How to Optimize Your Content for AI Training Data and AI Search Engines
Learn how to optimize your content for AI training data inclusion. Discover best practices for making your website discoverable by ChatGPT, Gemini, Perplexity, ...
10 min read
Technical and legal mechanisms that allow content creators and copyright holders to prevent their work from being used in large language model training datasets. These include robots.txt directives, legal opt-out statements, and contractual protections under regulations like the EU AI Act.
Technical and legal mechanisms that allow content creators and copyright holders to prevent their work from being used in large language model training datasets. These include robots.txt directives, legal opt-out statements, and contractual protections under regulations like the EU AI Act.
AI training opt-out refers to the technical and legal mechanisms that allow content creators, copyright holders, and website owners to prevent their work from being used in large language model (LLM) training datasets. As AI companies scrape vast amounts of data from the internet to train increasingly sophisticated models, the ability to control whether your content participates in this process has become essential for protecting intellectual property and maintaining creative control. These opt-out mechanisms operate on two levels: technical directives that instruct AI crawlers to skip your content, and legal frameworks that establish contractual rights to exclude your work from training datasets. Understanding both dimensions is crucial for anyone concerned about how their content is being used in the AI era.

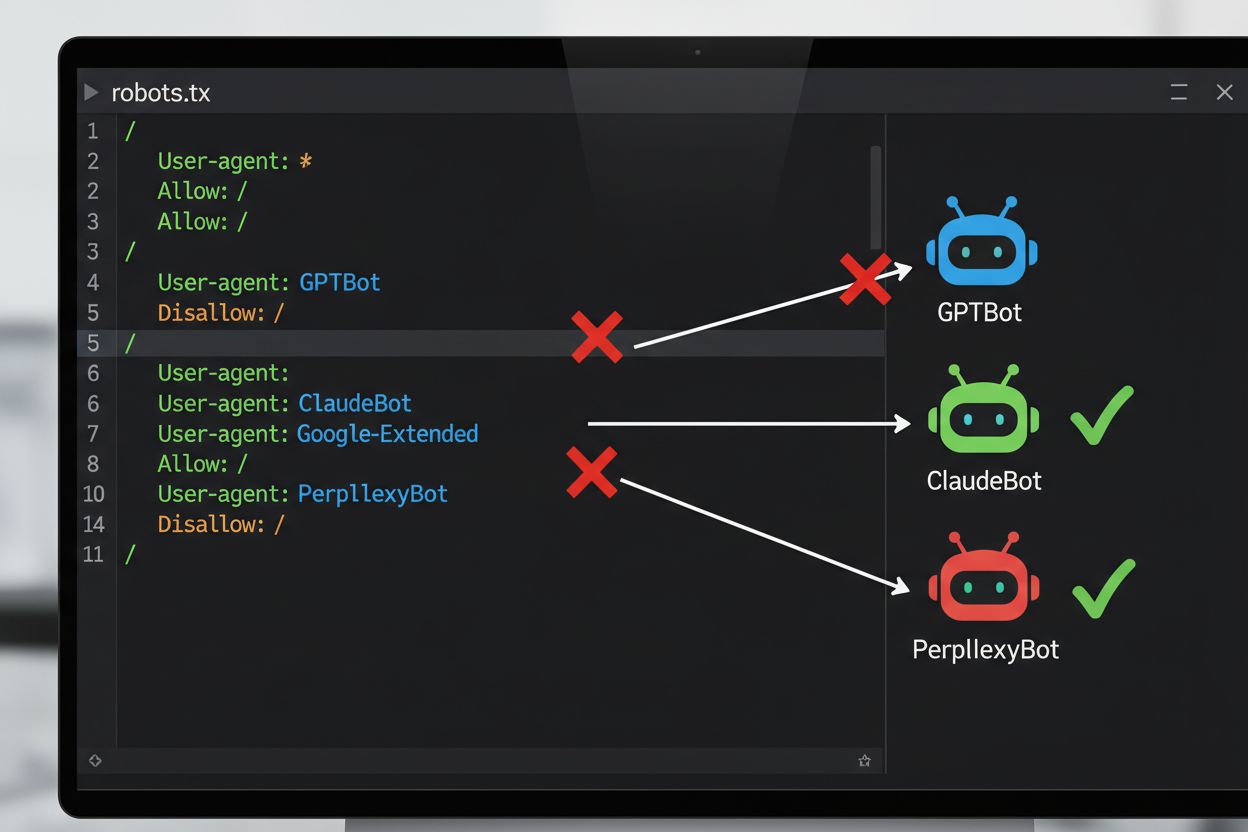
The most common technical method for opting out of AI training is through the robots.txt file, a simple text file placed in a website’s root directory that communicates crawler permissions to automated bots. When an AI crawler visits your site, it first checks robots.txt to see if it’s allowed to access your content. By adding specific disallow directives for particular crawler user agents, you can instruct AI bots to skip your site entirely. Each AI company operates multiple crawlers with distinct user agent identifiers—these are essentially the “names” that bots use to identify themselves when making requests. For example, OpenAI’s GPTBot identifies itself with the user agent string “GPTBot,” while Anthropic’s Claude uses “ClaudeBot.” The syntax is straightforward: you specify the user agent name and then declare what paths are disallowed, such as “Disallow: /” to block the entire site.
