Query Fanout
Découvrez comment fonctionne la diffusion de requête dans les systèmes de recherche IA. Comprenez comment l’IA élargit une requête unique en plusieurs sous-requ...
12 min de lecture
Découvrez comment les systèmes d’IA modernes comme Google AI Mode et ChatGPT décomposent une seule requête en plusieurs recherches. Apprenez les mécanismes de diffusion des requêtes, les implications pour la visibilité dans l’IA et l’optimisation de la stratégie de contenu.
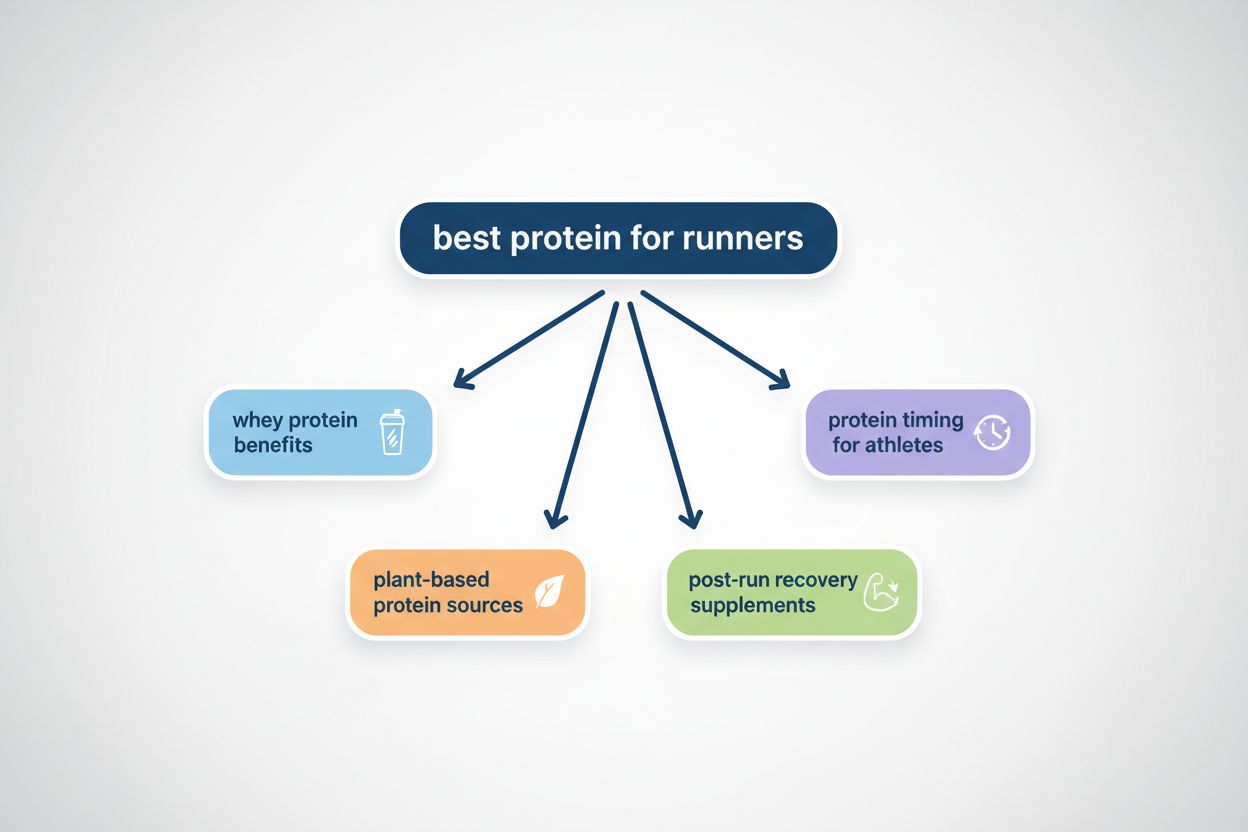
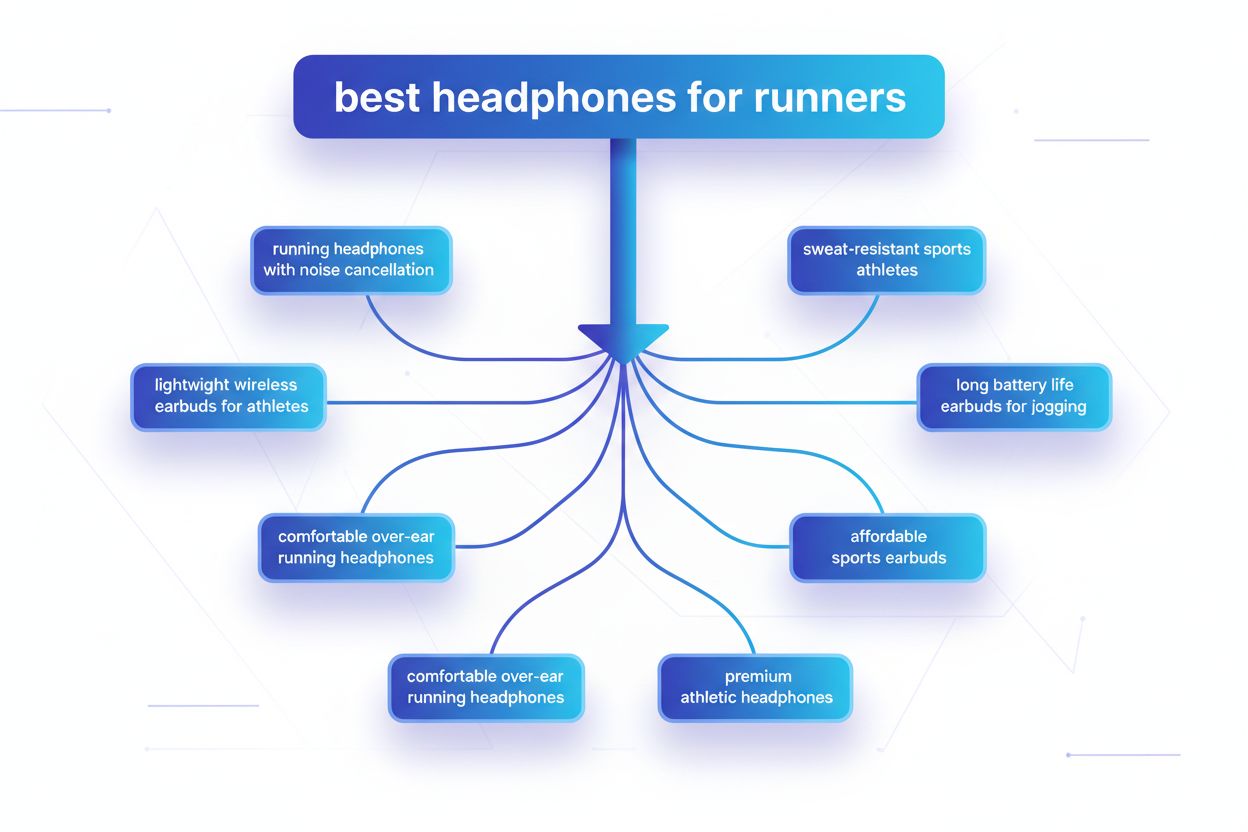
La diffusion des requêtes est le processus par lequel les grands modèles de langage divisent automatiquement une requête utilisateur unique en plusieurs sous-requêtes pour recueillir des informations plus complètes à partir de sources diverses. Plutôt que d’exécuter une seule recherche, les systèmes d’IA modernes décomposent l’intention de l’utilisateur en 5 à 15 requêtes connexes qui saisissent différents angles, interprétations et aspects de la demande d’origine. Par exemple, lorsqu’un utilisateur recherche « meilleurs écouteurs pour les coureurs » dans le mode IA de Google, le système génère environ 8 recherches différentes, y compris des variantes telles que « écouteurs de course avec réduction de bruit », « écouteurs sans fil légers pour athlètes », « écouteurs de sport résistants à la transpiration » et « écouteurs avec grande autonomie pour le jogging ». Cela représente une rupture fondamentale avec la recherche traditionnelle, où une seule chaîne de requête est comparée à un index. Les principales caractéristiques de la diffusion des requêtes incluent :
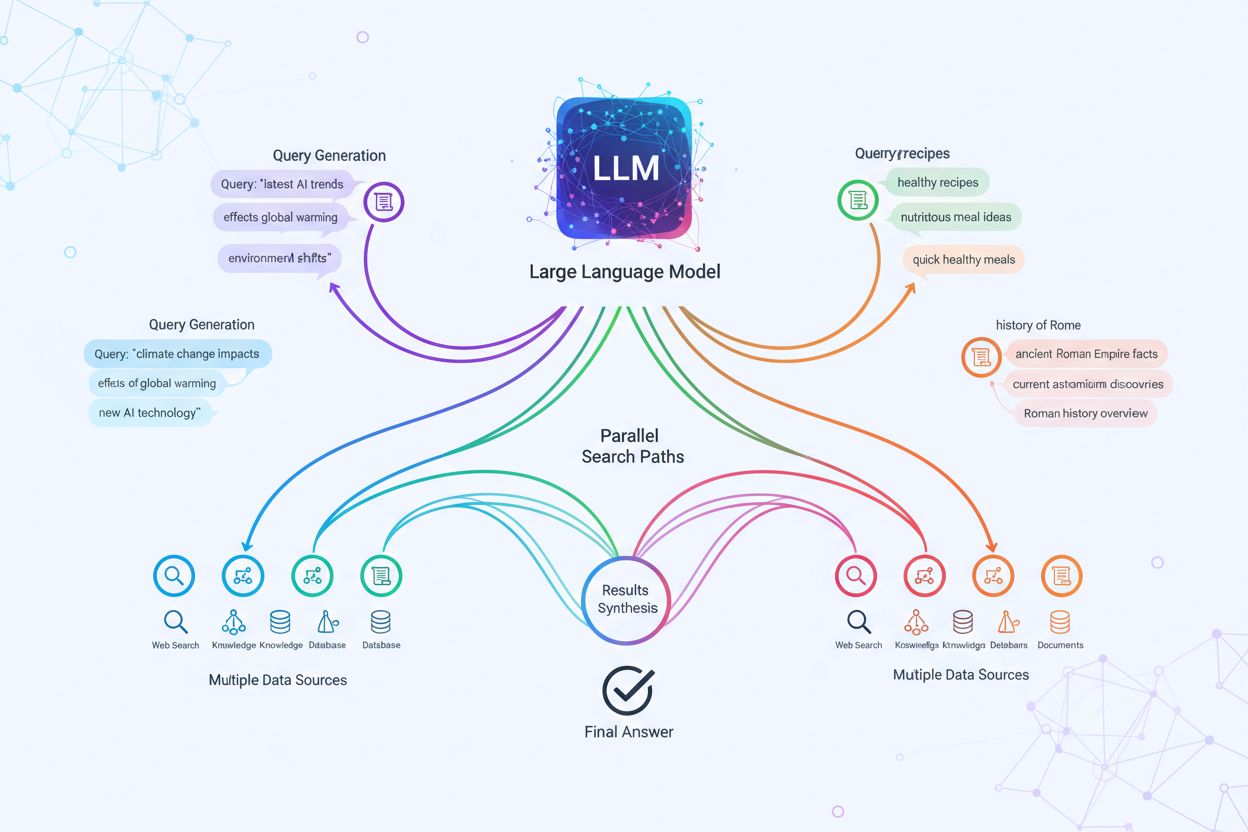
