
Couverture d’indexation IA
Découvrez ce qu’est la couverture d’indexation IA et pourquoi elle est essentielle pour la visibilité de votre marque dans ChatGPT, Google AI Overviews et Perpl...
9 min de lecture

La couverture de l’index fait référence au pourcentage et à l’état des pages d’un site web qui ont été découvertes, explorées et incluses dans l’index d’un moteur de recherche. Elle mesure quelles pages sont éligibles à apparaître dans les résultats de recherche et identifie les problèmes techniques empêchant l’indexation.
La couverture de l’index fait référence au pourcentage et à l’état des pages d’un site web qui ont été découvertes, explorées et incluses dans l’index d’un moteur de recherche. Elle mesure quelles pages sont éligibles à apparaître dans les résultats de recherche et identifie les problèmes techniques empêchant l’indexation.
La couverture de l’index est la mesure du nombre de pages de votre site web qui ont été découvertes, explorées et incluses dans l’index d’un moteur de recherche. Elle représente le pourcentage de pages de votre site susceptibles d’apparaître dans les résultats de recherche et identifie les pages rencontrant des problèmes techniques empêchant leur indexation. En somme, la couverture de l’index répond à la question cruciale : « Quelle part de mon site web les moteurs de recherche peuvent-ils réellement trouver et classer ? » Cette métrique est fondamentale pour comprendre la visibilité de votre site dans les moteurs de recherche et se suit à l’aide d’outils comme Google Search Console, qui fournit des rapports détaillés sur les pages indexées, exclues ou en erreur. Sans une bonne couverture de l’index, même le contenu le mieux optimisé reste invisible pour les moteurs de recherche et les utilisateurs à la recherche de vos informations.
La couverture de l’index ne concerne pas uniquement la quantité—il s’agit de s’assurer que les bonnes pages sont indexées. Un site peut comporter des milliers de pages, mais si beaucoup sont des doublons, du contenu pauvre ou bloquées par robots.txt, la couverture de l’index réelle peut être nettement inférieure aux attentes. Cette distinction entre le nombre total de pages et celles réellement indexées est essentielle pour élaborer une stratégie SEO efficace. Les organisations qui surveillent régulièrement la couverture de l’index peuvent identifier et corriger les problèmes techniques avant qu’ils n’affectent le trafic organique, faisant de cette métrique l’une des plus actionnables du SEO technique.
Le concept de couverture de l’index est apparu à mesure que les moteurs de recherche évoluaient, passant de simples robots d’exploration à des systèmes sophistiqués capables de traiter des millions de pages par jour. Aux débuts du SEO, les webmasters disposaient de peu de visibilité sur la façon dont les moteurs de recherche interagissaient avec leurs sites. Google Search Console, initialement lancé sous le nom de Google Webmaster Tools en 2006, a révolutionné cette transparence en offrant un retour direct sur l’état d’exploration et d’indexation. Le rapport Couverture de l’index (anciennement appelé « Indexation des pages ») est devenu l’outil principal pour comprendre quelles pages Google a indexées et pourquoi d’autres sont exclues.
Avec la complexification des sites web (contenu dynamique, paramètres, doublons), les problèmes de couverture de l’index sont devenus courants. Des études indiquent qu’environ 40 à 60 % des sites présentent des problèmes importants de couverture de l’index, avec de nombreuses pages restant non découvertes ou volontairement exclues de l’index. L’essor des sites riches en JavaScript et des applications monopages a encore compliqué l’indexation, les moteurs devant désormais rendre le contenu avant d’en déterminer l’indexabilité. Aujourd’hui, la surveillance de la couverture de l’index est considérée comme essentielle pour toute organisation misant sur le trafic organique, les experts du secteur recommandant des audits mensuels au minimum.
