
Recherche vectorielle
La recherche vectorielle utilise des représentations vectorielles mathématiques pour trouver des données similaires en mesurant les relations sémantiques. Décou...
12 min de lecture

La recherche secondaire est l’analyse et l’interprétation de données existantes précédemment collectées par d’autres chercheurs ou organisations à des fins différentes. Elle consiste à synthétiser des ensembles de données publiés, des rapports, des revues académiques et d’autres sources pour répondre à de nouvelles questions de recherche ou valider des hypothèses sans effectuer de collecte de données originale.
La recherche secondaire est l'analyse et l'interprétation de données existantes précédemment collectées par d'autres chercheurs ou organisations à des fins différentes. Elle consiste à synthétiser des ensembles de données publiés, des rapports, des revues académiques et d'autres sources pour répondre à de nouvelles questions de recherche ou valider des hypothèses sans effectuer de collecte de données originale.
La recherche secondaire, également appelée recherche documentaire, est une méthodologie de recherche systématique qui consiste à analyser, synthétiser et interpréter des données existantes précédemment collectées par d’autres chercheurs, organisations ou institutions à des fins différentes. Plutôt que de recueillir des données originales par le biais d’enquêtes, d’entretiens ou d’expériences, la recherche secondaire exploite des ensembles de données publiés, des rapports, des revues académiques, des statistiques gouvernementales et d’autres sources d’informations compilées pour répondre à de nouvelles questions de recherche ou valider des hypothèses. Cette approche représente un changement fondamental, passant de la collecte de données à l’analyse et à l’interprétation des données, permettant aux organisations d’extraire des informations exploitables à partir de données déjà disponibles dans le domaine public ou dans les archives organisationnelles. Le terme « secondaire » fait référence au fait que les chercheurs travaillent avec des données secondaires par rapport à leur objectif de collecte initial—des données recueillies à l’origine pour un objectif sont réanalysées pour répondre à d’autres questions de recherche ou défis commerciaux.
La pratique de la recherche secondaire a considérablement évolué au cours du siècle dernier, passant des revues littéraires en bibliothèque à des analyses sophistiquées de données numériques. Historiquement, les chercheurs s’appuyaient sur des bibliothèques physiques, des archives et des documents publiés pour mener une analyse secondaire, un processus long qui limitait la portée et l’accessibilité de la recherche. La révolution numérique a fondamentalement transformé la recherche secondaire en rendant d’immenses ensembles de données instantanément accessibles via des bases de données en ligne, des portails gouvernementaux et des dépôts académiques. Aujourd’hui, l’industrie mondiale des études de marché génère 140 milliards de dollars de chiffre d’affaires annuel en 2024, la recherche secondaire représentant une part importante de ce marché. La trajectoire de croissance est remarquable—le secteur est passé de 102 milliards de dollars en 2021 à 140 milliards en 2024, soit une hausse de 37,25 % en seulement trois ans. Cette expansion reflète la dépendance croissante des organisations à la prise de décision basée sur les données et la reconnaissance que la recherche secondaire offre des voies économiques vers des informations de marché. L’émergence d’outils d’analyse de données propulsés par l’IA a encore révolutionné la recherche secondaire, permettant aux chercheurs de traiter de vastes ensembles de données, d’identifier des schémas et d’extraire des informations à une vitesse inégalée. Selon des recherches récentes, 69 % des professionnels des études de marché ont intégré des données synthétiques et l’analyse par IA dans leurs efforts de recherche secondaire, illustrant l’évolution technologique rapide du domaine.
Les données de recherche secondaire proviennent de deux grandes catégories : les sources internes et les sources externes. Les données secondaires internes incluent les informations déjà collectées et stockées au sein d’une organisation, telles que les bases de données de ventes, les historiques de transactions clients, les projets de recherche antérieurs, les indicateurs de performance des campagnes et les analyses de sites web. Ces données internes offrent des avantages concurrentiels car elles restent exclusives à l’organisation et reflètent la performance réelle de l’entreprise. Les données secondaires externes englobent les informations publiques ou achetées auprès d’agences gouvernementales, d’institutions académiques, de sociétés d’études de marché, d’associations sectorielles et de médias. Les sources gouvernementales fournissent des données de recensement, des statistiques économiques et des informations réglementaires ; les sources académiques offrent des recherches évaluées par des pairs et des études longitudinales ; les agences d’études de marché publient des rapports sectoriels et des analyses concurrentielles ; et les associations professionnelles compilent des données et tendances spécifiques à leur secteur. La diversité des sources secondaires permet aux chercheurs de trianguler les résultats selon plusieurs perspectives et de valider les conclusions par vérification croisée des sources.
