Ancrage du contenu
Découvrez ce qu’est l’ancrage du contenu, comment il prévient les hallucinations de l’IA et pourquoi il est essentiel pour des systèmes d’IA fiables. Découvrez ...
10 min de lecture
La mise entre crochets contextuelle est une technique d’optimisation du contenu qui établit des limites claires autour des informations afin d’éviter l’interprétation erronée et les hallucinations des IA. Elle utilise des délimiteurs explicites et des marqueurs de contexte pour s’assurer que les modèles d’IA comprennent précisément où commencent et où finissent les informations pertinentes, empêchant ainsi la génération de réponses basées sur des suppositions ou des détails inventés.
La mise entre crochets contextuelle est une technique d’optimisation du contenu qui établit des limites claires autour des informations afin d’éviter l’interprétation erronée et les hallucinations des IA. Elle utilise des délimiteurs explicites et des marqueurs de contexte pour s’assurer que les modèles d’IA comprennent précisément où commencent et où finissent les informations pertinentes, empêchant ainsi la génération de réponses basées sur des suppositions ou des détails inventés.
La mise entre crochets contextuelle est une technique d’optimisation du contenu qui établit des limites claires autour des informations pour éviter l’interprétation erronée et les hallucinations des IA. Cette méthode consiste à utiliser des délimiteurs explicites—tels que des balises XML, des en-têtes markdown ou des caractères spéciaux—pour marquer le début et la fin de blocs d’informations spécifiques, créant ce que les experts appellent une « frontière de contexte ». En structurant les prompts et les données avec ces marqueurs clairs, les développeurs s’assurent que les modèles d’IA comprennent précisément où commencent et où finissent les informations pertinentes, empêchant le modèle de générer des réponses sur la base de suppositions ou de détails inventés. La mise entre crochets contextuelle représente une évolution de l’ingénierie de prompt traditionnelle, s’étendant à la discipline plus large de l’ingénierie contextuelle, qui vise à optimiser toutes les informations fournies à un LLM pour obtenir les résultats souhaités. La technique est particulièrement précieuse dans les environnements de production où l’exactitude et la cohérence sont essentielles, car elle fournit des garde-fous mathématiques et structurels qui guident le comportement de l’IA sans nécessiter de logique conditionnelle complexe.
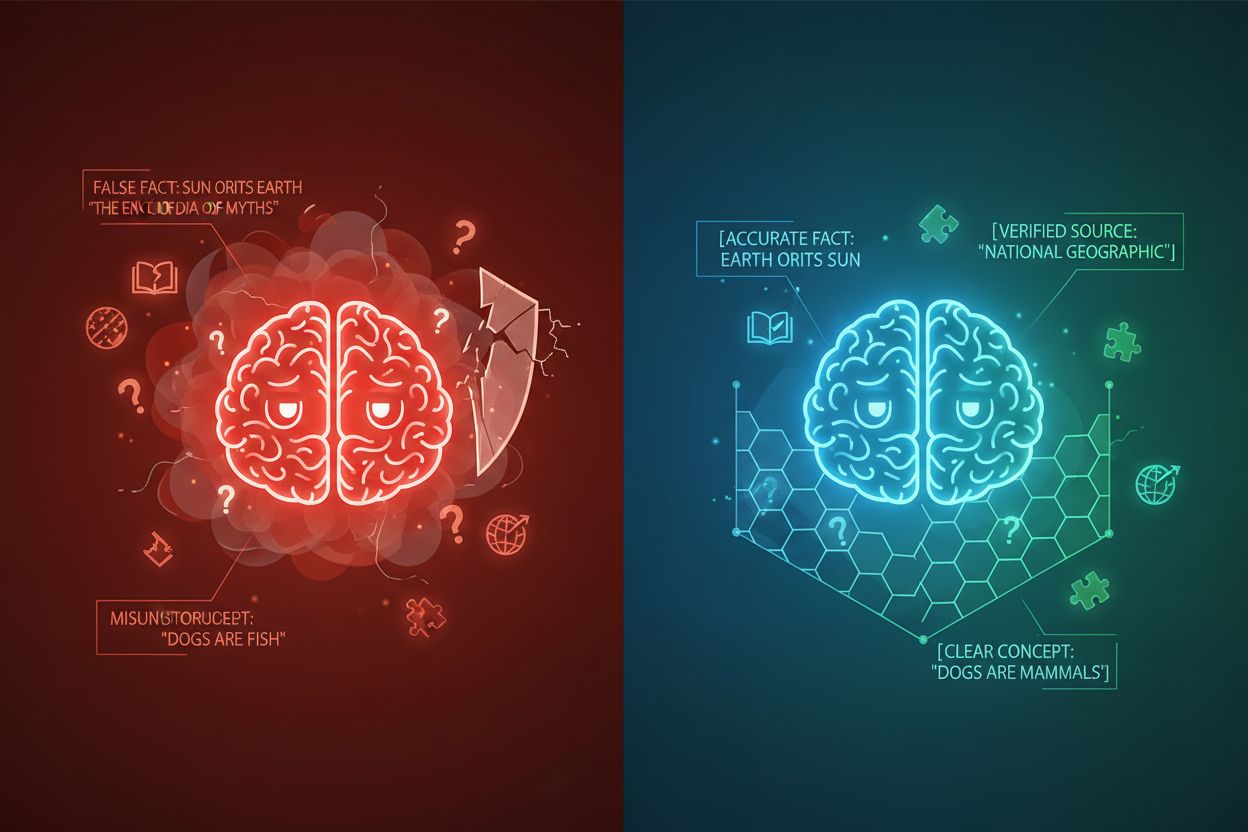
