La pratique stratégique qui consiste à autoriser ou à bloquer sélectivement les crawlers IA afin de contrôler comment le contenu est utilisé pour l’entraînement ou la recherche en temps réel. Cela implique l’utilisation de fichiers robots.txt, de contrôles au niveau serveur et d’outils de surveillance pour gérer quels systèmes d’IA peuvent accéder à votre contenu et à quelles fins.
Gestion des crawlers IA
La pratique stratégique qui consiste à autoriser ou à bloquer sélectivement les crawlers IA afin de contrôler comment le contenu est utilisé pour l'entraînement ou la recherche en temps réel. Cela implique l’utilisation de fichiers robots.txt, de contrôles au niveau serveur et d’outils de surveillance pour gérer quels systèmes d’IA peuvent accéder à votre contenu et à quelles fins.
Qu’est-ce que la gestion des crawlers IA ?
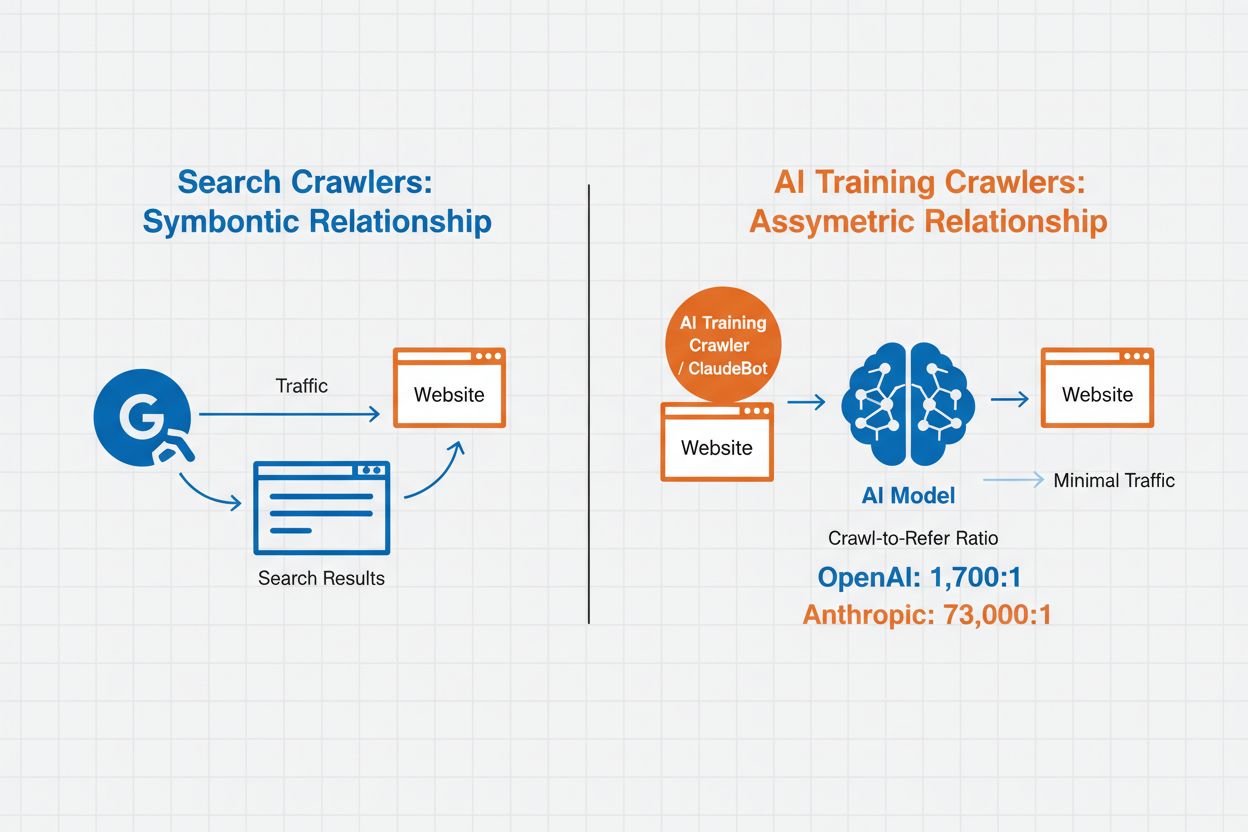
La gestion des crawlers IA désigne la pratique consistant à contrôler et surveiller la manière dont les systèmes d’intelligence artificielle accèdent et utilisent le contenu des sites web à des fins d’entraînement et de recherche. Contrairement aux crawlers des moteurs de recherche traditionnels qui indexent le contenu pour les résultats web, les crawlers IA sont spécifiquement conçus pour recueillir des données destinées à l’entraînement de grands modèles de langage ou à l’alimentation de fonctionnalités de recherche pilotées par l’IA. L’ampleur de cette activité varie considérablement selon les organisations : les crawlers d’OpenAI fonctionnent avec un ratio crawl-to-refer de 1 700:1, c’est-à-dire qu’ils accèdent 1 700 fois au contenu pour chaque référence fournie, tandis que celui d’Anthropic atteint 73 000:1, soulignant l’énorme consommation de données requise pour entraîner les systèmes d’IA modernes. Une gestion efficace des crawlers permet aux propriétaires de sites de choisir si leur contenu contribue à l’entraînement de l’IA, apparaît dans les résultats de recherche IA ou reste protégé contre l’accès automatisé.
Types de crawlers IA
