Définition du mécanisme d’attention
Le mécanisme d’attention est une technique d’apprentissage automatique qui oriente les modèles de deep learning à prioriser (ou « prêter attention à ») les parties les plus pertinentes des données d’entrée lors des prédictions. Plutôt que de traiter tous les éléments d’entrée de manière égale, les mécanismes d’attention calculent des poids d’attention reflétant l’importance relative de chaque élément pour la tâche, puis appliquent ces poids pour insister ou diminuer dynamiquement l’importance de certains éléments. Cette innovation fondamentale est devenue la pierre angulaire des architectures transformers modernes et des grands modèles de langage (LLMs) tels que ChatGPT, Claude et Perplexity, leur permettant de traiter des données séquentielles avec une efficacité et une précision inédites. Le mécanisme s’inspire de l’attention cognitive humaine — la capacité à se concentrer sélectivement sur les détails saillants tout en filtrant les informations non pertinentes — et transpose ce principe biologique en un composant de réseau de neurones mathématiquement rigoureux et apprenable.
Contexte historique et évolution
Le concept de mécanismes d’attention a été introduit pour la première fois par Bahdanau et ses collègues en 2014 pour pallier les limites critiques des réseaux de neurones récurrents (RNN) utilisés en traduction automatique. Avant l’attention, les modèles Seq2Seq reposaient sur un seul vecteur de contexte pour encoder des phrases sources entières, créant un goulet d’étranglement informationnel qui limitait sévèrement les performances sur de longues séquences. Le mécanisme d’attention initial a permis au décodeur d’accéder à tous les états cachés de l’encodeur, et non plus seulement au dernier, sélectionnant dynamiquement les parties de l’entrée les plus pertinentes à chaque étape de décodage. Cette avancée a amélioré de façon spectaculaire la qualité des traductions, en particulier pour les phrases longues. En 2015, Luong et ses collègues ont introduit l’attention à produit scalaire, qui a remplacé l’attention additive coûteuse computationnellement par une multiplication matricielle efficace. Le moment charnière est survenu en 2017 avec la publication de « Attention