| Aspect | Recherche secondaire | Recherche primaire |
|---|---|---|
| Collecte des données | Analyse des données existantes collectées par d’autres | Collecte des données originales directement auprès de sources |
| Délai | Jours à semaines | Semaines à mois |
| Coût | Faible à minime (souvent gratuit) | Élevé (recrutement de participants, administration) |
| Contrôle des données | Aucun contrôle sur la méthodologie ou la qualité | Contrôle total sur la conception et l’exécution de la recherche |
| Spécificité | Peut ne pas répondre aux questions de recherche spécifiques | Adaptée précisément aux objectifs de recherche |
| Biais du chercheur | Biais inconnu des collecteurs initiaux | Biais potentiel des chercheurs actuels |
| Exclusivité des données | Non exclusive (les concurrents accèdent aux mêmes données) | Propriété exclusive des résultats |
| Taille de l’échantillon | Jeux de données souvent à grande échelle | Variable selon le budget et la portée |
| Pertinence | Peut nécessiter une adaptation aux besoins actuels | Directement pertinent pour les objectifs de recherche actuels |
| Rapidité d’obtention des insights | Accès immédiat à l’information compilée | Nécessite du temps pour la collecte et l’analyse des données |
La méthodologie de la recherche secondaire suit un processus structuré en cinq étapes garantissant une analyse rigoureuse et des conclusions valides. La première étape consiste à définir clairement le sujet de recherche et à identifier les questions spécifiques auxquelles les données secondaires pourraient répondre. Les chercheurs doivent préciser ce qu’ils souhaitent accomplir—qu’il s’agisse d’une approche exploratoire (comprendre pourquoi un événement est survenu) ou confirmatoire (valider des hypothèses). La deuxième étape consiste à identifier et localiser des sources de données secondaires appropriées, en tenant compte de la pertinence des données, de la crédibilité des sources, de la date de publication et de la portée géographique. La troisième étape implique la collecte et l’organisation systématiques des données, ce qui nécessite souvent d’accéder à plusieurs bases de données, de vérifier l’authenticité des sources et de consolider les informations sous des formats exploitables. Au cours de cette phase, il faut évaluer la qualité des données, la transparence méthodologique et la correspondance des périodes de collecte avec les besoins de la recherche. La quatrième étape se concentre sur la combinaison et la comparaison des jeux de données, l’identification de tendances entre différentes sources et la reconnaissance de schémas ou d’anomalies issus de l’analyse comparative. Les chercheurs peuvent devoir filtrer les données inutilisables, concilier des informations contradictoires et organiser les résultats sous forme de récits cohérents. L’étape finale consiste en une analyse et une interprétation approfondies, au cours desquelles les chercheurs examinent si les données secondaires répondent suffisamment aux questions initiales, identifient les lacunes de connaissance et déterminent si une recherche primaire complémentaire est nécessaire. Cette approche structurée garantit que la recherche secondaire produit des résultats crédibles et exploitables, plutôt que des conclusions superficielles.
L’un des avantages les plus convaincants de la recherche secondaire est son efficacité économique spectaculaire par rapport aux méthodologies de recherche primaire. L’analyse des données secondaires est presque toujours moins coûteuse que la réalisation d’une recherche primaire, les organisations économisant généralement de 50 à 70 % sur leur budget en exploitant les ensembles de données existants. Puisque la collecte de données représente la part la plus onéreuse de la recherche primaire—incluant le recrutement de participants, les incitations, la gestion d’enquêtes et les opérations de terrain—la recherche secondaire élimine entièrement ces coûts importants. La plupart des sources de données secondaires sont accessibles gratuitement via des agences gouvernementales, des bibliothèques publiques et des dépôts académiques, ou à faible coût via des abonnements. Les économies de temps sont tout aussi significatives : la recherche secondaire peut être menée en quelques jours ou semaines, tandis que la recherche primaire nécessite généralement des semaines à des mois. Les chercheurs peuvent accéder à des ensembles de données compilés immédiatement via des plateformes en ligne, permettant une prise de décision rapide pour les enjeux urgents. En outre, les données secondaires sont généralement pré-nettoyées et organisées sous formats électroniques, éliminant la phase fastidieuse de préparation des données qui consomme beaucoup de ressources dans la recherche primaire. Pour les organisations ayant des budgets limités ou des délais serrés, la recherche secondaire offre une voie accessible vers des insights marché, de l’intelligence concurrentielle et l’analyse des tendances. La croissance de l’industrie mondiale des études de marché à 140 milliards de dollars reflète l’investissement croissant des organisations dans la recherche, la recherche secondaire constituant un pilier économique des stratégies de recherche globales.