La mise en œuvre technique de la diffusion des requêtes repose sur des algorithmes de traitement du langage naturel sophistiqués qui analysent la complexité de la requête et génèrent des variantes sémantiquement pertinentes. Les LLM produisent huit principaux types de variantes de requêtes : requêtes équivalentes (reformulation à signification identique), requêtes de suivi (exploration de sujets connexes), requêtes de généralisation (élargissement du champ), requêtes de spécification (ciblage plus précis), requêtes de canonisation (standardisation de la terminologie), requêtes de traduction (conversion entre domaines), requêtes d’entaillement (exploration des implications logiques) et requêtes de clarification (désambiguïsation des termes ambigus). Le système utilise des modèles neuronaux pour évaluer la complexité de la requête—mesurant des facteurs tels que le nombre d’entités, la densité des relations et l’ambiguïté sémantique—pour déterminer combien de sous-requêtes générer. Une fois générées, ces requêtes s’exécutent en parallèle sur plusieurs systèmes de récupération, y compris des robots d’indexation web, des graphes de connaissances (comme le Knowledge Graph de Google), des bases de données structurées et des index de similarité vectorielle. Les différentes plateformes mettent en œuvre cette architecture avec des niveaux de transparence et de sophistication variables :
| Plateforme | Mécanisme | Transparence | Nombre de requêtes | Méthode de classement |
|---|---|---|---|---|
| Google AI Mode | Diffusion explicite avec requêtes visibles | Élevée | 8-12 requêtes | Classement multi-étapes |
| Microsoft Copilot | Orchestrateur Bing itératif | Moyenne | 5-8 requêtes | Score de pertinence |
