Définition de l’Algorithme Sonar
L’Algorithme Sonar est le système propriétaire de classement RAG (retrieval-augmented generation) de Perplexity qui propulse son moteur de réponse en combinant recherche sémantique hybride, recherche par mots-clés, réordonnancement neuronal et génération de citations en temps réel. Contrairement aux moteurs de recherche traditionnels qui classent des pages à afficher dans une liste de résultats, Sonar classe des extraits de contenu afin de les synthétiser en une réponse unique, accompagnée de citations intégrées vers les documents sources. L’algorithme privilégie la fraîcheur du contenu, la pertinence sémantique et la citabilité afin de fournir des réponses argumentées, sourcées, tout en minimisant les hallucinations. Sonar représente un changement fondamental dans la façon dont les systèmes IA récupèrent et classent l’information—passant des signaux d’autorité basés sur les liens à des métriques d’utilité centrées sur la capacité du contenu à satisfaire directement l’intention de l’utilisateur et à être proprement cité dans des réponses synthétisées. Cette distinction est cruciale pour comprendre en quoi la visibilité dans les moteurs de réponse IA diffère du SEO traditionnel, car Sonar évalue le contenu non pour sa capacité à se classer dans une liste, mais pour son potentiel à être extrait, synthétisé et attribué au sein d’une réponse générée par IA.
Contexte et Origines : l’Évolution du Classement Piloté par l’IA
L’émergence de l’Algorithme Sonar reflète un mouvement plus large de l’industrie vers la génération augmentée par récupération comme architecture dominante des moteurs de réponse IA. Lorsque Perplexity a été lancé fin 2022, l’entreprise a identifié une lacune critique dans le paysage de l’IA : alors que ChatGPT offrait de puissantes capacités conversationnelles, il manquait d’accès à l’information en temps réel et d’attribution des sources, entraînant hallucinations et réponses obsolètes. L’équipe fondatrice de Perplexity, initialement focalisée sur un outil de traduction de requêtes pour base de données, a entièrement pivoté pour construire un moteur de réponse capable de combiner la recherche web en direct avec la synthèse LLM. Ce choix stratégique a façonné l’architecture de Sonar dès l’origine—l’algorithme a été conçu non pour classer des pages à destination d’humains, mais pour récupérer et classer des fragments de contenu en vue d’une synthèse et citation par machine. En deux ans, Sonar est devenu l’un des systèmes de classement les plus sophistiqués de l’écosystème IA, avec les modèles Sonar de Perplexity occupant les rangs 