Șirul de identificare pe care crawler-ele AI îl transmit serverelor web în anteturile HTTP, utilizat pentru controlul accesului, monitorizarea analiticelor și diferențierea bot-urilor AI legitime de extragătorii rău intenționați. Acesta identifică scopul, versiunea și originea crawler-ului.
AI Crawler User-Agent
Șirul de identificare pe care crawler-ele AI îl transmit serverelor web în anteturile HTTP, utilizat pentru controlul accesului, monitorizarea analiticelor și diferențierea bot-urilor AI legitime de extragătorii rău intenționați. Acesta identifică scopul, versiunea și originea crawler-ului.
Definiția AI Crawler User-Agent
Un user-agent al unui crawler AI este un șir de antet HTTP care identifică bot-urile automate ce accesează conținut web pentru antrenament, indexare sau cercetare în domeniul inteligenței artificiale. Acest șir servește ca identitate digitală a crawler-ului, comunicând serverului web cine face cererea și cu ce intenții. User-agent-ul este crucial pentru crawlerele AI deoarece permite proprietarilor de site-uri să recunoască, să urmărească și să controleze modul în care conținutul lor este accesat de diferite sisteme AI. Fără o identificare corespunzătoare a user-agent-ului, diferențierea între crawlerele AI legitime și bot-urile rău intenționate devine mult mai dificilă, ceea ce îl face o componentă esențială a practicilor responsabile de web scraping și colectare de date.
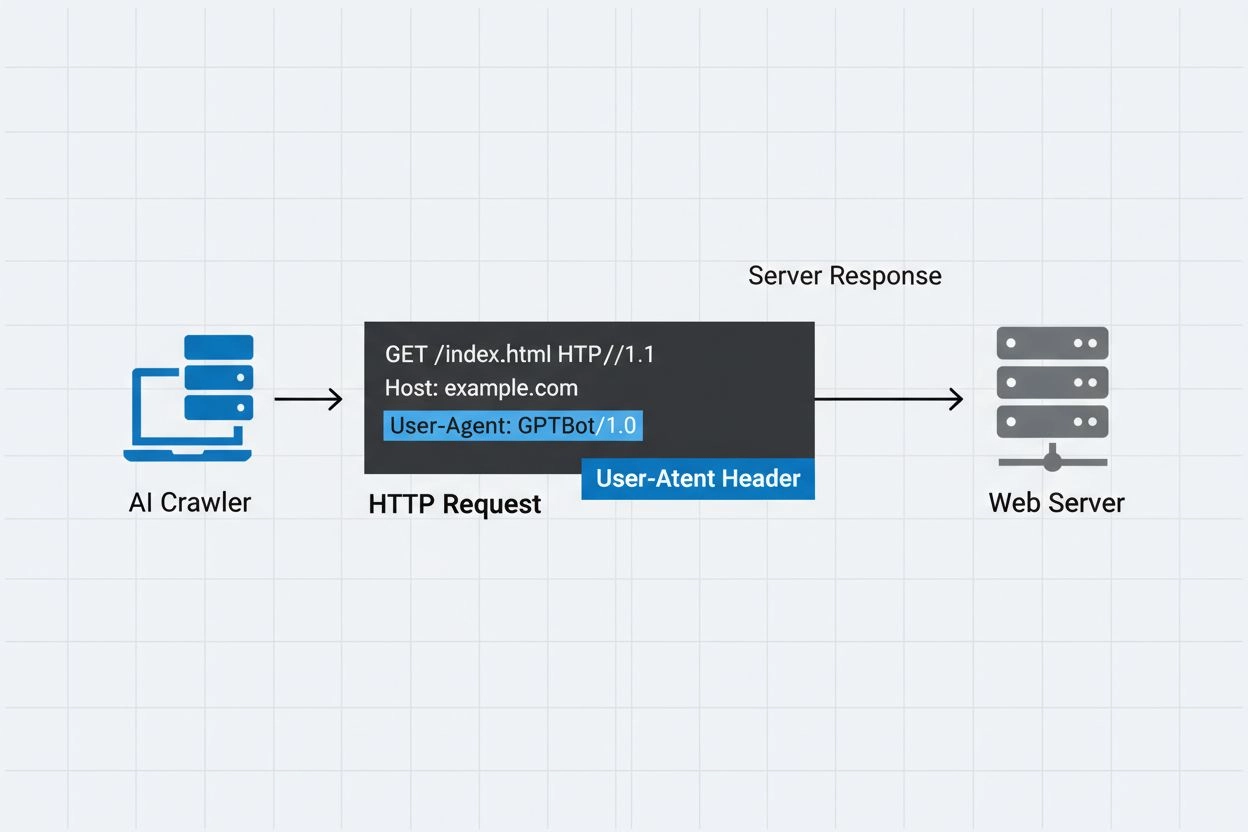
Comunicarea HTTP și Anteturile User-Agent
Antetul user-agent este o componentă critică a cererilor HTTP, apărând în anteturile pe care fiecare browser și bot le trimite la accesarea unei resurse web. Când un crawler face o cerere către un server web, include metadate despre sine în anteturile HTTP, șirul user-agent fiind unul dintre cei mai importanți identificatori. Acest șir conține de obicei informații despre numele crawler-ului, versiunea, organizația care îl operează și adesea o adresă URL sau un e-mail de