| Perplexity | Récupération hybride avec classement multi-étapes | Élevée | 6-10 requêtes | Basé sur la citation |
| ChatGPT | Génération implicite de requêtes | Faible | Inconnu | Pondération interne |
Les requêtes complexes subissent une décomposition sophistiquée où le système les divise en entités, attributs et relations constitutives avant de générer des variantes. Lors du traitement d’une requête telle que « écouteurs Bluetooth avec conception circum-auriculaire confortable et batterie longue durée adaptée aux coureurs », le système procède à une compréhension centrée sur l’entité en identifiant les entités clés (écouteurs Bluetooth, coureurs) et en extrayant les attributs essentiels (confortable, circum-auriculaire, batterie longue durée). Le processus de décomposition exploite les graphes de connaissances pour comprendre comment ces entités sont liées entre elles et quelles variations sémantiques existent—en reconnaissant que « écouteurs circum-auriculaires » et « casques circumauraux » sont équivalents, ou que « batterie longue durée » peut signifier plus de 8 h, plus de 24 h ou plusieurs jours selon le contexte. Le système identifie les concepts associés via des mesures de similarité sémantique, comprenant que les requêtes sur la « résistance à la transpiration » et la « résistance à l’eau » sont liées mais distinctes, et que les « coureurs » pourraient aussi s’intéresser aux « cyclistes », « adeptes de la salle de sport » ou « athlètes de plein air ». Cette décomposition permet de générer des sous-requêtes ciblées qui captent différentes facettes de l’intention utilisateur plutôt que de simplement reformuler la demande initiale.