1 à 4 dans l’évaluation Search Arena, surpassant nettement les modèles concurrents de Google et OpenAI. L’algorithme traite désormais plus de 400 millions de requêtes de recherche par mois, indexe plus de 200 milliards d’URL uniques et maintient la fraîcheur en temps réel grâce à des dizaines de milliers de mises à jour d’index par seconde. Cette échelle et sophistication soulignent l’importance de Sonar en tant que paradigme de classement déterminant à l’ère de la recherche IA.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Fonctionnement de l’Algorithme Sonar : le Pipeline RAG Multi-Étapes
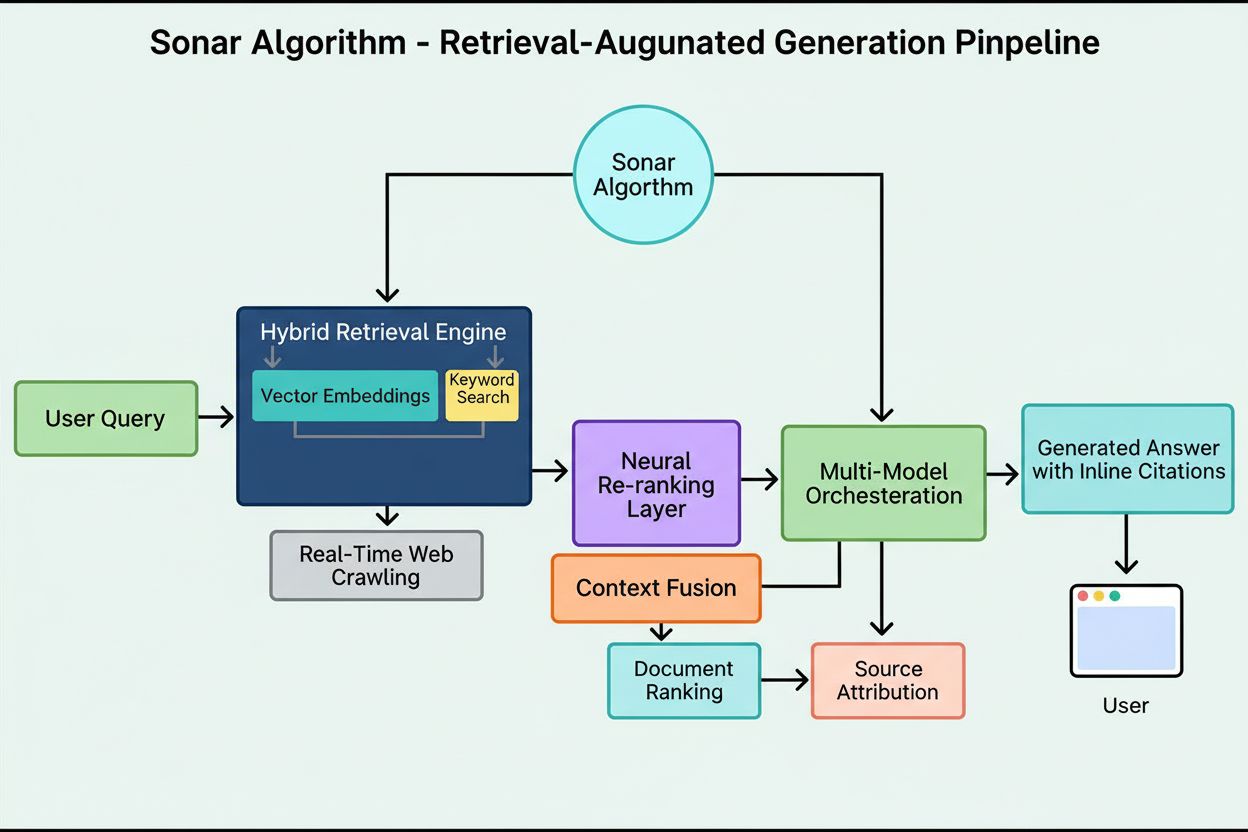
Le système de classement de Sonar fonctionne via un pipeline de génération augmentée par récupération en cinq étapes transformant les requêtes utilisateurs en réponses argumentées et sourcées. Première étape, Analyse de l’Intention de la Requête, un LLM dépasse la simple recherche de mots-clés pour comprendre sémantiquement ce que l’utilisateur demande vraiment, interprétant contexte, nuances et intention sous-jacente. Deuxième étape, Récupération Web en Temps Réel, la requête analysée est envoyée à l’index distribué massif de Perplexity propulsé par Vespa AI, qui fouille le web pour des pages et documents pertinents en temps réel. Ce système combine recherche dense (vectorielle via des embeddings sémantiques) et recherche clairsemée (lexicale/par mots-clés), fusionnant les résultats pour produire environ 50 documents candidats variés. Troisième étape, Extraction et Contextualisation des Extraits, le modèle génératif ne reçoit pas le texte complet des pages ; des algorithmes extraient les passages, paragraphes ou fragments les plus pertinents, les agrégeant dans une fenêtre de contexte ciblée. Quatrième étape, Génération de la Réponse Synthétisée avec Citations, ce contexte est transmis à un LLM choisi (famille propriétaire Sonar ou modèles tiers comme GPT-4 ou Claude), qui génère une réponse en langage naturel strictement basée sur l’information récupérée. Les citations intégrées relient chaque affirmation aux documents sources, garantissant transparence et vérification. Cinquième étape, Affinage Conversationnel, le contexte conversationnel est maintenu sur plusieurs tours, permettant des questions de suivi raffinant les réponses via des recherches web itératives. Le principe fondamental—« vous ne devez rien dire que vous n’avez pas récupéré »—assure que les réponses générées par Sonar sont ancrées dans des sources vérifiables, réduisant fondamentalement les hallucinations par rapport aux modèles dépendant uniquement des données d’entraînement.
