Comprendre les mécanismes de citation de l’IA
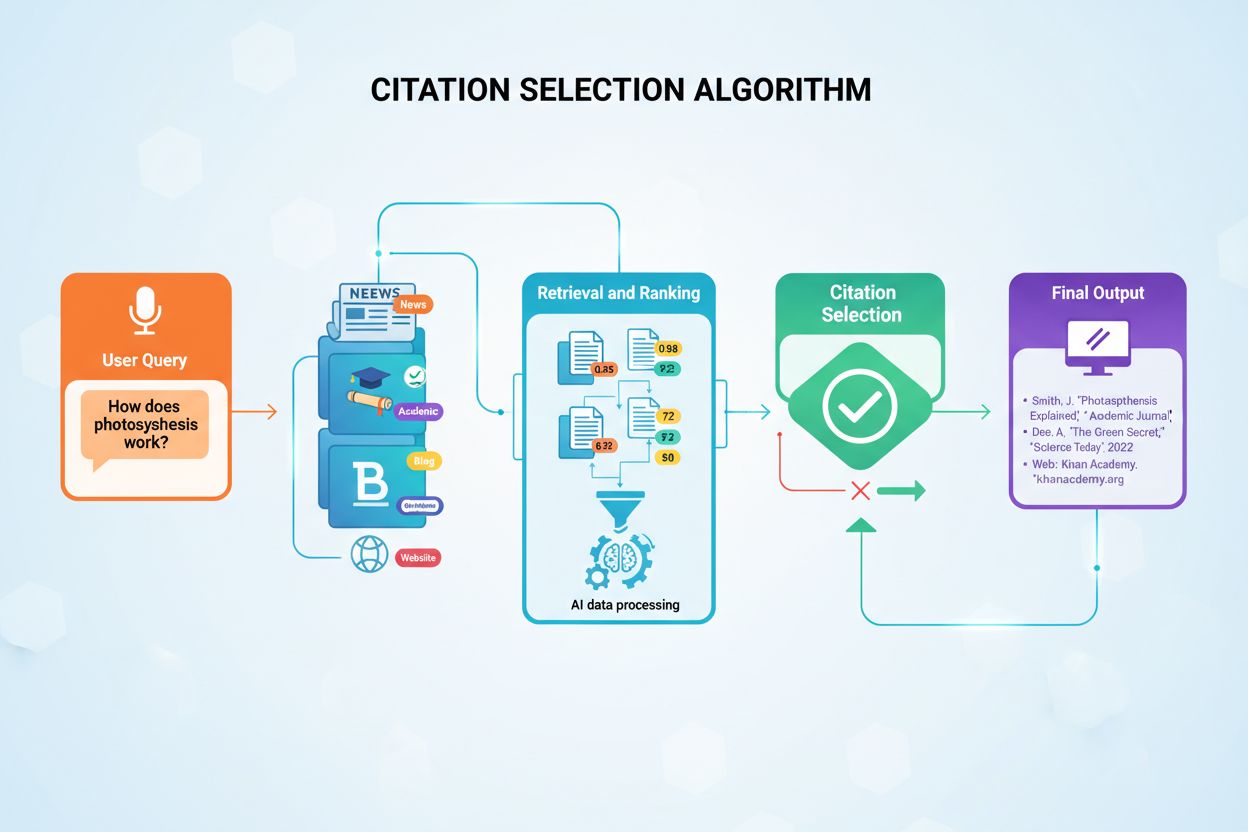
Les modèles d’IA ne sélectionnent pas au hasard les sources à citer dans leurs réponses. Ils utilisent plutôt des algorithmes sophistiqués qui évaluent des centaines de signaux en quelques millisecondes pour déterminer quelles sources méritent une attribution. Ce processus, appelé génération augmentée par récupération (RAG), diffère fondamentalement de la façon dont les moteurs de recherche traditionnels classent le contenu. Alors que l’algorithme de Google vise à classer les pages pour leur visibilité dans les résultats de recherche, les algorithmes de citation de l’IA privilégient les sources qui fournissent l’information la plus autoritaire, pertinente et fiable pour répondre à des requêtes utilisateurs spécifiques. Cette distinction signifie qu’obtenir de la visibilité dans les réponses générées par l’IA nécessite de comprendre un ensemble de principes d’optimisation totalement différent du SEO traditionnel.
