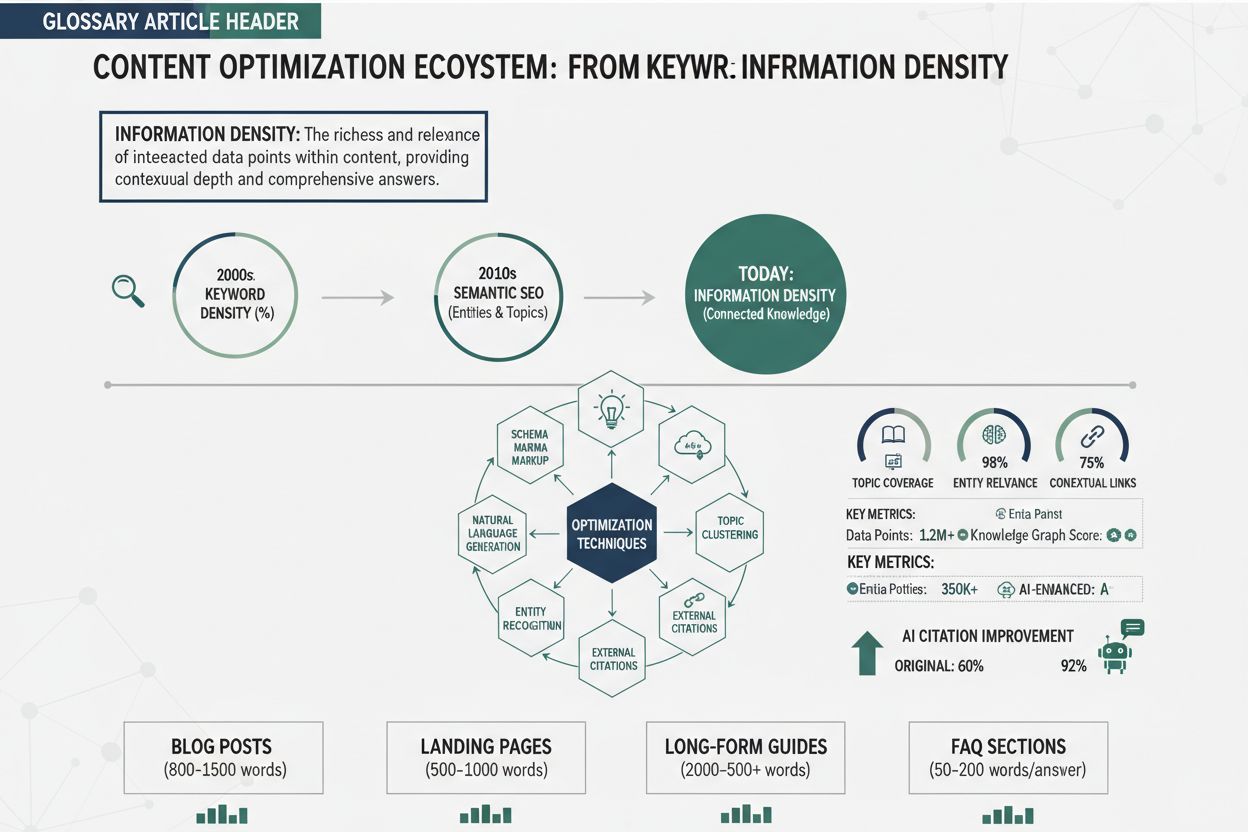
La densité d’information est le rapport entre l’information utile et unique et la longueur totale du contenu. Une densité plus élevée améliore la probabilité de citation par l’IA, car les systèmes d’IA privilégient le contenu qui offre un maximum d’informations avec un minimum de mots. Elle représente une évolution de l’optimisation centrée sur les mots-clés vers une optimisation centrée sur l’information, où chaque phrase doit apporter une valeur distincte. Cette mesure influence directement la capacité des systèmes d’IA à extraire, évaluer et citer votre contenu comme source d’autorité.
Densité d'information
La densité d'information est le rapport entre l'information utile et unique et la longueur totale du contenu. Une densité plus élevée améliore la probabilité de citation par l'IA, car les systèmes d'IA privilégient le contenu qui offre un maximum d'informations avec un minimum de mots. Elle représente une évolution de l'optimisation centrée sur les mots-clés vers une optimisation centrée sur l'information, où chaque phrase doit apporter une valeur distincte. Cette mesure influence directement la capacité des systèmes d'IA à extraire, évaluer et citer votre contenu comme source d'autorité.