Tableau Comparatif : Algorithme Sonar vs. Recherche Traditionnelle et Systèmes LLM Concurrents
| Aspect | Recherche Traditionnelle (Google) | Algorithme Sonar (Perplexity) | Classement ChatGPT | Classement Gemini | Classement Claude |
|---|
| Unité Principale | Liste classée de liens | Réponse synthétisée unique avec citations | Mentions d’entités par consensus | Contenu aligné E-E-A-T | Sources neutres et factuelles |
| Focus de la Récupération | Mots-clés, liens, signaux ML | Recherche hybride sémantique + mots-clés | Données d’entraînement + navigation web | Intégration graphe de connaissances | Filtres de sécurité constitutionnelle |
| Priorité Fraîcheur | Query-deserves-freshness (QDF) | Récupération web temps réel, +37 % sous 48 h | Priorité faible, dépend des données d’entraînement | Moyenne, intégrée à Google Search | Priorité faible, accent sur la stabilité |
| Signaux de Classement | Backlinks, autorité de domaine, CTR | Fraîcheur, pertinence sémantique, citabilité, bonus d’autorité | Reconnaissance d’entités, mentions de consensus | E-E-A-T, alignement conversationnel, données structurées | Transparence, citations vérifiables, neutralité |
| Mécanisme de Citation | Extraits d’URL dans les résultats | Citations intégrées avec liens sources | Implicite, souvent sans citation | AI Overviews avec attribution | Attribution explicite des sources |
| Diversité du Contenu | Résultats multiples inter-sites | Peu de sources sélectionnées pour synthèse | Synthèse multi-sources | Sources multiples dans l’overview | Sources équilibrées et neutres |
| Personnalisation | Subtile, surtout implicite | Modes focus explicites (Web, Académique, Finance, Rédaction, Social) | Implicite selon la conversation | Implicite selon le type de requête | Minimale, accent sur la cohérence |
| Gestion des PDF | Indexation standard | Avantage de citation de 22 % sur HTML | Indexation standard | Indexation standard | Indexation standard |
| Impact du Schéma | FAQ schema dans featured snippets | FAQ schema augmente les citations de 41 %, réduit le délai de 6 h | Impact direct minime | Impact modéré sur le graphe de connaissances | Impact direct minime |
| Optimisation de la Latence | Quelques millisecondes pour le classement | Récupération + génération en moins d’une seconde | Secondes pour la synthèse | Secondes pour la synthèse | Secondes pour la synthèse |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Architecture Technique : Récupération Hybride et Réordonnancement Neuronal
La fondation technique de l’Algorithme Sonar repose sur un moteur de récupération hybride combinant plusieurs stratégies de recherche pour maximiser à la fois le rappel et la précision. La récupération dense (recherche vectorielle) utilise des embeddings sémantiques pour comprendre la signification conceptuelle des requêtes, trouvant des documents contextuellement similaires même sans correspondance exacte de mots-clés. Cette approche s’appuie sur des embeddings de type transformer qui projettent requêtes et documents dans un espace vectoriel de haute dimension où le contenu sémantiquement proche se regroupe. La récupération clairsemée (recherche lexicale) complète la dense par sa précision sur les termes rares, noms de produits, identifiants internes et entités spécifiques où l’ambiguïté sémantique n’est pas souhaitée. Le système recourt à des fonctions de classement comme BM25 pour effectuer