La relation entre la couverture de l’index et le budget d’exploration est devenue capitale à mesure que les sites prennent de l’ampleur. Le budget d’exploration correspond au nombre de pages que Googlebot va parcourir sur votre site dans une période donnée. Les grands sites à l’architecture complexe ou au contenu dupliqué excessif gaspillent leur budget sur des pages à faible valeur, laissant des contenus importants non découverts. Des études montrent que plus de 78 % des grandes entreprises utilisent des outils de suivi de contenu pour contrôler leur visibilité dans les moteurs de recherche et sur les plateformes d’IA, reconnaissant que la couverture de l’index est le socle de toute stratégie de visibilité.
| Concept | Définition | Contrôle principal | Outils utilisés | Impact sur le classement |
|---|---|---|---|---|
| Couverture de l’index | Pourcentage de pages indexées par les moteurs | Balises meta, robots.txt, qualité du contenu | Google Search Console, Bing Webmaster Tools | Direct—seules les pages indexées peuvent être classées |
| Explorabilité | Capacité des robots à accéder et naviguer sur les pages | robots.txt, structure du site, liens internes | Screaming Frog, ZentroAudit, logs serveurs | Indirect—les pages doivent être explorables pour être indexées |
| Indexabilité | Capacité des pages explorées à être ajoutées à l’index | Directives noindex, balises canoniques, contenu | Google Search Console, Outil d’inspection d’URL | Direct—détermine si les pages apparaissent dans les résultats |
| Budget d’exploration | Nombre de pages explorées par Googlebot par période | Autorité du site, qualité des pages, erreurs d’exploration | Google Search Console, logs serveurs | Indirect—influence les pages explorées |
| Contenu dupliqué | Pages multiples avec un contenu identique/similaire | Balises canoniques, redirections 301, noindex | Outils d’audit SEO, révision manuelle | Négatif—dilue le potentiel de classement |
La couverture de l’index fonctionne selon un processus en trois étapes : découverte, exploration, indexation. Lors de la découverte, les moteurs de recherche trouvent des URLs via divers moyens, dont les sitemaps XML, liens internes, backlinks externes et soumissions directes via Google Search Console. Une fois découvertes, les URLs sont mises en file d’attente pour l’exploration : Googlebot demande la page et analyse son contenu. Enfin, lors de l’indexation, Google traite le contenu, évalue sa pertinence et sa qualité, puis décide de l’inclure ou non dans l’index de recherche.
Le rapport Couverture de l’index dans Google Search Console classe les pages selon quatre statuts principaux : Valide (pages indexées), Valide avec des avertissements (indexées mais avec des problèmes), Exclue (non indexée volontairement) et Erreur (pages non indexables). Chaque statut comporte des types d’erreurs spécifiques fournissant des détails sur les raisons d’indexation ou d’exclusion. Par exemple, une page peut être exclue en raison d’une balise meta noindex, d’un blocage par robots.txt, d’un doublon sans balise canonique appropriée, ou d’un code HTTP 4xx ou 5xx.
Comprendre les mécanismes techniques derrière la couverture de l’index nécessite de maîtriser plusieurs éléments clés. Le fichier robots.txt est un fichier texte à la racine de votre site qui indique aux robots les dossiers et fichiers accessibles ou non. Une mauvaise configuration de robots.txt est une cause fréquente de problèmes de couverture de l’index—bloquer par erreur des dossiers importants empêche Google de les découvrir. La balise meta robots, placée dans la partie head du HTML, fournit des instructions de page à l’aide de directives telles que index, noindex, follow et nofollow. La balise canonique (rel=“canonical”) indique aux moteurs de recherche quelle version d’une page est la version principale en cas de doublon, évitant l’explosion de l’index et consolidant les signaux de classement.