Les crawlers IA se répartissent en trois grandes catégories selon leur objectif et leurs modes d’utilisation des données. Les crawlers d’entraînement sont conçus pour collecter des données destinées au développement de modèles d’apprentissage automatique, consommant d’énormes quantités de contenu pour améliorer les capacités de l’IA. Les crawlers de recherche et de citation indexent le contenu pour alimenter des fonctions de recherche IA et fournir une attribution dans les réponses générées, permettant aux utilisateurs de découvrir votre contenu via des interfaces IA. Les crawlers déclenchés par l’utilisateur fonctionnent à la demande lorsque des utilisateurs interagissent avec des outils IA, par exemple lorsqu’un utilisateur de ChatGPT téléverse un document ou demande l’analyse d’une page web spécifique. Comprendre ces catégories vous aide à prendre des décisions éclairées sur les crawlers à autoriser ou à bloquer selon votre stratégie de contenu et vos objectifs commerciaux.
Type de crawler
Objectif
Exemples
Données d’entraînement utilisées
Entraînement
Développement et amélioration de modèle
GPTBot, ClaudeBot
Oui
Recherche/Citation
Résultats de recherche IA et attribution
Google-Extended, OAI-SearchBot, PerplexityBot
Variable
Déclenché par l’utilisateur
Analyse de contenu à la demande
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Selon le contexte
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Pourquoi la gestion des crawlers IA est-elle importante ?
La gestion des crawlers IA a un impact direct sur le trafic, les revenus et la valeur de votre contenu. Lorsque les crawlers consomment votre contenu sans compensation, vous perdez la possibilité d’en bénéficier via le trafic référent, les impressions publicitaires ou l’engagement utilisateur. Des sites ont constaté d’importantes baisses de trafic lorsque les utilisateurs obtiennent des réponses directement dans les réponses IA au lieu de cliquer sur la source d’origine, coupant ainsi le trafic référent et les revenus publicitaires associés. Au-delà des implications financières, il existe d’importantes considérations juridiques et éthiques : votre contenu représente une propriété intellectuelle et vous avez le droit de contrôler son usage et de recevoir une attribution ou une compensation. Par ailleurs, autoriser un accès illimité des crawlers peut augmenter la charge serveur et les coûts de bande passante, en particulier avec des crawlers ayant des taux d’exploration agressifs qui ne respectent pas les limitations de fréquence.
