Comment identifier les crawlers IA dans vos journaux de serveur
Apprenez à identifier et surveiller les crawlers IA comme GPTBot, ClaudeBot et PerplexityBot dans vos journaux de serveur. Guide complet avec chaînes user-agent, vérification IP et stratégies de surveillance pratiques.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
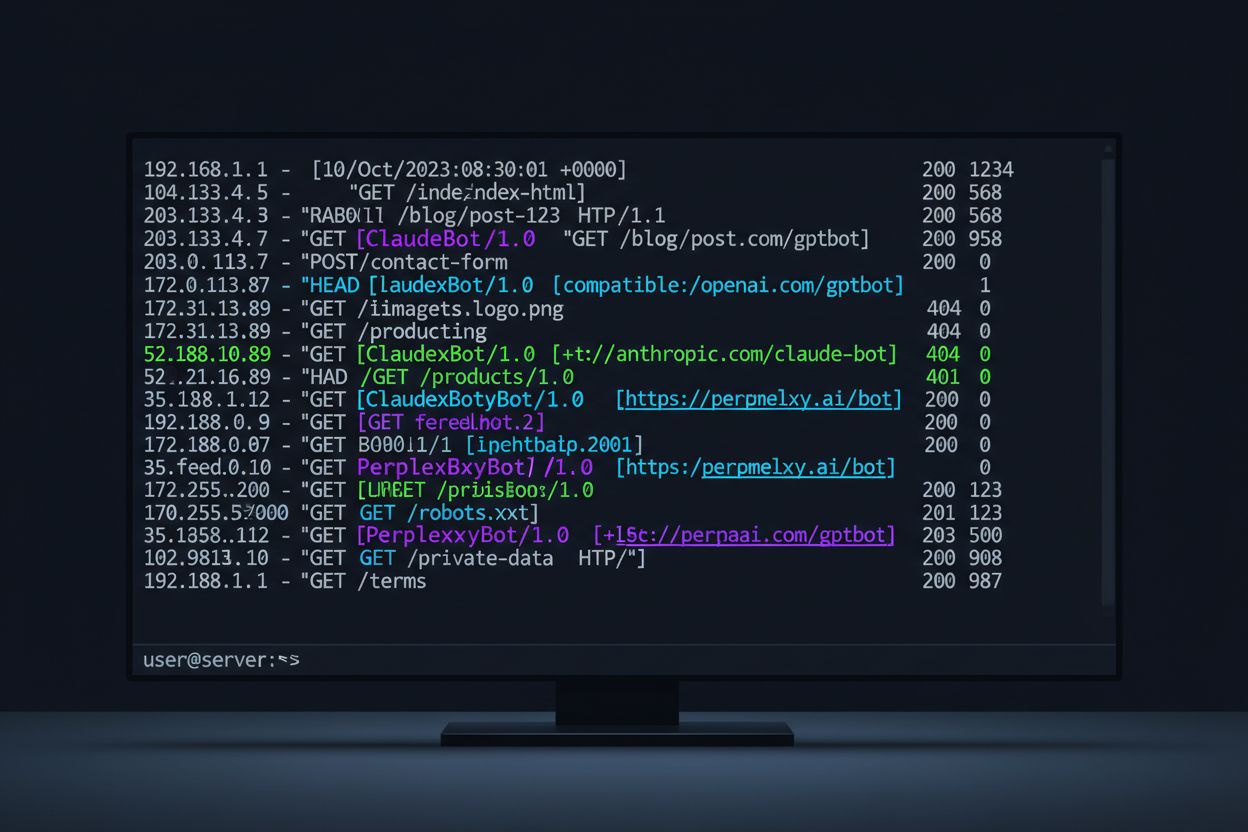
Le paysage du trafic web a profondément changé avec la montée de la collecte de données par IA, allant bien au-delà de l’indexation traditionnelle par les moteurs de recherche. Contrairement à Googlebot de Google ou au crawler de Bing, qui existent depuis des décennies, les crawlers IA représentent désormais une part significative et en forte croissance du trafic serveur—certains sites enregistrant des taux de croissance supérieurs à 2 800% d’une année sur l’autre. Comprendre l’activité des crawlers IA est crucial pour les propriétaires de sites web car cela impacte directement les coûts de bande passante, les performances du serveur, les métriques d’utilisation des données et, surtout, votre capacité à contrôler la façon dont votre contenu est utilisé pour entraîner les modèles IA. Sans surveillance appropriée, vous naviguez à l’aveugle face à un bouleversement majeur de l’accès et de l’utilisation de vos données.