Pour les entreprises dépendant du trafic organique, la couverture de l’index influence directement le chiffre d’affaires et la visibilité. Si des pages importantes ne sont pas indexées, elles n’apparaissent pas dans les résultats de recherche—vos clients potentiels ne peuvent donc pas les trouver via Google. Les sites e-commerce souffrant d’une mauvaise couverture de l’index peuvent avoir des fiches produits bloquées au statut « Découverte – actuellement non indexée », entraînant une perte de ventes. Les plateformes de content marketing avec des milliers d’articles ont besoin d’une couverture robuste pour garantir la diffusion de leur contenu. Les entreprises SaaS dépendent d’une documentation et d’articles de blog indexés pour générer des leads organiques.
Les implications pratiques dépassent la recherche traditionnelle. Avec l’essor des plateformes d’IA générative comme ChatGPT, Perplexity et Google AI Overviews, la couverture de l’index devient aussi un enjeu de visibilité IA. Ces systèmes s’appuient souvent sur le contenu web indexé pour l’entraînement et les citations. Si vos pages ne sont pas correctement indexées par Google, elles ont moins de chances d’être intégrées dans les jeux de données d’entraînement de l’IA ou citées dans les réponses générées. Cela crée un effet boule de neige : une mauvaise couverture de l’index nuit à la fois au référencement classique et à la visibilité dans l’IA générative.
Les organisations surveillant activement la couverture de l’index constatent des gains mesurables de trafic organique. Un exemple courant consiste à découvrir que 30 à 40 % des URLs soumises sont exclues à cause de balises noindex, de contenu dupliqué ou d’erreurs d’exploration. Après correction—suppression des balises noindex inutiles, mise en place de la canonisation, correction des erreurs d’exploration—le nombre de pages indexées augmente souvent de 20 à 50 %, ce qui se traduit directement par une meilleure visibilité organique. Le coût de l’inaction est élevé : chaque mois qu’une page reste non indexée représente une perte de trafic et de conversions potentiels.
Google Search Console reste l’outil de référence pour surveiller la couverture de l’index, offrant les données les plus fiables sur les décisions d’indexation de Google. Le rapport Couverture de l’index affiche les pages indexées, celles avec avertissements, les pages exclues et les pages en erreur, avec un détail des types de problèmes. Google propose également l’outil d’inspection d’URL, qui permet de vérifier le statut d’indexation d’une page précise et de demander l’indexation de nouveaux contenus. Cet outil est précieux pour diagnostiquer des cas particuliers et comprendre pourquoi Google n’indexe pas une page.
Bing Webmaster Tools propose des fonctionnalités similaires via son Index Explorer et la soumission d’URL. Même si la part de marché de Bing est moindre, il reste important pour toucher certains utilisateurs. Les données de couverture de l’index de Bing diffèrent parfois de celles de Google, révélant des problèmes propres à l’algorithme de Bing. Les grandes organisations doivent surveiller les deux plateformes pour garantir une couverture complète.
Pour la surveillance IA et la visibilité de la marque, des plateformes comme AmICited suivent la présence de votre marque et de votre domaine sur ChatGPT, Perplexity, Google AI Overviews et Claude. Ces plateformes font le lien entre la couverture de l’index traditionnelle et la visibilité IA, aidant les organisations à comprendre comment leur contenu indexé apparaît dans les réponses générées par l’IA. Cette intégration est aujourd’hui incontournable pour une stratégie SEO moderne, la visibilité sur l’IA influençant de plus en plus la notoriété et le trafic.
Les outils d’audit SEO tiers comme Ahrefs, SEMrush ou Screaming Frog apportent un éclairage complémentaire en explorant votre site de manière indépendante et en comparant leurs résultats à ceux déclarés par Google. Les écarts entre vos propres crawls et la couverture de Google peuvent révéler des problèmes de rendu JavaScript, des soucis serveur ou des limites de budget d’exploration. Ces outils identifient également les pages orphelines (sans liens internes), souvent mal indexées.
Améliorer la couverture de l’index nécessite une approche systématique, à la fois technique et stratégique. Première étape : auditez l’existant via le rapport Couverture de l’index de Google Search Console. Identifiez les principaux problèmes affectant votre site—balises noindex, blocages robots.txt, contenus dupliqués, erreurs d’exploration. Priorisez selon l’impact : les pages devant être indexées mais ne l’étant pas sont prioritaires sur celles exclues à juste titre.
