
Paramètres du modèle
Les paramètres du modèle sont des variables apprenables dans les modèles d’IA qui déterminent le comportement. Comprenez les poids, les biais et comment les par...
14 min de lecture
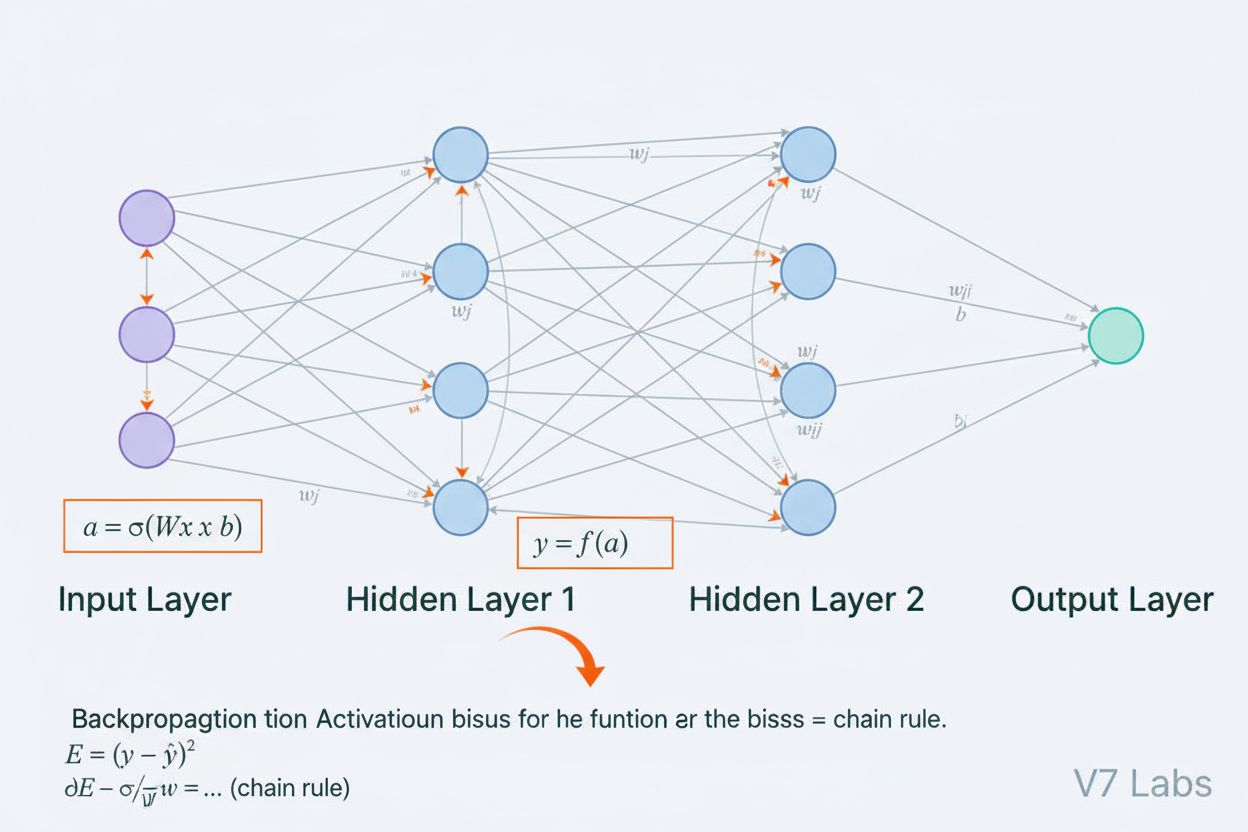
Un réseau de neurones est un système informatique inspiré des réseaux neuronaux biologiques, composé de neurones artificiels interconnectés organisés en couches, capables d’apprendre des motifs à partir de données grâce à un processus appelé rétropropagation. Ces systèmes constituent la base de l’intelligence artificielle moderne et de l’apprentissage profond, alimentant des applications allant du traitement du langage naturel à la vision par ordinateur.
Un réseau de neurones est un système informatique inspiré des réseaux neuronaux biologiques, composé de neurones artificiels interconnectés organisés en couches, capables d'apprendre des motifs à partir de données grâce à un processus appelé rétropropagation. Ces systèmes constituent la base de l'intelligence artificielle moderne et de l'apprentissage profond, alimentant des applications allant du traitement du langage naturel à la vision par ordinateur.