Comprendre les types de crawlers IA & les chaînes User-Agent
Les crawlers IA existent sous de nombreuses formes, chacun ayant des objectifs distincts et des caractéristiques identifiables via leurs chaînes user-agent. Ces chaînes sont les empreintes digitales numériques que les crawlers laissent dans vos journaux de serveur, vous permettant d’identifier précisément quels systèmes IA accèdent à votre contenu. Voici un tableau de référence exhaustif des principaux crawlers IA actuellement actifs sur le web :
Nom du crawler
Objectif
Chaîne User-Agent
Vitesse de crawl
GPTBot
Collecte de données OpenAI pour l’entraînement de ChatGPT
Analyser vos journaux de serveur pour détecter l’activité des crawlers IA requiert une approche méthodique et une familiarité avec les formats de logs générés par votre serveur web. La plupart des sites utilisent Apache ou Nginx, chacun ayant des structures de logs légèrement différentes, mais tous deux sont efficaces pour identifier le trafic crawler. L’essentiel est de savoir où chercher et quels motifs rechercher. Voici un exemple d’entrée de log Apache :
Cette commande extrait la chaîne user-agent, filtre les entrées de type bot, et compte les occurrences, ce qui vous donne une vue claire des crawlers les plus fréquents sur votre site.
Vérification IP & Authentification
Les chaînes user-agent peuvent être usurpées, ce qui signifie qu’un acteur malveillant peut prétendre être GPTBot alors qu’il s’agit d’autre chose. C’est pourquoi la vérification IP est essentielle pour confirmer que le trafic se prétendant issu d’entreprises IA légitimes provient effectivement de leur infrastructure. Vous pouvez effectuer une recherche DNS inverse sur l’adresse IP pour vérifier la propriété :
nslookup 192.0.2.1
Si le DNS inverse pointe vers un domaine appartenant à OpenAI, Anthropic ou une autre entreprise IA reconnue, vous pouvez être plus confiant quant à la légitimité du trafic. Voici les méthodes clés de vérification :
Recherche DNS inverse : vérifiez si le DNS inverse de l’IP correspond au domaine de l’entreprise
Vérification de plage IP : croisez avec les plages IP publiées par OpenAI, Anthropic et autres sociétés IA
Recherche WHOIS : vérifiez que le bloc IP est bien enregistré auprès de l’organisation revendiquée
Analyse historique : suivez si l’IP accède régulièrement à votre site avec le même user-agent
Analyse comportementale : les vrais crawlers suivent des schémas prévisibles, les faux bots affichent souvent des comportements erratiques
La vérification IP est importante car elle vous protège contre les faux crawlers, qui peuvent être des concurrents aspirant votre contenu ou des acteurs malveillants cherchant à saturer vos serveurs sous couvert de services IA légitimes.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Détecter les crawlers IA dans les outils d’analytics
Les plateformes d’analytics traditionnelles comme Google Analytics 4 et Matomo filtrent par conception le trafic des bots, ce qui rend l’activité des crawlers IA quasiment invisible dans vos tableaux de bord standards. Cela crée un angle mort où vous ignorez la part de trafic et de bande passante consommée par les systèmes IA. Pour bien surveiller l’activité des crawlers IA, il vous faut des solutions côté serveur qui capturent les logs bruts avant tout filtrage :
ELK Stack (Elasticsearch, Logstash, Kibana) : agrégation centralisée et visualisation des logs
Splunk : analyse de logs de niveau entreprise avec alertes en temps réel
Datadog : supervision cloud native avec capacités de détection de bots
Grafana + Prometheus : stack open source pour des tableaux de bord personnalisés
Vous pouvez aussi intégrer les données des crawlers IA dans Google Data Studio via le Measurement Protocol de GA4, afin de créer des rapports personnalisés affichant le trafic IA à côté de vos statistiques classiques. Cela vous offre une vision complète de tout le trafic, pas seulement celui des visiteurs humains.