Dans le contexte de la surveillance de l’IA et de l’optimisation pour les moteurs génératifs, la recherche secondaire joue un rôle clé dans l’établissement de bases de référence et la compréhension de la façon dont les systèmes d’IA citent les sources. Des plateformes comme AmICited appliquent les principes de la recherche secondaire pour suivre les mentions de marque sur des systèmes d’IA tels que ChatGPT, Perplexity, Google AI Overviews et Claude. En analysant les données existantes sur les citations des concurrents, les tendances sectorielles et la performance historique des marques dans les réponses de l’IA, les organisations peuvent identifier des schémas dans la sélection et la citation des sources par les systèmes d’IA. La recherche secondaire permet d’établir des points de référence pour la visibilité dans l’IA, permettant aux marques de comprendre leur position actuelle par rapport aux concurrents et aux standards sectoriels. Les organisations peuvent analyser les données secondaires sur la performance de leur contenu, les schémas de citation et les préférences des systèmes d’IA pour optimiser leur stratégie de contenu en vue d’une meilleure citation dans l’IA. Cette intégration de la recherche secondaire à la surveillance de l’IA offre une compréhension globale de la manière dont les marques apparaissent dans les résultats de recherche générative et les réponses alimentées par l’IA. L’analyse des données de citation existantes, des stratégies des concurrents et des tendances sectorielles fournit un contexte pour interpréter les données de surveillance en temps réel, permettant des stratégies d’optimisation plus sophistiquées. Alors que 47 % des chercheurs dans le monde utilisent régulièrement l’IA dans leurs activités d’études de marché, la convergence de la méthodologie de recherche secondaire et des outils d’analyse par IA transforme la compréhension de la position marché et de la visibilité dans l’IA des organisations.
Garantir la qualité des données issues de la recherche secondaire exige des processus de validation rigoureux et une évaluation critique de la crédibilité des sources. Les chercheurs doivent examiner la méthodologie de recherche initiale, incluant la taille de l’échantillon, les caractéristiques de la population, les procédures de collecte et les biais potentiels pouvant avoir influencé les résultats. Les revues académiques évaluées par des pairs maintiennent des normes de crédibilité plus élevées que les blogs ou articles d’opinion, car elles sont soumises à un examen d’experts avant publication. Les agences gouvernementales et les instituts de recherche reconnus appliquent généralement des contrôles de qualité stricts, rendant leurs données plus fiables que les sources auto-publiées. La recoupe des résultats entre plusieurs sources indépendantes permet de valider les conclusions et d’identifier d’éventuelles incohérences révélatrices de problèmes de qualité. Les chercheurs doivent vérifier si la période de l’étude initiale correspond aux besoins actuels, car des données recueillies il y a cinq ans peuvent ne plus refléter les conditions du marché ou les comportements des consommateurs actuels. La date de publication est cruciale—les données secondaires perdent en pertinence avec le temps, en particulier dans les secteurs dynamiques où les conditions évoluent rapidement. Les chercheurs doivent également considérer si la méthodologie de collecte initiale correspond à leurs exigences, car des méthodologies différentes peuvent rendre les résultats incomparables. Contacter les chercheurs ou organisations d’origine peut fournir un contexte additionnel sur les processus de collecte, les taux de réponse et les éventuelles limites. Cette approche de validation complète garantit que les conclusions de la recherche secondaire reposent sur des données crédibles et de qualité, et non sur des informations possiblement erronées ou obsolètes.
