
Gestion des crawlers IA
Découvrez comment gérer l’accès des crawlers IA au contenu de votre site web. Comprenez la différence entre crawlers d’entraînement et de recherche, mettez en p...
8 min de lecture
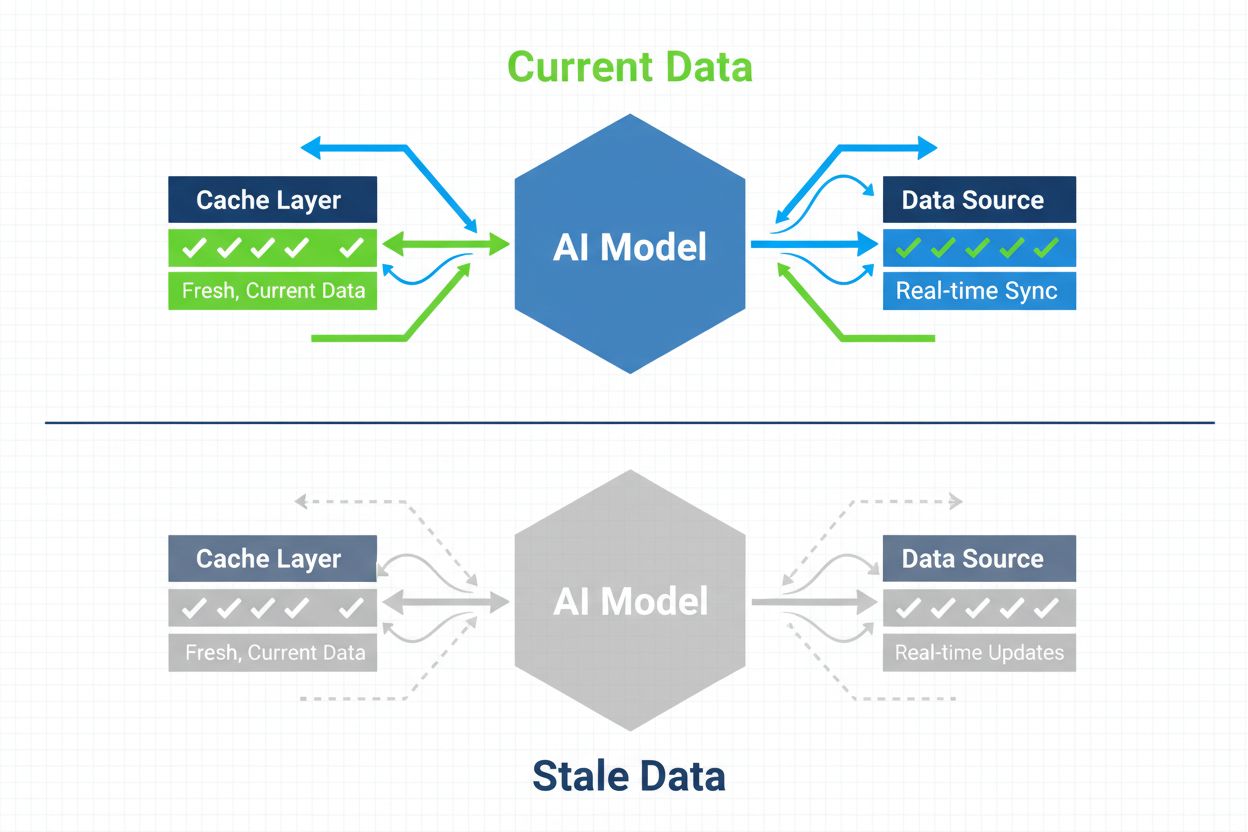
Stratégies pour garantir que les systèmes d’IA ont accès à un contenu à jour plutôt qu’à des versions obsolètes en cache. La gestion du cache équilibre les avantages de performance du stockage en cache avec le risque de servir des informations périmées, en utilisant des stratégies d’invalidation et une surveillance pour maintenir la fraîcheur des données tout en réduisant la latence et les coûts.
Stratégies pour garantir que les systèmes d'IA ont accès à un contenu à jour plutôt qu'à des versions obsolètes en cache. La gestion du cache équilibre les avantages de performance du stockage en cache avec le risque de servir des informations périmées, en utilisant des stratégies d'invalidation et une surveillance pour maintenir la fraîcheur des données tout en réduisant la latence et les coûts.