Deuxième étape : corrigez les erreurs robots.txt en examinant le fichier et en vous assurant que vous ne bloquez pas par erreur des dossiers importants. Une erreur classique consiste à bloquer /admin/, /staging/ ou /temp/ (ce qui est normal), mais aussi par inadvertance /blog/, /products/ ou d’autres contenus publics. Utilisez l’outil de test robots.txt de Google pour vérifier que les pages importantes ne sont pas bloquées.
Troisième étape : mettez en place la canonisation pour le contenu dupliqué. Si vous avez plusieurs URLs pour un même contenu (ex : fiches produits accessibles via différents chemins), implémentez des balises canoniques auto-référentes ou des redirections 301 vers l’URL principale. Cela évite la dilution de l’index et consolide les signaux de classement.
Quatrième étape : retirez les balises noindex inutiles des pages à indexer. Auditez votre site à la recherche de directives noindex, notamment sur des environnements de test qui auraient été migrés en production par erreur. Utilisez l’outil d’inspection d’URL pour vérifier que les pages importantes n’ont pas cette directive.
Cinquième étape : soumettez un sitemap XML à Google Search Console contenant uniquement des URLs indexables. Gardez un sitemap propre en excluant les pages en noindex, les redirections ou les erreurs 404. Pour les grands sites, segmentez le sitemap par type de contenu ou section pour une organisation optimale et un suivi d’erreurs plus précis.
Sixième étape : corrigez les erreurs d’exploration telles que liens cassés (404), erreurs serveur (5xx) et chaînes de redirection. Utilisez Google Search Console pour identifier les pages concernées et traitez-les méthodiquement. Pour les erreurs 404 sur des pages importantes, restaurez le contenu ou redirigez en 301 vers une alternative pertinente.
L’avenir de la couverture de l’index évolue avec les mutations technologiques de la recherche et l’essor des systèmes d’IA générative. À mesure que Google renforce ses Core Web Vitals et ses exigences E-E-A-T (Expérience, Expertise, Autorité, Fiabilité), la couverture de l’index dépendra de plus en plus de la qualité du contenu et des signaux d’expérience utilisateur. Les pages aux mauvais indicateurs Core Web Vitals ou au contenu faible risquent d’être exclues même si elles sont techniquement explorables.
L’essor des résultats générés par l’IA et des engines de réponse transforme la notion de couverture de l’index. Le référencement traditionnel dépend de l’indexation des pages, mais l’IA peut citer différemment ou prioriser certaines sources. Les organisations devront surveiller non seulement l’indexation Google, mais aussi leur citation et représentation par les plateformes d’IA. Ce double enjeu de visibilité impose d’élargir la surveillance de la couverture de l’index à des plateformes de monitoring IA captant les mentions de marque sur ChatGPT, Perplexity et autres systèmes génératifs.
Le rendu JavaScript et le contenu dynamique continueront de complexifier la couverture de l’index. Avec l’adoption massive de frameworks JavaScript et d’applications monopages, les moteurs doivent exécuter le JS pour accéder au contenu. Google a amélioré ses capacités de rendu, mais des problèmes subsistent. Les bonnes pratiques à venir mettront l’accent sur le rendering côté serveur ou le rendu dynamique pour garantir la visibilité du contenu sans exécution JS.
L’intégration des données structurées et des schémas deviendra déterminante pour la couverture de l’index. Les moteurs utilisent ces balises pour mieux comprendre le contenu et le contexte, ce qui peut faciliter l’indexation. Les organisations mettant en œuvre un balisage schema exhaustif pour leurs contenus (articles, produits, événements, FAQ) peuvent voir leur couverture de l’index et leur visibilité enrichie.