La recherche secondaire offre de nombreux avantages stratégiques qui en font un élément essentiel des programmes de recherche globaux. Des données facilement accessibles sont disponibles via des bases de données en ligne, des bibliothèques et des portails gouvernementaux, nécessitant peu d’expertise technique pour être consultées. La rapidité du processus de recherche permet aux organisations de répondre à des questions en quelques jours plutôt qu’en plusieurs mois, soutenant la prise de décision rapide et la réactivité concurrentielle. Les coûts financiers réduits rendent la recherche secondaire accessible aux structures disposant de budgets restreints, démocratisant ainsi l’accès aux insights marché. La recherche secondaire peut déclencher des actions de recherche supplémentaires en identifiant des lacunes nécessitant une investigation primaire, servant ainsi de base à des études plus ciblées. La capacité à étendre rapidement les résultats grâce à des ensembles de données à grande échelle tels que les données de recensement permet de tirer des conclusions sur de larges populations sans enquêtes coûteuses. La recherche secondaire offre des pré-insights permettant de déterminer la nécessité ou non de poursuivre la recherche, économisant potentiellement des ressources en identifiant des réponses déjà présentes dans la littérature publiée. La richesse et la profondeur des données disponibles autorisent l’analyse des tendances sur plusieurs années, l’identification de schémas et la compréhension du contexte historique pour éclairer les décisions actuelles. Les organisations peuvent tirer des avantages concurrentiels en exploitant des données internes secondaires inaccessibles à leurs concurrents, fournissant des insights uniques sur la performance et la position marché.
Malgré ses avantages, la recherche secondaire présente des limites importantes que les chercheurs doivent prendre en considération. Les données obsolètes constituent une préoccupation majeure, car les sources secondaires peuvent ne pas refléter les conditions de marché, les préférences des consommateurs ou les évolutions technologiques récentes. Dans les secteurs dynamiques, les données secondaires peuvent devenir obsolètes en quelques mois, obligeant à vérifier leur actualité. L’absence de contrôle sur la méthodologie signifie qu’il est impossible de vérifier la façon dont les données originales ont été recueillies, si les standards de qualité ont été respectés ou si des biais inconnus ont influencé les résultats. L’incapacité à personnaliser les données pour des questions de recherche spécifiques oblige souvent à adapter les objectifs à l’information disponible, plutôt que de trouver des données répondant parfaitement aux besoins. L’accès non exclusif aux données permet aux concurrents d’exploiter les mêmes sources, supprimant l’avantage concurrentiel que procure la recherche primaire. Le biais inconnu du chercheur initial a pu influencer les résultats de façon indétectable ou irréversible pour les chercheurs actuels. Les écarts de pertinence des données peuvent exiger de compléter les conclusions secondaires par de la recherche primaire pour répondre à des questions précises. La complexité de l’intégration des données provenant de sources secondaires multiples aux méthodologies, temporalités et populations différentes peut introduire des défis analytiques. Les chercheurs doivent investir un effort considérable dans la vérification et la validation des données afin de garantir que les sources secondaires respectent les standards de qualité et fournissent des insights fiables.
L’avenir de la recherche secondaire est fondamentalement transformé par l’intelligence artificielle, l’apprentissage automatique et les technologies d’analyses avancées. Les outils propulsés par l’IA permettent désormais de traiter des ensembles de données massifs, d’identifier des schémas complexes et d’extraire des insights impossibles à obtenir manuellement. 83 % des professionnels des études de marché prévoient d’investir dans l’IA pour leurs activités en 2025, ce qui témoigne d’une reconnaissance généralisée du potentiel transformateur de l’IA. L’intégration des données synthétiques à la recherche secondaire s’accélère, avec plus de 70 % des chercheurs de marché s’attendant à ce que les données synthétiques représentent plus de 50 % de la collecte de données d’ici trois ans. Ce changement reflète l’importance croissante des insights générés par l’IA et le besoin de compléter les sources secondaires traditionnelles par des données générées algorithmique-ment. L’analyse automatisée de contenu par traitement du langage naturel permet d’analyser à grande échelle des sources qualitatives secondaires, en identifiant thèmes, sentiments et relations sémantiques à travers des milliers de documents. La convergence de la recherche secondaire et des stratégies d’optimisation pour moteurs génératifs (GEO) crée de nouvelles opportunités pour comprendre la citation et la référence de sources par les systèmes d’IA. Alors que des systèmes comme ChatGPT, Perplexity et Claude deviennent des sources d’information majeures pour les consommateurs, les méthodologies de recherche secondaire évoluent pour analyser la sélection, la citation et la présentation de l’information par ces systèmes. Les organisations utilisent de plus en plus la recherche secondaire pour établir des bases de référence de visibilité dans l’IA, comprenant comment leur marque apparaît dans les réponses générées par l’IA par rapport à la concurrence. L’avenir verra probablement une recherche secondaire plus sophistiquée, en temps réel et intégrée à des plateformes de surveillance de l’IA qui suivent les mentions de marque sur plusieurs systèmes simultanément. Cette évolution marque un passage de la recherche secondaire traditionnelle vers une analyse dynamique et enrichie par l’IA, apportant des insights continus sur la position marché, le paysage concurrentiel et la visibilité dans l’IA.