Un réseau de neurones est un système informatique fondamentalement inspiré par la structure et le fonctionnement des réseaux neuronaux biologiques présents dans le cerveau des animaux. Il se compose de neurones artificiels interconnectés organisés en couches—généralement une couche d’entrée, une ou plusieurs couches cachées et une couche de sortie—qui travaillent ensemble pour traiter des données, reconnaître des motifs et effectuer des prédictions. Chaque neurone reçoit des entrées, applique des transformations mathématiques à l’aide de poids et de biais, puis transmet le résultat à une fonction d’activation pour produire une sortie. La caractéristique déterminante des réseaux de neurones est leur capacité à apprendre à partir de données grâce à un processus itératif appelé rétropropagation, où le réseau ajuste ses paramètres internes afin de minimiser les erreurs de prédiction. Cette capacité d’apprentissage, combinée à leur aptitude à modéliser des relations complexes et non linéaires, fait des réseaux de neurones la technologie fondatrice de l’intelligence artificielle moderne, des grands modèles de langage aux applications de vision par ordinateur.
Le concept de réseaux de neurones artificiels est issu des premières tentatives de modéliser mathématiquement la façon dont les neurones biologiques communiquent et traitent l’information. En 1943, Warren McCulloch et Walter Pitts ont proposé le premier modèle mathématique d’un neurone, démontrant que des unités computationnelles simples pouvaient effectuer des opérations logiques. Cette base théorique a été suivie par l’introduction du perceptron par Frank Rosenblatt en 1958, un algorithme conçu pour la reconnaissance de motifs qui est devenu l’ancêtre historique des architectures de réseaux de neurones sophistiquées d’aujourd’hui. Le perceptron était essentiellement un modèle linéaire avec une sortie contrainte, capable d’apprendre des frontières de décision simples. Cependant, le domaine a connu un recul important dans les années 1970 lorsque les chercheurs ont découvert que les perceptrons à une seule couche ne pouvaient pas résoudre des problèmes non linéaires comme la fonction XOR, menant à ce qui fut appelé “l’hiver de l’IA”. La percée est survenue dans les années 1980 avec la redécouverte et l’amélioration de la rétropropagation, un algorithme permettant d’entraîner des réseaux multicouches. Cette renaissance a été considérablement accélérée dans les années 2010 avec l’arrivée de jeux de données massifs, de GPU puissants et de techniques d’entraînement perfectionnées, menant à la révolution du deep learning qui a transformé l’intelligence artificielle.
L’architecture d’un réseau de neurones comprend plusieurs composants essentiels fonctionnant de concert. La couche d’entrée reçoit les caractéristiques brutes des données provenant de sources externes, chaque neurone de cette couche correspondant à une caractéristique. Les couches cachées effectuent le travail computationnel principal, transformant les entrées en représentations de plus en plus abstraites via des combinaisons pondérées et des fonctions d’activation non linéaires. Le nombre et la taille des couches cachées déterminent la capacité du réseau à apprendre des motifs complexes—des réseaux plus profonds peuvent capturer des relations plus sophistiquées mais nécessitent plus de données et de ressources de calcul. La couche de sortie produit les prédictions finales, avec une structure dépendant de la tâche : un seul neurone pour la régression, plusieurs neurones pour la classification multiclasses, ou des architectures spécialisées pour d’autres applications. Chaque connexion entre neurones porte un poids qui détermine la force d’influence, tandis que chaque neurone possède un biais qui décale son seuil d’activation. Ces poids et biais sont les paramètres apprenables ajustés par le réseau au cours de l’entraînement. La fonction d’activation appliquée à chaque neurone introduit une non-linéarité cruciale, permettant au réseau d’apprendre des frontières de décision et des motifs complexes qu’un modèle linéaire ne saurait capturer.