des correspondances exactes sur ces termes critiques. Les deux méthodes sont fusionnées et dédupliquées pour obtenir environ 50 documents candidats variés, évitant le surapprentissage de domaine et assurant une couverture large de sources autorisées. Après la récupération initiale, la couche de réordonnancement neuronal de Sonar exploite des modèles avancés d’apprentissage automatique (tels que les cross-encoders DeBERTa-v3) pour évaluer les candidats selon un ensemble riche de signaux : scores de pertinence lexicale, similarité vectorielle, autorité du document, signaux de fraîcheur, métriques d’engagement utilisateur et métadonnées. Cette architecture de classement multi-phases permet à Sonar d’affiner progressivement les résultats sous des contraintes de latence strictes, garantissant que l’ensemble final classé représente les sources les plus pertinentes et qualitatives pour la synthèse. Toute l’infrastructure de récupération repose sur Vespa AI, une plateforme de recherche distribuée capable de gérer l’indexation à l’échelle web (200+ milliards d’URL), les mises à jour temps réel (dizaines de milliers par seconde) et la compréhension fine du contenu grâce au découpage en fragments. Ce choix d’architecture permet à la petite équipe d’ingénierie de Perplexity de se concentrer sur les composants différenciants—l’orchestration RAG, le tuning des modèles Sonar et l’optimisation d’inférence—plutôt que de réinventer la recherche distribuée.
La Fraîcheur du Contenu comme Facteur Dominant de Classement
La fraîcheur du contenu est l’un des signaux de classement les plus puissants de Sonar, des études empiriques montrant que les pages récemment mises à jour reçoivent des taux de citation nettement supérieurs. Lors de tests A/B contrôlés sur 24 semaines et 120 URL, les articles mis à jour dans les dernières 48 heures étaient cités 37 % plus fréquemment que du contenu identique avec un ancien horodatage. Cet avantage persiste à environ 14 % après deux semaines, indiquant que la fraîcheur procure un effet soutenu mais déclinant. Ce mécanisme s’enracine dans la philosophie de Sonar : l’algorithme considère le contenu obsolète comme un risque accru d’hallucination, partant du principe que l’information datée peut avoir été supplantée par des nouveautés. L’infrastructure de Perplexity traite des dizaines de milliers de demandes de mise à jour par seconde, fournissant des signaux de fraîcheur en temps réel. Un modèle ML prédit si une URL doit être réindexée et planifie les mises à jour selon l’importance de la page et la fréquence d’historique des mises à jour, assurant que le contenu à forte valeur est rafraîchi plus agressivement. Même de simples modifications cosmétiques réinitialisent l’horloge de fraîcheur, à condition que le CMS republie l’horodatage modifié. Pour les éditeurs, cela crée une nécessité stratégique : adopter une cadence newsroom avec mises à jour hebdomadaires ou quotidiennes, ou voir le contenu evergreen décliner progressivement en visibilité. L’implication est majeure—à l’ère Sonar, la vélocité du contenu n’est plus un vanity metric mais une condition de survie. Les marques automatisant des micro-mises à jour hebdomadaires, ajoutant des journaux de changements ou maintenant des workflows d’optimisation continue décrocheront une part de citation disproportionnée par rapport aux concurrents sur des pages statiques et rarement mises à jour.