Workflow pratique d’analyse des logs
Mettre en place un workflow pratique pour la surveillance des crawlers IA nécessite de définir des métriques de référence et de les vérifier régulièrement. Commencez par collecter une semaine de données pour comprendre vos schémas de trafic crawler habituels, puis configurez une surveillance automatisée pour détecter les anomalies. Voici une check-list de surveillance quotidienne :
Revoir le nombre total de requêtes crawler et comparer à la base
Identifier tout nouveau crawler jamais vu auparavant
Vérifier les vitesses ou schémas de crawl inhabituels
Vérifier les IP des crawlers principaux
Surveiller la bande passante consommée par crawler
Alerter sur tout crawler dépassant les limites fixées
Utilisez ce script bash pour automatiser l’analyse quotidienne :
#!/bin/bash
LOG_FILE="/var/log/apache2/access.log"REPORT_DATE=$(date +%Y-%m-%d)echo "Rapport d’activité des crawlers IA - $REPORT_DATE" > crawler_report.txt
echo "========================================" >> crawler_report.txt
echo "" >> crawler_report.txt
# Compter les requêtes par crawlerecho "Requêtes par crawler :" >> crawler_report.txt
awk -F'"''{print $6}' $LOG_FILE | grep -iE "gptbot|claudebot|perplexitybot|bingbot" | sort | uniq -c | sort -rn >> crawler_report.txt
# Top IP accédant au siteecho "" >> crawler_report.txt
echo "Top 10 IPs :" >> crawler_report.txt
awk '{print $1}' $LOG_FILE | sort | uniq -c | sort -rn | head -10 >> crawler_report.txt
# Bande passante par crawlerecho "" >> crawler_report.txt
echo "Bande passante par crawler (octets) :" >> crawler_report.txt
awk -F'"''{print $6, $NF}' $LOG_FILE | grep -iE "gptbot|claudebot" | awk '{sum[$1]+=$2} END {for (crawler in sum) print crawler, sum[crawler]}' >> crawler_report.txt
mail -s "Rapport quotidien crawler" admin@example.com < crawler_report.txt
Planifiez ce script pour un lancement quotidien via cron :
09 * * * /usr/local/bin/crawler_analysis.sh
Pour la visualisation sur tableau de bord, utilisez Grafana pour créer des panels affichant les tendances de trafic crawler dans le temps, avec des visualisations séparées pour chaque crawler majeur et des alertes sur anomalies.
Contrôler l’accès des crawlers IA
Contrôler l’accès des crawlers IA commence par comprendre vos options et le niveau de contrôle dont vous avez réellement besoin. Certains propriétaires de site souhaitent tout bloquer pour protéger leur contenu, d’autres acceptent le trafic mais veulent le gérer proprement. Votre première ligne de défense est le fichier robots.txt, qui donne des instructions aux crawlers sur ce qu’ils peuvent ou non consulter. Voici comment l’utiliser :
# Bloquer tous les crawlers IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
# Autoriser certains crawlers
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
Cependant, robots.txt a de sérieuses limites : ce n’est qu’une suggestion, que les crawlers peuvent ignorer, et les acteurs malveillants n’en tiendront aucun compte. Pour un contrôle plus robuste, mettez en place un blocage côté pare-feu au niveau du serveur avec iptables ou les groupes de sécurité de votre fournisseur cloud. Vous pouvez bloquer des plages IP ou des chaînes user-agent spécifiques au niveau du serveur web avec mod_rewrite d’Apache ou des instructions if de Nginx. Pour une mise en œuvre pratique, combinez robots.txt pour les crawlers légitimes avec des règles de pare-feu pour ceux qui ne le respectent pas, et surveillez vos logs pour repérer les contrevenants.
Techniques avancées de détection
Les techniques avancées vont au-delà du simple appariement user-agent pour détecter les crawlers sophistiqués ou même le trafic usurpé. Les signatures HTTP Message (RFC 9421) permettent aux crawlers de prouver leur identité en signant leurs requêtes avec des clés privées, rendant l’usurpation quasi impossible. Certaines entreprises IA commencent à utiliser des en-têtes Signature-Agent contenant cette preuve cryptographique. Au-delà des signatures, vous pouvez analyser les schémas comportementaux qui distinguent les vrais crawlers des imposteurs : les vrais exécutent le JavaScript de façon cohérente, suivent des vitesses de crawl prévisibles, respectent les limites de débit et maintiennent des IP cohérentes. L’analyse des limitations de débit révèle les schémas suspects : un crawler qui augmente soudainement ses requêtes de 500% ou parcourt les pages dans un ordre aléatoire au lieu de suivre la structure du site est probablement malveillant. À mesure que les navigateurs IA agentiques deviennent plus sophistiqués, ils peuvent imiter le comportement humain (exécution JS, gestion cookies, referrer), ce qui nécessite des méthodes de détection affinées analysant la signature complète de la requête, et non juste la chaîne user-agent.
Stratégie de surveillance en conditions réelles
Une stratégie de surveillance complète en production nécessite d’établir des références, de détecter les anomalies et de conserver des archives détaillées. Commencez par collecter deux semaines de données pour comprendre vos schémas de trafic crawler habituels : pics horaires, vitesses de requête par crawler, bande passante consommée. Mettez en place une détection d’anomalies qui alerte si un crawler dépasse 150% de son taux de référence ou si de nouveaux crawlers apparaissent. Configurez des seuils d’alerte comme une notification immédiate si un crawler consomme plus de 30% de votre bande passante, ou si le trafic crawler total dépasse 50% du trafic global. Suivez les métriques de reporting comme le nombre total de requêtes crawler, la bande passante consommée, les crawlers uniques détectés et les requêtes bloquées. Pour les organisations soucieuses de l’utilisation de leurs données à des fins d’entraînement IA, AmICited.com propose un suivi complémentaire des citations IA qui montre exactement quels modèles IA citent votre contenu, vous donnant une vision claire de l’utilisation de vos données en aval. Appliquez cette stratégie grâce à une combinaison de logs serveur, de règles pare-feu et d’outils d’analytics pour garder une visibilité et un contrôle complets sur l’activité des crawlers IA.