contact pentru verificare. User-agent-ul permite serverelor să identifice clientul care face cererea și să decidă dacă să ofere conținutul, să limiteze rata cererilor sau să blocheze accesul complet. Mai jos sunt exemple de șiruri user-agent de la principalii crawlere AI:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Nume Crawler
Scop
Exemplu User-Agent
Verificare IP
GPTBot
Colectare date pentru antrenament
Mozilla/5.0…compatible; GPTBot/1.3
Intervalele IP OpenAI
ClaudeBot
Antrenare modele
Mozilla/5.0…compatible; ClaudeBot/1.0
Intervalele IP Anthropic
OAI-SearchBot
Indexare căutare
Mozilla/5.0…compatible; OAI-SearchBot/1.3
Intervalele IP OpenAI
PerplexityBot
Indexare căutare
Mozilla/5.0…compatible; PerplexityBot/1.0
Intervalele IP Perplexity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Mai multe companii AI de top operează propriile crawlere cu identificatori user-agent distincți și scopuri specifice. Aceste crawlere reprezintă diferite cazuri de utilizare în ecosistemul AI:
GPTBot (OpenAI): Colectează date pentru antrenarea ChatGPT și a altor modele OpenAI, respectă directivele robots.txt
ClaudeBot (Anthropic): Adună conținut pentru antrenarea modelelor Claude, poate fi blocat prin robots.txt
OAI-SearchBot (OpenAI): Indexează conținut web special pentru funcționalitatea de căutare și căutare AI
PerplexityBot (Perplexity AI): Crawl-ează web-ul pentru a oferi rezultate de căutare și capabilități de cercetare pe platforma lor
Gemini-Deep-Research (Google): Realizează sarcini de cercetare aprofundată pentru modelul Gemini AI al Google
Meta-ExternalAgent (Meta): Colectează date pentru inițiativele de antrenament și cercetare AI ale Meta
Bingbot (Microsoft): Servește atât pentru indexare tradițională de căutare, cât și pentru generarea de răspunsuri cu AI
Fiecare crawler are intervale IP specifice și documentație oficială pe care proprietarii de site-uri o pot consulta pentru a verifica legitimitatea și a implementa controale de acces adecvate.