Les réseaux de neurones apprennent au travers d’un processus itératif en deux phases. Lors de la propagation avant, les données d’entrée traversent le réseau de la couche d’entrée à la couche de sortie. À chaque neurone, la somme pondérée des entrées plus le biais est calculée (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), puis transmise à une fonction d’activation pour produire la sortie du neurone. Ce processus se répète à travers chaque couche cachée jusqu’à la couche de sortie, qui délivre la prédiction du réseau. Le réseau calcule ensuite l’erreur entre sa prédiction et la véritable étiquette à l’aide d’une fonction de perte, qui quantifie l’écart entre la prédiction et la bonne réponse. Lors de la rétropropagation, cette erreur est propagée en arrière à travers le réseau grâce à la règle de chaîne du calcul différentiel. À chaque neurone, l’algorithme calcule le gradient de la perte par rapport à chaque poids et biais, déterminant la contribution de chaque paramètre à l’erreur globale. Ces gradients guident les mises à jour des paramètres : les poids et biais sont ajustés dans la direction opposée au gradient, à une vitesse contrôlée par un taux d’apprentissage. Ce processus se répète de nombreuses fois sur l’ensemble d’apprentissage, réduisant progressivement la perte et améliorant les prédictions du réseau. La combinaison de propagation avant, calcul de la perte, rétropropagation et mise à jour des paramètres constitue le cycle complet d’entraînement qui permet aux réseaux de neurones d’apprendre à partir des données.
| Type d’architecture | Cas d’usage principal | Caractéristique clé | Forces | Limites |
|---|---|---|---|---|
| Réseaux feedforward | Classification, régression sur données structurées | L’information circule dans une seule direction | Simple, apprentissage rapide, interprétable | Gère mal les données séquentielles ou spatiales |
| Réseaux de neurones convolutifs (CNN) | Reconnaissance d’images, vision par ordinateur | Les couches de convolution détectent des caractéristiques spatiales | Excellents pour capturer des motifs locaux, efficaces en paramètres | Nécessitent de grands jeux d’images annotés |
| Réseaux de neurones récurrents (RNN) | Données séquentielles, séries temporelles, NLP | L’état caché conserve la mémoire entre les étapes temporelles | Peuvent traiter des séquences de longueur variable | Souffrent du problème des gradients qui disparaissent/explosent |
| Long Short-Term Memory (LSTM) | Dépendances à long terme dans les séquences | Cellules de mémoire avec portes d’entrée/oubli/sortie | Gèrent efficacement les dépendances à long terme | Plus complexes, apprentissage plus lent que les RNN |
| Réseaux transformeurs | Traitement du langage naturel, grands modèles de langage | Mécanisme d’attention multi-tête, traitement parallèle | Hautement parallélisables, capturent les dépendances à longue portée | Nécessitent d’énormes ressources de calcul |
| Réseaux antagonistes génératifs (GANs) | Génération d’images, création de données synthétiques | Réseaux générateur et discriminateur en compétition | Peuvent générer des données synthétiques réalistes | Difficiles à entraîner, problèmes de collapse de mode |
L’introduction des fonctions d’activation représente l’une des innovations les plus cruciales dans la conception des réseaux de neurones. Sans fonctions d’activation, un réseau de neurones serait mathématiquement équivalent à une seule transformation linéaire, quel que soit le nombre de couches. En effet, la composition de fonctions linéaires reste linéaire, limitant fortement l’aptitude du réseau à apprendre des motifs complexes. Les fonctions d’activation résolvent ce problème en introduisant de la non-linéarité à chaque neurone. La fonction ReLU (Rectified Linear Unit), définie par f(x) = max(0, x), est devenue le choix le plus populaire dans le deep learning moderne grâce à son efficacité computationnelle et sa capacité à permettre l’apprentissage de réseaux profonds. La fonction sigmoïde, f(x) = 1/(1 + e^(-x)), comprime les sorties entre 0 et 1, ce qui la rend utile pour les tâches de classification binaire. La fonction tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), produit des sorties entre -1 et 1 et fonctionne souvent mieux que la sigmoïde dans les couches cachées. Le choix de la fonction d’activation a un impact significatif sur la dynamique d’apprentissage, la vitesse de convergence et la performance finale du réseau. Les architectures modernes utilisent souvent ReLU dans les couches cachées pour son efficacité, et la sigmoïde ou softmax dans les couches de sortie pour l’estimation de probabilités. La non-linéarité introduite par les fonctions d’activation permet aux réseaux de neurones d’approximer toute fonction continue, une propriété appelée théorème d’approximation universelle, qui explique leur remarquable polyvalence dans des applications très variées.