| AI Company | Crawler Name | User Agent Token | Purpose |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Model training data collection |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT search indexing |
| Anthropic | ClaudeBot | ClaudeBot | Chat citation fetch |
| Google-Extended | Google-Extended | Gemini AI training data | |
| Perplexity | PerplexityBot | PerplexityBot | AI search indexing |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AI model training |
| Common Crawl | CCBot | CCBot | Open dataset for LLM training |
The legal landscape for AI training opt-out has evolved significantly with the introduction of the EU AI Act, which took effect in 2024 and incorporates provisions from the Text and Data Mining (TDM) Directive. Under these regulations, AI developers are permitted to use copyright-protected works for machine learning purposes only if they have lawful access to the content and the copyright holder has not expressly reserved the right to exclude their work from text and data mining. This creates a formal legal mechanism for opt-out: copyright holders can file opt-out reservations with their works, effectively preventing their use in AI training without explicit permission. The EU AI Act represents a significant shift from the previous “move fast and break things” approach, establishing that companies training AI models must verify whether rightsholders have reserved their content and implement technical and organizational safeguards to prevent inadvertent use of opted-out works. This legal framework applies across the European Union and influences how global AI companies approach data collection and training practices.
Implementing an opt-out mechanism involves both technical configuration and legal documentation. On the technical side, website owners add disallow directives to their robots.txt file for specific AI crawler user agents, which compliant crawlers will respect when they visit the site. On the legal side, copyright holders can file opt-out statements with collecting societies and rights organizations—for example, the Dutch collecting society Pictoright and the French music society SACEM have established formal opt-out procedures allowing creators to reserve their rights against AI training use. Many websites and content creators now include explicit opt-out statements in their terms of service or metadata, declaring that their content should not be used for AI model training. However, the effectiveness of these mechanisms depends on crawler compliance: while major companies like OpenAI, Google, and Anthropic have publicly stated they respect robots.txt directives and opt-out reservations, the lack of a centralized enforcement mechanism means that determining whether an opt-out request has been properly honored requires ongoing monitoring and verification.
Despite the availability of opt-out mechanisms, significant challenges limit their effectiveness:
For organizations requiring stronger protection than robots.txt alone provides, several additional technical methods can be implemented. User agent filtering at the server or firewall level can block requests from specific crawler identifiers before they reach your application, though this remains vulnerable to spoofing. IP address blocking can target known crawler IP ranges published by major AI companies, though determined scrapers can evade this through proxy networks. Rate limiting and throttling can slow down scrapers by capping the number of requests allowed per second, making scraping economically unviable, though sophisticated bots can distribute requests across multiple IPs to circumvent these limits. Authentication requirements and paywalls provide strong protection by restricting access to logged-in users or paying customers, effectively preventing automated scraping. Device fingerprinting and behavioral analysis can detect bots by analyzing patterns like browser APIs, TLS handshakes, and interaction patterns that differ from human users. Some organizations have even deployed honeypots and tarpits—hidden links or infinite link mazes that only bots would follow—to waste crawler resources and potentially pollute their training datasets with garbage data.
The tension between AI companies and content creators has produced several high-profile confrontations that illustrate the practical challenges of opt-out enforcement. Reddit took aggressive action in 2023 by dramatically raising API access prices specifically to charge AI companies for data, effectively pricing out unauthorized scrapers and forcing companies like OpenAI and Anthropic to negotiate licensing agreements. Twitter/X implemented even more extreme measures, temporarily blocking all unauthenticated access to tweets and limiting how many tweets logged-in users could read, explicitly targeting data scrapers consuming resources. Stack Overflow initially blocked OpenAI’s GPTBot in their robots.txt file, citing licensing concerns with user-contributed code, though they later removed the block—possibly indicating negotiations with OpenAI. News media organizations responded en masse: over 50% of major news sites blocked AI crawlers by 2023, with outlets like The New York Times, CNN, Reuters, and The Guardian all adding GPTBot to their disallow lists. Some news organizations pursued legal action instead, with The New York Times filing a copyright infringement lawsuit against OpenAI, while others like the Associated Press negotiated licensing deals to monetize their content. These examples demonstrate that while opt-out mechanisms exist, their effectiveness depends on both technical implementation and willingness to pursue legal remedies when violations occur.