La diffusion des requêtes renforce fondamentalement la composante récupération des cadres RAG (Retrieval-Augmented Generation) en permettant une collecte de preuves plus riche et diversifiée avant la phase de génération. Dans les pipelines RAG traditionnels, une seule requête est intégrée et comparée à une base de données vectorielle, ce qui peut faire manquer des informations pertinentes utilisant une terminologie ou une structuration conceptuelle différente. La diffusion des requêtes pallie cette limitation en exécutant plusieurs opérations de récupération en parallèle, chacune optimisée pour une variante de requête spécifique, ce qui permet de collecter des preuves sous différents angles et à partir de sources variées. Cette récupération parallèle réduit considérablement le risque d’hallucination en ancrant les réponses des LLM dans des sources indépendantes multiples—lorsque le système récupère des informations sur les « écouteurs circum-auriculaires », « conceptions circumaurales » et « casques grand format » séparément, il peut recouper et valider les affirmations à travers ces divers résultats. L’architecture intègre le découpage sémantique et la récupération par passage, où les documents sont divisés en unités sémantiques significatives plutôt qu’en segments de longueur fixe, permettant au système de récupérer les passages les plus pertinents quel que soit la structure du document. En combinant les preuves issues de multiples récupérations de sous-requêtes, les systèmes RAG produisent des réponses plus complètes, mieux sourcées et moins sujettes aux sorties erronées confiante qui affectent les approches à requête unique.