is All You Need », qui a introduit l’architecture transformer sans aucune récurrence, reposant uniquement sur des mécanismes d’attention. Cette publication a révolutionné le deep learning, rendant possible le développement de BERT, des modèles GPT, et de tout l’écosystème moderne de l’IA générative. Aujourd’hui, les mécanismes d’attention sont omniprésents dans le traitement du langage naturel, la vision par ordinateur et les systèmes IA multimodaux, plus de 85 % des modèles à l’état de l’art intégrant une forme d’architecture basée sur l’attention.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Architecture technique et composants
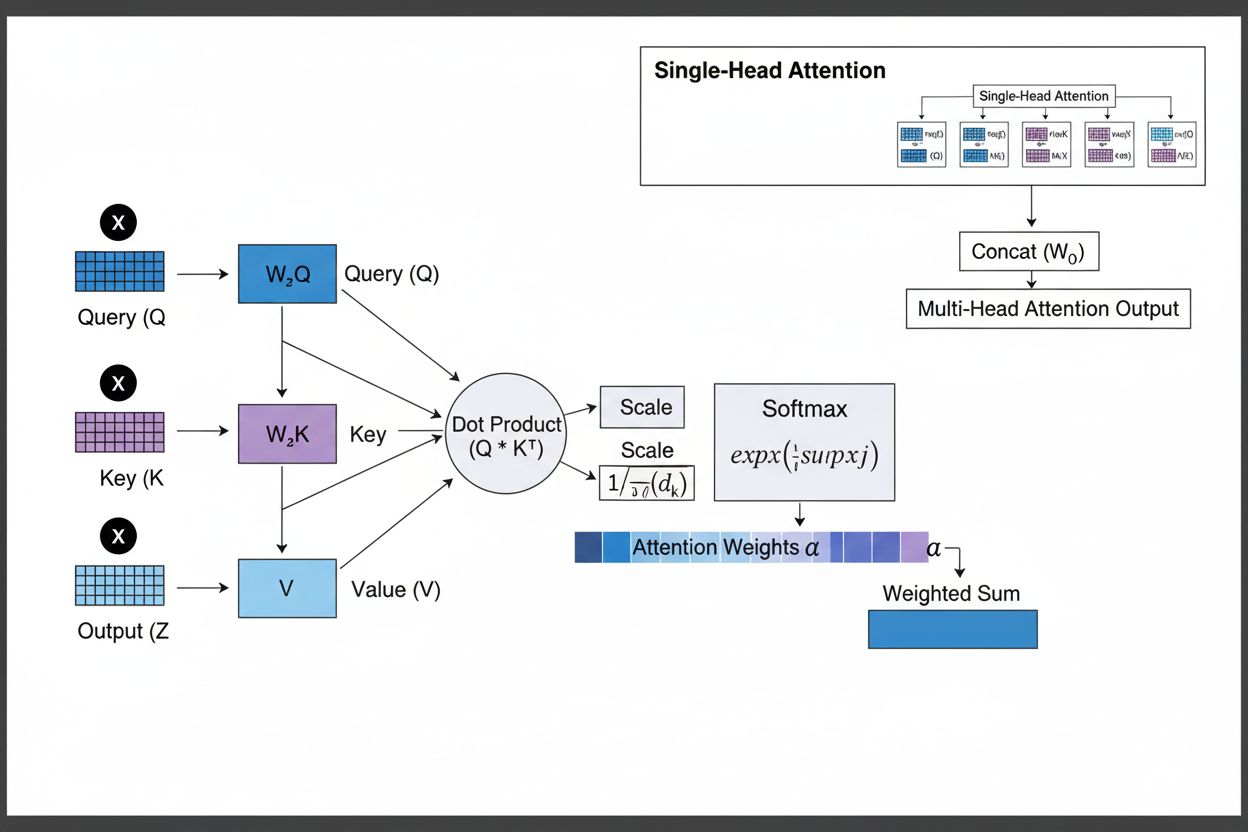
Le mécanisme d’attention fonctionne grâce à une interaction sophistiquée entre trois composants mathématiques : requêtes (Q), clés (K) et valeurs (V). Chaque élément d’entrée est transformé en ces trois représentations au moyen de projections linéaires apprises, créant une structure analogue à une base de données relationnelle où les clés servent d’identifiants et les valeurs contiennent l’information réelle. Le mécanisme calcule des scores d’alignement en mesurant la similarité entre une requête et toutes les clés, généralement via l’attention à produit scalaire normalisé où le score est calculé comme QK^T/√d_k. Ces scores bruts sont ensuite normalisés par la fonction softmax, qui les convertit en une distribution de probabilité dont la somme est égale à 1, garantissant que chaque élément reçoit un poids entre 0 et 1. La dernière étape consiste à calculer une somme pondérée des vecteurs de valeur à l’aide de ces poids d’attention, produisant un vecteur de contexte représentant les informations les plus pertinentes de toute la séquence d’entrée. Ce vecteur de contexte est ensuite combiné avec l’entrée originale via des connexions résiduelles et transmis à des couches feedforward, permettant au modèle d’affiner itérativement sa compréhension de l’entrée. L’élégance mathématique de cette conception — associant transformations apprenables, calculs de similarité et pondérations probabilistes — permet aux mécanismes d’attention de capturer des dépendances complexes tout en restant pleinement différentiables pour l’optimisation par gradient.
