La chaîne d’identification que les crawlers IA envoient aux serveurs web dans les en-têtes HTTP, utilisée pour le contrôle d’accès, le suivi analytique et la distinction entre bots IA légitimes et scrapers malveillants. Elle identifie le but du crawler, sa version et son origine.
Agent utilisateur des crawlers IA
La chaîne d'identification que les crawlers IA envoient aux serveurs web dans les en-têtes HTTP, utilisée pour le contrôle d'accès, le suivi analytique et la distinction entre bots IA légitimes et scrapers malveillants. Elle identifie le but du crawler, sa version et son origine.
Définition de l’agent utilisateur des crawlers IA
Un agent utilisateur de crawler IA est une chaîne d’en-tête HTTP qui identifie les bots automatisés accédant au contenu web à des fins de formation, d’indexation ou de recherche en intelligence artificielle. Cette chaîne sert d’identité numérique au crawler, indiquant aux serveurs web qui fait la demande et dans quel but. L’agent utilisateur est crucial pour les crawlers IA car il permet aux propriétaires de sites web de reconnaître, suivre et contrôler l’accès à leur contenu par différents systèmes IA. Sans identification correcte de l’agent utilisateur, il devient beaucoup plus difficile de distinguer les crawlers IA légitimes des bots malveillants, ce qui en fait un élément essentiel des pratiques responsables de scraping et de collecte de données.
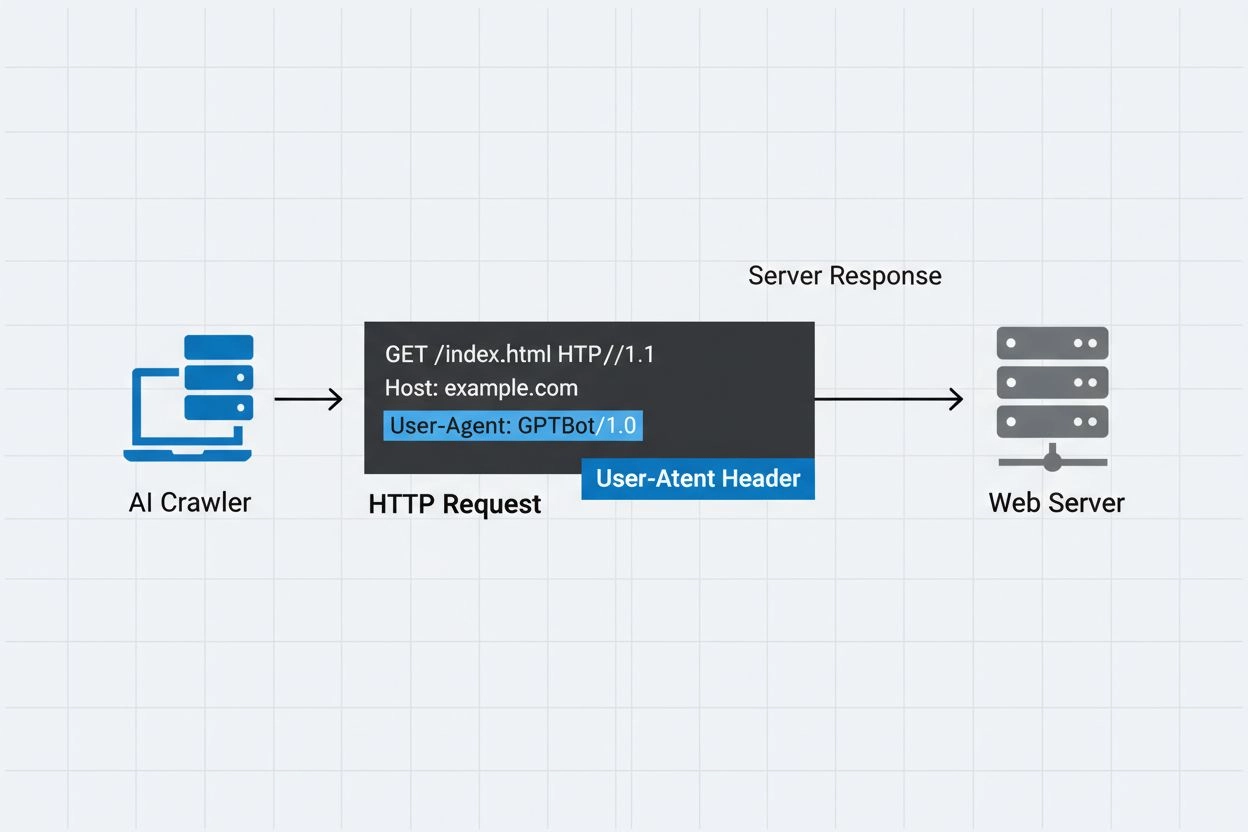
Communication HTTP et en-têtes User-Agent
L’en-tête user-agent est un composant clé des requêtes HTTP, apparaissant dans les en-têtes de chaque navigateur ou bot accédant à une ressource web. Lorsqu’un crawler fait une requête à un serveur web, il inclut des métadonnées le concernant dans les en-têtes HTTP, la chaîne user-agent étant l’un des identifiants les plus importants. Cette chaîne contient généralement des informations sur le nom du crawler, sa version, l’organisation qui l’opère, et souvent une URL ou une adresse email de contact pour vérification. L’agent utilisateur permet aux serveurs d’identifier le client demandeur et de décider s’ils servent le contenu, limitent le débit ou bloquent totalement l’accès. Voici des exemples de chaînes user-agent de grands crawlers IA :