Pertinence Sémantique et Structure de Contenu Orientée Réponse
Sonar privilégie la pertinence sémantique à la densité de mots-clés, récompensant fondamentalement le contenu répondant directement aux requêtes en langage naturel et conversationnel. Le système de récupération de l’algorithme utilise des embeddings vectoriels denses pour faire correspondre les requêtes au contenu au niveau conceptuel, ce qui permet à des pages employant synonymes, terminologie connexe ou langage contextuel riche de surpasser des pages surchargées de mots-clés mais pauvres en profondeur sémantique. Ce basculement du mot-clé vers le sens a un fort impact sur la stratégie de contenu. Les contenus performants dans Sonar présentent plusieurs caractéristiques structurelles : ils débutent par un résumé court et factuel avant d’entrer dans le détail, utilisent des titres H2/H3 descriptifs et des paragraphes courts facilitant l’extraction de passages, incluent citations claires et liens vers les sources primaires et affichent horodatages et notes de version pour signaler la fraîcheur. Chaque paragraphe fonctionne comme une unité sémantique atomique, optimisée pour la clarté copy-paste et la compréhension des LLM. Les tableaux, puces et graphiques labellisés sont particulièrement précieux car ils offrent une information structurée, facilement quotable. L’algorithme valorise aussi l’analyse originale et les données uniques par rapport à l’agrégation, car le moteur de synthèse de Sonar recherche des sources ajoutant de nouveaux angles, documents primaires ou insights propriétaires se démarquant des survols génériques. Cet accent sur la richesse sémantique et la structure orientée réponse marque une rupture avec le SEO traditionnel, où densité de mots-clés et autorité de lien dominaient. À l’ère Sonar, le contenu doit être conçu pour la récupération et la synthèse machine, non pour la simple navigation humaine.
Héberger des PDFs : un Atout Stratégique
Les PDFs hébergés publiquement constituent un avantage significatif, souvent négligé, dans le système de classement de Sonar, des tests empiriques démontrant que les versions PDF surpassent les équivalents HTML d’environ 22 % en fréquence de citation. Cet avantage provient du fait que le crawler de Sonar traite les PDFs plus favorablement que les pages HTML. Les PDFs n’ont ni bandeaux cookies, ni exigences de rendu JavaScript, ni authentification paywall, ni autres complications HTML qui peuvent masquer ou retarder l’accès au contenu. Le crawler de Sonar peut lire les PDFs proprement et systématiquement, extrayant le texte sans ambiguïté de parsing comme dans le HTML complexe. Les éditeurs peuvent tirer parti de cet avantage en hébergeant les PDFs dans des répertoires accessibles, en utilisant des noms de fichiers sémantiques reflétant les sujets et en signalant le PDF comme canonique via des balises <link rel="alternate" type="application/pdf"> dans le head HTML. Cela crée ce que des chercheurs appellent un « piège à LLM »—un actif très visible que les scripts de suivi concurrents ne peuvent facilement détecter ou surveiller. Pour les entreprises B2B, éditeurs SaaS et organisations de recherche, cette stratégie est particulièrement puissante : publier livres blancs, rapports de recherche, études de cas et documentation technique au format PDF peut augmenter considérablement les taux de citation Sonar. L’essentiel est de traiter le PDF non comme un simple téléchargement, mais comme une copie canonique méritant le même (voire plus) d’effort d’optimisation que la version HTML. Cette approche s’avère particulièrement efficace pour le contenu entreprise, où les PDF contiennent souvent de l’information plus structurée et autorisée que des pages web.
Schéma FAQ et Optimisation des Données Structurées
Le balisage JSON-LD FAQ amplifie fortement les taux de citation Sonar, les pages contenant trois blocs FAQ ou plus recevant des citations 41 % plus fréquemment que les pages témoins sans schéma. Cette hausse spectaculaire reflète la préférence de Sonar pour le contenu structuré, en chunks, qui s’aligne avec sa logique de récupération et de synthèse. Le schéma FAQ présente des unités Q&R distinctes et autonomes que l’algorithme peut facilement extraire, classer et citer comme blocs sémantiques atomiques. Contrairement au SEO traditionnel où le schéma FAQ était un « plus », Sonar traite le balisage Q&R comme un levier de classement central. Sonar cite aussi fréquemment les questions FAQ comme texte d’ancrage, réduisant le risque de perte de contexte lors de la synthèse de phrases en milieu de paragraphe. Le schéma accélère également le délai avant première citation d’environ six heures, suggérant que le parseur de Sonar priorise tôt les blocs Q&R structurés dans la cascade de classement. Pour les éditeurs, la stratégie d’optimisation est simple : insérer trois à cinq blocs FAQ ciblés sous la ligne de flottaison, avec des formulations conversationnelles proches des requêtes réelles. Les questions doivent utiliser des formulations longue traîne et une symétrie sémantique avec les requêtes Sonar probables. Chaque réponse doit être concise, factuelle et directe, sans remplissage ni langue marketing. Cette approche s’avère particulièrement efficace pour les sociétés SaaS, cliniques et cabinets de services, où le contenu FAQ s’aligne naturellement avec l’intention utilisateur et les besoins de synthèse de Sonar.