La gestion du cache IA désigne l’approche systématique de stockage et de récupération de résultats déjà calculés, de sorties de modèles ou de réponses d’API afin d’éviter des traitements redondants et de réduire la latence dans les systèmes d’intelligence artificielle. Le principal défi réside dans l’équilibre entre les bénéfices en performance liés aux données mises en cache et le risque de servir des informations obsolètes qui ne reflètent plus l’état actuel du système ou les besoins de l’utilisateur. Ce point devient particulièrement critique dans les grands modèles de langage (LLMs) et les applications IA où les coûts d’inférence sont importants et où le temps de réponse a un impact direct sur l’expérience utilisateur. Les systèmes de gestion du cache doivent déterminer intelligemment quand les résultats en cache restent valides et quand un calcul frais est nécessaire, ce qui en fait une considération architecturale fondamentale pour les déploiements IA en production.
L’impact d’une gestion efficace du cache sur la performance des systèmes IA est considérable et mesurable sur plusieurs axes. La mise en place de stratégies de cache peut réduire la latence des réponses de 80 à 90 % pour les requêtes répétées tout en diminuant les coûts d’API de 50 à 90 %, selon les taux de succès du cache et l’architecture du système. Au-delà des indicateurs de performance, la gestion du cache influence directement la cohérence de l’exactitude et la fiabilité du système, car un cache correctement invalidé garantit à l’utilisateur des informations actualisées alors qu’une gestion défaillante introduit des problèmes de données obsolètes. Ces améliorations deviennent de plus en plus importantes à mesure que les systèmes IA montent en charge pour gérer des millions de requêtes, où l’effet cumulatif de l’efficacité du cache détermine directement les coûts d’infrastructure et la satisfaction des utilisateurs.
| Aspect | Systèmes avec cache | Systèmes sans cache |
|---|---|---|
| Temps de réponse | 80-90 % plus rapide | De base |
| Coûts API | Réduction de 50-90 % | Coût complet |
| Précision | Cohérente | Variable |
| Scalabilité | Élevée | Limitée |
Les stratégies d’invalidation du cache déterminent comment et quand les données mises en cache sont rafraîchies ou supprimées du stockage, représentant l’une des décisions les plus critiques dans la conception de l’architecture de cache. Différentes approches d’invalidation offrent des compromis distincts entre la fraîcheur des données et la performance du système :
Le choix de la stratégie d’invalidation dépend fondamentalement des besoins de l’application : les systèmes privilégiant la précision des données peuvent accepter un coût de latence plus élevé via une invalidation agressive, tandis que les applications critiques en performance peuvent tolérer des données légèrement obsolètes pour maintenir des temps de réponse inférieurs à la milliseconde.
La mise en cache des prompts dans les grands modèles de langage représente une application spécialisée de la gestion du cache, qui stocke les états intermédiaires du modèle et les séquences de jetons afin d’éviter le retraitement d’entrées identiques ou similaires. Les LLMs proposent deux méthodes principales de cache : la mise en cache exacte correspond à des prompts identiques caractère par caractère, tandis que la mise en cache sémantique identifie des prompts fonctionnellement équivalents malgré un libellé différent. OpenAI met en œuvre une mise en cache automatique des prompts avec une réduction de 50 % du coût sur les jetons mis en cache, nécessitant un segment de prompt minimum de 1024 jetons pour activer les bénéfices du cache. Anthropic propose une mise en cache manuelle des prompts avec une réduction plus agressive de 90 %, mais requiert que les développeurs gèrent explicitement les clés et durées du cache, avec des exigences minimales de 1024 à 2048 jetons selon la configuration du modèle. La durée de conservation du cache dans les systèmes LLM varie généralement de quelques minutes à plusieurs heures, équilibrant les économies computationnelles du réemploi d’états mis en cache et le risque de servir des sorties obsolètes pour des applications sensibles au temps.