L’hallucination d’IA se produit lorsque les modèles de langage génèrent des réponses qui ne s’appuient pas sur des informations factuelles ou sur le contexte fourni, ce qui entraîne des faits erronés, des déclarations trompeuses ou des références à des sources inexistantes. Les recherches montrent que les chatbots inventent des faits environ 27 % du temps, avec 46 % de leurs textes contenant des erreurs factuelles, tandis que les citations journalistiques de ChatGPT étaient erronées dans 76 % des cas. Ces hallucinations proviennent de multiples sources : les modèles peuvent apprendre des schémas à partir de données d’entraînement biaisées ou incomplètes, mal comprendre la relation entre les tokens, ou manquer de contraintes suffisantes pour limiter les sorties possibles. Les conséquences sont graves dans tous les secteurs—en santé, les hallucinations peuvent entraîner des diagnostics incorrects et des interventions médicales inutiles ; dans le domaine juridique, elles peuvent conduire à la fabrication de citations de jurisprudence (comme dans l’affaire Mata c. Avianca où un avocat a été sanctionné pour avoir utilisé de fausses citations juridiques générées par ChatGPT) ; en entreprise, elles gaspillent des ressources à travers des analyses et prévisions erronées. Le problème fondamental est que, sans frontières contextuelles claires, les modèles d’IA opèrent dans un vide informationnel où ils sont plus susceptibles de « combler les vides » avec des informations plausibles mais inexactes, considérant l’hallucination comme une fonctionnalité plutôt qu’un bug.
| Type d’hallucination | Fréquence | Impact | Exemple |
|---|---|---|---|
| Inexactitudes factuelles | 27-46% | Propagation de fausses informations | Fausse description de produit |
| Fabrication de sources | 76% (citations) | Perte de crédibilité | Citations inexistantes |
| Concepts mal compris | Variable | Analyse incorrecte | Mauvais précédents juridiques |
| Schémas biaisés | Continu | Sorties discriminatoires | Réponses stéréotypées |
L’efficacité de la mise entre crochets contextuelle repose sur cinq principes fondamentaux :
Utilisation des délimiteurs : Employer des marqueurs cohérents et non ambigus (balises XML comme <context>, en-têtes markdown, caractères spéciaux) pour délimiter clairement les blocs d’informations et empêcher le modèle de confondre les frontières entre différentes sources de données ou types d’instructions.
Gestion de la fenêtre de contexte : Allouer stratégiquement les tokens entre les instructions système, les entrées utilisateur et les connaissances récupérées, en veillant à ce que les informations les plus pertinentes occupent le budget d’attention limité du modèle tandis que les détails moins critiques sont filtrés ou récupérés à la demande.