Robots.txt et contrôles techniques
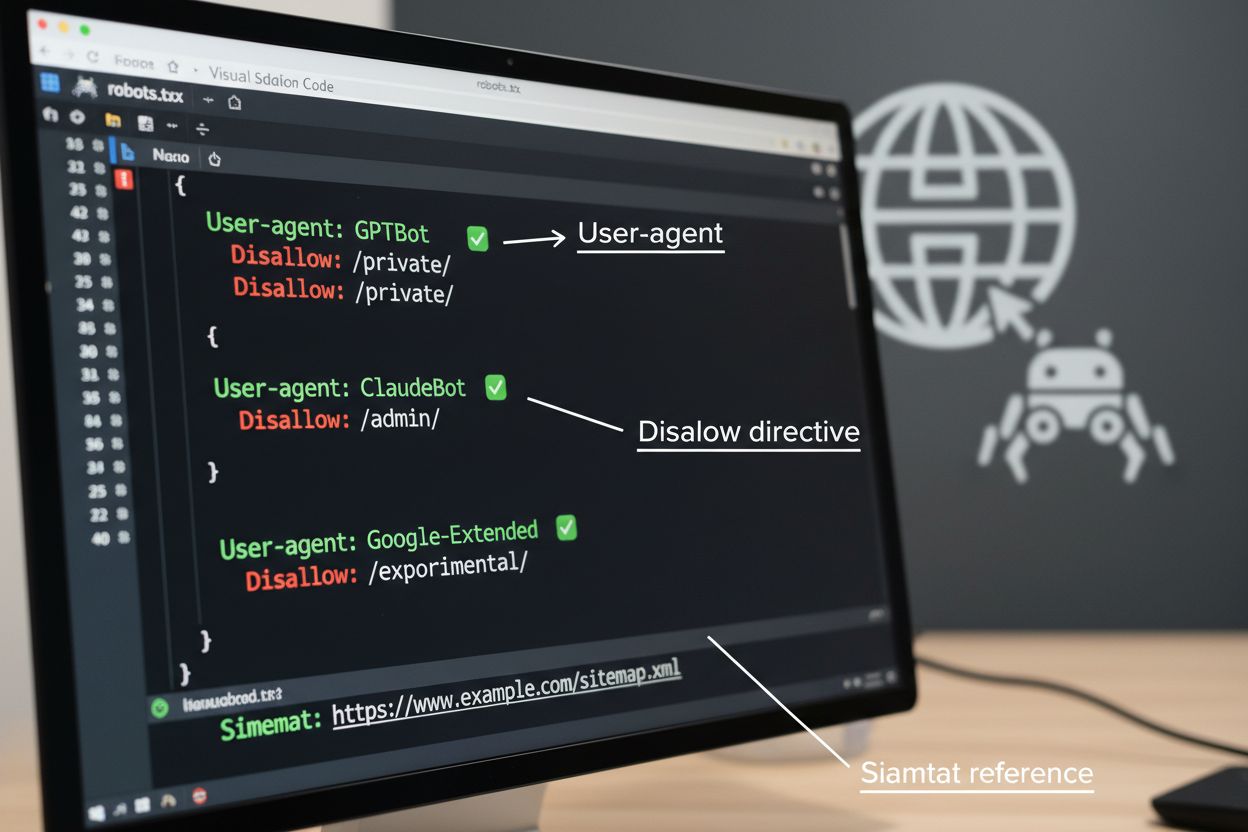
Le fichier robots.txt est l’outil fondamental pour gérer l’accès des crawlers, placé à la racine de votre site pour communiquer vos préférences aux agents automatisés. Ce fichier utilise des directives User-agent pour cibler des crawlers spécifiques et des règles Disallow ou Allow pour autoriser ou restreindre l’accès à certains chemins et ressources. Toutefois, le robots.txt présente des limites importantes : il s’agit d’un standard volontaire dépendant du respect par les crawlers, et les bots malveillants ou mal conçus peuvent l’ignorer totalement. De plus, robots.txt n’empêche pas l’accès aux contenus publics ; il ne fait que demander le respect de vos préférences. Pour ces raisons, robots.txt doit s’intégrer dans une approche multicouche de gestion des crawlers plutôt que d’être votre seule défense.
