Découvrez comment la génération augmentée par récupération transforme les citations de l’IA, permettant une attribution précise des sources et des réponses étayées sur ChatGPT, Perplexity et Google AI Overviews.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Les grands modèles de langage ont révolutionné l’IA, mais présentent un défaut critique : la borne de connaissances. Ces modèles sont entraînés sur des données datant d’une période donnée, ce qui signifie qu’ils ne peuvent pas accéder à des informations postérieures à cette date. Outre l’obsolescence, les LLM traditionnels souffrent d’hallucinations—générant avec assurance de fausses informations plausibles—et n’apportent aucune attribution de source à leurs affirmations. Lorsqu’une entreprise a besoin de données de marché actuelles, de recherches propriétaires ou de faits vérifiables, les LLM traditionnels ne sont pas à la hauteur, laissant les utilisateurs avec des réponses qu’ils ne peuvent ni vérifier ni valider.
Qu’est-ce que le RAG – Définition et composants
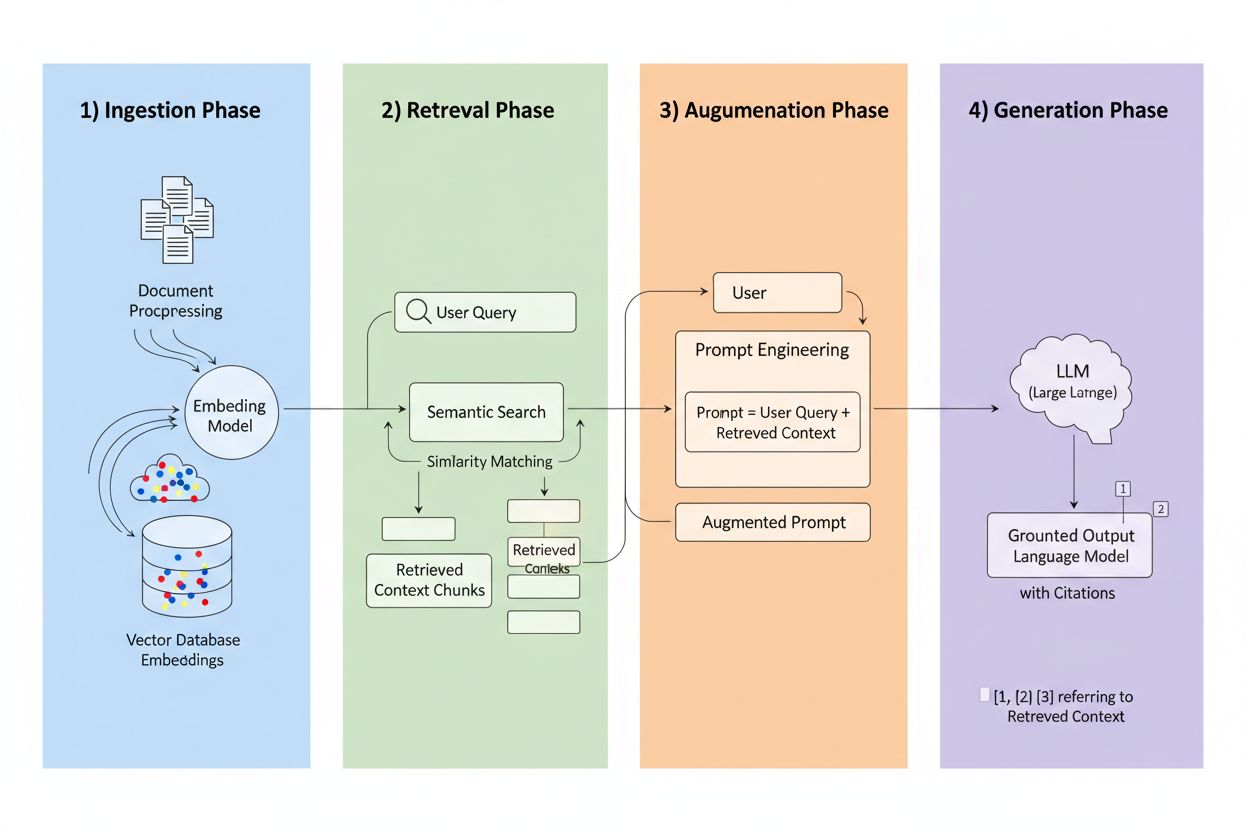
La génération augmentée par récupération (RAG) est un cadre qui allie la puissance générative des LLM à la précision des systèmes de recherche d’information. Au lieu de ne compter que sur les données d’entraînement, les systèmes RAG vont chercher des informations pertinentes dans des sources externes avant de générer des réponses, créant une chaîne qui fonde les réponses sur des données réelles. Les quatre composants clés fonctionnent de concert : Ingestion (conversion des documents en formats interrogeables), Récupération (trouver les sources les plus pertinentes), Augmentation (enrichissement du prompt avec le contexte récupéré), et Génération (création de la réponse finale avec citations). Voici comment le RAG se compare aux approches traditionnelles :
Aspect
LLM traditionnel
Système RAG
Source de connaissances
Données d’entraînement statiques
Sources indexées externes
Capacité de citation
Aucune/hallucinée
Traçable vers les sources
Précision
Sujet aux erreurs
Fondé sur des faits
Données en temps réel
Non
Oui
Risque d’hallucination
Élevé
Faible
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Comment fonctionne la récupération RAG – Approfondissement technique
Le moteur de récupération est le cœur battant du RAG, bien plus sophistiqué qu’une simple recherche par mots-clés. Les documents sont convertis en vecteurs d’embedding—représentations mathématiques capturant la signification sémantique—permettant au système de retrouver du contenu conceptuellement similaire même si les mots exacts ne correspondent pas. Le système découpe les documents en morceaux gérables, généralement de 256 à 1024 tokens, équilibrant la préservation du contexte et la précision de la récupération. La plupart des systèmes RAG avancés utilisent une recherche hybride, combinant la similarité sémantique à la recherche par mots-clés traditionnelle pour capter à la fois les correspondances conceptuelles et exactes. Un mécanisme de reranking note ensuite les candidats, souvent en utilisant des modèles cross-encoder qui évaluent la pertinence plus finement que la récupération initiale. La pertinence est calculée via de multiples signaux : score de similarité sémantique, recoupement des mots-clés, correspondance des métadonnées et autorité du domaine. L’ensemble du processus se déroule en millisecondes, garantissant à l’utilisateur des réponses rapides et précises sans latence perceptible.
