La stringa di identificazione che i crawler AI inviano ai server web nelle intestazioni HTTP, utilizzata per il controllo degli accessi, il monitoraggio delle analisi e per distinguere i bot AI legittimi dagli scraper dannosi. Identifica lo scopo, la versione e l’origine del crawler.
User-Agent del crawler AI
La stringa di identificazione che i crawler AI inviano ai server web nelle intestazioni HTTP, utilizzata per il controllo degli accessi, il monitoraggio delle analisi e per distinguere i bot AI legittimi dagli scraper dannosi. Identifica lo scopo, la versione e l'origine del crawler.
Definizione di User-Agent del crawler AI
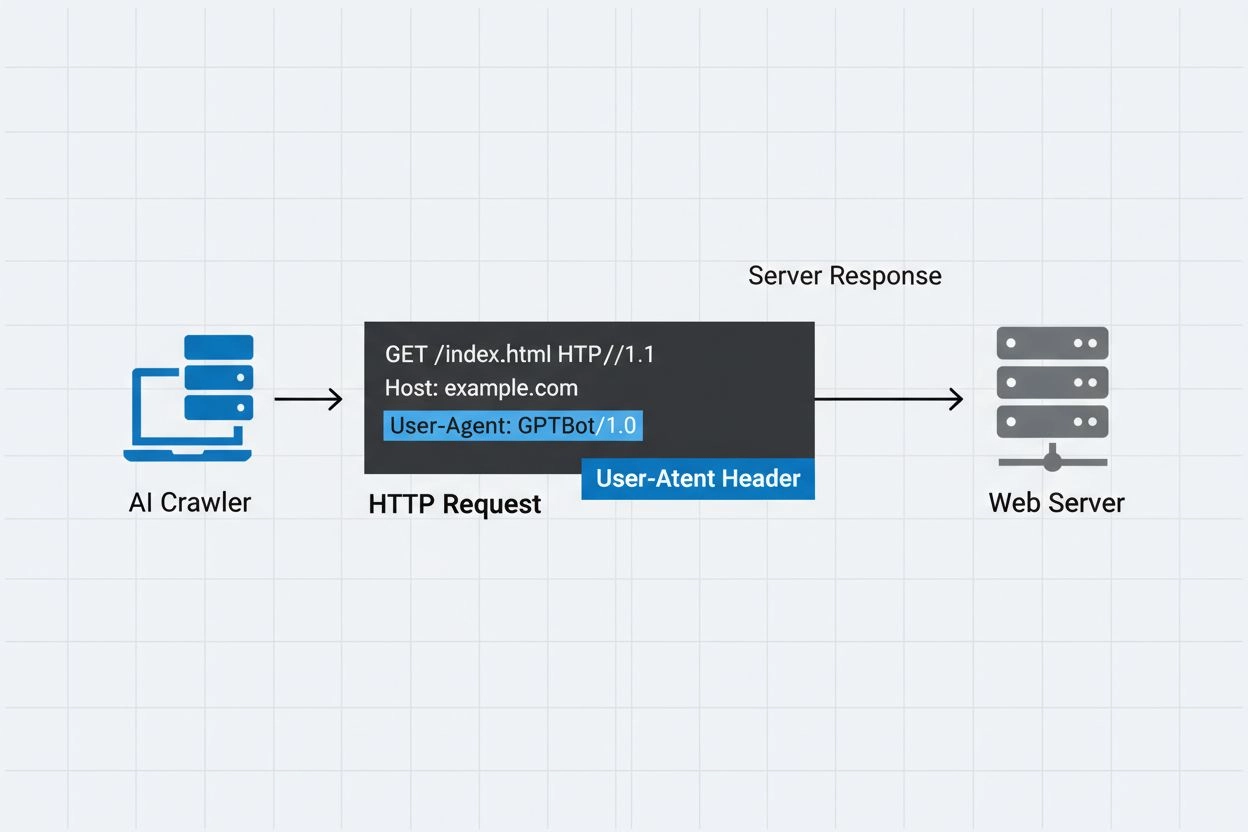
Un user-agent del crawler AI è una stringa dell’intestazione HTTP che identifica i bot automatici che accedono ai contenuti web per scopi di addestramento, indicizzazione o ricerca nell’ambito dell’intelligenza artificiale. Questa stringa funge da identità digitale del crawler, comunicando ai server web chi sta effettuando la richiesta e quali sono le sue intenzioni. Il user-agent è fondamentale per i crawler AI perché consente ai proprietari dei siti di riconoscere, tracciare e controllare come i loro contenuti vengono accessi dai diversi sistemi AI. Senza una corretta identificazione tramite user-agent, distinguere tra crawler AI legittimi e bot dannosi diventa molto più difficile, rendendolo una componente essenziale delle pratiche responsabili di web scraping e raccolta dati.