Comparaison des variantes du mécanisme d’attention
| Type d’attention | Méthode de calcul | Complexité computationnelle | Cas d’usage idéal | Avantage clé |
|---|
| Attention additive | Réseau feed-forward + activation tanh | O(n·d) par requête | Séquences courtes, dimensions variables | Gère différentes dimensions requête/clé |
| Attention à produit scalaire | Multiplication matricielle simple | O(n·d) par requête | Séquences standards | Efficace computationnellement |
| Produit scalaire normalisé | QK^T/√d_k + softmax | O(n·d) par requête | Transformers modernes | Prévient la disparition des gradients |
| Attention multi-tête | Plusieurs têtes d’attention parallèles | O(h·n·d) où h=têtes | Relations complexes | Capture divers aspects sémantiques |
| Self-attention | Requêtes, clés, valeurs d’une même séquence | O(n²·d) | Relations intra-séquence | Permet le traitement parallèle |
| Cross-attention | Requêtes d’une séquence, clés/valeurs d’une autre | O(n·m·d) | Encodeur-décodeur, multimodal | Aligne différentes modalités |
| Grouped Query Attention | Partage clés/valeurs entre têtes requête | O(n·d) | Inférence efficace | Réduit mémoire et calcul |
| Attention clairsemée | Attention limitée à positions locales/échelonnées | O(n·√n·d) | Très longues séquences | Gère les séquences extrêmes |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Fonctionnement pratique des mécanismes d’attention
Le mécanisme d’attention fonctionne grâce à une séquence rigoureusement orchestrée de transformations mathématiques permettant aux réseaux de neurones de se focaliser dynamiquement sur l’information pertinente. Lors du traitement d’une séquence d’entrée, chaque élément est d’abord encodé dans un espace vectoriel de haute dimension, capturant des informations sémantiques et syntaxiques. Ces embeddings sont ensuite projetés dans trois espaces distincts à l’aide de matrices de poids apprises : l’espace des requêtes (ce que cherche le modèle), l’espace des clés (ce que chaque élément contient), et l’espace des valeurs (l’information à agréger). Pour chaque position de requête, le mécanisme calcule un score de similarité avec chaque clé via leur produit scalaire, produisant un vecteur de scores d’alignement bruts. Ces scores sont normalisés en les divisant par la racine carrée de la dimension des clés (√d_k), étape critique pour éviter que les produits scalaires ne deviennent trop grands dans de grands espaces, ce qui entraînerait la disparition des gradients lors de la rétropropagation. Les scores normalisés sont ensuite passés dans une fonction softmax, qui exponentie chaque score et les normalise pour que leur somme soit 1, créant une distribution de probabilité sur toutes les positions d’entrée. Enfin, ces poids d’attention servent à calculer une moyenne pondérée des vecteurs de valeur, les positions ayant les poids les plus élevés contribuant davantage au vecteur de contexte final. Ce vecteur de contexte est ensuite combiné à l’entrée originale via des connexions résiduelles et traité par des couches feedforward, permettant au modèle d’affiner itérativement ses représentations. L’ensemble du processus est différentiable, permettant au modèle d’apprendre des schémas d’attention optimaux par descente de gradient lors de l’entraînement.
Les mécanismes d’attention constituent la brique fondamentale des architectures transformers, qui sont devenues le paradigme dominant en deep learning. Contrairement aux RNN qui traitent les séquences de manière séquentielle et aux CNN qui opèrent sur des fenêtres locales fixes, les transformers utilisent la self-attention pour permettre à chaque position de prêter attention à toutes les autres simultanément, autorisant une parallélisation massive sur GPU et TPU. L’architecture transformer est composée de couches alternées de self-attention multi-tête et de réseaux feedforward, chaque couche d’attention permettant au modèle d’affiner sa compréhension de l’entrée en se concentrant sélectivement sur différents aspects. L’attention multi-tête exécute plusieurs mécanismes d’attention en parallèle, chaque tête apprenant à se focaliser sur des types de relations différents — une tête pouvant se spécialiser dans les dépendances grammaticales, une autre dans les relations sémantiques, une troisième dans les coréférences à longue distance. Les sorties de toutes les têtes sont concaténées et projetées, permettant au modèle de rester conscient de multiples phénomènes linguistiques simultanément. Cette architecture s’est avérée extrêmement efficace pour les grands modèles de langage tels que GPT-4, Claude 3 et Gemini, qui utilisent des architectures transformer décodeur seul où chaque token ne peut prêter attention qu’aux tokens précédents (masquage causal) afin de conserver la propriété générative autoregressive. La capacité du mécanisme d’attention à capturer les dépendances à longue portée sans les problèmes de disparition de gradient ayant affecté les RNN a été déterminante pour permettre à ces modèles de traiter des fenêtres de contexte de plus de 100 000 tokens, en maintenant cohérence et consistance sur de vastes textes. Des études montrent qu’environ 92 % des modèles NLP à l’état de l’art s’appuient désormais sur des architectures transformers propulsées par des mécanismes d’attention, démontrant leur importance fondamentale dans les systèmes IA modernes.