Hiérarchie de l’information : Établir des niveaux de priorité clairs pour les différents types d’informations, signalant au modèle quelles données doivent être considérées comme sources d’autorité et lesquelles constituent un contexte supplémentaire, afin d’éviter que les informations primaires et secondaires soient pondérées de manière égale.
Définition des frontières : Indiquer explicitement quelles informations le modèle doit considérer et lesquelles il doit ignorer, créant des limites strictes qui empêchent le modèle d’extrapoler au-delà des données fournies ou de faire des suppositions sur des informations non explicites.
Marqueurs de portée : Utiliser des éléments structurels pour indiquer la portée des instructions, des exemples et des données, précisant si les indications s’appliquent globalement, à des sections spécifiques ou uniquement à certains types de requêtes.
La mise en œuvre de la mise entre crochets contextuelle nécessite une attention particulière à la structuration et à la présentation de l’information aux modèles d’IA. Le formatage structuré des entrées à l’aide de schémas JSON ou XML offre des définitions de champs explicites qui guident le comportement du modèle—par exemple, en enveloppant les requêtes utilisateur dans des balises <user_query> et les sorties attendues dans <expected_output>, on crée des frontières sans ambiguïté. Les prompts système doivent être organisés en sections distinctes à l’aide d’en-têtes markdown ou de balises XML : <background_information>, <instructions>, <tool_guidance> et <output_description> ont chacun un objectif précis et aident le modèle à comprendre la hiérarchie de l’information. Les exemples few-shot doivent inclure du contexte entre crochets montrant exactement comment le modèle doit structurer ses réponses, avec des délimiteurs clairs autour des entrées et des sorties. Les définitions d’outils bénéficient de descriptions explicites des paramètres et de contraintes d’utilisation, empêchant le modèle d’utiliser des outils hors de leur portée prévue. Les systèmes de génération augmentée par récupération (RAG) peuvent mettre en œuvre la mise entre crochets contextuelle en enveloppant les documents récupérés dans des marqueurs de source (<source>nom_document</source>) et en utilisant des scores d’ancrage pour vérifier que les réponses générées restent dans les limites de l’information récupérée. Par exemple, la fonctionnalité de délimitation contextuelle de CustomGPT fonctionne en entraînant les modèles uniquement sur les ensembles de données téléchargés, garantissant que les réponses ne sortent jamais de la base de connaissances fournie—une mise en œuvre pratique de la mise entre crochets contextuelle au niveau de l’architecture.
Bien que la mise entre crochets contextuelle partage des similitudes avec des techniques connexes, elle occupe une position distincte dans le paysage de l’ingénierie de l’IA. L’ingénierie de prompt basique se concentre principalement sur la création d’instructions et d’exemples efficaces, mais ne propose pas d’approche systématique de gestion de tous les éléments de contexte, contrairement à la mise entre crochets contextuelle. L’ingénierie contextuelle, la discipline plus large, englobe la mise entre crochets contextuelle comme un composant parmi d’autres—elle inclut l’optimisation des prompts, la conception d’outils, la gestion de la mémoire et la récupération dynamique de contexte, faisant d’elle un sur-ensemble de l’approche plus ciblée de la mise entre crochets contextuelle. Le simple suivi des instructions repose sur la capacité du modèle à comprendre des directives en langage naturel sans frontières structurelles explicites, ce qui échoue souvent lorsque les instructions sont complexes ou que le modèle rencontre des situations ambiguës. Les garde-fous et systèmes de validation opèrent au niveau de la sortie, vérifiant les réponses après leur génération, tandis que la mise entre crochets contextuelle agit au niveau de l’entrée afin de prévenir les hallucinations avant qu’elles ne se produisent. La distinction clé est que la mise entre crochets contextuelle est préventive et structurelle—elle façonne le paysage informationnel dans lequel le modèle opère—plutôt que corrective ou réactive, ce qui la rend plus efficace et fiable pour garantir l’exactitude en production.