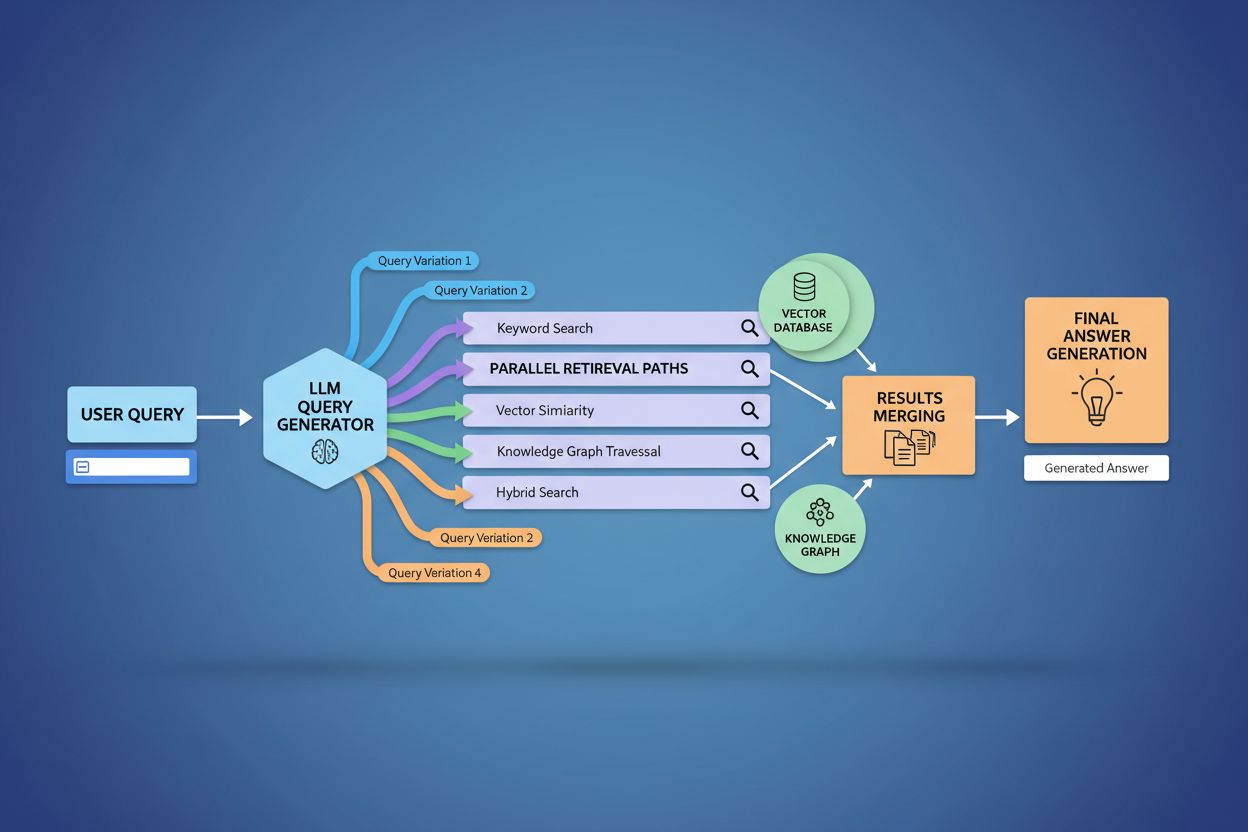
Le contexte utilisateur et les signaux de personnalisation façonnent dynamiquement la façon dont la diffusion des requêtes élargit chaque demande, créant des chemins de récupération personnalisés qui peuvent diverger fortement d’un utilisateur à l’autre. Le système intègre plusieurs dimensions de personnalisation, incluant les attributs de l’utilisateur (emplacement géographique, profil démographique, rôle professionnel), les schémas d’historique de recherche (requêtes précédentes et résultats cliqués), les signaux temporels (heure de la journée, saison, événements actuels) et le contexte de la tâche (recherche, achat, apprentissage). Par exemple, une requête sur les « meilleurs écouteurs pour les coureurs » s’étendra différemment pour un athlète d’ultramarathon de 22 ans au Kenya que pour un joggeur amateur de 45 ans au Minnesota—l’expansion du premier mettra l’accent sur la durabilité et la résistance à la chaleur tandis que celle du second insistera sur le confort et l’accessibilité. Cependant, cette personnalisation introduit le problème de « transformation à deux points » où le système traite les requêtes actuelles comme des variations de schémas historiques, pouvant limiter l’exploration et renforcer les préférences existantes. La personnalisation peut créer involontairement des bulles de filtre où l’expansion des requêtes favorise systématiquement les sources et perspectives alignées sur le comportement passé de l’utilisateur, limitant l’exposition à des points de vue alternatifs ou à des informations émergentes. Comprendre ces mécanismes de personnalisation est crucial pour les créateurs de contenu, car un même contenu pourra ou non être récupéré selon le profil et l’historique de l’utilisateur.