La décision de citation se produit via un processus en plusieurs étapes qui commence dès qu’un utilisateur soumet une requête. Le système d’IA convertit la question de l’utilisateur en vecteurs numériques appelés embeddings, qui représentent la signification sémantique de la requête. Ces embeddings recherchent ensuite dans des bases de données de contenus indexés contenant des millions de documents, à la recherche de segments de contenu sémantiquement similaires. Le système ne se contente pas de récupérer le contenu le plus similaire ; il applique plusieurs critères d’évaluation simultanément pour classer les sources potentielles selon leur pertinence pour la citation. Cette évaluation parallèle garantit que les sources les plus crédibles, pertinentes et bien structurées émergent en tête du classement.
Le rôle de la génération augmentée par récupération
La génération augmentée par récupération (RAG) constitue l’architecture de base qui permet aux modèles d’IA de citer des sources externes. Contrairement aux modèles de langage de grande taille traditionnels qui s’appuient uniquement sur les données d’entraînement encodées pendant leur développement, les systèmes RAG recherchent de manière active dans des documents indexés au moment de la requête, récupérant des informations pertinentes avant de générer des réponses. Cette différence architecturale explique pourquoi certaines plateformes comme Perplexity et Google AI Overviews fournissent systématiquement des citations, tandis que d’autres comme ChatGPT de base génèrent souvent des réponses sans attribution explicite de la source. Comprendre la RAG aide à clarifier pourquoi certains contenus sont cités alors que d’autres, pourtant de qualité équivalente, restent invisibles pour les systèmes d’IA.
Le processus RAG fonctionne en quatre phases distinctes qui déterminent quelles sources reçoivent finalement des citations. D’abord, les documents sont divisés en segments gérables de 200 à 500 mots, permettant aux systèmes d’IA d’extraire des informations spécifiques et pertinentes sans analyser les articles entiers. Ensuite, ces segments sont convertis en vecteurs numériques appelés embeddings via des modèles de machine learning entraînés à comprendre la signification sémantique. Troisièmement, lorsqu’un utilisateur pose une question, le système recherche les vecteurs sémantiquement similaires grâce à la correspondance de similarité vectorielle, identifiant le contenu qui répond aux concepts clés de la requête. Quatrièmement, l’IA génère une réponse en utilisant le contenu récupéré comme contexte, et les sources qui ont le plus contribué à la réponse sont citées. Cette architecture explique pourquoi la structure du contenu, la clarté et l’alignement sémantique avec les requêtes courantes impactent directement la probabilité d’être cité.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Principaux facteurs utilisés par l’IA pour sélectionner les citations
Les algorithmes de citation de l’IA évaluent les sources selon cinq dimensions clés qui déterminent collectivement la valeur de citation. Ces facteurs fonctionnent ensemble pour créer une évaluation globale de la qualité de la source, chaque dimension contribuant au score global de citation.