Comunicazione HTTP e intestazioni User-Agent
L’intestazione user-agent è una componente fondamentale delle richieste HTTP e compare nelle intestazioni che ogni browser e bot invia quando accede a una risorsa web. Quando un crawler effettua una richiesta a un server web, include nei suoi header HTTP dei metadati su sé stesso, con la stringa user-agent come uno degli identificatori più importanti. Questa stringa di solito contiene informazioni sul nome del crawler, la versione, l’organizzazione che lo gestisce e spesso un URL o un’e-mail di contatto per la verifica. Il user-agent consente ai server di identificare il client che effettua la richiesta e di decidere se servire il contenuto, limitare la frequenza delle richieste o bloccare completamente l’accesso. Di seguito alcuni esempi di stringhe user-agent dei principali crawler AI:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Nome Crawler
Scopo
Esempio User-Agent
Verifica IP
GPTBot
Raccolta dati di addestramento
Mozilla/5.0…compatible; GPTBot/1.3
Intervalli IP OpenAI
ClaudeBot
Addestramento modello
Mozilla/5.0…compatible; ClaudeBot/1.0
Intervalli IP Anthropic
OAI-SearchBot
Indicizzazione ricerca
Mozilla/5.0…compatible; OAI-SearchBot/1.3
Intervalli IP OpenAI
PerplexityBot
Indicizzazione ricerca
Mozilla/5.0…compatible; PerplexityBot/1.0
Intervalli IP Perplexity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Diverse aziende AI di rilievo gestiscono i propri crawler con identificativi user-agent distinti e scopi specifici. Questi crawler rappresentano casi d’uso differenti nell’ecosistema AI:
GPTBot (OpenAI): Raccoglie dati di addestramento per ChatGPT e altri modelli OpenAI, rispetta le direttive robots.txt
ClaudeBot (Anthropic): Raccoglie contenuti per addestrare i modelli Claude, può essere bloccato tramite robots.txt
OAI-SearchBot (OpenAI): Indicizza contenuti web specificatamente per funzionalità di ricerca e ricerche AI
PerplexityBot (Perplexity AI): Scansiona il web per fornire risultati di ricerca e capacità di ricerca nella propria piattaforma
Gemini-Deep-Research (Google): Svolge compiti di ricerca avanzata per il modello Gemini di Google
Meta-ExternalAgent (Meta): Raccoglie dati per iniziative di addestramento e ricerca AI di Meta
Bingbot (Microsoft): Serve sia per l’indicizzazione tradizionale che per la generazione di risposte AI
Ogni crawler ha specifici intervalli IP e documentazione ufficiale a cui i proprietari di siti possono fare riferimento per verificarne la legittimità e implementare i corretti controlli di accesso.