Implementing opt-out mechanisms is only half the battle; verifying that they’re actually working requires ongoing monitoring and testing. Several tools can help validate your configuration: Google Search Console includes a robots.txt tester for Googlebot-specific validation, while Merkle’s Robots.txt Tester and TechnicalSEO.com’s tool test individual crawler behavior against specific user agents. For comprehensive monitoring of whether AI companies are actually respecting your opt-out directives, platforms like AmICited.com provide specialized monitoring that tracks how AI systems reference your brand and content across GPTs, Perplexity, Google AI Overviews, and other AI platforms. This type of monitoring is particularly valuable because it reveals not just whether crawlers are accessing your site, but whether your content is actually appearing in AI-generated responses—indicating whether your opt-out is effective in practice. Regular server log analysis can also reveal which crawlers are attempting to access your site and whether they’re respecting your robots.txt directives, though this requires technical expertise to interpret correctly.
To effectively protect your content from unauthorized AI training use, adopt a layered approach combining technical and legal measures. First, implement robots.txt directives for all major AI training crawlers (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot, and others), understanding that this provides a baseline defense against compliant companies. Second, add explicit opt-out statements to your website’s terms of service and metadata, clearly declaring that your content should not be used for AI model training—this strengthens your legal position if violations occur. Third, monitor your configuration regularly using testing tools and server logs to verify that crawlers are respecting your directives, and update your robots.txt quarterly as new AI crawlers emerge constantly. Fourth, consider additional technical measures like user agent filtering or rate limiting if you have the technical resources, recognizing that these provide incremental protection against more sophisticated scrapers. Finally, document your opt-out efforts thoroughly, as this documentation becomes crucial if you need to pursue legal action against companies that ignore your directives. Remember that opt-out is not a one-time configuration but an ongoing process requiring vigilance and adaptation as the AI landscape continues to evolve.
robots.txt is a technical, voluntary standard that instructs crawlers to skip your content, while legal opt-out involves filing formal reservations with copyright organizations or including contractual clauses in your terms of service. robots.txt is easier to implement but lacks enforcement, while legal opt-out provides stronger legal protection but requires more formal procedures.
Major AI companies like OpenAI, Google, Anthropic, and Perplexity have publicly stated they respect robots.txt directives. However, robots.txt is a voluntary standard with no enforcement mechanism, so non-compliant crawlers and rogue scrapers can ignore your directives entirely.
No. Blocking AI training crawlers like GPTBot and ClaudeBot will not impact your Google or Bing search rankings because traditional search engines use different crawlers (Googlebot, Bingbot) that operate independently. Only block those if you want to disappear from search results entirely.
The EU AI Act requires that AI developers have lawful access to content and must respect copyright holder opt-out reservations. Copyright holders can file opt-out statements with their works, effectively preventing their use in AI training without explicit permission. This creates a formal legal mechanism for protecting content from unauthorized training use.
It depends on the specific mechanism. Blocking all AI crawlers will prevent your content from appearing in AI search results, but this also removes you from AI-powered search platforms entirely. Some publishers prefer selective blocking—allowing search-focused crawlers while blocking training-focused ones—to maintain visibility in AI search while protecting content from model training.
If an AI company ignores your opt-out directives, you have legal recourse through copyright infringement claims or breach of contract, depending on your jurisdiction and the specific circumstances. However, legal action is costly and slow, with uncertain outcomes. This is why monitoring and documentation of your opt-out efforts are crucial.
Review and update your robots.txt configuration at least quarterly. New AI crawlers emerge constantly, and companies frequently introduce new crawler user agents. For example, Anthropic merged their 'anthropic-ai' and 'Claude-Web' bots into 'ClaudeBot,' giving the new bot temporary unrestricted access to sites that hadn't updated their rules.
Opt-out is effective against compliant, reputable AI companies that respect robots.txt and legal frameworks. However, it's less effective against rogue crawlers and non-compliant scrapers that operate in legal gray areas. robots.txt stops approximately 40-60% of AI bots, which is why a layered approach combining multiple technical and legal measures is recommended.
Track whether your content appears in AI-generated responses across ChatGPT, Perplexity, Google AI Overviews, and other AI platforms with AmICited.
Learn how to optimize your content for AI training data inclusion. Discover best practices for making your website discoverable by ChatGPT, Gemini, Perplexity, ...
Complete guide to opting out of AI training data collection across ChatGPT, Perplexity, LinkedIn, and other platforms. Learn step-by-step instructions to protec...
Learn how to identify and capitalize on AI content opportunities by monitoring brand mentions in ChatGPT, Perplexity, and other AI platforms. Discover strategie...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.