| Facteur de citation | Niveau d’impact | Indicateurs clés |
|---|
| Autorité du domaine | Très élevé (25-30%) | Profil de backlinks, ancienneté du domaine, présence dans le knowledge graph, mentions sur Wikipédia |
| Actualité du contenu | Élevé (20-25%) | Date de publication, fréquence des mises à jour, fraîcheur des statistiques et des données |
| Pertinence sémantique | Élevé (20-25%) | Alignement requête-contenu, spécificité du sujet, présence de réponse directe |
| Structure de l’information | Moyen-élevé (15-20%) | Hiérarchie des titres, format scannable, implémentation du balisage schema |
| Densité factuelle | Moyen (10-15%) | Points de données spécifiques, statistiques, citations d’experts, chaînes de citations |
L’autorité représente le facteur le plus lourdement pondéré dans les décisions de citation de l’IA. Une étude portant sur 150 000 citations d’IA révèle que Reddit et Wikipédia comptent respectivement pour 40,1 % et 26,3 % de toutes les citations LLM, démontrant à quel point l’autorité établie influence fortement la sélection. Les systèmes d’IA évaluent l’autorité via de multiples signaux de confiance, dont l’âge du domaine, la qualité du profil de backlinks, la présence dans les knowledge graphs et la validation de tiers. Les sites avec des scores d’autorité de domaine supérieurs à 60 enregistrent systématiquement des taux de citation plus élevés sur ChatGPT, Perplexity et Gemini. Cependant, l’autorité ne se limite pas aux métriques du domaine ; elle englobe aussi la crédibilité de l’auteur, le contenu signé par des experts nommés et vérifiables étant privilégié par rapport aux contributions anonymes.
L’actualité agit comme un filtre temporel déterminant si le contenu reste éligible à la citation. Le contenu publié ou mis à jour dans les 48 à 72 heures bénéficie d’un classement préférentiel, tandis que la décadence du contenu commence immédiatement, la visibilité chutant de manière mesurable en 2 à 3 jours sans mises à jour. Ce biais d’actualité reflète l’engagement des plateformes IA à fournir des informations actuelles, en particulier pour les sujets qui évoluent rapidement où des informations obsolètes pourraient induire les utilisateurs en erreur. Cependant, un contenu intemporel récemment mis à jour peut surpasser un contenu plus récent mais superficiel, suggérant que la combinaison de la qualité fondamentale et de la fraîcheur temporelle compte plus que chaque facteur isolé. Les organisations qui maintiennent un cycle de rafraîchissement trimestriel ou annuel de leur contenu enregistrent des taux de citation supérieurs à celles qui publient une fois puis abandonnent leur contenu.
La pertinence mesure l’alignement sémantique entre la requête de l’utilisateur et le contenu du document. Les sources qui répondent directement à la question principale avec un minimum d’informations annexes obtiennent de meilleurs scores que les ressources complètes mais peu ciblées. Les systèmes d’IA évaluent la pertinence via la similarité des embeddings, en comparant la représentation numérique de la requête à celle des segments de documents. Cela signifie que le contenu rédigé dans un langage conversationnel correspondant aux requêtes de recherche naturelles fonctionne mieux que le contenu optimisé pour les mots-clés destiné aux moteurs de recherche traditionnels. Le contenu au format FAQ et les paires question-réponse s’alignent naturellement avec la façon dont les systèmes d’IA traitent les requêtes, rendant ce format particulièrement propice à la citation.
La structure englobe à la fois l’architecture de l’information et la mise en œuvre technique. Une organisation hiérarchique claire avec des titres descriptifs, un flux logique et un format scannable aide les systèmes d’IA à comprendre les limites du contenu et à extraire les informations pertinentes. Le balisage de données structurées via des formats schema comme FAQ, Article et Organization peut augmenter la probabilité de citation jusqu’à 10 %. Le contenu organisé en résumés concis, listes à puces, tableaux comparatifs et paires question-réponse est privilégié par rapport aux paragraphes denses à insights enfouis. Cette préférence structurelle reflète l’entraînement des systèmes d’IA à reconnaître l’information bien organisée apportant des réponses complètes et contextuelles.
La densité factuelle désigne la concentration d’informations spécifiques et vérifiables dans le contenu. Les sources contenant des données précises, des statistiques, des dates et des exemples concrets surpassent les contenus purement conceptuels. Plus important encore, les sources qui citent des références autorisées créent des cascades de confiance, les systèmes d’IA héritant de la confiance accordée aux sources citées. Le contenu incluant des preuves et des liens vers des sources primaires affiche des taux de citation supérieurs aux affirmations non étayées. Cette exigence de densité factuelle signifie que chaque affirmation importante doit être attribuée à des sources autorisées avec date de publication et références d’experts.