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Nom du crawler
But
Exemple User-Agent
Vérification IP
GPTBot
Collecte de données d’entraînement
Mozilla/5.0…compatible; GPTBot/1.3
Plages IP OpenAI
ClaudeBot
Entraînement de modèles
Mozilla/5.0…compatible; ClaudeBot/1.0
Plages IP Anthropic
OAI-SearchBot
Indexation de recherche
Mozilla/5.0…compatible; OAI-SearchBot/1.3
Plages IP OpenAI
PerplexityBot
Indexation de recherche
Mozilla/5.0…compatible; PerplexityBot/1.0
Plages IP Perplexity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Plusieurs grandes entreprises IA exploitent leurs propres crawlers avec des identifiants user-agent distincts et des objectifs spécifiques. Ces crawlers couvrent divers cas d’usage dans l’écosystème IA :
GPTBot (OpenAI) : collecte des données d’entraînement pour ChatGPT et d’autres modèles OpenAI, respecte les directives robots.txt
ClaudeBot (Anthropic) : collecte du contenu pour l’entraînement des modèles Claude, peut être bloqué via robots.txt
OAI-SearchBot (OpenAI) : indexe le contenu web spécifiquement pour la recherche et les fonctionnalités de recherche IA
PerplexityBot (Perplexity AI) : parcourt le web pour fournir des résultats de recherche et des capacités de recherche sur leur plateforme
Gemini-Deep-Research (Google) : effectue des tâches de recherche approfondie pour le modèle Gemini de Google
Meta-ExternalAgent (Meta) : collecte des données pour la formation et la recherche IA de Meta
Bingbot (Microsoft) : sert à la fois pour l’indexation traditionnelle et la génération de réponses assistées par IA
Chaque crawler dispose de plages d’IP spécifiques et de documentation officielle à laquelle les propriétaires de sites peuvent se référer pour vérifier leur légitimité et mettre en œuvre des contrôles d’accès appropriés.