L’avantage de la citation
C’est ici que le RAG bouleverse le paysage des citations : lorsqu’un système récupère une information depuis une source indexée précise, cette source devient traçable et vérifiable. Chaque fragment de texte peut être relié à son document, URL ou publication d’origine, rendant la citation automatique plutôt qu’hallucinée. Ce changement fondamental crée une transparence inédite dans la prise de décision de l’IA—les utilisateurs voient exactement quelles sources ont informé la réponse, peuvent vérifier les affirmations par eux-mêmes et évaluer la crédibilité des sources. Contrairement aux LLM traditionnels où les citations sont souvent inventées ou génériques, les citations RAG sont ancrées dans des événements de récupération réels. Cette traçabilité accroît considérablement la confiance des utilisateurs, qui peuvent valider l’information au lieu d’y croire sur parole. Pour les créateurs et éditeurs de contenu, cela signifie que leur travail peut être découvert et crédité par les systèmes d’IA, ouvrant de nouveaux canaux de visibilité.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Facteurs de qualité des citations dans les systèmes RAG
Toutes les sources ne se valent pas dans les systèmes RAG, et plusieurs facteurs déterminent quels contenus sont le plus souvent cités :
Autorité : La réputation du domaine, le profil de backlinks et la présence dans les graphes de connaissances signalent la fiabilité aux algorithmes de récupération
Actualité : Les contenus mis à jour dans des cycles de 48 à 72 heures sont mieux classés, la fraîcheur indiquant un maintien actif et la fiabilité
Pertinence : L’alignement sémantique avec les requêtes utilisateur détermine si le contenu apparaît dans les résultats de récupération
Structure : Une hiérarchie claire, des en-têtes descriptifs et un balisage sémantique aident les systèmes à comprendre et extraire l’information avec précision
Densité factuelle : Les contenus riches en données précises, statistiques et citations fournissent plus de fragments récupérables qu’un survol générique
Graphe de connaissances : La présence sur Wikipédia, Wikidata ou des bases sectorielles spécifiques augmente considérablement la probabilité de citation
Chaque facteur renforce les autres—un article bien structuré, fréquemment mis à jour, issu d’un domaine autoritaire, disposant de bons backlinks et présent dans les graphes de connaissances devient un aimant à citations pour les systèmes RAG. Cela crée un nouveau paradigme d’optimisation où la visibilité dépend moins du SEO générateur de trafic que du fait de devenir une source d’information fiable et structurée.