# Bloquer les crawlers d’entraînement IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Autoriser les moteurs de recherche
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Règle par défaut pour les autres crawlers
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Méthodes de contrôle avancées
Au-delà du robots.txt, plusieurs techniques avancées offrent une application plus stricte et un contrôle plus fin de l’accès des crawlers. Ces méthodes opèrent à différents niveaux de votre infrastructure et peuvent être combinées pour une protection complète :
Règles .htaccess : Directives serveur bloquant des user-agents ou des plages IP spécifiques avant la livraison du contenu
Listes blanches/noires d’IP : Restreindre l’accès selon les adresses IP associées aux crawlers IA connus (nécessite une veille régulière des listes d’IP)
Solutions Cloudflare WAF : Utiliser des règles de pare-feu applicatif pour identifier et bloquer le trafic crawler selon les signatures et comportements
En-têtes HTTP (X-Robots-Tag) : Envoyer des directives aux crawlers directement dans les en-têtes de réponse, offrant un contrôle plus granulaire et difficile à ignorer que robots.txt
Limitation de débit : Appliquer des limites strictes de fréquence sur le trafic crawler pour rendre la collecte massive de données économiquement non viable
Empreintes bots : Analyser les schémas de requêtes, en-têtes et comportements pour identifier les crawlers sophistiqués qui masquent leur identité
Trouver l’équilibre entre protection et visibilité
La décision de bloquer les crawlers IA implique un arbitrage entre protection du contenu et découvrabilité. Bloquer tous les crawlers IA supprime la possibilité que votre contenu apparaisse dans les résultats de recherche IA, les résumés IA ou soit cité par des outils d’IA – ce qui peut diminuer la visibilité auprès des utilisateurs découvrant du contenu via ces nouveaux canaux. À l’inverse, autoriser un accès illimité signifie que votre contenu alimente l’entraînement de l’IA sans compensation et peut réduire le trafic référent lorsque les utilisateurs obtiennent directement des réponses des systèmes IA. Une approche stratégique consiste en un blocage sélectif : autoriser les crawlers de citation comme OAI-SearchBot et PerplexityBot qui génèrent du trafic référent, tout en bloquant les crawlers d’entraînement comme GPTBot et ClaudeBot qui consomment des données sans attribution. Vous pouvez aussi choisir d’autoriser Google-Extended pour préserver votre visibilité dans Google AI Overviews, susceptible de générer beaucoup de trafic, tout en bloquant les crawlers d’entraînement concurrents. La stratégie optimale dépend du type de contenu, du modèle économique et du public visé : les sites d’actualité et éditeurs privilégieront souvent le blocage, tandis que les créateurs de contenus éducatifs peuvent bénéficier d’une visibilité IA plus large.
Surveillance et application
Mettre en place des contrôles de crawlers n’est efficace que si vous vérifiez le respect de vos directives par les bots IA. L’analyse des logs serveur est le principal moyen de surveiller l’activité des crawlers – examinez vos journaux d’accès pour repérer les User-Agent et schémas de requêtes afin d’identifier quels crawlers accèdent à votre site et s’ils respectent vos règles robots.txt. De nombreux crawlers prétendent être conformes tout en continuant d’accéder à des chemins bloqués, rendant la surveillance continue essentielle. Des outils comme Cloudflare Radar offrent une visibilité en temps réel sur les schémas de trafic et aident à repérer des comportements suspects ou non conformes. Configurez des alertes automatiques pour les tentatives d’accès à des ressources bloquées et auditez régulièrement vos logs pour détecter de nouveaux crawlers ou des changements de comportement pouvant indiquer des tentatives de contournement.