Le marché des réseaux de neurones a connu une croissance explosive, reflétant le rôle central de cette technologie dans l’intelligence artificielle moderne. Selon des études récentes, le marché mondial des logiciels de réseaux de neurones était estimé à environ 34,76 milliards de dollars en 2025 et devrait atteindre 139,86 milliards de dollars d’ici 2030, soit un taux de croissance annuel composé (CAGR) de 32,10 %. Le marché global des réseaux de neurones montre une expansion encore plus spectaculaire, avec des estimations prévoyant une croissance de 34,05 milliards de dollars en 2024 à 385,29 milliards de dollars d’ici 2033, à un CAGR de 31,4 %. Cette croissance fulgurante est alimentée par plusieurs facteurs : la disponibilité croissante de grands ensembles de données, le développement d’algorithmes d’entraînement plus efficaces, la prolifération des GPU et du matériel spécialisé IA, et l’adoption généralisée des réseaux de neurones dans les industries. Selon le rapport AI Index de Stanford 2025, 78 % des organisations déclaraient utiliser l’IA en 2024, contre 55 % l’année précédente, les réseaux de neurones constituant l’épine dorsale de la plupart des systèmes d’IA en entreprise. L’adoption concerne la santé, la finance, l’industrie, le commerce de détail et pratiquement tous les autres secteurs, les organisations reconnaissant l’avantage concurrentiel apporté par les systèmes basés sur les réseaux de neurones pour la reconnaissance de motifs, la prédiction et la prise de décision.
Les réseaux de neurones alimentent les systèmes d’IA les plus avancés actuellement déployés, notamment ChatGPT, Perplexity, Google AI Overviews et Claude. Ces grands modèles de langage sont construits sur des architectures de réseaux de neurones de type transformeur qui utilisent des mécanismes d’attention pour traiter et générer le langage humain avec une sophistication remarquable. L’architecture transformeur, introduite en 2017, a révolutionné le traitement du langage naturel en permettant le traitement parallèle de séquences entières plutôt qu’un traitement séquentiel, améliorant considérablement l’efficacité d’entraînement et la performance des modèles. Dans le contexte de la surveillance de marque et du suivi des citations par l’IA, comprendre les réseaux de neurones est crucial car ces systèmes les utilisent pour comprendre le contexte, retrouver l’information pertinente et générer des réponses qui peuvent référencer ou citer votre marque, domaine ou contenu. AmICited exploite la connaissance du fonctionnement des réseaux de neurones pour surveiller où votre marque apparaît dans les réponses générées par l’IA sur de multiples plateformes. À mesure que les réseaux de neurones progressent dans leur capacité à comprendre le sens sémantique et à retrouver l’information pertinente, l’importance de surveiller la présence de votre marque dans les réponses de l’IA devient de plus en plus critique pour préserver la visibilité de la marque et gérer votre réputation en ligne à l’ère de la recherche et du contenu pilotés par l’IA.
L’entraînement efficace des réseaux de neurones présente plusieurs défis majeurs que chercheurs et praticiens doivent relever. Le surapprentissage survient lorsqu’un réseau apprend trop bien les données d’entraînement, y compris leur bruit et leurs particularités, ce qui conduit à de mauvaises performances sur de nouvelles données. Ce problème est particulièrement marqué avec les réseaux profonds dotés de nombreux paramètres par rapport à la taille de l’ensemble d’entraînement. Le sous-apprentissage est le problème inverse, lorsque le réseau n’a pas assez de capacité ou d’entraînement pour saisir les motifs sous-jacents des données. Le problème du gradient qui disparaît survient dans les réseaux très profonds où les gradients deviennent exponentiellement petits lors de la rétropropagation, ce qui fait que les poids des premières couches évoluent très lentement voire pas du tout. Le problème du gradient qui explose est l’opposé, où les gradients deviennent exponentiellement grands, entraînant un apprentissage instable. Les solutions modernes incluent la normalisation par lot (batch normalization), qui normalise les entrées des couches pour maintenir un flux de gradient stable ; les connexions résiduelles (skip connections), qui permettent aux gradients de circuler directement à travers les couches ; et la clipping des gradients, qui limite leur amplitude. Les techniques de régularisation comme la régularisation L1 et L2 pénalisent les poids élevés, favorisant des modèles plus simples qui généralisent mieux. Le dropout désactive aléatoirement des neurones pendant l’entraînement, empêchant la co-adaptation et améliorant la généralisation. Le choix de l’optimiseur (tel que Adam, SGD ou RMSprop) et du taux d’apprentissage a un impact majeur sur l’efficacité de l’entraînement et les performances finales du modèle. Le praticien doit soigneusement équilibrer complexité du modèle, taille des données, force de régularisation et paramètres d’optimisation pour obtenir des réseaux qui apprennent efficacement sans surapprentissage.
