
Reconnaissance d'entités
La reconnaissance d'entités est une capacité NLP de l'IA identifiant et catégorisant les entités nommées dans le texte. Découvrez son fonctionnement, ses applic...
13 min de lecture

Découvrez comment les systèmes d’IA reconnaissent et traitent les entités dans le texte. Apprenez-en plus sur les modèles NER, les architectures de transformateurs et les applications réelles de la compréhension des entités.
La compréhension des entités est devenue une capacité fondamentale des systèmes d’intelligence artificielle moderne, permettant aux machines d’identifier et de comprendre les acteurs clés, lieux et concepts au sein de textes non structurés. Qu’il s’agisse d’alimenter des moteurs de recherche qui comprennent l’intention des utilisateurs ou de permettre à des chatbots de répondre à des questions complexes sur des personnes et organisations spécifiques, la reconnaissance d’entités forme la base d’une interaction homme-machine significative. Cette capacité technique est cruciale dans tous les secteurs—les institutions financières l’utilisent pour la conformité, les systèmes de santé pour la gestion des dossiers patients, et les plateformes e-commerce s’en servent pour comprendre les mentions produits et les retours clients. Comprendre comment les systèmes d’IA extraient et interprètent les entités est essentiel pour toute personne développant ou déployant des applications NLP en production.
La reconnaissance d’entités nommées (NER) est la tâche NLP qui consiste à identifier et classer les entités nommées—unités d’information spécifiques et significatives—dans le texte selon des catégories prédéfinies. Ces entités représentent les sujets concrets qui portent du sens dans la langue : des personnes qui agissent, des organisations qui prennent des décisions, des lieux où se produisent des événements, des expressions temporelles qui ancrent les événements dans le temps, des valeurs monétaires qui quantifient des transactions, et des produits achetés et vendus. La classification des entités est essentielle car elle transforme du texte brut en connaissances structurées sur lesquelles les machines peuvent raisonner et agir ; sans cela, un système ne peut distinguer “Apple la société” de “apple le fruit”, ni comprendre que “John Smith” et “J. Smith” désignent la même personne. La capacité à classer correctement les entités permet des applications aval telles que la construction de graphes de connaissances, l’extraction d’information, le question-réponse et la détection de relations.
| Type d’entité | Définition | Exemple |
|---|---|---|
| PERSONNE | Êtres humains individuels | “Steve Jobs”, “Marie Curie” |
| ORGANISATION | Entreprises, institutions, groupes | “Microsoft”, “Nations Unies”, “Université Harvard” |
| LIEU | Lieux et régions géographiques | “New York”, “Fleuve Amazone”, “Silicon Valley” |
| DATE | Expressions temporelles et périodes | “15 janvier 2024”, “mardi prochain”, “T3 2023” |
| ARGENT | Valeurs monétaires et devises | “50 millions $”, “100 €”, “5000 yens” |
| PRODUIT | Biens, services et créations | “iPhone 15”, “Windows 11”, “ChatGPT” |
Les systèmes d’IA modernes traitent les entités à travers un pipeline sophistiqué en plusieurs étapes, qui commence par la tokenisation, fragmentant le texte brut en tokens distincts servant d’unités fondamentales pour le traitement ultérieur. Chaque token est ensuite converti en une représentation numérique via des word embeddings—vecteurs denses capturant la signification sémantique—qui sont injectés dans des architectures neuronales conçues pour comprendre le contexte et les relations. Les modèles basés sur les transformateurs, désormais dominants en NLP, traitent les séquences en parallèle plutôt que séquentiellement, leur permettant de capturer les dépendances à longue distance et les relations contextuelles complexes, cruciales pour une compréhension précise des entités. Le mécanisme d’auto-attention des transformateurs permet à chaque token de pondérer dynamiquement l’importance de tous les autres tokens dans la séquence, créant des représentations contextuelles riches où le sens d’un mot dépend de son contexte ; c’est pourquoi “bank” est compris différemment dans “river bank” et “savings bank”. Les modèles de langage pré-entraînés comme BERT et GPT apprennent des motifs linguistiques généraux à partir de vastes corpus avant d’être affinés sur des tâches de reconnaissance d’entités, leur permettant d’exploiter des représentations acquises de la syntaxe, de la sémantique et des connaissances du monde. La couche finale des systèmes de reconnaissance d’entités utilise généralement une approche d’étiquetage de séquence—souvent implémentée par un champ aléatoire conditionnel (CRF) ou une simple tête de classification—qui affecte des labels d’entité à chaque token en se basant sur les représentations contextuelles apprises par le réseau. Cette architecture permet aux systèmes d’IA de comprendre non seulement quelles entités sont présentes, mais aussi comment elles interagissent et quels rôles elles jouent dans le contexte global du texte.