Bonnes pratiques et mise en œuvre
Une gestion efficace des crawlers IA exige une approche systématique qui équilibre protection et visibilité stratégique. Suivez ces huit étapes pour établir une stratégie complète de gestion des crawlers :
Auditez l’accès actuel : Analysez vos logs serveur pour identifier les crawlers IA accédant à votre site, leur fréquence et les ressources ciblées
Définissez votre politique : Décidez quels crawlers sont alignés avec vos objectifs – tenez compte des crawlers d’entraînement vs. recherche, de l’impact sur le trafic et de la valeur du contenu
Documentez vos décisions : Rédigez une documentation claire sur votre politique crawler et la logique de chaque choix pour référence future et alignement d’équipe
Implémentez les contrôles : Déployez les règles robots.txt, les en-têtes HTTP et les contrôles avancés comme la limitation de débit ou le blocage IP selon votre politique
Surveillez la conformité : Passez régulièrement en revue vos logs serveur et utilisez des outils de surveillance pour vérifier le respect de vos directives par les crawlers
Configurez des alertes : Mettez en place des alertes automatiques en cas d’accès crawler non conforme ou de tentatives de contournement de vos contrôles
Révisez chaque trimestre : Réévaluez votre stratégie chaque trimestre à mesure que de nouveaux crawlers apparaissent et que vos besoins évoluent
Mettez à jour selon l’émergence de nouveaux crawlers : Restez informé des nouveaux bots IA et adaptez vos contrôles de façon proactive
AmICited.com : Surveillez vos références IA
AmICited.com offre une plateforme spécialisée pour surveiller la manière dont les systèmes d’IA citent et utilisent vos contenus à travers différents modèles et applications. Le service propose un suivi en temps réel de vos citations dans les réponses générées par l’IA, vous aidant à comprendre quels crawlers exploitent le plus activement vos contenus et à quelle fréquence votre travail apparaît dans les productions IA. En analysant les schémas des crawlers et les données de citation, AmICited.com permet de prendre des décisions éclairées pour votre stratégie de gestion des crawlers : vous voyez exactement quels bots apportent de la valeur par des citations et du trafic référent, et ceux qui consomment vos contenus sans attribution. Cette intelligence transforme la gestion des crawlers d’une démarche défensive en un levier stratégique pour optimiser la visibilité et l’impact de vos contenus sur le web piloté par l’IA.
Questions fréquemment posées
Quelle est la différence entre le blocage des crawlers d’entraînement IA et des crawlers de recherche ?
Les crawlers d’entraînement tels que GPTBot et ClaudeBot collectent du contenu pour créer des ensembles de données destinés au développement de grands modèles de langage, consommant votre contenu sans générer de trafic référent. Les crawlers de recherche tels que OAI-SearchBot et PerplexityBot indexent le contenu pour des résultats de recherche IA et peuvent ramener des visiteurs sur votre site via des citations. Bloquer les crawlers d’entraînement protège votre contenu contre son incorporation dans des modèles d’IA, tandis que bloquer les crawlers de recherche peut réduire votre visibilité sur les plateformes de découverte alimentées par l’IA.
Bloquer les crawlers IA peut-il nuire à mon référencement SEO ?
Non. Bloquer les crawlers d’entraînement IA comme GPTBot, ClaudeBot et CCBot n’affecte pas votre classement dans Google ou Bing. Les moteurs de recherche traditionnels utilisent d’autres crawlers (Googlebot, Bingbot) qui fonctionnent indépendamment des bots d’entraînement IA. Ne bloquez les crawlers de recherche traditionnels que si vous souhaitez disparaître complètement des résultats, ce qui nuirait à votre SEO.
Comment savoir quels crawlers accèdent à mon site ?
Examinez les journaux d’accès de votre serveur pour identifier les chaînes User-Agent des crawlers. Recherchez les entrées contenant 'bot', 'crawler' ou 'spider' dans le champ User-Agent. Des outils comme Cloudflare Radar offrent une visibilité en temps réel sur les crawlers IA accédant à votre site et leurs schémas de trafic. Vous pouvez aussi utiliser des plateformes d’analytique différenciant le trafic des bots de celui des visiteurs humains.