Enfin, la notion de couverture de l’index va s’étendre des pages aux entités et aux sujets. Il ne s’agira plus seulement de savoir si une page est indexée, mais si votre marque, vos produits et sujets sont bien représentés dans les knowledge graphs des moteurs et dans les jeux de données IA. Cela marque un passage de l’indexation page à page à la visibilité au niveau de l’entité, impliquant de nouveaux outils et stratégies de suivi.
+++
L’explorabilité fait référence à la capacité des robots des moteurs de recherche à accéder et naviguer sur les pages de votre site, contrôlée par des facteurs comme le fichier robots.txt et la structure du site. L’indexabilité détermine si les pages explorées sont réellement ajoutées à l’index du moteur de recherche, contrôlée par les balises meta robots, les balises canoniques et la qualité du contenu. Une page doit être explorable pour être indexable, mais le fait d’être explorable ne garantit pas l’indexation.
Pour la plupart des sites, une vérification mensuelle de la couverture de l’index suffit à détecter les problèmes majeurs. Cependant, si vous effectuez des changements importants dans la structure du site, publiez régulièrement du nouveau contenu ou réalisez des migrations, surveillez le rapport chaque semaine ou toutes les deux semaines. Google envoie des notifications par e-mail en cas de problèmes urgents, mais elles sont souvent retardées, donc une surveillance proactive est essentielle pour maintenir une visibilité optimale.
Ce statut indique que Google a trouvé une URL (généralement via les sitemaps ou des liens internes) mais ne l’a pas encore explorée. Cela peut survenir en raison de limites du budget d’exploration, lorsque Google privilégie d’autres pages de votre site. Si des pages importantes restent longtemps dans ce statut, cela peut signaler un problème de budget d’exploration ou une faible autorité du site à corriger.
Oui, soumettre un sitemap XML à Google Search Console aide les moteurs de recherche à découvrir et à prioriser vos pages pour l’exploration et l’indexation. Un sitemap bien entretenu contenant uniquement des URLs indexables peut significativement améliorer la couverture de l’index en orientant le budget d’exploration de Google vers vos contenus les plus importants et en réduisant le temps de découverte.
Les problèmes courants incluent les pages bloquées par robots.txt, les balises meta noindex sur des pages importantes, le contenu dupliqué sans canonisation appropriée, les erreurs serveur (5xx), les chaînes de redirection et le contenu pauvre. De plus, les erreurs 404, les soft 404 et les pages nécessitant une authentification (erreurs 401/403) apparaissent fréquemment dans les rapports de couverture de l’index et doivent être corrigées pour améliorer la visibilité.
La couverture de l’index influence directement la présence de votre contenu dans les réponses générées par l’IA sur des plateformes comme ChatGPT, Perplexity et Google AI Overviews. Si vos pages ne sont pas correctement indexées par Google, elles ont moins de chances d’être incluses dans les données d’entraînement ou citées par les systèmes d’IA. Surveiller la couverture de l’index assure que le contenu de votre marque soit découvrable et cité aussi bien dans la recherche traditionnelle que sur les plateformes d’IA générative.
Le budget d’exploration est le nombre de pages que Googlebot va explorer sur votre site durant une période donnée. Les sites ayant une efficacité faible du budget d’exploration peuvent avoir de nombreuses pages bloquées au statut « Découverte – actuellement non indexée ». Optimiser le budget d’exploration en corrigeant les erreurs d’exploration, en supprimant les URLs dupliquées et en utilisant robots.txt stratégiquement permet à Google de se concentrer sur l’indexation de vos contenus les plus précieux.
Non, toutes les pages ne doivent pas être indexées. Des pages comme les environnements de test, les variantes de produits en double, les résultats de recherche internes et les archives des politiques de confidentialité sont généralement mieux exclues de l’index à l’aide de balises noindex ou du fichier robots.txt. L’objectif est d’indexer uniquement le contenu unique et à forte valeur ajoutée qui répond à l’intention des utilisateurs et contribue à la performance SEO globale de votre site.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Découvrez ce qu’est la couverture d’indexation IA et pourquoi elle est essentielle pour la visibilité de votre marque dans ChatGPT, Google AI Overviews et Perpl...