Facteurs de Classement et Mécanique de Citation : Cadre Complet
Le système de classement de Sonar intègre de multiples signaux dans un cadre de citation unifié, la recherche identifiant huit facteurs principaux influençant la sélection des sources et la fréquence de citation. Premièrement, la pertinence sémantique à la question domine la récupération, l’algorithme privilégiant les contenus répondant clairement à la requête en langage naturel. Deuxièmement, l’autorité et la crédibilité comptent fortement, les partenariats éditeurs de Perplexity et bonus algorithmiques favorisant médias, institutions académiques et experts reconnus. Troisièmement, la fraîcheur pèse exceptionnellement, les mises à jour récentes générant +37 % de citations. Quatrièmement, la diversité et couverture sont valorisées, Sonar préférant plusieurs sources de qualité à une réponse mono-source, réduisant le risque d’hallucination par validation croisée. Cinquièmement, le mode et le scope déterminent quels index interroger—les modes focus (Académique, Finance, Rédaction, Social) restreignent les types de sources, tandis que les sélecteurs (Web, Fichiers Org, Web + Org, Aucun) définissent si la récupération puise dans le web, documents internes ou les deux. Sixièmement, la citabilité et l’accès sont critiques ; si PerplexityBot peut explorer et indexer le contenu, il est plus facile à citer, d’où l’importance de la conformité robots.txt et de la vitesse de chargement. Septièmement, les filtres sources personnalisés via API permettent aux déploiements entreprise de restreindre ou privilégier certains domaines, modifiant le classement dans les collections whitelistees. Huitièmement, le contexte conversationnel impacte les questions de suivi, les pages s’alignant avec l’intention évolutive surpassant des références génériques. Ces facteurs créent un espace de classement multidimensionnel où la réussite demande une optimisation simultanée sur plusieurs axes, et non un seul levier comme le backlink ou la densité de mots-clés.
Points Clés et Implications Stratégiques pour l’Optimisation de Contenu
- La fraîcheur est obligatoire : Automatisez des mises à jour ou micro-modifications hebdomadaires pour réinitialiser l’horloge de fraîcheur et maintenir la visibilité des citations.
- La clarté sémantique prime sur la densité de mots-clés : Rédigez pour le sens avec une structure orientée réponse, en langage naturel et titres clairs pour faciliter l’extraction LLM.
- Les PDF sont un atout stratégique : Hébergez des PDF accessibles publiquement avec liens canoniques pour gagner 22 % d’avantage de citation sur les HTML.
- Le schéma FAQ booste les citations : Insérez trois blocs FAQ JSON-LD ou plus avec des questions conversationnelles pour augmenter le taux de citation de 41 % et réduire le délai de six heures.
- La citabilité compte : Assurez-vous que PerplexityBot peut crawler votre contenu, que les pages se chargent vite et que le contenu est structuré pour l’extraction et la citation.
- Les bonus d’autorité existent : Obtenez des mentions sur des plateformes reconnues, nouez des partenariats éditeurs et développez des signaux d’expertise vérifiables pour déclencher les bonus algorithmiques.