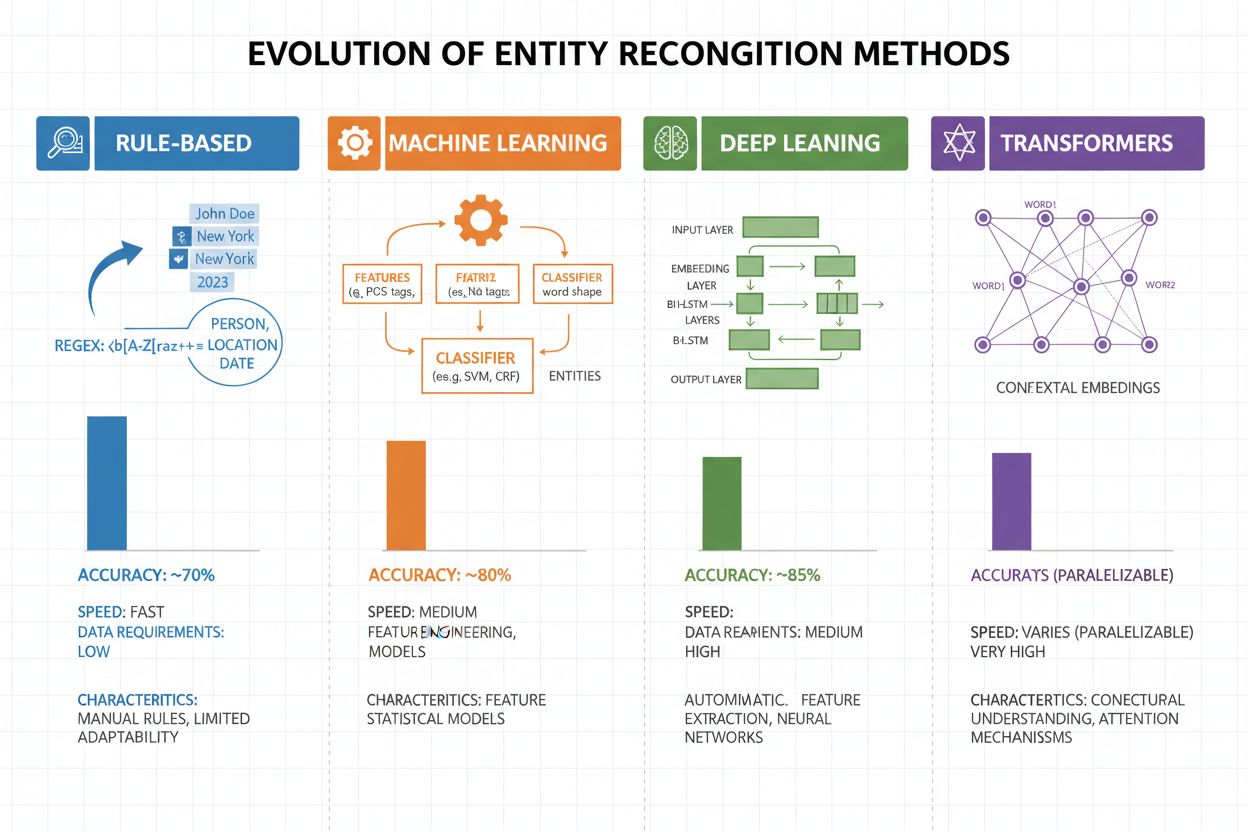
La reconnaissance d’entités a connu une évolution spectaculaire au cours des vingt dernières années, passant d’approches à base de règles simples à des architectures neuronales sophistiquées. Les premiers systèmes utilisaient des règles faites à la main et des dictionnaires, s’appuyant sur des expressions régulières et la correspondance de motifs pour identifier les entités—des méthodes interprétables et nécessitant peu de données d’entraînement mais souffrant d’une faible généralisation et d’un entretien lourd. L’avènement de l’apprentissage automatique a apporté des approches supervisées comme les machines à vecteurs de support (SVM) et les champs aléatoires conditionnels (CRF), qui apprenaient à partir de données annotées via l’ingénierie de caractéristiques et amélioraient nettement la précision, tout en nécessitant toujours l’expertise de domaine pour concevoir des caractéristiques pertinentes. Les méthodes deep learning, en particulier les LSTM et BiLSTM, ont automatisé l’extraction des caractéristiques en apprenant directement à partir du texte brut, atteignant une précision bien supérieure sans ingénierie manuelle, mais demandant davantage de données annotées. Les modèles à base de transformateurs comme BERT et RoBERTa ont révolutionné le domaine grâce à l’auto-attention, capturant dépendances à longue distance et nuances contextuelles, atteignant des résultats de pointe (BERT : 90,9% F1 sur CoNLL-2003) tout en rendant possible l’apprentissage par transfert à partir de modèles massivement pré-entraînés. Le compromis entre complexité et précision a radicalement évolué : si les systèmes à base de règles gardent leur valeur dans des environnements contraints ou très spécialisés, les modèles de transformateurs dominent désormais dès lors que les ressources informatiques et les données annotées sont suffisantes, avec des alternatives plus légères comme DistilBERT pour les systèmes de production à faible latence.