Les organisations souhaitant maximiser l’efficacité de la recherche secondaire doivent appliquer des bonnes pratiques structurées afin de garantir une analyse rigoureuse et des résultats exploitables. Définir des objectifs de recherche clairs avant de commencer, en formulant les questions spécifiques que la recherche secondaire peut aborder et en établissant des critères de succès pour le projet. Prioriser la crédibilité des sources en privilégiant les revues académiques évaluées par des pairs, les agences gouvernementales et les institutions reconnues, plutôt que des sources auto-publiées ou partiales. Mettre en place des protocoles de vérification exigeant de recouper les résultats entre plusieurs sources indépendantes avant de tirer des conclusions. Documenter la méthodologie utilisée, en notant les sources consultées, la façon dont les données ont été analysées, et les éventuelles limites ou biais identifiés. Évaluer la fraîcheur des données en vérifiant qu’elles reflètent les conditions de marché actuelles et ne sont pas obsolètes du fait de changements rapides. Combiner avec de la recherche primaire lorsque les données secondaires ne répondent pas à certaines questions ou qu’une validation des résultats secondaires s’avère nécessaire. Exploiter les données internes en auditant minutieusement les bases de données organisationnelles et les recherches antérieures avant de chercher des sources secondaires externes. Utiliser des outils d’analyse propulsés par l’IA pour traiter efficacement de grands ensembles de données secondaires et identifier des schémas difficilement détectables manuellement. Surveiller la visibilité dans l’IA en intégrant les insights de la recherche secondaire à des plateformes telles qu’AmICited afin de comprendre la présence de la marque dans les réponses générées par l’IA. Établir des plannings de mise à jour pour les projets de recherche secondaire, reconnaissant que les conditions de marché évoluent et qu’une réanalyse périodique peut être nécessaire pour conserver la pertinence des insights.
La recherche secondaire demeure une méthodologie essentielle pour les organisations souhaitant obtenir rapidement et à moindre coût des informations sur les marchés, la concurrence et les tendances de consommation. Alors que l’industrie mondiale des études de marché poursuit son expansion—passant de 102 milliards de dollars en 2021 à 140 milliards en 2024—la recherche secondaire occupe une place de plus en plus importante dans les stratégies de recherche globales. L’intégration des technologies d’IA et d’apprentissage automatique transforme la recherche secondaire, qui passe d’un processus manuel et chronophage à une discipline analytique automatisée et sophistiquée, capable de traiter d’immenses ensembles de données et d’identifier des schémas complexes. Les organisations maîtrisant la méthodologie de la recherche secondaire acquièrent un avantage concurrentiel significatif, favorisant la prise de décision rapide, l’analyse de marché économique et la planification stratégique éclairée. L’émergence de plateformes de surveillance de l’IA comme AmICited démontre que les principes de la recherche secondaire évoluent pour répondre à de nouveaux défis à l’ère de l’IA générative, où il est crucial de comprendre comment les systèmes d’IA citent et référencent les sources pour la visibilité des marques et leur positionnement marché. Alors que 47 % des chercheurs dans le monde utilisent désormais régulièrement l’IA dans leurs études de marché, l’avenir de la recherche secondaire réside dans l’intégration sophistiquée de la méthodologie traditionnelle avec les capacités de pointe de l’IA. Les organisations combinant des pratiques rigoureuses de recherche secondaire, des outils d’analyse propulsés par l’IA, des plateformes de surveillance en temps réel et des protocoles de validation stratégiques seront les mieux placées pour extraire une valeur maximale des données existantes tout en préservant la crédibilité et la précision nécessaires à une prise de décision confiante dans un environnement commercial de plus en plus complexe et piloté par l’IA.