Comment les différentes plateformes IA utilisent le RAG pour les citations
Différentes plateformes IA implémentent le RAG selon des stratégies propres, générant des schémas de citation variés. ChatGPT privilégie fortement Wikipédia, des études montrant qu’environ 26 à 35 % des citations proviennent de Wikipédia, reflétant son autorité et son format structuré. Google AI Overviews choisit des sources plus diverses, puisant dans des sites d’actualité, publications académiques et forums, Reddit apparaissant dans environ 5 % des citations malgré une autorité traditionnelle moindre. Perplexity AI cite généralement 3 à 5 sources par réponse, montrant une préférence pour les publications sectorielles et l’actualité récente, optimisant pour l’exhaustivité et l’actualité. Ces plateformes pondèrent différemment l’autorité du domaine—certaines privilégient les critères traditionnels comme les backlinks et l’ancienneté du domaine, d’autres mettent l’accent sur la fraîcheur du contenu et la pertinence sémantique. Comprendre ces stratégies de récupération propres à chaque plateforme est crucial pour les créateurs, car l’optimisation pour le RAG d’une plateforme peut différer sensiblement d’une autre.
RAG vs Recherche traditionnelle – Implications pour la citation
L’essor du RAG bouleverse la sagesse SEO traditionnelle. En référencement, citations et visibilité sont directement corrélées au trafic—il faut des clics pour compter. Le RAG inverse cette équation : le contenu peut être cité et influencer les réponses IA sans générer aucun trafic. Un article bien structuré et autoritaire peut apparaître dans des dizaines de réponses IA chaque jour sans recevoir un seul clic, les utilisateurs obtenant leur réponse directement via le résumé IA. Cela signifie que les signaux d’autorité sont plus cruciaux que jamais, car ils sont le principal mécanisme d’évaluation de la qualité des sources par les systèmes RAG. La cohérence inter-plateformes devient essentielle—si votre contenu est présent sur votre site, LinkedIn, bases sectorielles et graphes de connaissances, les systèmes RAG voient des signaux d’autorité renforcés. La présence dans les graphes de connaissances passe d’un « plus » à une infrastructure essentielle, car ces bases structurées sont les principales sources de récupération pour beaucoup de RAG. Le jeu de la citation n’est plus « générer du trafic » mais « devenir une source d’information fiable ».