L’indexabilité est la capacité pour les moteurs de recherche d’inclure des pages dans leur index. Découvrez comment l’explorabilité, les facteurs techniques et ...
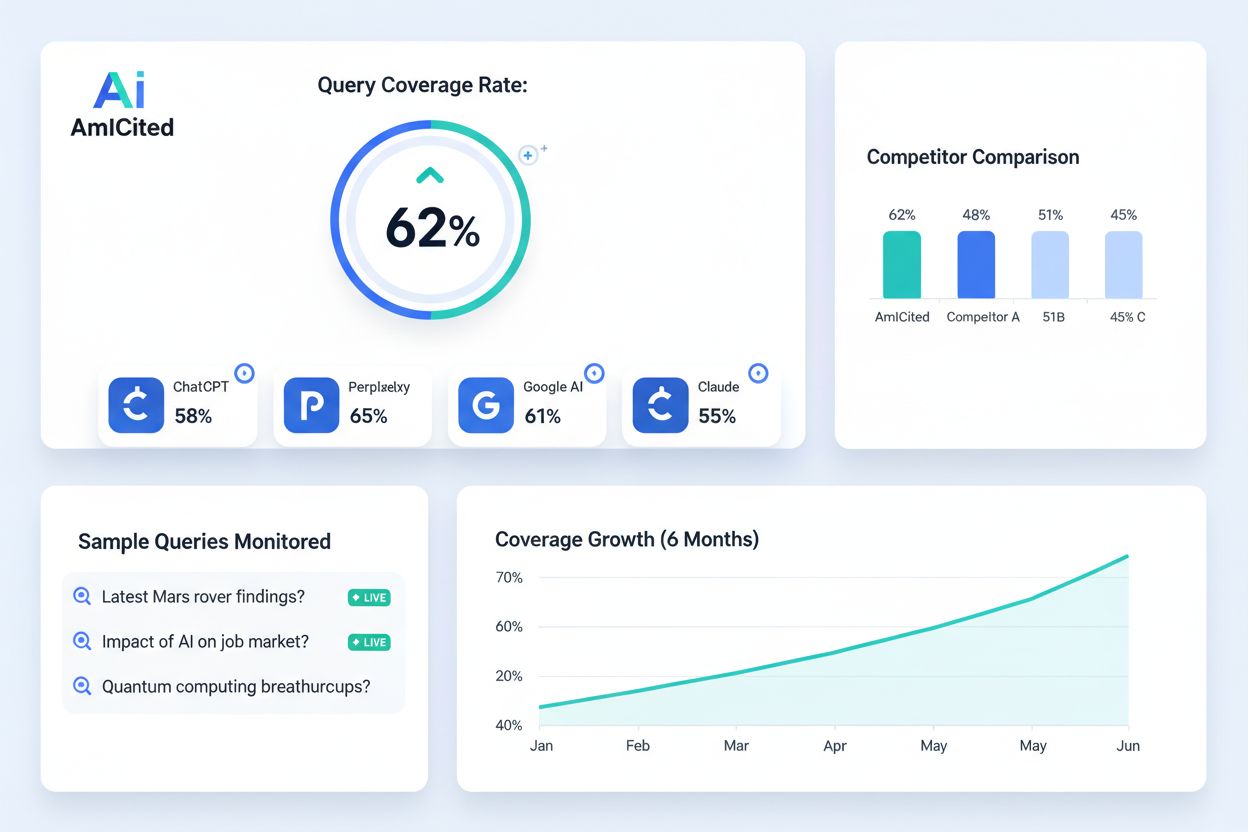
Découvrez ce qu'est le taux de couverture des requêtes, comment le mesurer et pourquoi il est essentiel pour la visibilité de la marque dans la recherche alimen...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.