Les crawlers IA peuvent-ils ignorer les directives du robots.txt ?
Oui. Le fichier robots.txt est un standard consultatif qui repose sur le respect volontaire des crawlers – il n’est pas imposable. Les crawlers sérieux des grandes entreprises comme OpenAI, Anthropic et Google respectent généralement les directives, mais certains crawlers les ignorent complètement. Pour une meilleure protection, mettez en place un blocage au niveau serveur via .htaccess, des règles de pare-feu ou des restrictions basées sur l’IP.
Faut-il bloquer tous les crawlers IA ou pratiquer un blocage sélectif ?
Cela dépend de vos priorités métiers. Bloquer tous les crawlers d’entraînement protège votre contenu contre son utilisation dans les modèles d’IA tout en permettant éventuellement les crawlers de recherche qui peuvent générer du trafic référent. De nombreux éditeurs pratiquent le blocage sélectif ciblant les crawlers d’entraînement tout en autorisant ceux de recherche et de citation. Tenez compte du type de contenu, des sources de trafic et de votre modèle de monétisation pour définir votre stratégie.
À quelle fréquence dois-je mettre à jour ma politique de gestion des crawlers ?
Révisez et mettez à jour votre politique de gestion des crawlers au moins tous les trimestres. De nouveaux crawlers IA apparaissent régulièrement et les existants changent de User-Agent sans préavis. Suivez des ressources comme le projet ai.robots.txt sur GitHub pour des listes maintenues par la communauté et vérifiez chaque mois vos logs serveur pour identifier les nouveaux crawlers qui visitent votre site.
Quel est l’impact des crawlers IA sur le trafic et les revenus de mon site ?
Les crawlers IA peuvent avoir un impact significatif sur votre trafic et vos revenus. Lorsque les utilisateurs obtiennent directement des réponses via les systèmes d’IA sans visiter votre site, vous perdez le trafic référent et les impressions publicitaires associées. Des études montrent des ratios crawl-to-refer allant jusqu’à 73 000:1 pour certaines plateformes IA, signifiant qu’elles accèdent à votre contenu des milliers de fois pour chaque visiteur renvoyé. Bloquer les crawlers d’entraînement peut protéger votre trafic, tandis qu’autoriser les crawlers de recherche peut apporter quelques bénéfices de référencement.
Comment vérifier que ma configuration robots.txt fonctionne ?
Vérifiez vos logs serveur pour voir si les crawlers bloqués apparaissent toujours dans vos accès. Utilisez des outils de test comme le robots.txt tester de Google Search Console ou celui de Merkle pour valider votre configuration. Accédez directement à votre fichier robots.txt sur votresite.com/robots.txt pour vérifier son contenu. Surveillez régulièrement vos logs pour détecter les crawlers qui devraient être bloqués mais apparaissent encore.
Surveillez comment les systèmes d’IA citent votre contenu
AmICited.com suit en temps réel les références faites à votre marque par l’IA sur ChatGPT, Perplexity, Google AI Overviews et d’autres systèmes. Prenez des décisions éclairées sur votre stratégie de gestion des crawlers.
Impact des crawlers IA sur les ressources serveur : à quoi s’attendre
Découvrez comment les crawlers IA impactent les ressources serveur, la bande passante et la performance. Consultez des statistiques réelles, des stratégies de m...
Les crawlers IA expliqués : GPTBot, ClaudeBot et plus encore
Comprenez comment fonctionnent les crawlers IA comme GPTBot et ClaudeBot, leurs différences avec les crawlers de recherche traditionnels, et comment optimiser v...
Règles WAF pour les crawlers IA : Au-delà de robots.txt
Découvrez comment les pare-feux applicatifs web offrent un contrôle avancé sur les crawlers IA au-delà du robots.txt. Mettez en place des règles WAF pour protég...
11 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.