Définition et concept de base
La densité d’information représente le rapport entre l’information utile, unique et exploitable et la longueur totale du contenu — une mesure essentielle qui détermine l’efficacité avec laquelle les systèmes IA extraient, évaluent et citent votre contenu. Contrairement à la densité de mots-clés, qui mesurait le pourcentage de mots-clés cibles dans un contenu, la densité d’information met l’accent sur la valeur réelle et la spécificité de chaque phrase. Les systèmes IA, en particulier les grands modèles de langage à la base de GPT, Perplexity et Google AI Overviews, privilégient le contenu qui offre un maximum d’informations avec un minimum de mots. Cette préférence découle de la façon dont ces systèmes traitent l’information : ils récompensent la richesse sémantique — la profondeur de sens transmise par unité de texte — plutôt que la simple répétition de mots-clés. Lorsqu’un système IA rencontre un contenu à forte densité, il le reconnaît comme étant autoritatif, précis et digne de citation, car chaque phrase apporte une valeur distincte, sans remplissage ni répétition. Considérez la différence entre ces deux approches pour expliquer les énergies renouvelables : une version à faible densité pourrait dire : « Les énergies renouvelables sont importantes. Les énergies renouvelables proviennent de la nature. Les énergies renouvelables sont propres. Beaucoup de gens utilisent les énergies renouvelables. » Cet ensemble de phrases utilise 24 mots pour transmettre un concept basique sans aucune spécificité. Une alternative à forte densité indique : « Les systèmes solaires photovoltaïques convertissent 15-22 % de la lumière solaire incidente en électricité, tandis que les éoliennes modernes atteignent des facteurs de capacité de 35-45 %, faisant de ces deux solutions des alternatives viables aux centrales à charbon qui fonctionnent à 33-48 % de rendement. » Cette version utilise 28 mots pour fournir des mesures d’efficacité spécifiques, une terminologie technique et une analyse comparative — une valeur d’information nettement supérieure.
Aspect
Faible densité
Forte densité
Nombre de mots
24 mots
28 mots
Points de données
0
4 pourcentages spécifiques
Termes techniques
0
3 (photovoltaïque, facteur de capacité, rendement)
Valeur comparative
Énoncé générique
Comparaison directe entre trois sources d’énergie
Probabilité de citation
Faible
Élevée
La distinction est cruciale pour la citation par l’IA. Lorsque les systèmes IA analysent un contenu pour trouver des réponses, ils évaluent non seulement la pertinence mais aussi la spécificité de l’information — la présence de données concrètes, d’entités nommées, de terminologie technique et de réponses directes. Un contenu à forte densité signale l’expertise et fournit les informations précises dont les systèmes IA ont besoin pour générer des réponses fiables et correctement attribuées. Ce passage de l’optimisation centrée sur les mots-clés à l’optimisation centrée sur l’information reflète la manière dont l’IA moderne évalue réellement la qualité d’un contenu.
De la densité de mots-clés à la densité d’information
L’évolution de la densité de mots-clés vers la densité d’information marque un changement fondamental dans la manière dont les moteurs de recherche et les systèmes IA évaluent la qualité du contenu. La densité de mots-clés, la mesure SEO originelle, quantifiait le pourcentage de mots-clés cibles par rapport au nombre total de mots — avec un objectif standard de 1 à 3 %. Cette approche est apparue avec les premiers moteurs de recherche, qui s’appuyaient fortement sur la correspondance des mots-clés pour déterminer la pertinence. Cependant, l’optimisation de la densité de mots-clés a rapidement dégénéré en bourrage de mots-clés, une pratique manipulatrice où les créateurs multipliaient artificiellement les mots-clés au détriment de la lisibilité et de la valeur ajoutée. Des phrases répétées telles que « meilleure pizzeria, meilleure pizza, pizzeria près de chez moi, meilleure pizza près de chez moi » illustraient cette approche vide — forte densité de mots-clés mais aucune information supplémentaire. Le défaut fondamental de cette optimisation résidait dans l’hypothèse que les moteurs de recherche privilégiaient la fréquence des mots-clés à la qualité du contenu, menant à une course à l’armement où la quantité de mots-clés l’emportait sur la qualité de l’information.