L’évolution des architectures de réseaux de neurones suit une trajectoire claire vers des mécanismes de traitement de l’information de plus en plus sophistiqués. Les réseaux feedforward initiaux étaient limités à des entrées de taille fixe et ne pouvaient pas capturer les dépendances temporelles ou séquentielles. Les réseaux de neurones récurrents (RNN) ont introduit des boucles de rétroaction permettant à l’information de persister entre les étapes temporelles, rendant possible le traitement de séquences de longueur variable. Cependant, les RNN souffraient de problèmes de flux de gradient et étaient intrinsèquement séquentiels, empêchant la parallélisation sur le matériel moderne. Les réseaux Long Short-Term Memory (LSTM) ont résolu certains de ces problèmes grâce à des cellules mémoire et des mécanismes de portes, mais restaient fondamentalement séquentiels. La percée est venue avec les réseaux transformeurs, qui ont entièrement remplacé la récurrence par des mécanismes d’attention. Le mécanisme d’attention permet au réseau de se concentrer dynamiquement sur différentes parties de l’entrée, calculant des combinaisons pondérées de tous les éléments en parallèle. Cela permet aux transformeurs de capturer efficacement les dépendances à longue portée tout en restant entièrement parallélisables sur des grappes de GPU. L’architecture transformeur, combinée à une échelle massive (les grands modèles de langage modernes comptent des milliards à des milliers de milliards de paramètres), s’est révélée extrêmement efficace pour le traitement du langage, la vision par ordinateur et les tâches multimodales. Le succès des transformeurs a conduit à leur adoption comme architecture standard pour les systèmes d’IA de pointe, incluant tous les principaux grands modèles de langage. Cette évolution illustre comment les innovations architecturales, alliées à l’augmentation des ressources de calcul et à des jeux de données toujours plus volumineux, continuent de repousser les limites de ce que les réseaux de neurones peuvent accomplir.
Le domaine des réseaux de neurones continue d’évoluer rapidement, avec plusieurs axes prometteurs. Le calcul neuromorphique vise à créer un matériel imitant de plus près les réseaux neuronaux biologiques, permettant potentiellement une efficacité énergétique et une puissance de calcul accrues. Les recherches sur l’apprentissage few-shot et zero-shot cherchent à permettre aux réseaux de neurones d’apprendre à partir de très peu d’exemples, se rapprochant ainsi des capacités d’apprentissage humain. L’explicabilité et l’interprétabilité deviennent de plus en plus importantes, les chercheurs développant des techniques pour comprendre et visualiser ce qu’apprennent les réseaux de neurones, crucial pour les applications à enjeux élevés comme la santé, la finance ou la justice. L’apprentissage fédéré permet d’entraîner des réseaux de neurones sur des données distribuées sans centraliser les informations sensibles, répondant ainsi aux enjeux de confidentialité. Les réseaux de neurones quantiques constituent un nouveau front combinant les principes de l’informatique quantique aux architectures de réseaux de neurones, avec à la clé des accélérations exponentielles potentielles pour certains problèmes. Les réseaux de neurones multimodaux qui intègrent de façon transparente texte, images, audio et vidéo deviennent de plus en plus sophistiqués, permettant des systèmes d’IA plus complets. Les réseaux de neurones économes en énergie sont développés pour réduire les coûts computationnels et environnementaux de l’entraînement et du déploiement de grands modèles. À mesure que les réseaux de neurones progressent, leur intégration dans des systèmes de monitoring IA comme AmICited devient stratégique pour les organisations cherchant à comprendre et gérer leur présence de marque dans les contenus et réponses générés par l’IA sur des plateformes telles que ChatGPT, Perplexity, Google AI Overviews et Claude.
