Les citations Wikipédia comme données d’entraînement pour l’IA : L’effet de ricochet
Découvrez comment les citations Wikipédia façonnent les données d’entraînement de l’IA et créent un effet de ricochet au sein des LLM. Comprenez pourquoi votre présence Wikipédia compte pour les mentions de l’IA et la perception de votre marque.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
La fondation : le rôle de Wikipédia dans l’entraînement des LLM
Wikipédia est devenue le jeu de données d’entraînement fondamental pour pratiquement tous les grands modèles de langage de grande taille existants aujourd’hui — de ChatGPT d’OpenAI et Gemini de Google à Claude d’Anthropic et le moteur de recherche Perplexity. Dans de nombreux cas, Wikipédia constitue la source unique la plus importante de texte structuré et de haute qualité dans les jeux de données d’entraînement de ces systèmes d’IA, représentant souvent 5 à 15 % du corpus total selon le modèle. Cette domination découle des caractéristiques uniques de Wikipédia : sa politique de neutralité de point de vue, sa rigoureuse vérification communautaire des faits, son formatage structuré et sa licence librement accessible en font une ressource sans égal pour enseigner aux systèmes d’IA comment raisonner, citer des sources et communiquer avec précision. Pourtant, cette relation a fondamentalement transformé le rôle de Wikipédia dans l’écosystème numérique — ce n’est plus seulement une destination pour les lecteurs humains en quête d’information, mais bien l’épine dorsale invisible qui alimente les IA conversationnelles auxquelles des millions de personnes s’adressent chaque jour. Comprendre ce lien met en lumière un effet de ricochet critique : la qualité, les biais et les lacunes de Wikipédia façonnent directement les capacités et les limites des systèmes d’IA qui servent désormais d’intermédiaires à la façon dont des milliards de personnes accèdent et comprennent l’information.
Comment les LLM utilisent réellement les données Wikipédia
Lorsque les grands modèles de langage traitent les informations pendant l’entraînement, ils ne considèrent pas toutes les sources comme équivalentes — Wikipédia occupe une position privilégiée dans leur hiérarchie décisionnelle. Lors du processus de reconnaissance d’entités, les LLM identifient les faits et concepts clés, puis les recoupent avec plusieurs sources pour établir des scores de crédibilité. Wikipédia fonctionne comme une « vérification de l’autorité principale » dans ce processus grâce à son historique d’édition transparent, ses mécanismes de vérification communautaire et sa politique de neutralité, qui signalent collectivement la fiabilité aux systèmes d’IA. L’effet multiplicateur de crédibilité amplifie cet avantage : lorsque l’information est présente de façon constante sur Wikipédia, dans des graphes de connaissances structurés tels que Google Knowledge Graph et Wikidata, ainsi que dans des sources académiques, les LLM attribuent une confiance exponentiellement plus élevée à cette information. Ce système de pondération explique pourquoi Wikipédia reçoit un traitement particulier lors de l’entraînement — elle sert à la fois de source directe de connaissances et de couche de validation pour les faits extraits d’autres sources. Le résultat est que les LLM ont appris à considérer Wikipédia non seulement comme un point de données parmi d’autres, mais comme une référence fondamentale qui confirme ou remet en question les informations issues de sources moins vérifiées.