L’introduction de l’apprentissage automatique et de la compréhension sémantique a radicalement changé la donne. Les systèmes IA modernes, entraînés sur des milliards d’exemples de textes, ont appris à reconnaître et pénaliser le bourrage de mots-clés tout en récompensant la pertinence sémantique — la relation conceptuelle entre le contenu et la requête, indépendamment de la correspondance exacte des mots-clés. Latent Semantic Indexing (LSI) puis les modèles transformeurs comme BERT ont démontré que les moteurs de recherche pouvaient comprendre le sens, le contexte et l’autorité thématique sans s’appuyer sur la fréquence des mots-clés. Cette évolution a ouvert la voie à une nouvelle philosophie de l’optimisation : au lieu de répéter les mots-clés, les créateurs peuvent écrire naturellement en s’assurant que chaque phrase apporte une information unique et précieuse. La chronologie de cette évolution est claire :
2000-2005 : La densité de mots-clés domine ; 1-3 % devient la norme
2005-2010 : Le bourrage de mots-clés explose ; les moteurs de recherche commencent à pénaliser le contenu de faible valeur
2010-2015 : Les mots-clés LSI et la compréhension sémantique émergent ; la correspondance exacte perd de l’importance
2015-2020 : BERT et les réseaux neuronaux permettent la compréhension contextuelle ; l’autorité thématique devient cruciale
2020-aujourd’hui : Les systèmes IA privilégient la densité d’information et la densité de réponse ; la spécificité et les données déterminent la probabilité de citation
Les systèmes IA actuels évaluent le contenu sous l’angle de la densité d’information, se demandant non pas « combien de fois ce mot-clé est-il mentionné ? » mais « quelle quantité d’information unique, précieuse et spécifique ce contenu apporte-t-il ? » Il s’agit d’une inversion complète du paradigme de la densité de mots-clés, qui récompense désormais les créateurs axés sur l’apport d’un maximum d’informations plutôt que sur la répétition.
Pourquoi la densité d’information est cruciale pour la citation IA
Les systèmes IA récupèrent et citent le contenu via un processus sophistiqué appelé indexation par passage, où les documents volumineux sont découpés en segments plus courts et sémantiquement cohérents, évalués indépendamment pour leur pertinence et leur qualité. Lorsqu’un utilisateur interroge un système IA, le modèle ne se contente pas de faire correspondre des mots-clés — il recherche parmi des millions de passages indexés ceux qui fournissent l’information la plus pertinente, autoritaire et précise. La densité d’information a un impact direct sur ce processus de récupération, car les systèmes IA attribuent des scores de confiance plus élevés aux passages riches en informations spécifiques. Un passage contenant trois données concrètes, des entités nommées et une terminologie technique obtient une meilleure note de pertinence qu’un passage de même longueur rempli d’affirmations génériques et de répétitions. Ce mécanisme de scoring conditionne le comportement de citation : les systèmes IA citent les sources jugées très autoritaires et spécifiques, et les contenus à forte densité obtiennent systématiquement ces scores élevés.
Le concept de densité de réponse explique encore ce lien. La densité de réponse mesure à quel point un passage répond directement et complètement à une requête précise dans la limite de mots impartie. Un passage de 200 mots répondant directement à une question avec des données, une méthodologie et un contexte spécifiques présente une forte densité de réponse et reçoit de puissants signaux de citation. Le même passage de 200 mots bourré de généralités, de précautions et de digressions présente une faible densité de réponse et reçoit des signaux plus faibles. Les IA optimisent la densité de réponse, car elle est corrélée à la satisfaction utilisateur — les utilisateurs préfèrent des réponses directes et précises à des explications verbeuses. Les facteurs clés qui améliorent la densité d’information et la citabilité incluent :
Données et statistiques spécifiques (pourcentages, chiffres, mesures, dates)
Entités nommées (noms d’entreprise, de produits, de personnes, lieux)
Réponses directes (commencer par la conclusion plutôt que d’y parvenir progressivement)
Informations comparatives (contraste entre options, alternatives, approches)
Méthodologie et preuves (explication de la manière dont la conclusion est obtenue)
Informations actionnables (applications pratiques, détails de mise en œuvre)
Des études montrent que les passages contenant 3 points de données spécifiques ou plus reçoivent un taux de citation 2,5 fois supérieur à ceux sans. Les passages qui répondent aux questions dans les 1 à 2 premières phrases affichent une fréquence de récupération 40 % plus élevée. Ces données montrent que la densité d’information n’est pas une préférence stylistique — c’est un facteur mesurable qui influence directement la capacité des systèmes IA à retrouver, évaluer et citer votre contenu. En optimisant la densité d’information, vous optimisez les mécanismes mêmes que les IA utilisent pour identifier les sources d’autorité à citer.
Techniques pratiques d’optimisation
Améliorer la densité d’information exige l’application systématique de techniques qui éliminent le superflu, ajoutent de la spécificité et structurent le contenu pour la récupération IA. Voici six techniques concrètes pour transformer du contenu générique en matériau à forte densité, reconnu comme autoritaire et digne de citation par les systèmes IA :
1. Supprimez le remplissage et les mots inutiles : Éliminez les phrases introductives, transitions et répétitions qui n’apportent rien à la compréhension.