La mise entre crochets contextuelle apporte une valeur mesurable dans des applications variées. Les chatbots de service client utilisent des frontières contextuelles pour limiter les réponses à des bases de connaissances validées par l’entreprise, empêchant les agents d’inventer des fonctionnalités produit ou de prendre des engagements non autorisés. Les systèmes d’analyse de documents juridiques entourent la jurisprudence pertinente, les lois et les précédents afin que l’IA ne référence que des sources vérifiées et ne fabrique pas de citations juridiques. Les systèmes médicaux d’IA instaurent des frontières strictes autour des recommandations cliniques, des données patient et des protocoles de traitement approuvés, évitant ainsi des hallucinations dangereuses pour les patients. Les plateformes de génération de contenu utilisent la mise entre crochets contextuelle pour appliquer les directives de marque, le ton et les contraintes factuelles, garantissant que le contenu généré est conforme aux standards organisationnels. Les outils de recherche et d’analyse encadrent les sources primaires, les jeux de données et les informations vérifiées, permettant à l’IA de synthétiser des analyses tout en maintenant une attribution claire et en évitant l’invention de statistiques ou d’études. AmICited.com illustre ce principe en surveillant la façon dont les systèmes d’IA citent et référencent les marques à travers GPTs, Perplexity et Google AI Overviews—en suivant si les modèles d’IA restent dans les frontières contextuelles appropriées lorsqu’ils évoquent des entreprises ou produits spécifiques, aidant les organisations à comprendre si l’IA hallucine sur leur marque ou représente fidèlement leurs informations.
Réussir la mise en œuvre de la mise entre crochets contextuelle nécessite le respect de bonnes pratiques éprouvées :
Commencer avec le minimum de contexte : Débutez avec l’ensemble d’informations le plus restreint possible pour des réponses précises, puis élargissez uniquement lorsque les tests révèlent des lacunes, afin d’éviter la pollution du contexte et de maintenir la concentration du modèle.
Utiliser des schémas de délimiteurs cohérents : Établissez et maintenez des conventions de délimiteurs uniformes dans tout votre système, facilitant ainsi la reconnaissance des frontières par le modèle et réduisant la confusion liée à un formatage incohérent.
Tester et valider les frontières : Testez systématiquement si le modèle respecte les frontières définies en tentant de le pousser à les dépasser, identifiant et fermant les failles avant le déploiement.
Surveiller la dérive du contexte : Suivez en continu si les réponses du modèle restent dans les frontières prévues dans le temps, car le comportement du modèle peut évoluer avec de nouveaux schémas d’entrées ou l’évolution des bases de connaissances.
Implémenter des boucles de retour : Prévoyez des mécanismes permettant aux utilisateurs ou aux réviseurs humains de signaler les cas où le modèle a dépassé ses frontières, afin d’affiner les définitions du contexte et d’améliorer les performances futures.
Versionner vos définitions de contexte : Considérez les frontières de contexte comme du code, en maintenant un historique des versions et une documentation des changements, pour permettre un retour arrière si de nouvelles définitions de frontières produisent de moins bons résultats.
Plusieurs plateformes ont intégré la mise entre crochets contextuelle dans leurs offres principales. CustomGPT.ai implémente les frontières contextuelles via sa fonctionnalité « context boundary », qui agit comme une barrière protectrice garantissant que l’IA n’utilise que les données fournies par l’utilisateur, sans jamais accéder à des connaissances générales ou inventer des informations—cette approche a fait ses preuves auprès d’organisations comme le MIT, qui exigent une exactitude absolue dans la restitution des connaissances. Claude d’Anthropic met l’accent sur les principes d’ingénierie contextuelle, fournissant une documentation détaillée sur la structuration des prompts, la gestion de la fenêtre de contexte et la mise en place de garde-fous maintenant les réponses dans des frontières définies. AWS Bedrock Guardrails propose des vérifications automatiques du raisonnement qui confrontent les contenus générés à des règles mathématiques et logiques, avec des scores d’ancrage indiquant si les réponses restent dans le matériel source (des scores supérieurs à 0,85 sont requis pour les applications financières). Shelf.io propose des solutions RAG avec gestion du contexte, permettant aux organisations de mettre en œuvre la génération augmentée par récupération tout en maintenant des frontières strictes sur les informations accessibles et référencées par le modèle. AmICited.com joue un rôle complémentaire en surveillant la façon dont les systèmes d’IA citent et référencent votre marque sur plusieurs plateformes d’IA, vous aidant à comprendre si les modèles d’IA respectent des frontières contextuelles appropriées lorsqu’ils évoquent votre organisation ou s’ils restent fidèles à des informations vérifiées sur votre marque—offrant ainsi une visibilité sur l’efficacité réelle de la mise entre crochets contextuelle sur le terrain.