Pondération de la crédibilité des sources dans l’entraînement des LLM
Type de source
Poids de crédibilité
Raison
Traitement IA
Wikipédia
Très élevé
Neutre, édité par la communauté, vérifié
Référence principale
Site web d’entreprise
Moyen
Auto-promotionnel
Source secondaire
Articles de presse
Élevé
Tiers, mais potentiellement biaisé
Source de corroboration
Graphes de connaissances
Très élevé
Structuré, agrégé
Multiplicateur d’autorité
Réseaux sociaux
Faible
Non vérifié, promotionnel
Poids minimal
Sources académiques
Très élevé
Revu par des pairs, autoritaire
Haute confiance
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
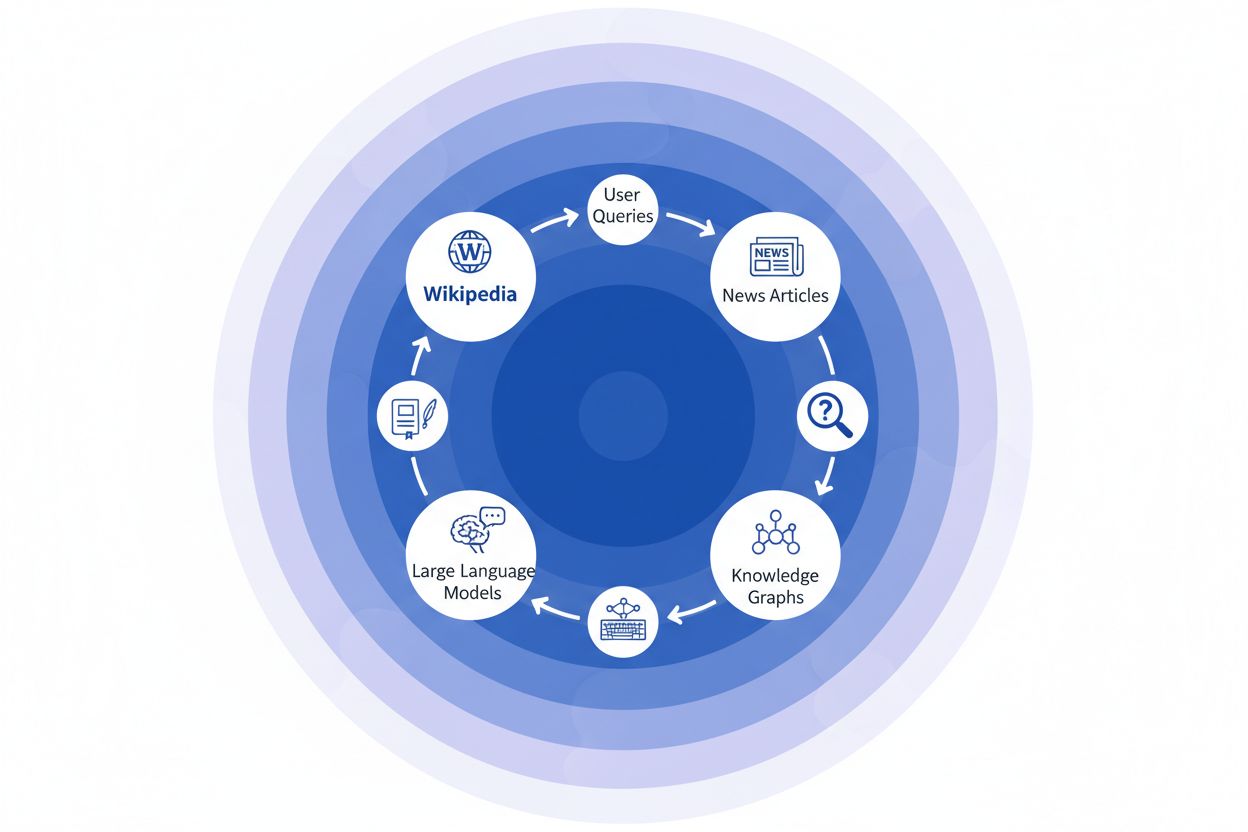
La chaîne des citations : comment Wikipédia influence les réponses de l’IA
Lorsqu’une organisation médiatique cite Wikipédia comme source, elle crée ce que nous appelons la « chaîne des citations » — un mécanisme en cascade où la crédibilité se multiplie à travers plusieurs couches de l’infrastructure informationnelle. Un journaliste écrivant sur la science du climat peut référencer un article Wikipédia sur le réchauffement climatique, qui lui-même cite des études évaluées par des pairs ; cet article de presse est ensuite indexé par les moteurs de recherche et intégré dans des graphes de connaissances, qui sont ensuite utilisés pour entraîner des grands modèles de langage que des millions d’utilisateurs interrogent chaque jour. Cela crée une boucle de rétroaction puissante : Wikipédia → Graphe de connaissances → LLM → Utilisateur, où la manière dont l’article Wikipédia original est présenté peut subtilement façonner la façon dont les systèmes d’IA présentent l’information aux utilisateurs finaux, souvent sans que ceux-ci ne réalisent que l’information provient d’une encyclopédie collaborative. Prenons un exemple concret : si l’article Wikipédia sur un traitement pharmaceutique met l’accent sur certains essais cliniques tout en en minimisant d’autres, ce choix éditorial se répercute dans la couverture médiatique, s’intègre dans les graphes de connaissances et finit par influencer la façon dont ChatGPT ou des modèles similaires répondent aux questions des patients sur les options de traitement. Cet « effet de ricochet » signifie que les choix éditoriaux de Wikipédia n’influencent pas seulement les lecteurs qui visitent directement le site — ils façonnent fondamentalement le paysage informationnel dont les systèmes d’IA s’inspirent et qu’ils restituent à des milliards d’utilisateurs. La chaîne des citations transforme ainsi Wikipédia d’une destination de référence en une couche invisible mais influente de la filière d’entraînement de l’IA, où l’exactitude et les biais à la source peuvent s’amplifier à l’échelle de tout l’écosystème.
L’effet de ricochet : conséquences en aval