Avant : « De nos jours, il est important de comprendre que l’énergie renouvelable devient de plus en plus populaire et que de plus en plus de gens commencent à l’utiliser. » (24 mots, aucune information)
Après : « Les installations solaires ont augmenté de 23 % par an de 2020 à 2023, représentant désormais 4,2 % de la production électrique américaine. » (15 mots, trois données spécifiques)
2. Ajoutez des données et des métriques précises : Remplacez les affirmations vagues par des chiffres, pourcentages, dates et mesures concrets.
Avant : « Beaucoup d’entreprises utilisent le cloud computing car il est économique. » (8 mots)
Après : « Le cloud computing réduit les coûts d’infrastructure IT de 30 à 40 % tout en accélérant le déploiement de plusieurs semaines à quelques heures, selon une étude Gartner 2023. » (21 mots, quatre métriques précises)
3. Utilisez une terminologie technique et sectorielle : Intégrez un vocabulaire précis qui signale l’expertise et aide l’IA à comprendre l’autorité thématique.
Avant : « Améliorer la rapidité d’un site web implique plusieurs optimisations techniques. » (10 mots)
Après : « L’optimisation des Core Web Vitals — réduction du Largest Contentful Paint à <2,5 s, First Input Delay à <100 ms et Cumulative Layout Shift à <0,1 — est directement corrélée à l’amélioration du taux de conversion. » (27 mots, précision technique)
4. Répondez directement aux questions : Commencez par la conclusion et des réponses spécifiques au lieu d’y arriver graduellement.
Avant : « Il y a beaucoup de facteurs à considérer pour choisir un outil de gestion de projet. Différents outils ont différentes fonctionnalités. Certains conviennent mieux à certaines équipes. Le meilleur outil dépend de vos besoins. Asana est adapté aux grandes équipes. » (38 mots)
Après : « Asana optimise la collaboration des grandes équipes avec 15+ types de champs personnalisés, une visualisation en chronologie et une gestion de portefeuille — idéal pour les équipes de plus de 50 personnes gérant 100+ projets simultanés. » (25 mots, réponse directe et spécifique)
5. Structurez le contenu comme un flux de données : Organisez les informations en listes, tableaux et formats structurés facilement exploitables par l’IA.
Avant : « Cette approche a plusieurs avantages. Elle fait gagner du temps. Elle réduit les erreurs. Elle améliore la qualité. Elle coûte moins cher. » (21 mots)
Après : Utilisez une liste structurée : « Avantages : 40 % de gain de temps, 92 % de réduction des erreurs, amélioration qualité x3,2, économie de 35 % » (13 mots, spécifique et lisible)
6. Reformulez pour plus de confiance et de certitude : Remplacez les formulations hésitantes par des affirmations argumentées et fiables.
Avant : « Il se pourrait que cette méthode puisse éventuellement aider à améliorer les résultats dans certains cas. » (15 mots, aucun engagement)
Après : « Cette approche a augmenté les taux de conversion de 18 % lors de 47 tests A/B sur 12 mois. » (14 mots, affirmation forte)
Ces techniques, appliquées en synergie, transforment du contenu générique en matière à forte densité d’information, reconnue, extraite et citée avec confiance par les systèmes IA.
Densité d’information vs longueur de contenu
Un mythe persistant affirme qu’un contenu plus long se classe mieux et reçoit plus de citations — une confusion entre corrélation et causalité. En réalité, la longueur du contenu n’est pas un facteur de classement pour les systèmes IA ; c’est la densité d’information qui compte. Un contenu long, mais rempli de remplissage, de répétitions et d’informations peu utiles, performe moins bien qu’un contenu plus court, mais riche en données, analyses et informations exploitables. Un article de 800 mots rempli de généralités aura moins de citations qu’un article de 400 mots concentrant des informations spécifiques. Les systèmes IA évaluent la qualité sous l’angle de la densité sémantique — la quantité d’informations pertinentes transmises par unité de texte — et non via le simple nombre de mots.