Les principales plateformes IA mettent en œuvre la diffusion des requêtes avec des architectures, des niveaux de transparence et des approches stratégiques très différents, reflétant leur infrastructure et leur philosophie de conception sous-jacentes. Le mode IA de Google utilise une diffusion explicite et visible, où les utilisateurs peuvent voir les 8-12 sous-requêtes générées affichées à côté des résultats, lançant des centaines de recherches individuelles sur l’index de Google pour rassembler des preuves complètes. Microsoft Copilot adopte une approche itérative propulsée par l’Orchestrateur Bing, qui génère séquentiellement 5 à 8 requêtes, affinant l’ensemble des requêtes à partir des résultats intermédiaires avant d’exécuter la phase finale de récupération. Perplexity met en place une stratégie hybride de récupération avec classement multi-étapes, générant 6 à 10 requêtes exécutées à la fois sur des sources web et sur son propre index, puis appliquant des algorithmes de classement sophistiqués pour faire remonter les passages les plus pertinents. L’approche de ChatGPT reste en grande partie opaque pour les utilisateurs, la génération des requêtes se produisant implicitement dans le traitement interne du modèle, ce qui rend difficile de savoir combien de requêtes sont générées ou comment elles sont exécutées. Ces différences architecturales ont des implications majeures pour la transparence, la reproductibilité et la capacité des créateurs de contenu à optimiser pour chaque plateforme :
| Aspect | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Visibilité des requêtes | Entièrement visible pour les utilisateurs | Partiellement visible | Visible dans les citations | Cachée |
| Modèle d’exécution | Lot parallèle | Séquentiel itératif | Parallèle avec classement | Interne/implicite |
| Diversité des sources | Index Google uniquement | Bing + propriétaire | Web + index propriétaire | Données d’entraînement + plugins |
| Transparence des citations | Élevée | Moyenne | Très élevée | Faible |
| Options de personnalisation | Limitées | Moyennes | Élevées | Moyennes |
La diffusion des requêtes introduit plusieurs défis techniques et sémantiques qui peuvent conduire le système à s’écarter de l’intention réelle de l’utilisateur, en récupérant des informations techniquement liées mais finalement peu utiles. Une dérive sémantique se produit lors de l’expansion générative, lorsque le LLM crée des variantes de requêtes qui, bien que sémantiquement proches de l’original, en modifient progressivement le sens—une requête sur les « meilleurs écouteurs pour les coureurs » peut s’élargir vers « écouteurs sportifs », puis « équipement de sport », puis « matériel de fitness », s’éloignant peu à peu de l’intention initiale. Le système doit distinguer l’intention latente (ce que l’utilisateur pourrait vouloir s’il en savait plus) et l’intention explicite (ce qui est effectivement demandé), et une expansion trop agressive peut confondre ces catégories, récupérant des informations sur des produits jamais envisagés par l’utilisateur. Une divergence d’expansion itérative survient lorsque chaque requête générée engendre de nouvelles sous-requêtes, créant un arbre de recherches de plus en plus tangentielles qui au final s’éloignent fortement de la demande de départ. Les bulles de filtre et les biais de personnalisation font que deux utilisateurs posant la même question reçoivent des expansions systématiquement différentes selon leur profil, créant potentiellement des chambres d’écho où chaque expansion renforce les préférences existantes de l’utilisateur. Des scénarios réels illustrent ces écueils : un utilisateur cherchant des « écouteurs abordables » verra sa requête étendue à des marques de luxe selon son historique de navigation, ou une requête sur des « écouteurs pour malentendants » pourra être élargie à des produits d’accessibilité générale, diluant la spécificité de la demande initiale.