L’effet de ricochet dans l’écosystème Wikipédia-vers-IA est sans doute la dynamique la plus cruciale à comprendre pour les marques et organisations. Une simple modification sur Wikipédia ne change pas qu’une seule source — elle se propage à travers un réseau interconnecté de systèmes d’IA, chacun puisant dans et amplifiant l’information de manière à multiplier son impact de façon exponentielle. Lorsqu’une inexactitude apparaît sur une page Wikipédia, elle ne reste pas isolée ; elle se diffuse dans tout le paysage IA, façonnant la façon dont votre marque est décrite, comprise et présentée à des millions d’utilisateurs chaque jour. Cet effet multiplicateur signifie qu’investir dans l’exactitude sur Wikipédia n’est pas seulement une question d’un seul canal — il s’agit de maîtriser votre narration à travers tout l’écosystème de l’IA générative. Pour les professionnels du PR digital et de la gestion de marque, cette réalité change fondamentalement la façon de prioriser les ressources et l’attention.
Effets de ricochet clés à surveiller :
La qualité de la page Wikipédia affecte directement la façon dont les systèmes d’IA décrivent votre marque — Un contenu Wikipédia de mauvaise qualité devient la base de la manière dont ChatGPT, Gemini, Claude et d’autres systèmes d’IA caractérisent votre organisation
Une seule citation Wikipédia influence les graphes de connaissances, qui influencent les aperçus IA — Les citations transitent par l’infrastructure de connaissances de Google et impactent directement la façon dont l’information apparaît dans les résumés générés par l’IA
Une information inexacte sur Wikipédia se propage dans tout l’écosystème IA — Une fois intégrée dans les données d’entraînement, la désinformation devient exponentiellement plus difficile à corriger sur plusieurs plateformes
Une présence positive sur Wikipédia s’amplifie sur toutes les grandes plateformes IA — Une page Wikipédia bien entretenue crée un message cohérent et autoritaire sur ChatGPT, Gemini, Claude, Perplexity et les systèmes d’IA émergents
Les modifications Wikipédia ont des effets retardés mais cumulatifs sur l’entraînement IA — Les changements effectués aujourd’hui influencent les sorties des modèles IA pendant des mois voire des années, à mesure que l’information circule dans les processus de réentraînement
Le ricochet s’étend à Google AI Overviews, aux extraits optimisés et aux panneaux de connaissances — Wikipédia sert de source autoritaire alimentant les résultats de recherche générés par l’IA de Google et les affichages de données structurées
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Le défi de la durabilité de Wikipédia : une menace pour l’écosystème
Des recherches récentes de l’étude IUP menée par Vetter et al. ont mis en lumière une vulnérabilité critique de notre infrastructure IA : la durabilité de Wikipédia en tant que ressource d’entraînement est de plus en plus menacée par la technologie même qu’elle contribue à alimenter. À mesure que les grands modèles de langage prolifèrent et sont entraînés sur des ensembles de données toujours plus vastes, comprenant du contenu généré par d’autres LLM, le domaine fait face à un problème croissant d’« effondrement du modèle » où les productions artificielles commencent à contaminer le bassin de données d’entraînement, dégradant la qualité des modèles au fil des générations. Ce phénomène est particulièrement aigu du fait que Wikipédia — une encyclopédie collaborative fondée sur l’expertise humaine et le