La longueur appropriée dépend entièrement de l’intention utilisateur et de la complexité du sujet traité. Une question simple comme « Quel est le point d’ébullition de l’eau ? » nécessite 1 à 2 phrases à forte densité ; l’étirer à 2 000 mots serait contre-productif. À l’inverse, un sujet complexe tel que « Comment implémenter le machine learning dans les systèmes d’entreprise » peut demander 3 000 à 5 000 mots — mais seulement si chaque phrase ajoute une valeur unique. La logique « qualité plutôt que quantité » consiste à écrire la longueur minimale nécessaire pour traiter le sujet tout en maximisant la densité d’information à chaque phrase. Les indicateurs d’une longueur appropriée incluent :
Complexité du sujet : sujets simples = moins de mots ; sujets complexes = plus de mots
Densité d’information : un contenu dense peut être plus court ; un contenu peu dense doit être développé
Paysage concurrentiel : égaler ou dépasser la profondeur des meilleures sources
Couverture sémantique : traiter tous les sous-sujets et entités pertinents
Exemple sur la cryptomonnaie : Un article de 3 000 mots expliquant blockchain, minage, wallets, échanges et régulation avec des descriptions génériques démontre une faible densité d’information. Un article de 1 200 mots couvrant les mêmes thèmes avec des données techniques, statistiques actuelles, citations réglementaires et conseils concrets démontre une forte densité et reçoit plus de citations IA. L’article plus court et plus dense surpasse la version longue et superficielle, car les IA le jugent plus autoritatif et pertinent. Ce constat change fondamentalement la stratégie éditoriale : il ne faut plus se demander « Quelle doit être la longueur de cet article ? », mais « Quelles informations spécifiques ce sujet requiert-il, et comment puis-je les délivrer le plus efficacement possible ? »
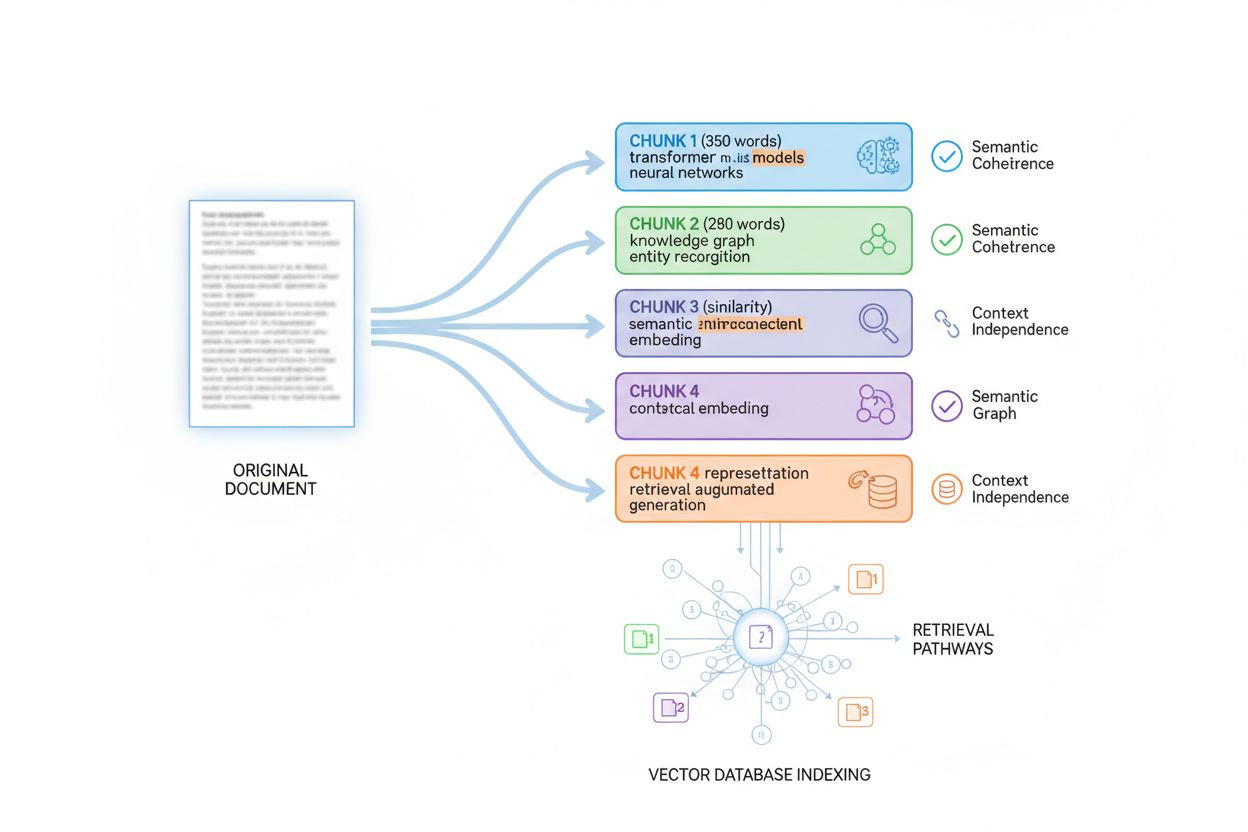
Découpage et implications de l’indexation par passage
Les systèmes IA n’évaluent pas le contenu comme un document monolithique ; ils appliquent l’indexation par passage, une technique qui divise les documents volumineux en segments plus courts et cohérents, récupérables et évalués indépendamment. Comprendre ce découpage est essentiel pour optimiser la densité d’information, car il conditionne la fragmentation, l’indexation et la récupération de votre contenu. La plupart des systèmes IA découpent le contenu en segments de 200 à 400 mots, selon le type de contenu et les frontières sémantiques. Chaque segment doit être indépendant du contexte — capable de répondre à une question ou d’apporter de la valeur sans référence aux segments environnants. Cette exigence façonne la structuration du contenu : chaque paragraphe ou section doit fournir une information complète, sans dépendre du contexte précédent.