Questions fréquemment posées
Quelle est la différence entre les crawlers IA et les crawlers des moteurs de recherche ?
Les crawlers des moteurs de recherche comme Googlebot indexent le contenu pour les résultats de recherche, tandis que les crawlers IA collectent des données pour entraîner de grands modèles de langage ou alimenter des moteurs de réponse IA. Les crawlers IA ont souvent une activité de crawl plus agressive et peuvent accéder à du contenu que les moteurs de recherche ignorent, ce qui en fait des sources de trafic distinctes nécessitant des stratégies de surveillance et de gestion séparées.
Les crawlers IA peuvent-ils usurper leur chaîne user-agent ?
Oui, les chaînes user-agent sont très faciles à usurper car elles ne sont que des en-têtes texte dans les requêtes HTTP. C'est pourquoi la vérification IP est essentielle : les véritables crawlers IA proviennent de plages IP spécifiques appartenant à leurs entreprises, rendant la vérification basée sur l'adresse IP bien plus fiable que le simple appariement user-agent.
Comment puis-je bloquer des crawlers IA spécifiques sur mon site ?
Vous pouvez utiliser le fichier robots.txt pour suggérer un blocage (même si les crawlers peuvent l’ignorer), ou mettre en place un blocage au niveau du pare-feu sur le serveur via iptables, Apache mod_rewrite ou des règles Nginx. Pour un contrôle maximal, combinez robots.txt pour les crawlers légitimes avec des règles de pare-feu IP pour ceux qui ne respectent pas robots.txt.
Pourquoi mes outils d'analytics n'affichent-ils pas le trafic des crawlers IA ?
Google Analytics 4, Matomo et des plateformes similaires sont conçus pour filtrer le trafic des bots, rendant les crawlers IA invisibles dans les tableaux de bord standards. Vous avez besoin de solutions côté serveur comme ELK Stack, Splunk ou Datadog pour capturer les données brutes des logs et visualiser l’intégralité de l’activité des crawlers.
Quel est l'impact des crawlers IA sur la bande passante du serveur ?
Les crawlers IA peuvent consommer une bande passante significative : certains sites rapportent que 30 à 50% du trafic total provient de crawlers. ChatGPT-User à lui seul crawl à 2 400 pages/heure, et avec plusieurs crawlers IA actifs en même temps, les coûts de bande passante peuvent augmenter considérablement sans surveillance et contrôle appropriés.
À quelle fréquence dois-je surveiller mes journaux serveur pour détecter une activité IA ?
Mettez en place une surveillance automatisée quotidienne à l’aide de tâches cron pour analyser les logs et générer des rapports. Pour les applications critiques, implémentez une alerte en temps réel qui vous notifie immédiatement si un crawler dépasse les taux de base de 150% ou consomme plus de 30% de la bande passante.
La vérification IP suffit-elle pour authentifier les crawlers IA ?
La vérification IP est bien plus fiable que l’appariement user-agent, mais elle n’est pas infaillible : l’usurpation IP est techniquement possible. Pour une sécurité maximale, combinez la vérification IP avec les signatures HTTP Message de la RFC 9421, qui fournissent une preuve cryptographique d'identité presque impossible à usurper.
Que faire si je détecte une activité suspecte de crawler ?
Commencez par vérifier l'adresse IP avec les plages officielles de la société revendiquée. Si cela ne correspond pas, bloquez l’IP au niveau du pare-feu. Si cela correspond mais que le comportement semble anormal, appliquez une limitation de débit ou bloquez temporairement le crawler le temps de l’enquête. Conservez toujours des logs détaillés pour l’analyse et pour référence future.
Suivez comment les systèmes IA référencent votre contenu
AmICited surveille comment les systèmes IA comme ChatGPT, Perplexity et Google AI Overviews citent votre marque et votre contenu. Obtenez des informations en temps réel sur votre visibilité auprès des IA et protégez vos droits sur vos contenus.
Comment identifier les crawlers IA dans les logs serveur : Guide complet de détection
Découvrez comment identifier et surveiller les crawlers IA comme GPTBot, PerplexityBot et ClaudeBot dans vos logs serveur. Découvrez les chaînes user-agent, les...
Le guide complet pour bloquer (ou autoriser) les crawlers IA
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide...
Suivi de l'activité des crawlers IA : Guide complet de surveillance
Apprenez à suivre et surveiller l'activité des crawlers IA sur votre site web à l'aide des logs serveurs, d'outils et de bonnes pratiques. Identifiez GPTBot, Cl...
12 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.