bénévolat — est devenue un pilier fondamental pour l’entraînement des systèmes d’IA avancés, souvent sans attribution explicite ni compensation pour ses contributeurs. Les implications éthiques sont profondes : alors que les entreprises d’IA extraient de la valeur de la connaissance librement partagée sur Wikipédia tout en inondant l’écosystème informationnel de contenus synthétiques, les mécanismes d’incitation qui ont permis à la communauté bénévole de Wikipédia de perdurer plus de vingt ans subissent une pression sans précédent. Sans intervention délibérée pour préserver le contenu généré par l’humain comme ressource distincte et protégée, nous risquons de créer une boucle de rétroaction où le texte généré par l’IA remplace progressivement le savoir humain authentique, minant ainsi la fondation même sur laquelle reposent les modèles de langage modernes. La durabilité de Wikipédia n’est donc pas seulement une question pour l’encyclopédie elle-même, mais un enjeu critique pour tout l’écosystème de l’information et la viabilité future des systèmes d’IA dépendant du savoir humain authentique.
Surveiller votre présence Wikipédia : où intervient AmICited
À mesure que les systèmes d’intelligence artificielle s’appuient de plus en plus sur Wikipédia comme source de connaissance fondamentale, surveiller la façon dont votre marque apparaît dans ces réponses générées par l’IA est devenu essentiel pour les organisations modernes. AmICited.com est spécialisé dans le suivi des citations Wikipédia à mesure qu’elles se répercutent dans les systèmes d’IA, offrant aux marques une visibilité sur la manière dont leur présence Wikipédia se traduit en mentions et recommandations IA. Tandis que des outils alternatifs tels que FlowHunt.io proposent des capacités de veille web généraliste, AmICited se concentre spécifiquement sur la chaîne de citations Wikipédia-vers-IA, capturant le moment précis où les systèmes d’IA se réfèrent à votre entrée Wikipédia et l’impact de cette référence sur leurs réponses. Comprendre ce lien est crucial car les citations Wikipédia pèsent lourdement dans les données d’entraînement et la génération des réponses IA — une présence Wikipédia bien entretenue n’informe pas seulement les lecteurs humains, elle façonne aussi la perception et la présentation de votre marque par les systèmes d’IA auprès de millions d’utilisateurs. En surveillant vos mentions Wikipédia via AmICited, vous obtenez des informations exploitables sur votre empreinte IA, vous permettant d’optimiser votre présence Wikipédia en pleine connaissance de son impact en aval sur la découverte par IA et la perception de la marque.
Questions fréquemment posées
Wikipédia est-il vraiment utilisé pour entraîner chaque LLM ?
Oui, chaque LLM majeur, y compris ChatGPT, Gemini, Claude et Perplexity, inclut Wikipédia dans ses données d’entraînement. Wikipédia est souvent la plus grande source unique d’informations structurées et vérifiées dans les jeux de données d’entraînement des LLM, représentant généralement 5 à 15 % du corpus total selon le modèle.
Comment Wikipédia influence-t-il ce que les systèmes d’IA disent de ma marque ?