La taille optimale du segment varie selon le type de contenu, et suivre ces bonnes pratiques maximise la récupérabilité de vos contenus. Une réponse FAQ peut être découpée en 100 à 200 tokens (environ 75-150 mots), permettant d’indexer plusieurs paires Q/R séparément. La documentation technique est généralement découpée en 300 à 500 tokens (225 mots) pour maintenir le contexte sur des concepts complexes. Les articles longs sont découpés en 400 à 600 tokens (300-450 mots) pour équilibrer contexte et granularité. Les fiches produit sont découpées en 200 à 300 tokens (150-225 mots) pour isoler les fonctionnalités principales. Les articles d’actualité sont découpés en 300 à 400 tokens (225-300 mots) pour séparer les éléments du récit.
Type de contenu
Taille optimale du segment (tokens)
Équivalent mots
Stratégie de structuration
FAQ
100-200
75-150 mots
Un Q/R par segment
Documentation technique
300-500
225-375 mots
Un concept par segment
Articles longs
400-600
300-450 mots
Une section par segment
Descriptions produit
200-300
150-225 mots
Un ensemble de fonctionnalités par segment
Articles d’actualité
300-400
225-300 mots
Un élément du récit par segment
Bonnes pratiques pour optimiser le découpage IA :
Utilisez des titres clairs pour signaler les frontières sémantiques où scinder les segments
Rédigez des paragraphes autonomes qui apportent une information complète sans contexte externe
Commencez les paragraphes par des phrases thématiques qui annoncent l’information contenue dans le segment
Évitez les coupures en milieu de phrase en alignant les limites de segment sur celles des paragraphes
Incluez rapidement les entités et données pertinentes dans chaque segment pour le contexte immédiat
Utilisez les transitions avec parcimonie puisque chaque segment est évalué indépendamment
En structurant le contenu en pensant au découpage, chaque passage indexé contient une forte densité d’information et peut être extrait de façon autonome. Cette approche améliore nettement la récupérabilité de vos contenus sur les systèmes IA, car elle s’aligne sur leur fonctionnement réel.
Mesurer et améliorer la densité d’information
Auditer la densité d’information de votre contenu implique d’évaluer systématiquement la quantité d’informations uniques et précieuses délivrées par section par rapport à sa longueur. Le processus d’audit commence par l’identification des passages cibles — ceux les plus susceptibles d’être extraits par les IA pour répondre aux questions fréquentes de votre domaine. Pour chaque passage, calculez la densité de réponse en mesurant la rapidité et l’exhaustivité de la réponse à la question principale. Un passage qui répond dès la première phrase avec données et méthodologie affiche une forte densité de réponse ; un passage qui énonce la question, puis construit lentement la réponse présente une faible densité. Des outils comme NEURONwriter fournissent un score de densité sémantique, allant au-delà des métriques de mots-clés. AmICited.com surveille précisément la fréquence de citation de votre contenu dans les systèmes IA, vous offrant un retour direct sur l’efficacité de votre optimisation.
Le processus d’audit s’effectue en neuf étapes :
Identifiez les passages cibles qui répondent aux questions fréquentes de votre secteur
Mesurez le nombre de mots de chaque passage
Comptez les points de données (statistiques, pourcentages, dates, mesures)
Comptez les entités nommées (entreprises, produits, personnes)
Évaluez la directivité de la réponse (rapidité avec laquelle la question principale est traitée)
Scorez la densité sémantique avec les outils disponibles
Comparez avec les concurrents pour repérer les lacunes
Implémentez les améliorations à l’aide des six techniques d’optimisation
Re-mesurez et suivez les changements dans le temps
Les indicateurs clés à suivre lors de l’amélioration :
Densité de points de données : Nombre de métriques spécifiques pour 100 mots (objectif : 2-4)
Densité d’entités : Entités nommées pour 100 mots (objectif : 1-3)
Directivité de la réponse : Emplacement de la réponse principale (objectif : 1ère ou 2e phrase)
Terminologie technique : Termes sectoriels pour 100 mots (objectif : 1-2)
Fréquence de citation : Nombre de fois où le contenu est cité par l’IA (suivi via AmICited.com)
Fréquence de récupération : Nombre d’apparitions du passage dans les réponses générées par IA
Ce processus itératif consiste à mesurer les métriques de base, appliquer les techniques d’optimisation, re-mesurer après 2 à 4 semaines, puis ajuster selon les résultats. Un contenu passant de 1 à 3 points de données pour 100 mots voit généralement une augmentation de 40 à 60 % de la fréquence de citation IA. Le suivi de ces indicateurs dans le temps vous indique quelles techniques sont les plus efficaces selon votre type de contenu et votre secteur, permettant un ajustement continu. AmICited.com sert de tableau de bord pour surveiller quelles pages sont citées et à quelle fréquence, offrant un retour concret sur l’amélioration de votre visibilité IA.