Falsificarea User-Agent și Provocările Verificării
Șirurile user-agent pot fi ușor falsificate de orice client care face o cerere HTTP, ceea ce le face insuficiente ca mecanism unic de autentificare pentru identificarea crawler-elor AI legitime. Bot-urile rău intenționate falsifică frecvent șiruri user-agent populare pentru a-și ascunde identitatea reală și pentru a ocoli măsurile de securitate sau restricțiile robots.txt. Pentru a aborda această vulnerabilitate, experții în securitate recomandă utilizarea verificării IP ca strat suplimentar de autentificare, verificând că cererile provin din intervalele oficiale de IP publicate de companiile AI. Standardul emergent RFC 9421 HTTP Message Signatures oferă capabilități de verificare criptografică, permițând crawler-elor să-și semneze digital cererile astfel încât serverele să poată verifica autenticitatea în mod criptografic. Totuși, diferențierea între crawlere reale și false rămâne o provocare, deoarece atacatorii determinați pot falsifica atât șirurile user-agent, cât și adresele IP prin proxy-uri sau infrastructuri compromise. Acest joc de-a șoarecele și pisica între operatorii de crawlere și proprietarii de site-uri atenți la securitate continuă să evolueze pe măsură ce sunt dezvoltate noi tehnici de verificare.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Utilizarea robots.txt cu Directive User-Agent
Proprietarii de site-uri pot controla accesul crawler-elor specificând directive user-agent în fișierul robots.txt, permițând un control granular asupra secțiunilor site-ului accesibile fiecărui crawler. Fișierul robots.txt folosește identificatori user-agent pentru a viza crawlere specifice cu reguli personalizate, permițând proprietarilor de site-uri să permită anumite crawlere și să blocheze altele. Iată un exemplu de configurație robots.txt:
Deși robots.txt oferă un mecanism convenabil pentru controlul crawler-elor, are limitări importante:
Robots.txt este pur consultativ și nu poate fi aplicat cu forța; crawlerele pot ignora regulile
User-agent-urile falsificate pot ocoli complet restricțiile robots.txt
Verificarea la nivel de server prin liste IP permise oferă protecție mai puternică
Regulile Web Application Firewall (WAF) pot bloca cererile din intervale IP neautorizate
Combinarea robots.txt cu verificarea IP creează o strategie de control al accesului mai robustă
Analiza Activității Crawler-elor Prin Log-urile Serverului
Proprietarii de site-uri pot folosi log-urile serverului pentru a urmări și analiza activitatea crawler-elor AI, obținând vizibilitate asupra sistemelor AI care accesează conținutul și asupra frecvenței acestora. Prin examinarea log-urilor cererilor HTTP și filtrarea după user-agent-urile crawler-elor AI cunoscute, administratorii site-ului pot înțelege impactul asupra lățimii de bandă și tiparele de colectare de date ale diferitelor companii AI. Instrumente precum platformele de analiză a log-urilor, serviciile de analiză web și scripturile personalizate pot parsa log-urile serverului pentru a identifica traficul crawler-elor, a măsura frecvența cererilor și a calcula volumele de transfer de date. Această vizibilitate este deosebit de importantă pentru creatorii de conținut și editori care doresc să știe cum este folosită munca lor pentru antrenamentul AI și dacă ar trebui să implementeze restricții de acces. Servicii precum AmICited.com joacă un rol esențial în acest ecosistem, monitorizând și urmărind modul în care sistemele AI citează și menționează conținutul de pe web, oferind creatorilor transparență cu privire la utilizarea conținutului lor în antrenamentul AI. Înțelegerea activității crawler-elor ajută proprietarii de site-uri să ia decizii informate despre politicile de conținut și să negocieze cu companiile AI drepturile de utilizare a datelor.
Cele Mai Bune Practici pentru Managementul Accesului Crawler-elor AI
Implementarea unui management eficient al accesului crawler-elor AI necesită o abordare pe mai multe niveluri, combinând mai multe tehnici de verificare și monitorizare:
Combină verificarea user-agent cu verificarea IP – Nu te baza niciodată doar pe șirurile user-agent; verifică mereu cu intervalele oficiale de IP publicate de companiile AI
Menține liste de IP-uri permise actualizate – Revizuiește și actualizează regulat regulile firewall-ului cu cele mai recente intervale IP de la OpenAI, Anthropic, Google și alți furnizori AI
Implementează analiza regulată a log-urilor – Programează revizuiri periodice ale log-urilor serverului pentru a identifica activitate suspectă a crawler-elor și încercări neautorizate de acces
Fă diferența între tipurile de crawlere – Distinge între crawlere pentru antrenament (GPTBot, ClaudeBot) și crawlere pentru căutare (OAI-SearchBot, PerplexityBot) pentru a aplica politici adecvate
Ia în considerare implicațiile etice – Echilibrează restricțiile de acces cu realitatea că antrenamentul AI beneficiază de surse de conținut diverse și de calitate
Folosește servicii de monitorizare – Utilizează platforme precum AmICited.com pentru a urmări modul în care conținutul tău este folosit și citat de sistemele AI, asigurând atribuirea corectă și înțelegând impactul conținutului tău
Urmând aceste practici, proprietarii de site-uri pot menține controlul asupra conținutului lor, sprijinind în același timp dezvoltarea responsabilă a sistemelor AI.