Wikipédia sert de point de contrôle de crédibilité pour les systèmes d’IA. Lorsqu’un LLM génère des informations sur votre marque, il accorde plus de poids à la description de Wikipédia qu’à d’autres sources, faisant de votre page Wikipédia une influence critique sur la façon dont vous êtes représenté dans ChatGPT, Gemini, Claude et d’autres plateformes.
Qu’est-ce que l’« effet de ricochet » dans le contexte de Wikipédia et de l’IA ?
L’effet de ricochet fait référence à la façon dont une simple citation ou une modification sur Wikipédia engendre des conséquences en aval dans tout l’écosystème IA. Un changement sur Wikipédia peut influencer les graphes de connaissances, qui eux-mêmes influencent les aperçus IA, qui à leur tour influencent la façon dont plusieurs systèmes d’IA décrivent votre marque auprès de millions d’utilisateurs.
Des informations inexactes sur Wikipédia peuvent-elles nuire à ma marque dans les systèmes d’IA ?
Oui. Parce que les LLM considèrent Wikipédia comme hautement crédible, des informations inexactes sur votre page Wikipédia se propageront dans les systèmes d’IA. Cela peut affecter la façon dont ChatGPT, Gemini et d’autres plateformes IA décrivent votre organisation, pouvant nuire à la perception de votre marque.
Comment puis-je surveiller l’influence de Wikipédia sur ma marque dans les systèmes d’IA ?
Des outils comme AmICited.com suivent comment votre marque est citée et mentionnée dans les systèmes d’IA, y compris ChatGPT, Perplexity et Google AI Overviews. Cela vous aide à comprendre l’effet de ricochet de votre présence Wikipédia et à optimiser en conséquence.
Dois-je créer ou modifier moi-même ma page Wikipédia ?
Wikipédia a des règles strictes contre l’auto-promotion. Toute modification doit respecter les directives de Wikipédia et se baser sur des sources fiables et tierces. De nombreuses organisations font appel à des spécialistes Wikipédia pour assurer la conformité tout en maintenant une présence exacte.
Combien de temps faut-il pour que les changements sur Wikipédia affectent les systèmes d’IA ?
Les LLM sont entraînés sur des instantanés de données, donc les changements mettent du temps à se propager. Cependant, les graphes de connaissances se mettent à jour plus fréquemment, donc l’effet de ricochet peut débuter en quelques semaines à quelques mois selon le système d’IA et la fréquence de son réentraînement.
Quelle est la différence entre Wikipédia et les graphes de connaissances dans l’entraînement de l’IA ?
Wikipédia est une source primaire utilisée directement dans l’entraînement des LLM. Les graphes de connaissances comme le Knowledge Graph de Google agrègent des informations de multiples sources, dont Wikipédia, et les injectent dans les systèmes d’IA, créant une couche d’influence supplémentaire sur la façon dont l’IA comprend et présente l’information.
Surveillez votre présence Wikipédia dans les systèmes d’IA
Suivez comment les citations Wikipédia se répercutent dans ChatGPT, Gemini, Claude et d’autres systèmes d’IA. Comprenez votre empreinte IA et optimisez votre présence Wikipédia avec AmICited.
Le rôle de Wikipédia dans les données d'entraînement de l'IA : qualité, impact et licences
Découvrez comment Wikipédia sert de jeu de données critique pour l'entraînement de l'IA, son impact sur la précision des modèles, les accords de licence et pour...
Être cité dans les articles Wikipédia : une approche non manipulatrice
Découvrez des stratégies éthiques pour que votre marque soit citée sur Wikipédia. Comprenez les politiques de contenu de Wikipédia, les sources fiables, et comm...
Le rôle de Wikipédia dans les citations par l’IA : comment il façonne les réponses générées par l’IA
Découvrez comment Wikipédia influence les citations par l’IA dans ChatGPT, Perplexity et Google AI. Comprenez pourquoi Wikipédia est la source la plus fiable po...
15 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.