Falsificazione user-agent e sfide di verifica
Le stringhe user-agent possono essere facilmente falsificate da qualsiasi client che effettua una richiesta HTTP, rendendole insufficienti come unico meccanismo di autenticazione per identificare i crawler AI legittimi. I bot dannosi spesso imitano stringhe user-agent popolari per mascherare la loro vera identità e aggirare le misure di sicurezza dei siti o le restrizioni del robots.txt. Per affrontare questa vulnerabilità, gli esperti di sicurezza raccomandano di utilizzare la verifica IP come livello aggiuntivo di autenticazione, controllando che le richieste provengano dagli intervalli IP ufficiali pubblicati dalle aziende AI. Lo standard emergente RFC 9421 HTTP Message Signatures offre capacità di verifica crittografica, permettendo ai crawler di firmare digitalmente le loro richieste affinché i server possano verificare crittograficamente l’autenticità. Tuttavia, distinguere tra crawler veri e falsi rimane una sfida perché attaccanti determinati possono falsificare sia le stringhe user-agent sia gli indirizzi IP tramite proxy o infrastrutture compromesse. Questo gioco del gatto e del topo tra operatori di crawler e proprietari di siti attenti alla sicurezza continua a evolvere con lo sviluppo di nuove tecniche di verifica.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Utilizzo di robots.txt con direttive user-agent
I proprietari dei siti possono controllare l’accesso dei crawler specificando direttive user-agent nel file robots.txt, permettendo un controllo granulare su quali crawler possono accedere a quali parti del sito. Il file robots.txt utilizza gli identificatori user-agent per indirizzare specifici crawler con regole personalizzate, consentendo ai proprietari di consentire l’accesso ad alcuni crawler e bloccarne altri. Ecco un esempio di configurazione robots.txt:
Sebbene robots.txt offra un meccanismo comodo per il controllo dei crawler, presenta importanti limitazioni:
Robots.txt ha solo valore consultivo e non è vincolante; i crawler possono ignorarlo
User-agent falsificati possono aggirare completamente le restrizioni di robots.txt
La verifica lato server tramite whitelist di IP garantisce una protezione più forte
Le regole di Web Application Firewall (WAF) possono bloccare richieste da intervalli IP non autorizzati
Combinare robots.txt e verifica IP crea una strategia di controllo più solida
Analisi dell’attività dei crawler tramite log del server
I proprietari dei siti possono sfruttare i log del server per tracciare e analizzare l’attività dei crawler AI, ottenendo visibilità su quali sistemi AI accedono ai loro contenuti e con quale frequenza. Analizzando i log delle richieste HTTP e filtrando i noti user-agent dei crawler AI, gli amministratori possono comprendere l’impatto sulla banda e i pattern di raccolta dati delle diverse aziende AI. Strumenti come piattaforme di analisi dei log, servizi di web analytics e script personalizzati possono elaborare i log server per identificare il traffico dei crawler, misurare la frequenza delle richieste e calcolare i volumi di dati trasferiti. Questa visibilità è particolarmente importante per creatori di contenuti ed editori che vogliono capire come il loro lavoro viene utilizzato per l’addestramento AI e se dovrebbero implementare restrizioni di accesso. Servizi come AmICited.com svolgono un ruolo cruciale in questo ecosistema monitorando e tracciando come i sistemi AI citano e fanno riferimento a contenuti dal web, offrendo ai creatori trasparenza sull’utilizzo dei loro contenuti nell’addestramento AI. Comprendere l’attività dei crawler aiuta i proprietari di siti a prendere decisioni informate sulle proprie policy sui contenuti e a negoziare con le aziende AI in merito ai diritti di utilizzo dei dati.
Best practice per la gestione dell’accesso dei crawler AI
Implementare una gestione efficace dell’accesso dei crawler AI richiede un approccio multilivello che combini diverse tecniche di verifica e monitoraggio:
Combina controllo user-agent e verifica IP – Non affidarti mai solo alle stringhe user-agent; incrocia sempre con gli intervalli IP ufficiali pubblicati dalle aziende AI
Mantieni whitelist di IP aggiornate – Rivedi e aggiorna regolarmente le regole firewall con gli ultimi intervalli IP di OpenAI, Anthropic, Google e altri provider AI
Implementa analisi regolari dei log – Pianifica revisioni periodiche dei log server per identificare attività sospette dei crawler e tentativi di accesso non autorizzati
Distingui tra tipi di crawler – Differenzia tra crawler di training (GPTBot, ClaudeBot) e crawler di ricerca (OAI-SearchBot, PerplexityBot) per applicare policy appropriate
Valuta le implicazioni etiche – Bilancia le restrizioni di accesso con la realtà che l’addestramento AI beneficia di fonti di contenuto diversificate e di alta qualità
Usa servizi di monitoraggio – Sfrutta piattaforme come AmICited.com per tracciare come i tuoi contenuti vengono usati e citati dai sistemi AI, assicurando la corretta attribuzione e comprendendo l’impatto dei tuoi contenuti
Seguendo queste pratiche, i proprietari dei siti possono mantenere il controllo sui propri contenuti supportando allo stesso tempo lo sviluppo responsabile dei sistemi AI.