Les réseaux de neurones sont inspirés par la structure et la fonction des neurones biologiques dans le cerveau humain. Dans le cerveau, les neurones communiquent par des signaux électriques via des synapses, qui peuvent être renforcées ou affaiblies selon l'expérience. Les réseaux de neurones artificiels imitent ce comportement en utilisant des modèles mathématiques de neurones connectés par des liens pondérés, permettant au système d'apprendre et de s'adapter à partir de données d'une manière analogue à la façon dont les cerveaux biologiques traitent l'information et forment des souvenirs.
La rétropropagation est l'algorithme principal qui permet aux réseaux de neurones d'apprendre. Lors de la propagation avant, les données traversent les couches du réseau pour produire des prédictions. Le réseau calcule ensuite l'erreur entre les sorties prévues et réelles à l'aide d'une fonction de perte. Lors du passage arrière, cette erreur est propagée en arrière à travers le réseau en utilisant la règle de chaîne du calcul différentiel, calculant dans quelle mesure chaque poids et biais a contribué à l'erreur. Les poids sont alors ajustés dans la direction qui minimise l'erreur, généralement en utilisant l'optimisation par descente de gradient.
Les principales architectures de réseaux de neurones incluent les réseaux feedforward (les données circulent dans une seule direction), les réseaux de neurones convolutifs ou CNN (optimisés pour le traitement d'images), les réseaux de neurones récurrents ou RNN (conçus pour les données séquentielles), les réseaux à mémoire à long terme ou LSTM (RNN améliorés avec cellules de mémoire), et les réseaux transformeurs (utilisant des mécanismes d'attention pour le traitement parallèle). Chaque architecture est spécialisée pour différents types de données et de tâches, de la reconnaissance d'images au traitement du langage naturel.
Les systèmes d'IA modernes comme ChatGPT, Perplexity et Claude sont construits sur des réseaux de neurones de type transformeur, qui utilisent des mécanismes d'attention pour traiter efficacement le langage. Ces réseaux de neurones permettent à ces systèmes de comprendre le contexte, de générer un texte cohérent et d'effectuer des tâches de raisonnement complexes. La capacité des réseaux de neurones à apprendre à partir d'ensembles de données massifs et à capturer des motifs complexes dans le langage les rend essentiels pour construire des IA conversationnelles capables de comprendre et de répondre aux requêtes humaines avec une grande précision.
Les poids dans les réseaux de neurones contrôlent la force des connexions entre les neurones, déterminant l'influence de chaque entrée sur la sortie. Les biais sont des paramètres supplémentaires qui décalent le seuil d'activation des neurones, leur permettant de s'activer même lorsque les entrées sont faibles. Ensemble, les poids et les biais constituent les paramètres apprenables du réseau qui sont ajustés pendant l'entraînement pour minimiser les erreurs de prédiction et permettre au réseau d'apprendre des motifs complexes à partir des données.
Les fonctions d'activation introduisent de la non-linéarité dans les réseaux de neurones, leur permettant d'apprendre des relations complexes et non linéaires dans les données. Sans fonctions d'activation, empiler plusieurs couches aboutirait toujours à des transformations linéaires, limitant fortement la capacité d'apprentissage du réseau. Les fonctions d'activation courantes incluent ReLU (Rectified Linear Unit), sigmoïde et tanh, chacune introduisant différents types de non-linéarité qui aident le réseau à capturer des motifs complexes et à faire des prédictions plus sophistiquées.
Les couches cachées sont des couches intermédiaires entre les couches d'entrée et de sortie où le réseau effectue la majeure partie de son travail computationnel. Ces couches extraient et transforment les caractéristiques des données brutes en représentations de plus en plus abstraites. La profondeur et la largeur des couches cachées déterminent la capacité du réseau à apprendre des motifs complexes. Les réseaux plus profonds avec davantage de couches cachées peuvent capturer des relations plus sophistiquées dans les données, mais nécessitent plus de ressources de calcul et un entraînement soigné pour éviter le surapprentissage.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Les paramètres du modèle sont des variables apprenables dans les modèles d’IA qui déterminent le comportement. Comprenez les poids, les biais et comment les par...

L’architecture Transformer est une conception de réseau de neurones utilisant des mécanismes d’auto-attention pour traiter les données séquentielles en parallèl...

Les données d'entraînement sont l'ensemble de données utilisé pour enseigner aux modèles ML les motifs et les relations. Découvrez comment la qualité des donnée...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.