Les modèles basés sur les transformateurs ont fondamentalement transformé la reconnaissance d’entités, remplaçant le traitement séquentiel par des mécanismes d’auto-attention parallèles considérant simultanément tous les tokens d’une phrase, permettant une compréhension contextuelle bien plus riche que les architectures précédentes. BERT et ses variantes (RoBERTa, DistilBERT, ALBERT) s’appuient sur un pré-entraînement bidirectionnel sur d’immenses corpus non annotés, apprenant des représentations universelles du langage capturant informations syntaxiques et sémantiques avant d’être affinés sur des tâches NER avec relativement peu de données annotées. Le paradigme pré-entraînement / fine-tuning est particulièrement puissant pour la reconnaissance d’entités : les modèles pré-entraînés sur des milliards de tokens développent des représentations robustes de la structure du langage et des motifs d’entités, adaptables ensuite à des domaines spécifiques avec seulement quelques milliers d’exemples annotés, réduisant considérablement les besoins en données par rapport à un entraînement from scratch. Les transformateurs excellent pour la compréhension des entités grâce au mécanisme d’attention multi-tête, permettant à différentes têtes de spécialiser sur divers types de relations—certaines sur les frontières syntaxiques, d’autres sur les associations sémantiques entre entités et contexte. La reconnaissance d’entités multilingue a été révolutionnée par des modèles comme mBERT et XLM-RoBERTa, pré-entraînés sur 100+ langues, permettant le transfert zero-shot/few-shot vers des langues peu dotées et la liaison d’entités interlinguistique. Des modèles émergents comme GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) repoussent les limites en permettant une reconnaissance d’entités basée sur instructions, où le modèle identifie n’importe quel type d’entité spécifié en langage naturel sans fine-tuning spécifique à la tâche, amorçant une évolution vers des systèmes plus flexibles et généralisables.
