cómo los sistemas de IA referencian fuentes, lo cual solo es posible cuando el grounding está correctamente implementado. Esto ayuda a asegurar un despliegue responsable de la IA y la atribución de marca en diferentes plataformas de IA.
El sesgo de 'perdido en el medio' es un fenómeno donde los LLMs tienen un desempeño peor cuando la información relevante se encuentra en medio de contextos largos, en comparación con información al principio o al final. Esto ocurre porque los modelos tienden a 'ojear' al procesar grandes cantidades de texto. Las soluciones incluyen minimizar el tamaño de entrada, colocar información crítica en ubicaciones preferentes y usar fragmentos de texto más pequeños.
Para el despliegue en producción, enfócate en asegurar la calidad de los datos, implementar controles de acceso para información sensible, establecer políticas de actualización y refresco, habilitar registros de auditoría para cumplimiento y crear bucles de retroalimentación de usuarios para identificar fallos. Monitorea el uso de tokens para optimizar costes, implementa control de versiones para las bases de conocimiento y rastrea el comportamiento del modelo para detectar desviaciones.
AmICited rastrea cómo GPTs, Perplexity y Google AI Overviews citan y referencian tu contenido. Obtén información en tiempo real sobre monitoreo de respuestas de IA y atribución de marca.
Descubre cómo la Generación Aumentada por Recuperación transforma las citaciones de la IA, permitiendo una atribución precisa de fuentes y respuestas fundamenta...

Aprende cómo las alucinaciones de IA amenazan la seguridad de marca en Google AI Overviews, ChatGPT y Perplexity. Descubre estrategias de monitoreo, técnicas pa...

Descubre cómo los Modelos de Lenguaje Grande seleccionan y citan fuentes mediante la ponderación de evidencia, el reconocimiento de entidades y los datos estruc...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.