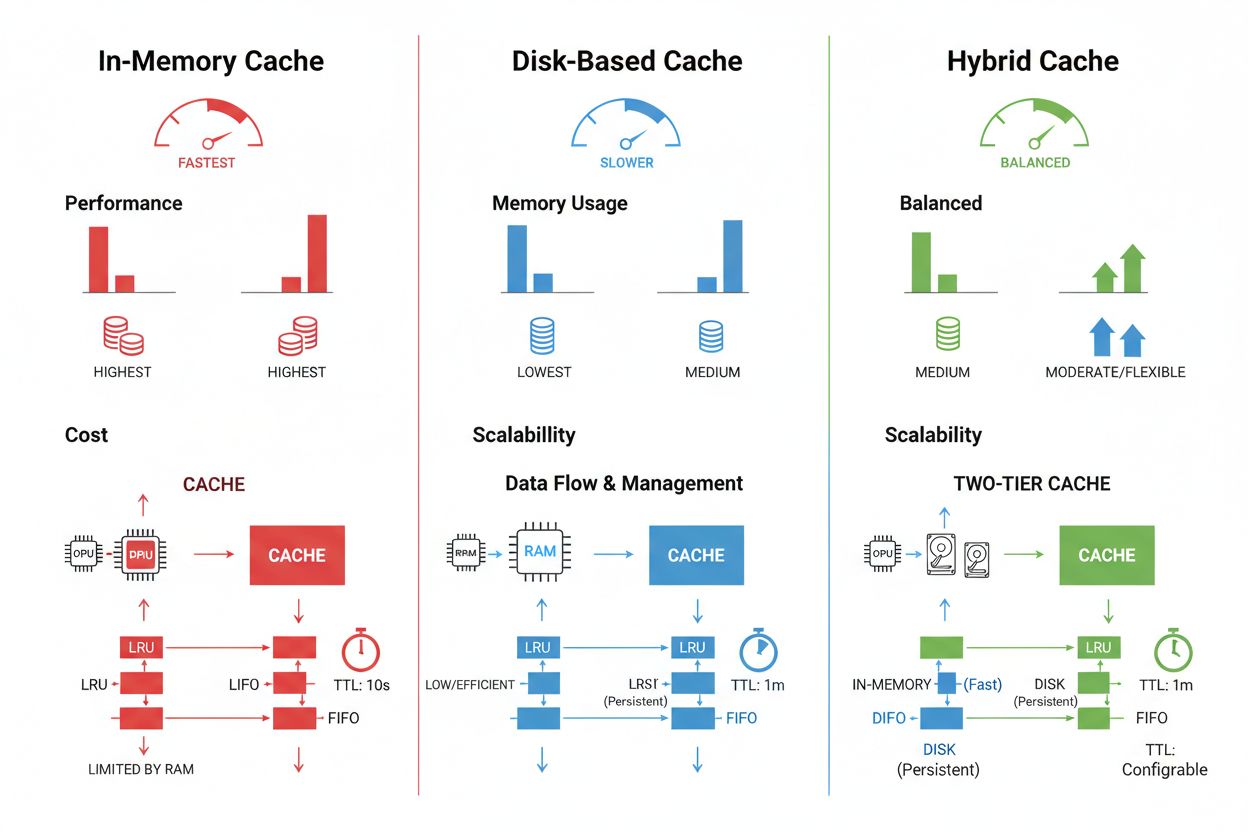
Les techniques de stockage et de gestion du cache varient considérablement selon les besoins de performance, le volume de données et les contraintes d’infrastructure, chaque approche présentant des avantages et des limites distincts. Les solutions de mise en cache en mémoire comme Redis offrent des vitesses d’accès de l’ordre de la microseconde, idéales pour les requêtes à haute fréquence, mais consomment beaucoup de RAM et nécessitent une gestion attentive de la mémoire. La mise en cache sur disque permet de gérer de plus grands ensembles de données et persiste après les redémarrages, mais introduit une latence de l’ordre de la milliseconde comparée aux alternatives en mémoire. Les approches hybrides combinent les deux types de stockage, orientant les données fréquemment consultées vers la mémoire tout en conservant les ensembles plus volumineux sur disque :
| Type de stockage | Idéal pour | Performance | Utilisation mémoire |
|---|---|---|---|
| En mémoire (Redis) | Requêtes fréquentes | Plus rapide | Plus élevée |
| Sur disque | Grandes données | Modérée | Plus faible |
| Hybride | Charges mixtes | Équilibrée | Équilibrée |
Une gestion efficace du cache nécessite de configurer des TTL appropriés reflétant la volatilité des données — TTL courts (minutes) pour des données changeant rapidement, contre TTL plus longs (heures/jours) pour du contenu stable — combinés à une surveillance continue des taux de succès du cache, des schémas d’éviction et de l’utilisation mémoire afin d’identifier des axes d’optimisation.
Les applications IA réelles démontrent à la fois le potentiel transformateur et la complexité opérationnelle de la gestion du cache à travers des cas d’usage diversifiés. Les chatbots de service client utilisent le cache pour fournir des réponses cohérentes aux questions fréquentes tout en réduisant les coûts d’inférence de 60 à 70 %, permettant une montée en charge économique vers des milliers d’utilisateurs simultanés. Les assistants de codage mettent en cache des patrons de code et extraits de documentation courants, permettant aux développeurs de recevoir des suggestions d’autocomplétion avec une latence inférieure à 100 ms même en période de forte utilisation. Les systèmes de traitement de documents mettent en cache les embeddings et représentations sémantiques de documents fréquemment analysés, accélérant considérablement les recherches de similarité et les tâches de classification. En revanche, la gestion du cache en production introduit des défis majeurs : la complexité de l’invalidation croît exponentiellement dans les systèmes distribués où la cohérence du cache doit être maintenue sur plusieurs serveurs, les contraintes de ressources imposent des choix difficiles entre taille de cache et couverture, des risques de sécurité apparaissent lorsque des données sensibles nécessitent chiffrement et contrôle d’accès, et la coordination des mises à jour de cache entre microservices introduit des conditions de compétition et des incohérences potentielles. Des solutions de surveillance complètes qui suivent la fraîcheur du cache, les taux de succès et les événements d’invalidation deviennent essentielles pour garantir la fiabilité du système et identifier quand les stratégies de cache doivent être ajustées en fonction de l’évolution des données et du comportement des utilisateurs.