Optimiser son contenu pour les citations RAG
Pour maximiser les citations RAG, la stratégie de contenu doit passer de l’optimisation du trafic à l’optimisation de la source. Mettez en place des cycles de mise à jour de 48 à 72 heures pour vos contenus evergreen, signalant aux systèmes de récupération que vos informations sont à jour. Déployez des balisages de données structurées (Schema.org, JSON-LD) pour aider les systèmes à comprendre le sens et les relations de votre contenu. Alignez votre contenu sémantiquement avec les schémas de requêtes courants—utilisez un langage naturel correspondant à la façon dont les gens posent des questions, pas seulement à la façon dont ils recherchent. Formatez vos contenus avec des sections FAQ et Q&R, correspondant directement au schéma question-réponse utilisé par les systèmes RAG. Développez ou contribuez à des articles Wikipédia et des entrées dans les graphes de connaissances, qui sont des sources primaires pour la plupart des plateformes. Renforcez l’autorité des backlinks via des partenariats stratégiques et des citations depuis d’autres sources autoritaires, car le profil de liens reste un signal fort d’autorité. Enfin, maintenez la cohérence sur toutes les plateformes—assurez-vous que vos affirmations, données et messages clés sont alignés sur votre site web, vos profils sociaux, bases sectorielles et graphes de connaissances, créant ainsi des signaux de fiabilité renforcés.
Le futur du RAG et des citations
La technologie RAG évolue rapidement, avec plusieurs tendances redéfinissant le fonctionnement des citations. Des algorithmes de récupération plus sophistiqués iront au-delà de la simple similarité sémantique, intégrant une compréhension plus profonde de l’intention et du contexte des requêtes, améliorant la pertinence des citations. Des bases de connaissances spécialisées émergeront pour des domaines spécifiques—RAG médical utilisant la littérature médicale, systèmes juridiques exploitant la jurisprudence et les textes de loi—créant de nouvelles opportunités de citation pour des sources expertes. L’intégration aux systèmes multi-agents permettra au RAG d’orchestrer plusieurs récupérateurs spécialisés, combinant les insights de différentes bases pour des réponses plus complètes. L’accès aux données en temps réel s’améliorera fortement, permettant aux systèmes RAG d’intégrer des informations live issues d’API, de bases de données ou de flux en continu. Le RAG agentique—où des agents IA décident de façon autonome quoi récupérer, comment le traiter et quand itérer—créera des schémas de citation plus dynamiques, citant potentiellement plusieurs fois les mêmes sources à mesure que les agents affinent leur raisonnement.
Le rôle d’AmICited dans la surveillance des citations RAG
Alors que le RAG redéfinit la façon dont les systèmes IA découvrent et citent les sources, comprendre votre performance de citation devient essentiel. AmICited surveille les citations IA sur toutes les plateformes, suivant quelles de vos sources apparaissent sur ChatGPT, Google AI Overviews, Perplexity et les systèmes IA émergents. Vous verrez quelles sources précises sont citées, à quelle fréquence et dans quel contexte—révélant quels contenus résonnent avec les algorithmes de récupération RAG. Notre plateforme vous aide à comprendre les schémas de citation sur l’ensemble de votre portefeuille de contenus, identifiant ce qui rend certains éléments dignes de citation et d’autres invisibles. Mesurez la visibilité de votre marque dans les réponses IA grâce à des métriques adaptées à l’ère RAG, au-delà de l’analytique de trafic classique. Réalisez une analyse concurrentielle de la performance des citations, en voyant comment vos sources se positionnent dans les réponses générées par l’IA face à la concurrence. Dans un monde où la citation IA dicte visibilité et autorité, avoir une vision claire de votre performance de citation n’est pas optionnel—c’est la clé pour rester compétitif.
Questions fréquemment posées
Quelle est la différence entre le RAG et les LLM traditionnels ?
Les LLM traditionnels s'appuient sur des données d'entraînement statiques avec des bornes de connaissances et ne peuvent pas accéder à des informations en temps réel, ce qui entraîne souvent des hallucinations et des affirmations invérifiables. Les systèmes RAG récupèrent des informations à partir de sources indexées externes avant de générer des réponses, permettant des citations précises et des réponses étayées fondées sur des données actuelles et vérifiables.
Comment le RAG améliore-t-il la précision des citations ?