Les différentes plateformes IA mettent en œuvre des stratégies de citation distinctes, reflétant leurs différences architecturales et leurs philosophies de conception. Comprendre ces préférences spécifiques aide les créateurs de contenu à optimiser simultanément pour plusieurs systèmes IA.
Les schémas de citation de ChatGPT révèlent une forte préférence pour les sources encyclopédiques et autorisées. Wikipédia apparaît dans environ 35 % des citations ChatGPT, ce qui montre la dépendance du modèle à l’information établie et vérifiée par la communauté. La plateforme évite le contenu issu des forums utilisateur sauf si la requête cible explicitement des avis communautaires, préférant les sources avec chaînes d’attribution claires et faits vérifiables aux contenus à base d’opinions. Cette approche conservatrice reflète la formation de ChatGPT sur des sources de haute qualité et sa philosophie de conception privilégiant l’exactitude à l’exhaustivité. Les organisations cherchant à obtenir des citations ChatGPT bénéficient d’une présence dans les knowledge graphs, de la création de pages Wikipédia et de contenus reflétant la profondeur et la neutralité encyclopédiques.
Les systèmes IA de Google, dont Gemini et AI Overviews, intègrent des types de sources plus diversifiés, reflétant la philosophie d’indexation plus large de Google. Les posts Reddit comptent pour environ 5 % des citations AI Overviews, tandis que la plateforme privilégie le contenu figurant en tête des résultats organiques, créant une synergie entre SEO traditionnel et taux de citation IA. Les systèmes IA de Google montrent une plus grande volonté de citer des sources récentes et du contenu généré par les utilisateurs par rapport à ChatGPT, à condition que ces sources démontrent pertinence et autorité. Cette préférence de plateforme signifie que une bonne performance SEO traditionnelle corrèle avec le succès de citation IA sur les plateformes Google, même si la corrélation n’est pas parfaite.
Les préférences de Perplexity AI mettent l’accent sur la transparence et l’attribution directe des sources. La plateforme fournit généralement 3 à 5 sources par réponse avec des liens directs, privilégiant les sites d’avis sectoriels, les publications d’experts et le contenu basé sur les données. L’autorité du domaine pèse lourd, les publications établies étant favorisées tandis que le contenu communautaire ne représente qu’environ 1 % des citations, principalement pour des recommandations produit. La philosophie de Perplexity vise à aider les utilisateurs à vérifier l’information via une attribution claire, ce qui en fait un outil précieux pour surveiller la visibilité de marque. Les organisations optimisant pour Perplexity bénéficient de la création de contenus riches en données, de ressources sectorielles et de textes rédigés par des experts reconnus.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Autorité de domaine et signaux de confiance
L’autorité de domaine fait office de proxy de fiabilité dans les algorithmes IA, indiquant qu’une source a démontré sa crédibilité dans le temps. Les systèmes évaluent l’autorité grâce à de multiples signaux de confiance représentant environ 5 % de la probabilité totale de citation, ce pourcentage augmentant nettement pour les sujets YMYL (Your Money, Your Life) impactant la santé, les finances ou la sécurité. Les indicateurs clés d’autorité incluent l’ancienneté du domaine, les certificats SSL, la politique de confidentialité, et les marqueurs de conformité tel que la certification SOC 2 ou RGPD. Ces signaux techniques s’ajoutent aux métriques de qualité de contenu, créant un effet multiplicateur où les sites techniquement solides dotés d’un excellent contenu surpassent les sites techniquement faibles, quelle que soit la qualité de leur contenu.
Les profils de backlinks influencent fortement la perception des sources par les algorithmes IA. Les modèles IA évaluent l’autorité des domaines référents, la pertinence du contexte du lien et la diversité du portefeuille de backlinks. Les études montrent que dix backlinks issus de grandes publications valent mieux que cent backlinks provenant de sites à faible autorité, prouvant que la qualité des liens prévaut sur la quantité. L’attribution à des experts augmente considérablement la probabilité de citation, le contenu signé par des auteurs nommés et vérifiables obtenant de bien meilleurs résultats que le contenu anonyme. Le balisage schema auteur et les biographies détaillées aident les systèmes IA à valider l’expertise, tandis que la validation tierce via des mentions dans des publications sectorielles renforce la crédibilité. Les organisations souhaitant renforcer leur autorité doivent viser des backlinks de sources à forte autorité, établir des références d’auteur et obtenir des mentions dans des publications du secteur.