- La diversité est valorisée : Apportez des données uniques, analyses originales et documents primaires distinctifs par rapport aux agrégateurs génériques.
- Suivez vos citations séparément : Surveillez la visibilité Sonar indépendamment du classement Google, les schémas de citation différant fondamentalement entre systèmes.
Évolution Future : Décodage Spéculatif, Classement Temps Réel et Impératif de Vélocité
L’Algorithme Sonar évolue rapidement à mesure que progressent l’inférence LLM et la technologie de récupération. Le blog technique de Perplexity a récemment mis en avant le décodage spéculatif, technique réduisant de moitié la latence des tokens en prédisant simultanément plusieurs tokens futurs. Des boucles de génération plus rapides permettent d’offrir des ensembles de récupération plus frais à chaque requête, rétrécissant la fenêtre où des pages obsolètes peuvent encore rivaliser. Un modèle Sonar-Reasoning-Pro déjà annoncé surpasse Gemini 2.0 Flash et GPT-4o Search dans les arènes, laissant présager des raffinements continus du classement Sonar. À mesure que la latence approche la vitesse de pensée humaine, la compétition pour la citation devient un jeu haute fréquence où la vélocité du contenu est le critère ultime. Attendez-vous à voir émerger des innovations comme les « APIs de fraîcheur LLM » auto-incrémentant les horodatages, comme la publicité automatisait jadis les bids, créant de nouvelles dynamiques compétitives autour de la mise à jour temps réel. Des défis juridiques et éthiques surgiront également alors que les pirates PDF exploiteront la préférence Sonar pour siphonner l’autorité d’ebooks ou recherches propriétaires, ce qui pourrait imposer de nouveaux contrôles d’accès ou d’authentification. L’implication générale est claire : l’ère Sonar récompense les éditeurs qui traitent chaque paragraphe comme un manifeste atomique, balisé et horodaté prêt à la consommation machine. Les marques obsédées par la première page Google mais négligeant la visibilité Sonar peignent des panneaux dans une ville dont les habitants viennent d’acquérir des casques VR. L’avenir appartient à ceux qui optimisent pour le « pourcentage de boîtes-réponse contenant notre URL », et non pour le CTR traditionnel.
Conclusion : l’Algorithme Sonar comme Paradigme Définissant de la Recherche IA
L’Algorithme Sonar incarne une réinvention fondamentale de la façon dont les systèmes de classement évaluent et priorisent le contenu à l’ère des moteurs de réponse IA. En combinant récupération hybride, réordonnancement neuronal, signaux de fraîcheur temps réel et exigence stricte de citation, Sonar a créé un environnement où les signaux SEO classiques comme les liens et la densité de mots-clés comptent bien moins que la pertinence sémantique, la fraîcheur du contenu et la citabilité. L’accent mis par l’algorithme sur l’ancrage des réponses dans des sources vérifiables répond à l’un des plus grands défis de l’IA générative—l’hallucination—en imposant la règle stricte que les LLM ne peuvent rien affirmer sans l’avoir récupéré. Pour les éditeurs et marques, comprendre les facteurs de classement de Sonar n’est plus optionnel ; c’est essentiel pour obtenir de la visibilité dans un paysage informationnel de plus en plus médié par l’IA. Le passage de l’autorité par lien à des métriques d’utilité orientées réponse demande une refonte stratégique du contenu, passant de l’optimisation par mots-clés à la richesse sémantique, de pages statiques à des actifs continuellement mis à jour, et du design centré humain à la structure lisible machine. À mesure que la part de marché de Perplexity croît et que les moteurs de réponse IA concurrents adoptent des architectures RAG similaires, l’influence de Sonar ne fera que s’accroître. Les marques qui prospéreront dans cette nouvelle ère seront celles qui verront en Sonar non une menace pour le SEO traditionnel, mais un système de classement complémentaire requérant des stratégies d’optimisation distinctes. En traitant le contenu comme des unités atomiques,