Usurpation d’agent utilisateur et défis de vérification
Les chaînes d’agent utilisateur peuvent être facilement falsifiées par n’importe quel client effectuant une requête HTTP, ce qui les rend insuffisantes comme unique mécanisme d’authentification pour identifier un crawler IA légitime. Les bots malveillants usurpent fréquemment des chaînes d’agent utilisateur populaires pour masquer leur identité réelle et contourner les mesures de sécurité ou les restrictions de robots.txt. Pour pallier cette vulnérabilité, les experts en sécurité recommandent d’utiliser la vérification IP comme couche supplémentaire d’authentification, en vérifiant que les requêtes proviennent des plages d’IP officielles publiées par les entreprises IA. Le standard émergent RFC 9421 HTTP Message Signatures offre des capacités de vérification cryptographique, permettant aux crawlers de signer numériquement leurs requêtes pour que les serveurs puissent authentifier cryptographiquement leur origine. Cependant, distinguer les crawlers réels des faux reste compliqué, car des attaquants déterminés peuvent usurper à la fois les chaînes user-agent et les adresses IP via des proxys ou des infrastructures compromises. Ce jeu du chat et de la souris entre opérateurs de crawlers et propriétaires de sites soucieux de sécurité évolue constamment à mesure que de nouvelles techniques de vérification sont développées.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Utilisation de robots.txt avec des directives User-Agent
Les propriétaires de sites peuvent contrôler l’accès des crawlers en spécifiant des directives user-agent dans leur fichier robots.txt, permettant un contrôle granulaire sur quels crawlers peuvent accéder à quelles parties de leur site. Le fichier robots.txt utilise des identifiants d’agent utilisateur pour cibler des crawlers spécifiques avec des règles personnalisées, permettant aux propriétaires de sites d’autoriser certains crawlers tout en en bloquant d’autres. Voici un exemple de configuration robots.txt :
Bien que robots.txt offre un mécanisme pratique de contrôle des crawlers, il présente des limites importantes :
Robots.txt est purement informatif et non contraignant ; les crawlers peuvent l’ignorer
Les agents utilisateurs usurpés peuvent contourner complètement les restrictions de robots.txt
La vérification côté serveur par liste blanche d’IP offre une protection plus forte
Les règles de pare-feu applicatif (WAF) peuvent bloquer les requêtes des plages d’IP non autorisées
Combiner robots.txt et la vérification IP offre une stratégie de contrôle d’accès plus robuste
Analyse de l’activité des crawlers via les journaux serveur
Les propriétaires de sites peuvent exploiter les journaux serveur pour suivre et analyser l’activité des crawlers IA, obtenant ainsi une visibilité sur les systèmes IA qui accèdent à leur contenu et à quelle fréquence. En examinant les logs de requêtes HTTP et en filtrant les agents utilisateurs de crawlers IA connus, les administrateurs de sites peuvent comprendre l’impact sur la bande passante et les schémas de collecte de données des différentes entreprises IA. Des outils comme les plateformes d’analyse de logs, les services d’analytique web ou des scripts personnalisés peuvent parser les logs serveur pour identifier le trafic crawler, mesurer la fréquence des requêtes et calculer les volumes de transfert de données. Cette visibilité est particulièrement importante pour les créateurs de contenu et éditeurs qui souhaitent comprendre comment leur travail est utilisé pour l’entraînement IA et s’ils doivent mettre en place des restrictions d’accès. Des services comme AmICited.com jouent un rôle crucial dans cet écosystème en surveillant et suivant la façon dont les systèmes IA citent et référencent le contenu sur le web, offrant ainsi aux créateurs une transparence sur l’utilisation de leur contenu pour l’entraînement IA. Comprendre l’activité des crawlers aide les propriétaires à prendre des décisions éclairées sur leurs politiques de contenu et à négocier avec les entreprises IA concernant les droits d’utilisation des données.
Bonnes pratiques pour la gestion de l’accès des crawlers IA
La gestion efficace de l’accès des crawlers IA nécessite une approche multicouche combinant plusieurs techniques de vérification et de surveillance :
Combiner la vérification user-agent et IP – Ne jamais se fier uniquement aux chaînes user-agent ; toujours croiser avec les plages d’IP officielles publiées par les entreprises IA
Maintenir des listes blanches d’IP à jour – Vérifier et mettre à jour régulièrement les règles de pare-feu avec les dernières plages d’IP d’OpenAI, Anthropic, Google et autres fournisseurs IA
Mettre en place une analyse régulière des logs – Planifier des revues périodiques des journaux serveur pour détecter toute activité suspecte de crawler et des tentatives d’accès non autorisées
Différencier les types de crawlers – Distinguer les crawlers d’entraînement (GPTBot, ClaudeBot) et de recherche (OAI-SearchBot, PerplexityBot) afin d’appliquer les politiques appropriées
Prendre en compte les implications éthiques – Équilibrer les restrictions d’accès avec la réalité que l’entraînement IA bénéficie de sources de contenu diverses et de qualité
Utiliser des services de surveillance – S’appuyer sur des plateformes comme AmICited.com pour suivre l’utilisation et la citation de votre contenu par les systèmes IA, garantir une attribution correcte et comprendre l’impact de votre contenu
En suivant ces pratiques, les propriétaires de sites peuvent garder le contrôle sur leur contenu tout en soutenant le développement responsable des systèmes d’intelligence artificielle.