L’essor de la diffusion des requêtes modifie fondamentalement la stratégie de contenu, qui passe de l’optimisation pour le classement par mot-clé à la visibilité basée sur la citation, obligeant les créateurs à repenser la structuration et la présentation de l’information. Le SEO traditionnel se concentrait sur le classement pour des mots-clés spécifiques ; la recherche pilotée par l’IA privilégie l’obtention de la citation comme source d’autorité à travers de multiples variantes de requêtes et contextes. Les créateurs de contenu doivent adopter des stratégies atomiques et riches en entités, où l’information est structurée autour d’entités spécifiques (produits, concepts, personnes) avec un balisage sémantique riche permettant aux systèmes IA d’extraire et de citer les passages pertinents. Le regroupement thématique et l’autorité sur les sujets deviennent essentiels—plutôt que de produire des articles isolés sur des mots-clés individuels, le contenu performant assure une couverture complète de domaines thématiques, augmentant la probabilité d’être récupéré dans les diverses variantes générées par la diffusion. La mise en œuvre de schémas structurés et de données structurées permet aux IA de mieux comprendre la structure du contenu et d’en extraire plus efficacement l’information pertinente, augmentant ainsi la probabilité d’être cité. Les métriques de réussite évoluent du suivi des classements de mots-clés vers la surveillance de la fréquence des citations via des outils comme AmICited.com, qui suit la fréquence d’apparition des marques et contenus dans les réponses IA. Les bonnes pratiques incluent : la création de contenus complets et bien sourcés abordant plusieurs angles d’un sujet ; l’intégration de balisage de schéma riche (Organization, Product, Article) ; la construction d’une autorité thématique via des contenus interconnectés ; et l’audit régulier de la présence de son contenu dans les réponses IA sur différentes plateformes et segments d’utilisateurs.
La diffusion des requêtes représente le changement architectural le plus important dans la recherche depuis l’indexation mobile-first, restructurant en profondeur la manière dont l’information est découverte et présentée aux utilisateurs. L’évolution vers une infrastructure sémantique signifie que les systèmes de recherche fonctionneront de plus en plus sur le sens plutôt que sur les mots-clés, la diffusion des requêtes devenant le mécanisme par défaut de la récupération d’information plutôt qu’un enrichissement optionnel. Les métriques de citation deviennent aussi importantes que les backlinks pour déterminer la visibilité et l’autorité du contenu—un contenu cité dans 50 réponses IA différentes pèse davantage qu’un contenu classé #1 pour un seul mot-clé. Ce changement crée à la fois des défis et des opportunités : les outils SEO traditionnels de suivi des classements par mot-clé deviennent moins pertinents, nécessitant de nouveaux cadres de mesure axés sur la fréquence des citations, la diversité des sources et l’apparition dans différentes variantes de requêtes. Cependant, cette évolution offre aussi aux marques l’opportunité d’optimiser spécifiquement pour la recherche IA en construisant un contenu structuré et faisant autorité qui sert de source fiable à travers de multiples interprétations de requêtes. L’avenir impliquera probablement une plus grande transparence autour des mécanismes de diffusion des requêtes, les plateformes rivalisant sur la clarté des raisons derrière leur approche multi-requêtes, et les créateurs de contenu développant des stratégies spécialisées pour maximiser leur visibilité à travers les multiples chemins de récupération créés par la diffusion.