La présence sur Wikipédia et dans les knowledge graphs améliore nettement les taux de citation quels que soient les autres facteurs. Les sources référencées sur Wikipédia bénéficient d’un avantage considérable car les knowledge graphs servent de sources autorisées que les modèles IA consultent à répétition pour divers types de requêtes. Les informations du Google Knowledge Panel alimentent directement la façon dont les modèles IA comprennent les relations d’entités et l’autorité. Les organisations sans présence sur Wikipédia peinent à obtenir des citations régulières même avec du contenu de haute qualité, ce qui suggère que le développement de knowledge graphs doit être une priorité pour toute stratégie sérieuse de visibilité IA. Cela crée une couche de confiance fondamentale que les modèles de langage consultent lors de la récupération, faisant des entrées dans les knowledge graphs des sources de référence pour les modèles.
Caractéristiques de contenu qui favorisent les citations
L’alignement conversationnel avec les requêtes marque un changement fondamental par rapport à l’optimisation SEO traditionnelle. Le contenu structuré en paires question-réponse fonctionne mieux dans les algorithmes de récupération que le contenu optimisé pour les mots-clés. Les pages FAQ et les contenus imitant des requêtes en langage naturel sont favorisés car les systèmes IA sont entraînés sur des données conversationnelles et comprennent mieux les schémas de langage naturel que les chaînes de mots-clés. Cela signifie qu’un contenu rédigé comme pour répondre à la question d’un ami surpasse celui écrit pour les algorithmes de moteurs de recherche. Les organisations devraient auditer leurs contenus pour un ton conversationnel, des réponses directes aux questions courantes et un alignement naturel avec la façon dont les utilisateurs posent réellement leurs questions.
La qualité des citations dans le contenu crée des cascades de confiance qui dépassent la source individuelle. Les systèmes IA évaluent si les affirmations sont accompagnées de données et de preuves. Un contenu citant des références autorisées hérite de la crédibilité des sources citées, générant un effet de crédibilité multiplicateur. Les sources incluant des preuves et des liens vers des sources primaires affichent des taux de citation supérieurs aux affirmations non justifiées. Cela signifie que chaque affirmation importante doit être attribuée à des sources autorisées avec date de publication et références d’experts. Les organisations souhaitant produire du contenu digne de citation doivent rechercher et citer au minimum 5 à 8 sources autorisées, inclure 2 à 3 citations d’experts avec références complètes, et ajouter 3 à 5 statistiques récentes avec dates de publication.
La cohérence entre plateformes influence la façon dont les systèmes IA évaluent la crédibilité des sources. Lorsque l’IA retrouve des informations cohérentes sur plusieurs sources, la confiance augmente pour citer toute source individuelle de ce groupe. Les sources contredisant le consensus général sont moins prioritaires sauf à fournir des preuves contraires solides. Ce biais de cohérence signifie qu’établir des récits cohérents sur l’ensemble des canaux owned, earned et shared renforce la citabilité individuelle. Les organisations développant des stratégies de gestion de réputation IA doivent maintenir un message cohérent sur tous leurs supports digitaux, s’assurant que les informations présentées sur leurs sites web, réseaux sociaux, publications sectorielles et plateformes tierces s’alignent et renforcent les messages clés.