Mécanismes d’attention dans la recherche IA et la surveillance
Dans le contexte des plateformes de recherche IA comme ChatGPT, Perplexity, Claude et Google AI Overviews, les mécanismes d’attention jouent un rôle crucial pour déterminer quelles parties des documents récupérés et des bases de connaissances sont les plus pertinentes pour les requêtes des utilisateurs. Lorsque ces systèmes génèrent des réponses, leurs mécanismes d’attention pondèrent dynamiquement différentes sources et passages selon leur pertinence, leur permettant de synthétiser des réponses cohérentes à partir de multiples sources tout en maintenant la véracité. Les poids d’attention calculés lors de la génération peuvent être analysés pour comprendre quelles informations le modèle a privilégiées, offrant un aperçu de la façon dont les systèmes IA interprètent et répondent aux requêtes. Pour la surveillance de marque et la GEO (Generative Engine Optimization), comprendre les mécanismes d’attention est essentiel car ils déterminent quels contenus et sources sont mis en avant dans les réponses générées par IA. Un contenu structuré pour coïncider avec la façon dont les mécanismes d’attention pondèrent l’information — via des définitions claires d’entités, des sources faisant autorité et une pertinence contextuelle — a plus de chances d’être cité et mis en avant dans les réponses IA. AmICited exploite les mécanismes d’attention pour suivre comment les marques et domaines apparaissent sur les plateformes IA, en reconnaissant que les citations pondérées par l’attention représentent les mentions les plus influentes dans le contenu généré par IA. À mesure que les entreprises surveillent de plus en plus leur présence dans les réponses IA, comprendre que les mécanismes d’attention pilotent les schémas de citation devient crucial pour optimiser sa stratégie de contenu et garantir la visibilité de la marque à l’ère de l’IA générative.
Aspects clés et considérations de mise en œuvre
- Efficacité computationnelle : l’attention à produit scalaire normalisé permet une complexité O(n²) avec une parallélisation massive, la rendant pratique pour des séquences de milliers de tokens sur GPU modernes
- Flux de gradients : le facteur de normalisation (1/√d_k) prévient la disparition des gradients, garantissant un entraînement stable de réseaux très profonds avec de nombreuses couches d’attention
- Interprétabilité : les poids d’attention offrent des visualisations interprétables montrant quels éléments d’entrée ont influencé des prédictions spécifiques, augmentant la transparence des modèles
- Encodage positionnel : les transformers nécessitent une information positionnelle explicite via des encodages sinusoïdaux ou rotatifs, car l’attention ne préserve pas intrinsèquement l’ordre des séquences
- Masquage causal : les modèles autoregressifs comme GPT utilisent le masquage causal pour empêcher les tokens de prêter attention aux positions futures, maintenant la propriété générative
- Efficacité mémoire : des variantes comme grouped query attention et l’attention clairsemée réduisent les besoins en mémoire de O(n²) à O(n·√n) pour les très longues séquences
- Attention multi-échelle : différentes têtes d’attention apprennent à se concentrer sur différents niveaux de contexte, des relations locales entre mots aux thèmes de niveau document
- Alignement cross-modal : la cross-attention permet à des modèles comme Stable Diffusion d’aligner des invites textuelles avec la génération d’images, et aux modèles vision-langage d’ancrer le langage dans l’information visuelle
Évolution et perspectives futures