La recherche primaire consiste à collecter des données originales directement auprès des sources par le biais d'enquêtes, d'entretiens ou d'observations, tandis que la recherche secondaire analyse des données existantes précédemment recueillies par d'autres. La recherche primaire est plus longue et coûteuse mais fournit des informations sur mesure, alors que la recherche secondaire est plus rapide et économique mais peut ne pas répondre précisément aux questions de recherche spécifiques. Les deux méthodes sont souvent combinées pour des stratégies de recherche complètes.
Les sources de recherche secondaire incluent les statistiques gouvernementales et les données de recensement, les revues académiques et publications évaluées par des pairs, les rapports d'études de marché d'agences professionnelles, les rapports d'entreprise et livres blancs, les données des associations sectorielles, les archives de presse et publications médiatiques, et les bases de données internes d'organisations. Ces sources peuvent être internes (provenant de votre organisation) ou externes (accessibles au public ou achetées auprès de tiers). Le choix de la source dépend des objectifs de recherche, de la pertinence des données et des exigences de crédibilité.
La recherche secondaire élimine les coûts de collecte de données puisque l'information a déjà été recueillie et compilée par d'autres. Les chercheurs évitent les frais liés au recrutement de participants, à la réalisation d'enquêtes ou d'entretiens, et à la gestion des opérations de terrain. De plus, les données secondaires sont souvent disponibles gratuitement ou à faible coût via des bases de données publiques, des bibliothèques et des agences gouvernementales. Les organisations peuvent économiser 50 à 70 % sur leurs budgets de recherche en exploitant les ensembles de données existants, ce qui est idéal pour les équipes disposant de ressources limitées.
Les données de recherche secondaire peuvent être obsolètes, manquant potentiellement les changements ou tendances récentes du marché. La méthodologie de collecte initiale est inconnue, soulevant des questions sur la qualité et la validité des données. Les chercheurs n'ont aucun contrôle sur la façon dont les données ont été collectées, ce qui peut introduire des biais inconnus. Les jeux de données secondaires peuvent ne pas répondre précisément aux questions de recherche spécifiques, obligeant les chercheurs à adapter leurs objectifs. De plus, les données secondaires ne sont pas exclusives, ce qui signifie que les concurrents peuvent accéder aux mêmes informations.
Les organisations doivent examiner la méthodologie de recherche initiale, la date de publication et la réputation de la source avant d'utiliser les données secondaires. Les revues académiques évaluées par des pairs et les agences gouvernementales maintiennent généralement des normes de crédibilité plus élevées que les blogs ou articles d'opinion. Recouper les données entre plusieurs sources indépendantes aide à valider les résultats et à identifier d'éventuelles incohérences. Les chercheurs doivent évaluer si la taille de l'échantillon, la population et la conception de la recherche de l'étude initiale correspondent à leurs besoins. Contacter les chercheurs ou organisations d'origine peut fournir un contexte supplémentaire sur les processus de collecte des données.
La recherche secondaire fournit un contexte historique et des données de référence pour les plateformes de surveillance de l'IA comme AmICited, qui suivent les mentions de marque sur des systèmes d'IA tels que ChatGPT, Perplexity et Claude. En analysant les données existantes sur les mentions de concurrents, les tendances sectorielles et la performance historique des marques, les organisations peuvent établir des points de référence pour la visibilité dans l'IA. La recherche secondaire aide à identifier les schémas de citation des sources par les systèmes d'IA, permettant aux marques d'optimiser leur stratégie de contenu pour de meilleures citations et une meilleure visibilité dans les résultats de recherche générative.