Questions fréquemment posées
Qu'est-ce qu'une chaîne d'agent utilisateur ?
Un agent utilisateur est une chaîne d'en-tête HTTP qui identifie le client effectuant une requête web. Elle contient des informations sur le logiciel, le système d'exploitation et la version de l'application à l'origine de la demande, qu'il s'agisse d'un navigateur, d'un crawler ou d'un bot. Cette chaîne permet aux serveurs web d'identifier et de suivre les différents types de clients accédant à leur contenu.
Pourquoi les crawlers IA ont-ils besoin de chaînes d'agent utilisateur ?
Les chaînes d'agent utilisateur permettent aux serveurs web d'identifier quel crawler accède à leur contenu, ce qui permet aux propriétaires de sites de contrôler l'accès, de suivre l'activité des crawlers et de différencier les types de bots. C'est essentiel pour gérer la bande passante, protéger le contenu et comprendre comment les systèmes IA utilisent vos données.
Les chaînes d'agent utilisateur peuvent-elles être falsifiées ?
Oui, les chaînes d'agent utilisateur peuvent être facilement usurpées car ce ne sont que des valeurs texte dans les en-têtes HTTP. C'est pourquoi la vérification IP et les signatures de message HTTP sont des méthodes de vérification supplémentaires importantes pour confirmer la véritable identité d'un crawler et empêcher les bots malveillants d'usurper les crawlers légitimes.
Comment puis-je bloquer des crawlers IA spécifiques ?
Vous pouvez utiliser robots.txt avec des directives user-agent pour demander aux crawlers de ne pas accéder à votre site, mais ce n'est pas contraignant. Pour un contrôle plus strict, utilisez la vérification côté serveur, la liste blanche/noire d'IP ou des règles WAF qui vérifient simultanément l'agent utilisateur et l'adresse IP.
Quelle est la différence entre GPTBot et OAI-SearchBot ?
GPTBot est le crawler d'OpenAI pour collecter des données d'entraînement pour des modèles IA comme ChatGPT, tandis que OAI-SearchBot est conçu pour l'indexation et l'alimentation des fonctionnalités de recherche dans ChatGPT. Ils ont des objectifs, des fréquences de crawl et des plages d'IP différentes, nécessitant des stratégies de contrôle d'accès distinctes.
Comment vérifier si un crawler est légitime ?
Vérifiez l'adresse IP du crawler par rapport à la liste officielle publiée par l'opérateur du crawler (par exemple, openai.com/gptbot.json pour GPTBot). Les crawlers légitimes publient leurs plages d'IP et vous pouvez vérifier que les requêtes proviennent de ces plages grâce à des règles de pare-feu ou des configurations WAF.
Qu'est-ce que la vérification de signature de message HTTP ?
Les signatures de messages HTTP (RFC 9421) sont une méthode cryptographique où les crawlers signent leurs requêtes avec une clé privée. Les serveurs peuvent vérifier la signature à l'aide de la clé publique du crawler issue de leur répertoire .well-known, prouvant ainsi que la requête est authentique et n'a pas été modifiée.
Comment AmICited.com aide-t-il à la surveillance des crawlers IA ?
AmICited.com surveille comment les systèmes IA référencent et citent votre marque à travers GPTs, Perplexity, Google AI Overviews et d'autres plateformes IA. Il suit l'activité des crawlers et les mentions IA, vous aidant à comprendre votre visibilité dans les réponses générées par l'IA et comment votre contenu est utilisé.
Surveillez votre marque dans les systèmes IA
Suivez comment les crawlers IA référencent et citent votre contenu sur ChatGPT, Perplexity, Google AI Overviews et d'autres plateformes IA avec AmICited.
Comment identifier les crawlers IA dans les logs serveur : Guide complet de détection
Découvrez comment identifier et surveiller les crawlers IA comme GPTBot, PerplexityBot et ClaudeBot dans vos logs serveur. Découvrez les chaînes user-agent, les...
Quels crawlers IA dois-je autoriser ? Guide complet pour 2025
Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...
Comment autoriser les bots IA à explorer votre site web : Guide complet robots.txt & llms.txt
Découvrez comment autoriser des bots IA comme GPTBot, PerplexityBot et ClaudeBot à explorer votre site. Configurez robots.txt, mettez en place llms.txt, et opti...
17 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.