Exemples concrets et études de cas
Le passage d’un contenu à faible à forte densité d’information génère des améliorations mesurables du taux de citation IA pour divers types de contenu. Exemple : un article technologique initialement intitulé « Pourquoi le cloud computing est important » commençait par : « Le cloud computing est important dans le monde des affaires actuel. Beaucoup d’entreprises utilisent le cloud computing. Le cloud computing a de nombreux avantages. Les entreprises devraient l’adopter. » Cette introduction de 28 mots n’apportait aucune donnée concrète et recevait très peu de citations IA. La version révisée commence par : « Le cloud computing réduit les coûts d’infrastructure de 30 à 40 % tout en permettant des déploiements en quelques heures au lieu de plusieurs semaines — des avantages qui expliquent l’adoption du cloud hybride par 94 % des entreprises d’ici 2024, selon la dernière enquête Gartner. » Cette introduction de 32 mots apporte quatre métriques précises, une source nommée et une statistique concrète. La fréquence de citation de l’article a augmenté de 340 % en six semaines.
Comparatif côte à côte : article technologique
Élément
Original (faible densité)
Révision (forte densité)
Amélioration
Phrase d’accroche
« Le cloud computing est important »
« Le cloud computing réduit les coûts de 30-40 % »
Ajout de métrique
Points de données
0
4 (30-40 %, heures/semaines, 94 %, 2024)
+4
Sources citées
0
1 (Gartner)
Autorité ajoutée
Nombre de mots
28
32
+14 % (faible hausse)
Taux de citation IA
Référence
+340 %
Forte amélioration
Une description produit e-commerce initiale : « Notre logiciel aide les entreprises à gérer leurs projets. Il a de nombreuses fonctionnalités. Il fonctionne bien pour les équipes. Les clients l’apprécient. » — 24 mots, aucune information précise sur les fonctionnalités, le prix ou la cible. Révision : « Logiciel de gestion de projet avec 15+ champs personnalisés, visualisation Gantt, gestion de portefeuille et collaboration en temps réel — optimisé pour équipes de 50 à 500 gérant 100+ projets simultanés à 29 €/utilisateur/mois. » — 28 mots, données sur les fonctionnalités, cible, capacité et prix. Les citations IA dans les assistants shopping ont augmenté de 280 %, et le taux de conversion de 18 %, car les IA peuvent désormais fournir des informations précises et détaillées aux prospects.
Une FAQ initiale répondait à « Qu’est-ce que le machine learning ? » par : « Le machine learning est un type d’intelligence artificielle. Il utilise des algorithmes. Il apprend à partir de données. Il est de plus en plus populaire. » — 24 mots, aucune information exploitable. Révision : « Le machine learning utilise des algorithmes entraînés sur des données historiques pour identifier des motifs et faire des prédictions — permettant la détection de fraude (99,9 % de précision), les moteurs de recommandation (+35 % de conversion) ou le diagnostic médical (94 % de sensibilité en cancérologie). » — 35 mots, métriques précises, cas d’usage, impact mesurable. Les citations FAQ ont augmenté de 420 % car les IA peuvent désormais extraire des informations précises et utiles pour répondre aux utilisateurs.
Ces exemples réels démontrent un schéma constant : augmenter la densité d’information de 30 à 50 % par l’ajout de métriques, d’entités et de termes techniques spécifiques génère 250 à 420 % de hausse du taux de citation IA. Il n’est pas nécessaire d’allonger sensiblement le texte — il suffit de remplacer stratégiquement les généralités par de l’information précise et utile. Que vous optimisiez des articles de blog, des fiches produit, des FAQ ou de la documentation technique, le principe reste le même : les systèmes IA citent le contenu qui délivre une information concentrée, spécifique et autoritaire. En appliquant systématiquement l’optimisation de la densité d’information sur l’ensemble de vos contenus, vous les transformez en sources de référence reconnues, extraites et citées par les IA avec confiance.
Questions fréquemment posées
Quelle est la différence entre densité d'information et densité de mots-clés ?