Stratégies d’optimisation pour les citations IA
La stratégie de fréquence de mise à jour est plus cruciale à l’ère de l’IA qu’en SEO traditionnel. La fréquence de publication impacte directement les taux de citation, les plateformes IA montrant une nette préférence pour le contenu récemment mis à jour. Les organisations devraient mettre à jour leurs contenus existants tous les 48 à 72 heures pour maintenir les signaux d’actualité, sans nécessiter de réécriture complète. L’ajout de nouvelles données, la mise à jour des statistiques ou l’élargissement de sections avec des développements récents permettent de rester éligible à la citation. Les CMS qui suivent la fréquence de mise à jour et la fraîcheur du contenu aident à maintenir des taux de citation compétitifs alors que les plateformes IA accordent un poids croissant à l’actualité. Cette approche continue diffère fondamentalement du SEO traditionnel où un contenu pouvait rester classé indéfiniment sans modification.
Le placement stratégique sur des sites agrégateurs crée des voies de découverte multiples pour les systèmes IA. Être mentionné dans des panoramas sectoriels, listes d’experts ou sites d’avis génère des opportunités au-delà de ce que peuvent offrir les seules sources originales. Une seule mention dans une publication fréquemment citée multiplie les voies de découverte et favorise la rencontre de votre contenu par l’IA via différents chemins. Les relations presse et les partenariats de contenu gagnent en valeur pour la visibilité IA, tout comme le placement dans des bases de données et annuaires sectoriels. Les organisations devraient rechercher des publications dans des panoramas sectoriels, listes d’experts et sites d’avis dans le cadre de leur stratégie de visibilité IA.
L’implémentation de données structurées améliore la probabilité de citation en rendant le contenu lisible par machine. Le balisage schema dans des formats compatibles IA aide les plateformes à comprendre et extraire des faits sans devoir analyser du texte non structuré. Le schéma FAQ, le schéma Article avec informations sur l’auteur et le schéma Organization créent des signaux lisibles par machine que les algorithmes de récupération priorisent. Les données structurées JSON-LD permettent à l’IA d’extraire efficacement des faits précis, augmentant la probabilité de citation et la précision des informations citées. Les organisations mettant en œuvre un balisage schema complet constatent une amélioration mesurable des taux de citation sur plusieurs plateformes IA.
Le développement de Wikipédia et des knowledge graphs offre des retours cumulés malgré l’effort soutenu requis. Construire une présence sur Wikipédia exige des contributions neutres, bien sourcées et conformes aux standards éditoriaux de la plateforme. L’optimisation simultanée des profils sur Wikidata, Google Knowledge Panel et les bases sectorielles crée la couche de confiance fondamentale à laquelle les systèmes IA se réfèrent constamment. Ces entrées dans les knowledge graphs servent de sources d’autorité que les modèles consultent pour diverses requêtes, faisant de leur développement une priorité stratégique pour toute organisation visant une visibilité IA durable.
Mesurer le succès des citations IA
Les organisations devraient suivre la fréquence des citations en testant manuellement les requêtes pertinentes sur ChatGPT, Google AI Overviews, Perplexity et d’autres plateformes. Des tests réguliers de prompts révèlent quels contenus obtiennent efficacement des citations et où se trouvent les lacunes dans la représentation IA. Cette méthodologie offre une visibilité directe sur la performance des citations et aide à identifier des opportunités d’optimisation. Les algorithmes de citation IA évoluent en continu à mesure que les données d’entraînement s’élargissent et que les stratégies de récupération changent, obligeant les stratégies de contenu à s’adapter en fonction des données de performance. Lorsque le contenu cesse d’être cité malgré un succès passé, il convient de le rafraîchir avec des informations récentes ou de le restructurer pour un meilleur alignement sémantique.
Plusieurs sources peuvent être citées pour une même requête, créant des opportunités de co-citation plutôt qu’une compétition à somme nulle. Les organisations bénéficient de la création de contenus complets qui complètent, plutôt que dupliquent, les sources déjà très citées. L’analyse du paysage concurrentiel révèle quelles marques dominent la visibilité IA dans des catégories spécifiques, aidant à identifier des lacunes et des opportunités. Le suivi des performances de citation dans le temps met en lumière les tendances et les URL qui génèrent du succès, permettant de répliquer les stratégies gagnantes et d’étendre les approches fructueuses.