Malgré des avancées remarquables, les systèmes de reconnaissance d’entités font face à des défis persistants en conditions réelles, l’ambiguïté et la sensibilité au contexte étant parmi les plus ardus—le mot “Apple” nécessite de comprendre s’il s’agit du fruit ou de la société technologique selon le contexte, et même les meilleurs modèles peinent à désambiguïser dans des textes bruités ou ambigus. Les entités hors-vocabulaire (OOV) posent également problème : les modèles entraînés sur des corpus standards peuvent ne jamais rencontrer des entités rares, des noms propres de nouveaux domaines ou des variantes mal orthographiées, entraînant des erreurs de classification ou une non-reconnaissance. L’adaptation au domaine demeure difficile : des modèles entraînés sur des actualités (CoNLL-2003) performent mal sur du biomédical, du juridique ou des réseaux sociaux, où la distribution des entités et les motifs linguistiques diffèrent, nécessitant une ré-annotation coûteuse et du fine-tuning pour chaque domaine. Les erreurs de détection de frontières—quand une entité est bien identifiée mais ses limites mal localisées—sont fréquentes avec des entités multi-mots ou imbriquées, comme distinguer “New York City” de “New York” ou gérer “Chief Executive Officer of Apple Inc.” Les complexités multilingues accentuent ces défis, chaque langue ayant ses propres conventions de capitalisation, morphologie et motifs de nommage, rendant les modèles entraînés sur l’anglais peu performants sur d’autres langues. Le manque de données pour des domaines spécialisés (noms de maladies rares, technologies émergentes, terminologie propriétaire) crée un goulot d’étranglement où le coût de l’annotation manuelle est prohibitif, forçant à choisir entre moindre précision et investissement substantiel en collecte de données spécifiques.
La compréhension des entités est devenue indispensable dans tous les secteurs, transformant la valeur extraite des textes non structurés. En extraction d’information et construction de graphes de connaissances, la reconnaissance d’entités permet la population automatisée de bases de données structurées à partir de documents, alimentant moteurs de recherche et systèmes de recommandation qui comprennent les relations entre personnes, lieux et concepts. Les organisations de santé utilisent la compréhension des entités pour identifier noms de médicaments, dosages, symptômes et données démographiques dans les notes cliniques, améliorant le support décisionnel et permettant la pharmacovigilance à grande échelle. Les institutions financières extraient symboles boursiers, valeurs monétaires et événements de marché à partir de flux d’actualités et rapports de résultats, permettant aux systèmes de trading algorithmique et de gestion du risque de réagir en temps réel. Les entreprises de legal tech appliquent la reconnaissance d’entités pour identifier automatiquement parties, dates, obligations et clauses de responsabilité dans les contrats, réduisant le temps de revue documentaire de semaines à quelques heures. Les services clients et chatbots extraient les intentions utilisateurs et le contexte pertinent—numéros de commande, noms de produits, types de problèmes—pour un routage plus précis et une résolution plus rapide. Les plateformes e-commerce utilisent la compréhension des entités pour identifier les produits, marques, caractéristiques et spécifications dans les avis clients et requêtes, améliorant la découverte et la personnalisation. Les systèmes de recommandation de contenu s’appuient sur la reconnaissance d’entités pour comprendre avec quoi interagissent les utilisateurs, permettant des filtrages collaboratifs et recommandations sophistiquées qui stimulent l’engagement et les revenus.
Implémenter un système de compréhension des entités en production requiert une attention particulière à la préparation des données, la sélection du modèle et l’évaluation. Commencez avec des données annotées de haute qualité : définissez clairement les types d’entités, utilisez des métriques d’accord inter-annotateurs pour garantir la cohérence et visez au moins 500-1000 exemples annotés par type d’entité, même si certains domaines en nécessitent davantage. Le choix du modèle dépend de vos contraintes : les systèmes à règles offrent interprétabilité et faible latence pour des domaines bien définis, les modèles traditionnels (CRF, SVM) offrent de bonnes performances avec des volumes de données modérés, tandis que les modèles transformeurs (BERT, RoBERTa) atteignent la pointe mais exigent plus de ressources et de données. Les stratégies d’entraînement et de fine-tuning doivent inclure des techniques d’augmentation de données pour gérer le déséquilibre des classes, la validation croisée pour prévenir l’overfitting, et l’ajustement attentif des hyperparamètres (taux d’apprentissage, taille des batchs). Évaluez votre système avec la précision (entités correctement identifiées), le rappel (entités trouvées parmi toutes les vraies entités) et le score F1 (moyenne harmonique), avec des métriques par type pour cibler les points faibles. Les considérations de déploiement incluent la latence (batch vs. temps réel), la scalabilité et l’intégration avec vos pipelines de données, tandis que le suivi post-déploiement doit surveiller la dérive des performances, les taux de faux positifs et les retours utilisateurs pour déclencher de nouveaux cycles d’entraînement.