Le domaine des mécanismes d’attention évolue rapidement, avec des chercheurs développant des variantes de plus en plus sophistiquées pour surmonter les limites computationnelles et améliorer les performances. Les motifs d’attention clairsemée limitent l’attention à des voisinages locaux ou positions échelonnées, réduisant la complexité de O(n²) à O(n·√n) tout en maintenant les performances sur de très longues séquences. Les mécanismes d’attention efficace comme FlashAttention optimisent les schémas d’accès mémoire du calcul d’attention, obtenant des accélérations de 2 à 4x grâce à une meilleure utilisation des GPU. La grouped query attention et la multi-query attention réduisent le nombre de têtes clé-valeur tout en maintenant les performances, diminuant significativement la mémoire requise lors de l’inférence — un critère déterminant pour le déploiement de grands modèles en production. Les architectures mixture of experts combinent attention et routage clairsemé, permettant de passer à des modèles de plusieurs trillions de paramètres tout en maintenant l’efficacité computationnelle. Des recherches émergentes explorent les schémas d’attention appris qui s’adaptent dynamiquement selon les caractéristiques de l’entrée, ainsi que l’attention hiérarchique opérant à plusieurs niveaux d’abstraction. L’intégration des mécanismes d’attention à la génération augmentée par récupération (RAG) permet aux modèles de prêter attention dynamiquement à des connaissances externes pertinentes, améliorant la factualité et réduisant les hallucinations. À mesure que les systèmes IA sont déployés dans des applications critiques, les mécanismes d’attention sont enrichis de fonctionnalités d’explicabilité offrant une meilleure compréhension des prises de décision des modèles. L’avenir verra probablement des architectures hybrides combinant attention et mécanismes alternatifs comme les state-space models (exemplifiés par Mamba), qui offrent une complexité linéaire tout en maintenant des performances compétitives. Comprendre ces évolutions des mécanismes d’attention est essentiel pour les praticiens développant la prochaine génération de systèmes IA et pour les organisations surveillant leur présence dans le contenu généré par IA, car les mécanismes qui déterminent les schémas de citation et la mise en avant du contenu ne cessent de progresser.
Mécanismes d’attention et schémas de citation IA
Pour les organisations utilisant AmICited afin de surveiller la visibilité de leur marque dans les réponses IA, comprendre les mécanismes d’attention fournit un contexte essentiel pour interpréter les schémas de citation. Lorsque ChatGPT, Claude ou Perplexity citent votre domaine dans leurs réponses, ce sont les poids d’attention calculés lors de la génération qui ont déterminé que votre contenu était le plus pertinent pour la requête de l’utilisateur. Un contenu de qualité, bien structuré, définissant clairement les entités et apportant une information faisant autorité, reçoit naturellement des poids d’attention plus élevés, augmentant la probabilité d’être sélectionné pour citation. Les fonctionnalités de visualisation de l’attention présentes sur certaines plateformes IA révèlent les sources ayant reçu le plus d’attention lors de la génération des réponses, indiquant ainsi quelles citations ont été les plus influentes. Cette compréhension permet aux organisations d’optimiser leur stratégie de contenu en sachant que les mécanismes d’attention récompensent la clarté, la pertinence et la qualité des sources. À mesure que la recherche IA se développe — plus de 60 % des entreprises investissant désormais dans l’IA générative — la capacité à comprendre et à optimiser pour les mécanismes d’attention devient de plus en plus précieuse pour maintenir la visibilité de la marque et garantir une représentation fidèle dans le contenu généré par IA. L’intersection entre mécanismes d’attention et surveillance de marque représente un nouveau front de la GEO, où comprendre les fondements mathématiques de la pondération et de la citation par l’IA se traduit directement par une visibilité et une influence accrues dans l’écosystème de l’IA générative.