L'invalidation du cache supprime ou met à jour les données obsolètes lorsque des modifications surviennent, offrant une fraîcheur immédiate mais nécessitant des déclencheurs événementiels. L'expiration du cache définit une durée limite (TTL) pendant laquelle les données restent en cache, offrant une mise en œuvre plus simple mais risquant de servir des données obsolètes si le TTL est trop long. De nombreux systèmes combinent les deux approches pour une performance optimale.
Une gestion efficace du cache peut réduire les coûts API de 50 à 90 % selon les taux de succès du cache et l'architecture du système. La mise en cache des prompts d'OpenAI offre une réduction de 50 % sur les jetons mis en cache, tandis qu'Anthropic fournit jusqu'à 90 % de réduction. Les économies réelles dépendent des modèles de requêtes et de la quantité de données pouvant être effectivement mises en cache.
La mise en cache des prompts stocke les états intermédiaires du modèle et les séquences de jetons pour éviter le retraitement des entrées identiques ou similaires dans les grands modèles de langage. Elle prend en charge la mise en cache exacte (correspondance caractère par caractère) et la mise en cache sémantique (prompts fonctionnellement équivalents avec un libellé différent). Cela réduit la latence de 80 % et les coûts de 50 à 90 % pour les requêtes répétées.
Les principales stratégies sont : expiration basée sur le temps (TTL) pour la suppression automatique après une durée définie, invalidation basée sur les événements pour des mises à jour immédiates lors de changements de données, invalidation sémantique pour des requêtes similaires sur la base du sens, et approches hybrides combinant plusieurs stratégies. Le choix dépend de la volatilité des données et des exigences de fraîcheur.
La mise en cache en mémoire (comme Redis) offre des vitesses d'accès de l'ordre de la microseconde, idéales pour les requêtes fréquentes mais consomme beaucoup de RAM. La mise en cache sur disque gère des ensembles de données plus volumineux et persiste après un redémarrage, mais introduit une latence de l'ordre de la milliseconde. Les approches hybrides combinent les deux, en dirigeant les données fréquemment consultées vers la mémoire tout en conservant de grands ensembles sur disque.
Le TTL est un compte à rebours qui détermine combien de temps les données en cache restent valides avant expiration. Des TTL courts (minutes) conviennent aux données changeant rapidement, tandis que des TTL plus longs (heures/jours) conviennent à un contenu stable. Une configuration appropriée du TTL équilibre la fraîcheur des données et les rafraîchissements inutiles du cache ainsi que la charge serveur.
Une gestion efficace du cache permet aux systèmes d'IA de gérer nettement plus de requêtes sans extension proportionnelle de l'infrastructure. En réduisant la charge de calcul par requête grâce au cache, les systèmes peuvent servir des millions d'utilisateurs de manière plus économique. Les taux de succès du cache déterminent directement les coûts d'infrastructure et la satisfaction des utilisateurs en production.
La mise en cache de données sensibles introduit des vulnérabilités de sécurité si elles ne sont pas correctement chiffrées et contrôlées en accès. Les risques incluent l'accès non autorisé aux informations en cache, l'exposition des données lors de l'invalidation du cache, et la mise en cache involontaire de contenu confidentiel. Un chiffrement complet, des contrôles d'accès et une surveillance sont essentiels pour protéger les données sensibles en cache.
AmICited suit la façon dont les systèmes d'IA référencent votre marque et garantit que votre contenu reste à jour dans les caches IA. Obtenez une visibilité sur la gestion du cache IA et la fraîcheur du contenu sur GPTs, Perplexity et Google AI Overviews.
Découvrez comment gérer l’accès des crawlers IA au contenu de votre site web. Comprenez la différence entre crawlers d’entraînement et de recherche, mettez en p...

Découvrez ce que signifie la gestion de la réputation pour la recherche par IA, pourquoi c’est important pour votre marque et comment surveiller votre présence ...

Découvrez comment détecter, répondre et prévenir les crises générées par l’IA qui menacent la réputation de votre marque. Découvrez des stratégies de surveillan...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.