L’écosystème d’outils de compréhension des entités propose des solutions pour tous les besoins. Les librairies open source comme spaCy offrent des pipelines NER prêts pour la production avec d’excellentes performances (89,22% F1 sur les benchmarks) et une documentation de qualité, idéales pour des équipes maîtrisant le machine learning ; NLTK a une valeur éducative et des capacités NER de base ; Hugging Face Transformers donne accès aux modèles pré-entraînés de pointe, facilement affinables sur vos domaines avec peu de code. Les services cloud managés éliminent la gestion de l’infrastructure : Google Cloud Natural Language API, AWS Comprehend et IBM Watson NLP proposent une reconnaissance d’entités pré-entraînée multilingue, gérant l’élasticité et l’intégration avec les pipelines cloud. Les frameworks spécialisés comme Flair (basé sur PyTorch avec un excellent support de l’étiquetage de séquence) et DeepPavlov (modèles pré-entraînés pour de multiples langues et domaines) ciblent chercheurs et équipes cherchant une personnalisation avancée. Le choix entre solutions sur-mesure et outils prêts à l’emploi dépend de la sensibilité des données (on-premise vs. cloud), des niveaux de précision requis, de la spécialisation du domaine et de l’expertise de l’équipe : utilisez les APIs managées pour les applications généralistes avec des entités standards, les librairies open source pour la personnalisation métier sur vos données, et développez un modèle sur-mesure seulement si les outils existants ne répondent pas à vos exigences de précision ou de latence.
L’avenir de la compréhension des entités est porté par les grands modèles de langage qui apportent une flexibilité et des performances inédites à la tâche. Des modèles comme GPT-4 et Claude démontrent des capacités remarquables de reconnaissance d’entités few-shot et zero-shot, permettant d’identifier des types d’entités personnalisés avec seulement quelques exemples ou même de simples descriptions en langage naturel, réduisant drastiquement le besoin d’annotation et accélérant la mise en production. La compréhension multimodale des entités émerge, combinant texte, images et données structurées pour reconnaître des entités dans des documents, factures et pages web avec un contexte enrichi, ouvrant la voie à la gestion documentaire automatisée et à la recherche visuelle. Les progrès du traitement en temps réel grâce à la distillation de modèles et au déploiement edge rendent possible la reconnaissance d’entités sur mobiles et objets connectés, ouvrant de nouveaux usages en réalité augmentée, traduction instantanée ou systèmes autonomes. Les avancées du fine-tuning spécifique au domaine produisent des modèles spécialisés (biomédical, juridique, financier) surpassant les généralistes de plusieurs ordres de grandeur, grâce à des techniques comme le pré-entraînement adaptatif ou le transfert, de plus en plus accessibles. À mesure que ces technologies mûrissent, la compréhension des entités deviendra une couche fondamentale invisible de l’IA, permettant aux machines de comprendre le monde avec une sémantique proche de l’humain et ouvrant des perspectives encore insoupçonnées.
À mesure que des systèmes comme ChatGPT, Perplexity ou Google AI Overviews sont de plus en plus intégrés dans la découverte et la consommation d’information, comprendre comment ces IA reconnaissent et référencent les entités—y compris votre marque—devient essentiel. La compréhension des entités est le mécanisme par lequel les IA identifient et traitent les mentions de sociétés, produits, personnes et concepts. En surveillant comment les IA comprennent et référencent votre marque via la reconnaissance d’entités, vous obtenez des informations sur :
C’est précisément ce que AmICited surveille—le suivi de la reconnaissance et des références à votre marque en tant qu’entité à travers plusieurs plateformes d’IA. Comprendre la reconnaissance d’entités, c’est mieux comprendre comment les IA perçoivent et communiquent à propos de votre entreprise.