Le RAG relie chaque information récupérée à sa source d'origine, rendant les citations automatiques et vérifiables plutôt qu'hallucinées. Cela crée un lien direct entre la réponse et le document source, permettant aux utilisateurs de vérifier les affirmations de manière indépendante et d'évaluer la crédibilité de la source.
Quels facteurs déterminent quelles sources sont citées dans les systèmes RAG ?
Les systèmes RAG évaluent les sources selon l'autorité (réputation du domaine et backlinks), la fraîcheur (contenu mis à jour dans les 48 à 72 heures), la pertinence sémantique avec la requête, la structure et la clarté du contenu, la densité factuelle avec des données précises, et la présence dans des graphes de connaissances comme Wikipédia. Ces facteurs se combinent pour déterminer la probabilité de citation.
Comment puis-je optimiser mon contenu pour les citations RAG ?
Mettez à jour votre contenu toutes les 48 à 72 heures pour conserver les signaux de fraîcheur, implémentez des balisages de données structurées (Schema.org), alignez le contenu sémantiquement avec les requêtes courantes, utilisez des formats FAQ et Q&R, développez votre présence sur Wikipédia et dans les graphes de connaissances, renforcez l'autorité des backlinks et maintenez la cohérence sur toutes les plateformes.
Pourquoi la présence dans un graphe de connaissances est-elle importante pour les citations par l'IA ?
Les graphes de connaissances comme Wikipédia et Wikidata sont les principales sources de récupération pour la plupart des systèmes RAG. Être présent dans ces bases structurées augmente considérablement la probabilité de citation et crée des signaux de confiance fondamentaux que les systèmes d'IA référencent à maintes reprises pour des requêtes diverses.
À quelle fréquence dois-je mettre à jour le contenu pour la visibilité RAG ?
Le contenu doit être mis à jour toutes les 48 à 72 heures pour maintenir de forts signaux de fraîcheur dans les systèmes RAG. Il n'est pas nécessaire de tout réécrire : ajouter de nouvelles données, actualiser les statistiques ou étoffer des sections avec des développements récents suffit à conserver l'éligibilité à la citation.
Quel rôle joue l'autorité du domaine dans les citations RAG ?
L'autorité du domaine fonctionne comme un proxy de fiabilité dans les algorithmes RAG, représentant environ 5 % de la probabilité de citation. Elle est évaluée via l'ancienneté du domaine, les certificats SSL, le profil de backlinks, l'attribution d'experts et la présence dans les graphes de connaissances, qui s'additionnent pour influencer la sélection des sources.
Comment AmICited aide-t-il à surveiller les citations RAG ?
AmICited suit quelles sources à vous apparaissent dans les réponses générées par l'IA sur ChatGPT, Google AI Overviews, Perplexity et d'autres plateformes. Vous verrez la fréquence des citations, leur contexte et la performance par rapport à la concurrence, vous aidant à comprendre ce qui rend un contenu digne de citation à l'ère du RAG.
Surveillez les citations de votre marque par l'IA
Comprenez comment votre marque apparaît dans les réponses générées par l'IA sur ChatGPT, Perplexity, Google AI Overviews et plus encore. Suivez les schémas de citation, mesurez la visibilité et optimisez votre présence dans le paysage de la recherche pilotée par l'IA.
Fonctionnement de la génération augmentée par récupération : architecture et processus
Découvrez comment RAG combine les LLM avec des sources de données externes pour générer des réponses d’IA précises. Comprenez le processus en cinq étapes, les c...
Comment les systèmes RAG gèrent-ils les informations obsolètes ?
Découvrez comment les systèmes de génération augmentée par récupération (RAG) gèrent la fraîcheur de leur base de connaissances, évitent les données obsolètes e...
Qu'est-ce que le RAG dans la recherche par IA : Guide complet sur la génération augmentée par récupération
Découvrez ce qu’est le RAG (génération augmentée par récupération) en recherche par IA. Découvrez comment RAG améliore la précision, réduit les hallucinations e...
10 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.