Les outils d'IA automatisent désormais l'analyse des données secondaires, permettant aux chercheurs de traiter de grands ensembles de données plus rapidement et d'identifier des schémas difficiles à détecter manuellement. Environ 47 % des chercheurs dans le monde utilisent régulièrement l'IA dans leurs activités d'études de marché, avec des taux d'adoption atteignant 58 % dans la région Asie-Pacifique. Les outils d'analyse de contenu propulsés par l'IA peuvent reconnaître des thèmes, des connexions sémantiques et des relations au sein des sources secondaires. Toutefois, 73 % des chercheurs se disent confiants dans l'application de l'IA à la recherche secondaire, tandis que des inquiétudes concernant les lacunes de compétences subsistent dans certaines équipes.
La recherche secondaire peut être réalisée en quelques jours ou semaines puisque les données sont déjà collectées et organisées, alors que la recherche primaire nécessite généralement des semaines à des mois pour la planification, la collecte et l'analyse des données. Les organisations peuvent accéder immédiatement aux données secondaires via des bases de données et bibliothèques en ligne, ce qui permet une prise de décision rapide. Cet avantage de rapidité rend la recherche secondaire idéale pour les décisions commerciales urgentes, l'analyse concurrentielle et les phases préliminaires de recherche. Cependant, la contrepartie est que les données secondaires peuvent ne pas fournir les informations spécifiques et actuelles que délivre la recherche primaire.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
La recherche vectorielle utilise des représentations vectorielles mathématiques pour trouver des données similaires en mesurant les relations sémantiques. Décou...
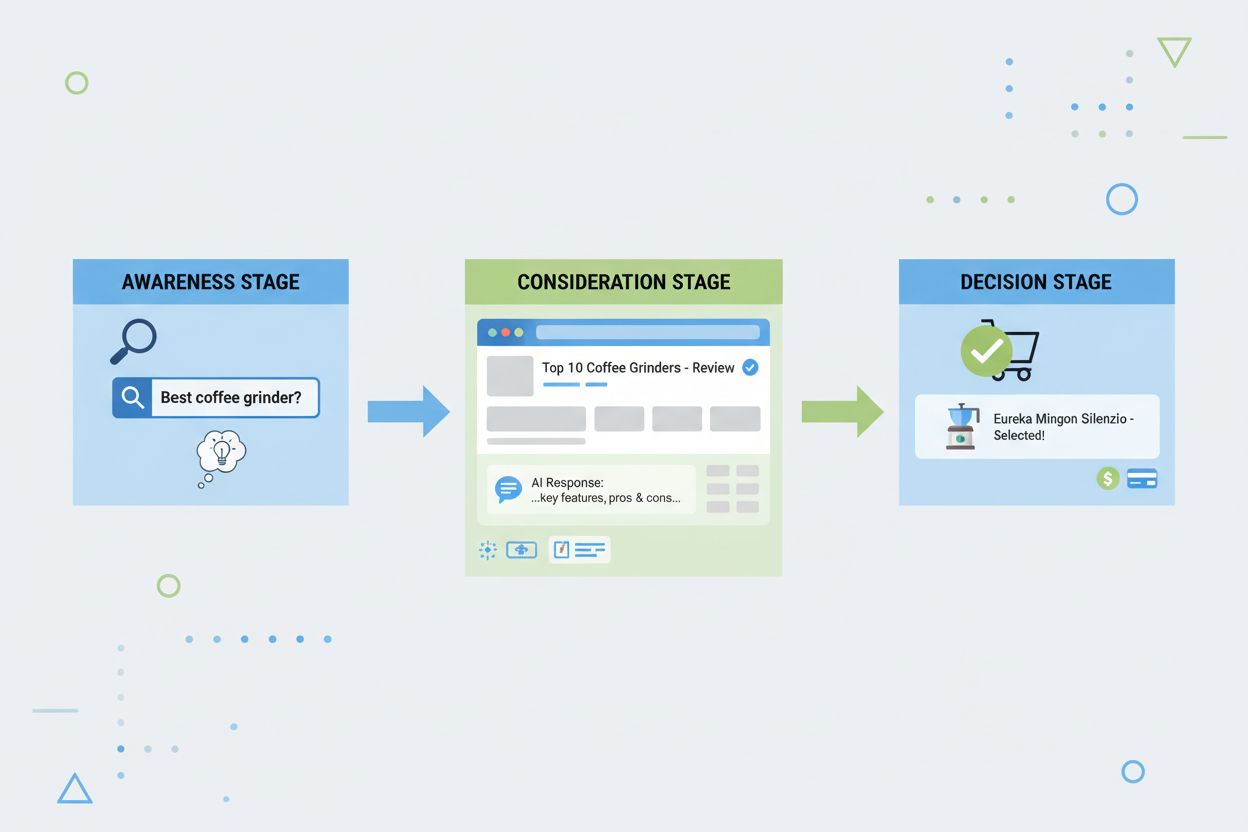
Découvrez ce qu’est un parcours de recherche, comment les utilisateurs naviguent à travers les étapes de prise de conscience, de considération et de décision, e...