Întrebări frecvente
Un user-agent este un șir de antet HTTP care identifică clientul ce trimite o cerere web. Conține informații despre software, sistemul de operare și versiunea aplicației care face cererea, fie că este browser, crawler sau bot. Acest șir permite serverelor web să identifice și să urmărească diferite tipuri de clienți care accesează conținutul lor.
Șirurile user-agent permit serverelor web să identifice care crawler accesează conținutul lor, oferind proprietarilor de site-uri control asupra accesului, posibilitatea de a monitoriza activitatea crawler-ului și de a diferenția tipurile de bot-uri. Acest lucru este esențial pentru gestionarea lățimii de bandă, protejarea conținutului și înțelegerea modului în care sistemele AI utilizează datele tale.
Da, șirurile user-agent pot fi ușor falsificate deoarece sunt doar valori text în anteturile HTTP. De aceea, verificarea IP și semnăturile HTTP Message reprezintă metode suplimentare importante de verificare pentru a confirma adevărata identitate a unui crawler și a preveni ca bot-urile rău intenționate să se dea drept crawlere legitime.
Poți folosi robots.txt cu directive user-agent pentru a solicita crawler-elor să nu acceseze site-ul tău, dar acest lucru nu este obligatoriu. Pentru un control mai puternic, folosește verificarea la nivel de server, liste de IP-uri permise/blocate sau reguli WAF care verifică simultan atât user-agent-ul cât și adresa IP.
GPTBot este crawler-ul OpenAI pentru colectarea datelor de antrenament pentru modele AI precum ChatGPT, în timp ce OAI-SearchBot este conceput pentru indexarea căutărilor și pentru funcții de căutare în ChatGPT. Au scopuri, rate de crawl și intervale de IP diferite, necesitând strategii diferite de control al accesului.
Verifică adresa IP a crawler-ului față de lista oficială de IP-uri publicată de operatorul crawler-ului (de exemplu, openai.com/gptbot.json pentru GPTBot). Crawlerele legitime își publică intervalele de IP, iar tu poți verifica dacă cererile provin din acele intervale folosind reguli firewall sau configurații WAF.
HTTP Message Signatures (RFC 9421) este o metodă criptografică prin care crawlerele semnează cererile cu o cheie privată. Serverele pot verifica semnătura folosind cheia publică a crawler-ului din directorul .well-known, dovedind că cererea este autentică și nu a fost modificată.
AmICited.com monitorizează modul în care sistemele AI menționează și citează brandul tău pe GPT-uri, Perplexity, Google AI Overviews și alte platforme AI. Urmărește activitatea crawler-elor și mențiunile AI pentru a te ajuta să înțelegi vizibilitatea ta în răspunsurile generate de AI și modul în care este utilizat conținutul tău.
Monitorizează-ți Brandul în Sisteme AI
Urmărește cum crawler-ele AI menționează și citează conținutul tău pe ChatGPT, Perplexity, Google AI Overviews și alte platforme AI cu AmICited.
Cum să Identifici Crawlerele AI în Jurnalele Serverului: Ghid Complet de Detectare
Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...
Cum pot identifica crawlerii AI în jurnalele serverului? Vreau să înțeleg ce accesează de fapt site-ul meu
Discuție comunitară despre identificarea și analiza activității crawlerilor AI în jurnalele serverului. Profesioniști în SEO tehnic împărtășesc modele de user a...
6 min citire
Discussion
Technical SEO
+1
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.