Domande frequenti
Un user-agent è una stringa nell'intestazione HTTP che identifica il client che effettua una richiesta web. Contiene informazioni sul software, sul sistema operativo e sulla versione dell'applicazione che effettua la richiesta, che si tratti di un browser, di un crawler o di un bot. Questa stringa consente ai server web di identificare e tracciare i diversi tipi di client che accedono ai loro contenuti.
Le stringhe user-agent consentono ai server web di identificare quale crawler sta accedendo ai loro contenuti, permettendo ai proprietari dei siti di controllare l'accesso, monitorare l'attività dei crawler e distinguere tra diversi tipi di bot. Questo è essenziale per gestire la larghezza di banda, proteggere i contenuti e comprendere come i sistemi AI utilizzano i tuoi dati.
Sì, le stringhe user-agent possono essere facilmente falsificate poiché sono solo valori di testo nelle intestazioni HTTP. Ecco perché la verifica tramite IP e le firme dei messaggi HTTP sono importanti metodi di verifica aggiuntivi per confermare la vera identità di un crawler e prevenire che bot dannosi si spaccino per crawler legittimi.
Puoi utilizzare robots.txt con direttive user-agent per richiedere ai crawler di non accedere al tuo sito, ma ciò non è vincolante. Per un controllo più forte, usa verifiche lato server, whitelist/blacklist di IP o regole WAF che controllino contemporaneamente sia user-agent che indirizzo IP.
GPTBot è il crawler di OpenAI per raccogliere dati di addestramento per modelli AI come ChatGPT, mentre OAI-SearchBot è progettato per l'indicizzazione della ricerca e per alimentare le funzioni di ricerca in ChatGPT. Hanno scopi, frequenze di crawling e intervalli di IP diversi, richiedendo strategie di controllo degli accessi distinte.
Controlla l'indirizzo IP del crawler rispetto all'elenco ufficiale pubblicato dall'operatore del crawler (es. openai.com/gptbot.json per GPTBot). I crawler legittimi pubblicano i loro intervalli di IP e puoi verificare che le richieste provengano da tali intervalli tramite regole firewall o configurazioni WAF.
Le firme dei messaggi HTTP (RFC 9421) sono un metodo crittografico in cui i crawler firmano le loro richieste con una chiave privata. I server possono verificare la firma utilizzando la chiave pubblica del crawler dalla loro directory .well-known, dimostrando che la richiesta è autentica e non è stata alterata.
AmICited.com monitora come i sistemi AI fanno riferimento e citano il tuo brand su GPT, Perplexity, Google AI Overviews e altre piattaforme AI. Traccia l'attività dei crawler e le menzioni AI, aiutandoti a capire la tua visibilità nelle risposte generate dall'AI e come vengono utilizzati i tuoi contenuti.
Monitora il tuo brand nei sistemi AI
Traccia come i crawler AI fanno riferimento e citano i tuoi contenuti su ChatGPT, Perplexity, Google AI Overviews e altre piattaforme AI con AmICited.
Come Consentire ai Bot AI di Scansionare il Tuo Sito Web: Guida Completa a robots.txt & llms.txt
Scopri come consentire ai bot AI come GPTBot, PerplexityBot e ClaudeBot di scansionare il tuo sito. Configura robots.txt, imposta llms.txt e ottimizza per la vi...
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
Come Identificare i Crawler AI nei Log del Server: Guida Completa alla Rilevazione
Scopri come identificare e monitorare i crawler AI come GPTBot, PerplexityBot e ClaudeBot nei log del tuo server. Scopri stringhe user-agent, metodi di verifica...
9 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.