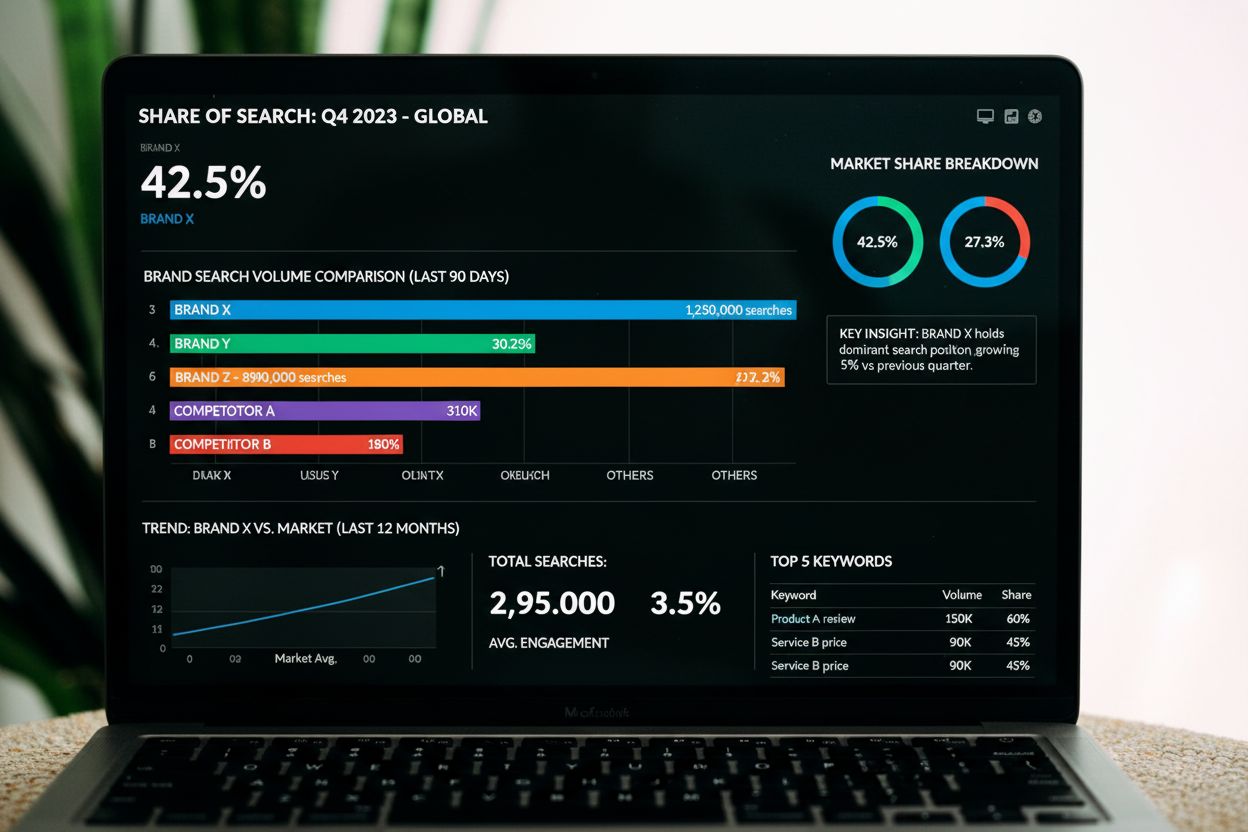
La part de recherche mesure le volume de recherche d'une marque par rapport aux concurrents de la catégorie. Découvrez comment cet indicateur prédit la part de ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.