L’ingénierie de prompt se concentre principalement sur la création d’instructions et d’exemples efficaces, tandis que la mise entre crochets contextuelle est une approche systématique de gestion de tous les éléments de contexte par des délimiteurs et des frontières explicites. La mise entre crochets contextuelle est plus structurée et préventive, agissant au niveau de l’entrée pour empêcher les hallucinations avant qu’elles ne surviennent, alors que l’ingénierie de prompt est plus large et inclut diverses techniques d’optimisation.
La mise entre crochets contextuelle prévient les hallucinations en établissant des limites claires aux informations à l’aide de délimiteurs tels que des balises XML ou des en-têtes markdown. Cela indique au modèle d’IA exactement quelles informations il doit prendre en compte et lesquelles il doit ignorer, l’empêchant ainsi d’inventer des détails ou de faire des suppositions sur des informations non explicites. En limitant l’attention du modèle aux frontières définies, on réduit la probabilité de générer de fausses informations ou des sources inexistantes.
Les délimiteurs courants incluent les balises XML (comme
Les principes de la mise entre crochets contextuelle peuvent être appliqués à la plupart des modèles de langage modernes, bien que l’efficacité varie. Les modèles formés pour mieux suivre les instructions (comme Claude, GPT-4 et Gemini) ont tendance à respecter les frontières de manière plus fiable. La technique fonctionne mieux lorsqu’elle est combinée à des modèles prenant en charge les sorties structurées et ayant été entraînés sur des données diverses et bien formatées.
Commencez par organiser vos prompts systèmes en sections distinctes à l’aide de délimiteurs clairs. Structurez les entrées et sorties avec des schémas JSON ou XML. Utilisez des schémas de délimiteurs cohérents partout. Implémentez des exemples few-shot montrant au modèle exactement comment respecter les frontières. Testez largement pour vous assurer que le modèle respecte les frontières définies et surveillez les performances dans le temps pour détecter les dérives de contexte.
La mise entre crochets contextuelle peut légèrement augmenter l’utilisation des tokens à cause des délimiteurs et des marqueurs structurels supplémentaires, mais ceci est généralement compensé par une meilleure exactitude et des hallucinations réduites. En réalité, la technique améliore l’efficacité en évitant que le modèle gaspille des tokens sur des informations inventées. En production, les gains de précision dépassent largement le faible surcoût en tokens.
La mise entre crochets contextuelle et la RAG sont des techniques complémentaires. La RAG récupère des informations pertinentes depuis des sources externes, tandis que la mise entre crochets contextuelle s’assure que le modèle reste dans les limites de ces informations récupérées. Ensemble, elles créent un système puissant où le modèle peut accéder à des connaissances externes tout en étant limité à ne référencer que des sources vérifiées et récupérées.
Plusieurs plateformes disposent d’un support intégré : CustomGPT.ai propose des fonctionnalités de délimitation du contexte, Claude d’Anthropic fournit une documentation sur l’ingénierie du contexte et le support des sorties structurées, AWS Bedrock Guardrails inclut des vérifications automatiques de raisonnement, et Shelf.io propose une RAG avec gestion du contexte. AmICited.com surveille comment les systèmes d’IA citent votre marque, aidant à vérifier que la mise entre crochets contextuelle fonctionne efficacement.
La mise entre crochets contextuelle garantit que les systèmes d’IA fournissent des informations exactes sur votre marque. Utilisez AmICited pour suivre comment les modèles d’IA citent et référencent votre contenu à travers GPTs, Perplexity et Google AI Overviews.
Découvrez ce qu’est l’ancrage du contenu, comment il prévient les hallucinations de l’IA et pourquoi il est essentiel pour des systèmes d’IA fiables. Découvrez ...

Discussion communautaire sur les fenêtres de contexte de l'IA et leurs implications pour le marketing de contenu. Comprendre comment les limites de contexte aff...
Découvrez ce que sont les fenêtres de contexte dans les modèles de langage IA, leur fonctionnement, leur impact sur les performances des modèles et pourquoi ell...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.