La diffusion des requêtes est le processus automatisé par lequel les systèmes d'IA décomposent une seule requête utilisateur en plusieurs sous-requêtes et les exécutent en parallèle, tandis que l'expansion des requêtes fait traditionnellement référence à l'ajout de termes associés à une seule requête. La diffusion des requêtes est plus sophistiquée, générant des variantes sémantiquement diverses qui captent différents angles et interprétations de l'intention d'origine.
La diffusion des requêtes a un impact significatif sur la visibilité car votre contenu doit être découvrable à travers de multiples variantes de requêtes, et pas seulement la requête exacte de l'utilisateur. Un contenu qui aborde différents angles, utilise une terminologie variée et est bien structuré avec du balisage de schéma a plus de chances d'être récupéré et cité dans les diverses sous-requêtes générées par la diffusion.
Toutes les principales plateformes de recherche IA utilisent des mécanismes de diffusion des requêtes : Google AI Mode utilise une diffusion explicite et visible (8-12 requêtes) ; Microsoft Copilot utilise une diffusion itérative via Bing Orchestrator ; Perplexity implémente une récupération hybride avec classement multi-étapes ; et ChatGPT utilise une génération implicite de requêtes. Chaque plateforme l'implémente différemment mais toutes décomposent les requêtes complexes en plusieurs recherches.
Oui. Optimisez en créant du contenu atomique et riche en entités structuré autour de concepts spécifiques ; en implémentant un balisage de schéma complet ; en développant une autorité thématique grâce à du contenu interconnecté ; en utilisant une terminologie claire et variée ; et en abordant plusieurs angles d'un sujet. Des outils comme AmICited.com vous aident à surveiller comment votre contenu apparaît à travers différentes décompositions de requêtes.
La diffusion des requêtes augmente la latence car plusieurs requêtes sont exécutées en parallèle, mais les systèmes modernes atténuent cela grâce au traitement parallèle. Alors qu'une seule requête peut prendre 200 ms, l'exécution de 8 requêtes en parallèle ajoute généralement seulement 300 à 500 ms de latence totale grâce à l'exécution simultanée. Le compromis en vaut la peine pour améliorer la qualité des réponses.
La diffusion des requêtes renforce la génération augmentée par récupération (RAG) en permettant une collecte de preuves plus riche. Au lieu de récupérer des documents pour une seule requête, la diffusion récupère des preuves pour plusieurs variantes de requêtes en parallèle, offrant au LLM un contexte plus diversifié et complet pour générer des réponses précises et réduire le risque d'hallucination.
La personnalisation façonne la manière dont les requêtes sont décomposées en fonction des attributs de l'utilisateur (emplacement, historique, démographie), des signaux temporels et du contexte de la tâche. La même requête s'élargit différemment selon les utilisateurs, créant des chemins de récupération personnalisés. Cela peut améliorer la pertinence mais crée aussi des bulles de filtre où les utilisateurs voient systématiquement des résultats différents selon leur profil.
La diffusion des requêtes représente le changement le plus significatif dans la recherche depuis l'indexation mobile-first. Les métriques traditionnelles de classement par mot-clé deviennent moins pertinentes car la même requête s'élargit différemment selon les utilisateurs. Les professionnels du SEO doivent déplacer leur attention du classement par mot-clé vers la visibilité basée sur la citation, la structure du contenu et l'optimisation des entités pour réussir dans la recherche pilotée par l'IA.
Comprenez comment votre marque apparaît sur les plateformes de recherche IA lorsque les requêtes sont élargies et décomposées. Suivez les citations et mentions dans les réponses générées par l'IA.
Découvrez comment fonctionne la diffusion de requête dans les systèmes de recherche IA. Comprenez comment l’IA élargit une requête unique en plusieurs sous-requ...
Découvrez les modèles de requête IA - des structures et formulations récurrentes utilisées par les utilisateurs lorsqu'ils posent des questions aux assistants I...
Maîtrisez l'optimisation des requêtes IA en comprenant les requêtes factuelles, comparatives, instructionnelles, créatives et analytiques. Découvrez des stratég...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.