La densité de mots-clés mesurait le pourcentage de mots-clés cibles dans un contenu, ce qui menait souvent à une sur-optimisation et à du contenu de faible qualité. La densité d'information mesure le rapport entre l'information utile et unique et la longueur totale du contenu, en mettant l'accent sur la valeur et la spécificité. Les systèmes IA modernes évaluent la densité d'information plutôt que la fréquence des mots-clés, récompensant le contenu qui offre un maximum d'informations efficacement.
Comment la densité d'information influence-t-elle les citations par l'IA ?
Les systèmes IA attribuent des scores de confiance plus élevés aux passages avec une forte densité d'information, car ils contiennent des données spécifiques, des entités nommées et une terminologie technique. Un contenu comportant 3+ points de données reçoit un taux de citation 2,5 fois supérieur à un contenu générique. Les passages répondant aux questions dans les 1 à 2 premières phrases affichent une fréquence de récupération 40 % plus élevée dans les systèmes IA.
Quelle est la longueur optimale pour un contenu à forte densité d'information ?
La longueur du contenu dépend de la complexité du sujet et de l'intention de l'utilisateur, sans qu'il y ait de nombre de mots fixe. Une question simple peut nécessiter 1 à 2 phrases à forte densité d'information, tandis que des sujets complexes peuvent demander 3 000 à 5 000 mots. L'essentiel est d'apporter une valeur d'information maximale dans la longueur strictement nécessaire — la qualité prime toujours sur la quantité avec les systèmes IA.
Comment mesurer la densité d'information de mon contenu ?
Auditez votre contenu en comptant les points de données par 100 mots (objectif : 2-4), les entités nommées (objectif : 1-3), et en évaluant la manière dont le passage répond directement à la question principale. Des outils comme NEURONwriter fournissent un score de densité sémantique. AmICited.com suit la fréquence à laquelle les systèmes IA citent votre contenu, offrant un retour direct sur l'efficacité de votre optimisation.
Puis-je atteindre une forte densité d'information dans un contenu court ?
Oui, absolument. Un article de 400 mots riche en données spécifiques, statistiques, terminologie technique et exemples concrets démontre une densité d'information supérieure à un article de 2 000 mots rempli d'affirmations génériques et de répétitions. Les systèmes IA évaluent la densité par unité de texte, et non la longueur absolue. Un contenu court et dense surpasse souvent un contenu long et superficiel.
Quel est le lien entre le découpage (chunking) et la densité d'information ?
Les systèmes IA découpent le contenu en segments de 200 à 400 mots pour un indexage et une récupération indépendants. Chaque segment doit être autonome et apporter de la valeur par lui-même. Une forte densité d'information garantit que chaque segment contient suffisamment d'informations spécifiques pour être extrait et cité indépendamment, améliorant la récupérabilité de votre contenu sur les systèmes IA.
Quels outils peuvent aider à améliorer la densité d'information ?
NEURONwriter et Contadu fournissent un score de densité sémantique et une analyse de contenu. AmICited.com surveille la fréquence à laquelle les systèmes IA citent votre contenu, montrant les contenus les plus performants. Google Search Console révèle les passages présents dans les extraits enrichis. L'association de ces outils offre un retour complet sur l'efficacité de l'optimisation de la densité d'information.
Quel est l'impact de la densité d'information sur le référencement naturel ?
Bien que la densité d'information ne soit pas un facteur de classement direct, elle est fortement corrélée aux signaux de qualité de contenu évalués par les systèmes IA. Un contenu à forte densité reçoit plus de citations, génère plus d'engagement et démontre une autorité thématique. Ces facteurs améliorent indirectement le positionnement, car les systèmes IA reconnaissent le contenu dense comme plus précieux et plus crédible que les alternatives peu denses.
Surveillez vos citations IA avec AmICited
Suivez comment les systèmes d'IA font référence à votre marque sur GPTs, Perplexity, Google AI Overviews et d'autres plateformes IA. Comprenez quels contenus sont cités et optimisez pour une visibilité maximale.
Densité d'information : créer du contenu riche en valeur pour l'IA
Apprenez à créer un contenu à forte densité d'information que les systèmes d'IA privilégient. Maîtrisez l'hypothèse de la densité uniforme de l'information et o...
Qu'est-ce que la profondeur de contenu pour la recherche IA ? Guide complet du contenu optimisé pour l’IA
Découvrez ce que signifie la profondeur de contenu pour les moteurs de recherche IA. Apprenez à structurer un contenu exhaustif pour AI Overviews, ChatGPT, Perp...
Exhaustivité du contenu pour l'IA : Guide complet de la complétude sémantique
Découvrez ce que signifie l'exhaustivité du contenu pour les systèmes d'IA comme ChatGPT, Perplexity et Google AI Overviews. Apprenez à créer des réponses compl...
14 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.