La reconnaissance d'entités (NER) identifie et classe les entités dans le texte (par exemple, 'Apple' comme ORGANISATION), tandis que la liaison d'entités relie ces entités à des bases de connaissances ou des références canoniques (par exemple, relier 'Apple' à la page Wikipédia d'Apple Inc.). La reconnaissance d'entités est la première étape ; la liaison d'entités ajoute un ancrage sémantique.
Les modèles à la pointe basés sur les transformateurs comme BERT atteignent 90,9% de score F1 sur des benchmarks standards comme CoNLL-2003. Cependant, la précision varie considérablement selon le domaine—les modèles entraînés sur des actualités performent mal sur des textes biomédicaux ou issus des réseaux sociaux. La précision réelle dépend fortement de l'adaptation au domaine et de la qualité des données.
Oui, des modèles multilingues comme mBERT et XLM-RoBERTa supportent plus de 100 langues simultanément. Cependant, la performance varie selon la langue en raison des différences de conventions de capitalisation, de morphologie, et de données d'entraînement disponibles. Les modèles spécifiques à une langue surpassent généralement les modèles multilingues pour les applications critiques.
Les systèmes basés sur des règles utilisent des motifs et des dictionnaires faits à la main (rapides, interprétables, mais fragiles). Les systèmes basés sur l'IA apprennent à partir de données annotées (plus flexibles, meilleure généralisation, mais nécessitent des données d'entraînement et de l'ingénierie de caractéristiques). Les approches modernes de deep learning automatisent l'extraction des caractéristiques, atteignant une précision supérieure.
Les systèmes à base de règles nécessitent uniquement la définition des motifs. Les modèles traditionnels d'IA nécessitent 300-500 exemples annotés. Les modèles basés sur les transformateurs fonctionnent avec 800+ exemples mais bénéficient de l'apprentissage par transfert—les modèles pré-entraînés peuvent donner de bons résultats avec seulement 100-200 exemples spécifiques au domaine via le fine-tuning.
Les principaux défis incluent : l'ambiguïté (un même mot peut avoir des significations différentes), les entités hors-vocabulaire, l'adaptation au domaine (les modèles entraînés sur un domaine échouent sur un autre), les erreurs de détection de frontières, les complexités multilingues, et le manque de données pour les domaines spécialisés. Cela nécessite une conception de système soignée et un ajustement spécifique au domaine.
Le contexte est crucial—'bank' n'a pas le même sens dans 'river bank' que dans 'savings bank'. Les transformateurs modernes utilisent l'auto-attention pour pondérer le contexte de tous les tokens environnants, leur permettant de désambiguïser les entités selon le contexte linguistique et sémantique. Une mauvaise gestion du contexte est une source majeure d'erreurs en reconnaissance d'entités.
Les développements futurs incluent : les grands modèles de langage permettant la reconnaissance d'entités zéro-shot, la compréhension multimodale combinant texte et images, le traitement en temps réel sur les appareils edge, et les avancées du fine-tuning spécifique au domaine. La compréhension des entités deviendra une couche fondamentale invisible permettant aux machines de comprendre le monde avec une compréhension sémantique proche de celle des humains.
AmICited suit les mentions d'entités à travers des systèmes d'IA comme ChatGPT, Perplexity et Google AI Overviews. Comprenez comment l'IA comprend et fait référence à votre marque en temps réel.
La reconnaissance d'entités est une capacité NLP de l'IA identifiant et catégorisant les entités nommées dans le texte. Découvrez son fonctionnement, ses applic...

Découvrez comment les systèmes d'IA identifient, extraient et comprennent les relations entre entités dans un texte. Explorez les techniques d'extraction des re...

Découvrez comment construire la visibilité des entités dans la recherche IA. Maîtrisez l'optimisation des graphes de connaissances, le balisage schema et les st...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.