
Google-Extended: What It Does and Should You Block It?
Learn what Google-Extended is, how it works, and whether you should block it in your robots.txt. Understand the difference between AI training control and AI Ov...
8 min read
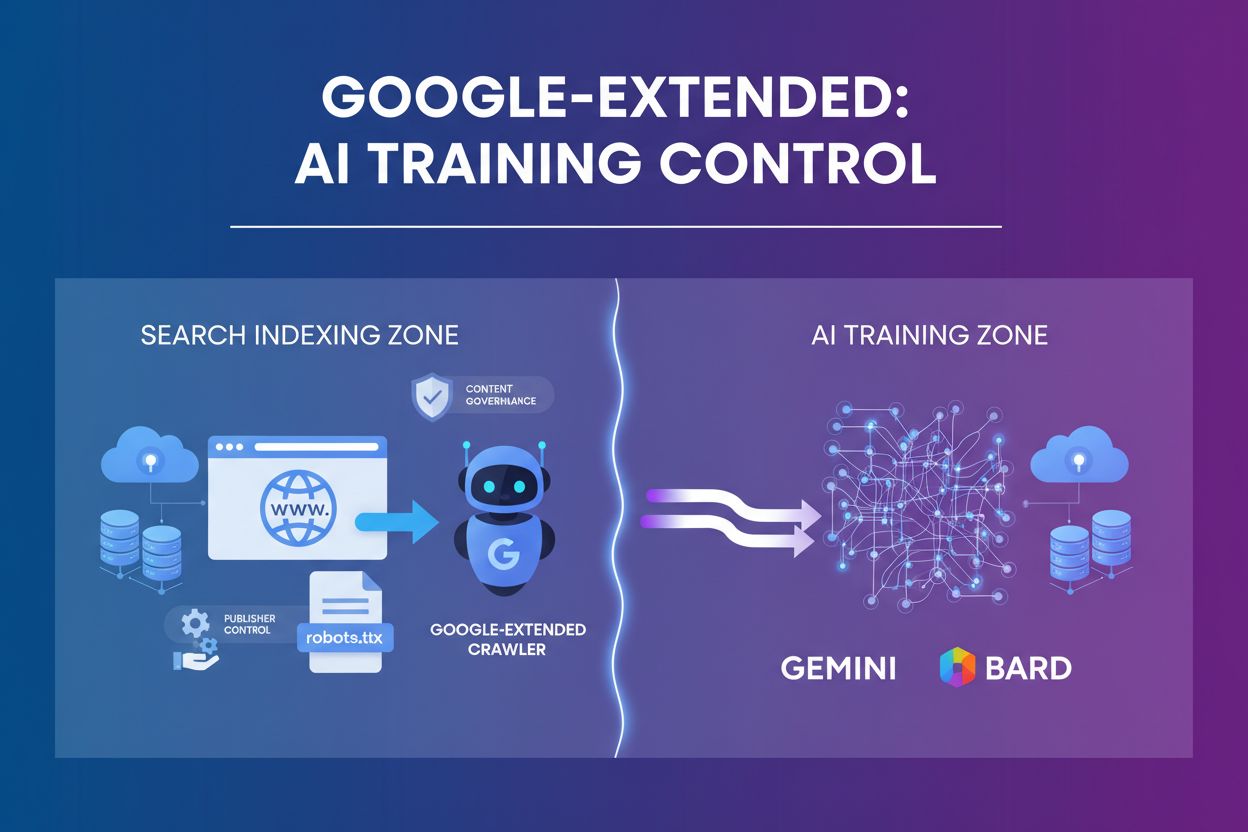
Google-Extended is a user-agent token that controls whether site content is used to improve Gemini and other Google AI products, separate from standard Googlebot crawling. It allows publishers to manage AI training access through robots.txt without affecting search visibility. Introduced in September 2023, it addresses publisher concerns about content usage in AI model development. Google-Extended does not impact SEO rankings or search inclusion.
Google-Extended is a user-agent token that controls whether site content is used to improve Gemini and other Google AI products, separate from standard Googlebot crawling. It allows publishers to manage AI training access through robots.txt without affecting search visibility. Introduced in September 2023, it addresses publisher concerns about content usage in AI model development. Google-Extended does not impact SEO rankings or search inclusion.
Google-Extended is a user-agent token that allows website publishers to control whether their content is used to train Google’s generative AI models, including Gemini, Bard, and Vertex AI. Unlike Googlebot, which crawls websites to index content for search results, Google-Extended operates independently to collect data specifically for AI model training and grounding purposes. This user-agent token is not a separate HTTP crawler—instead, it functions as a control mechanism within the robots.txt file that publishers can use to make strategic decisions about their content’s role in AI development. The introduction of Google-Extended represents a significant shift in how web publishers can manage their intellectual property in the age of artificial intelligence.
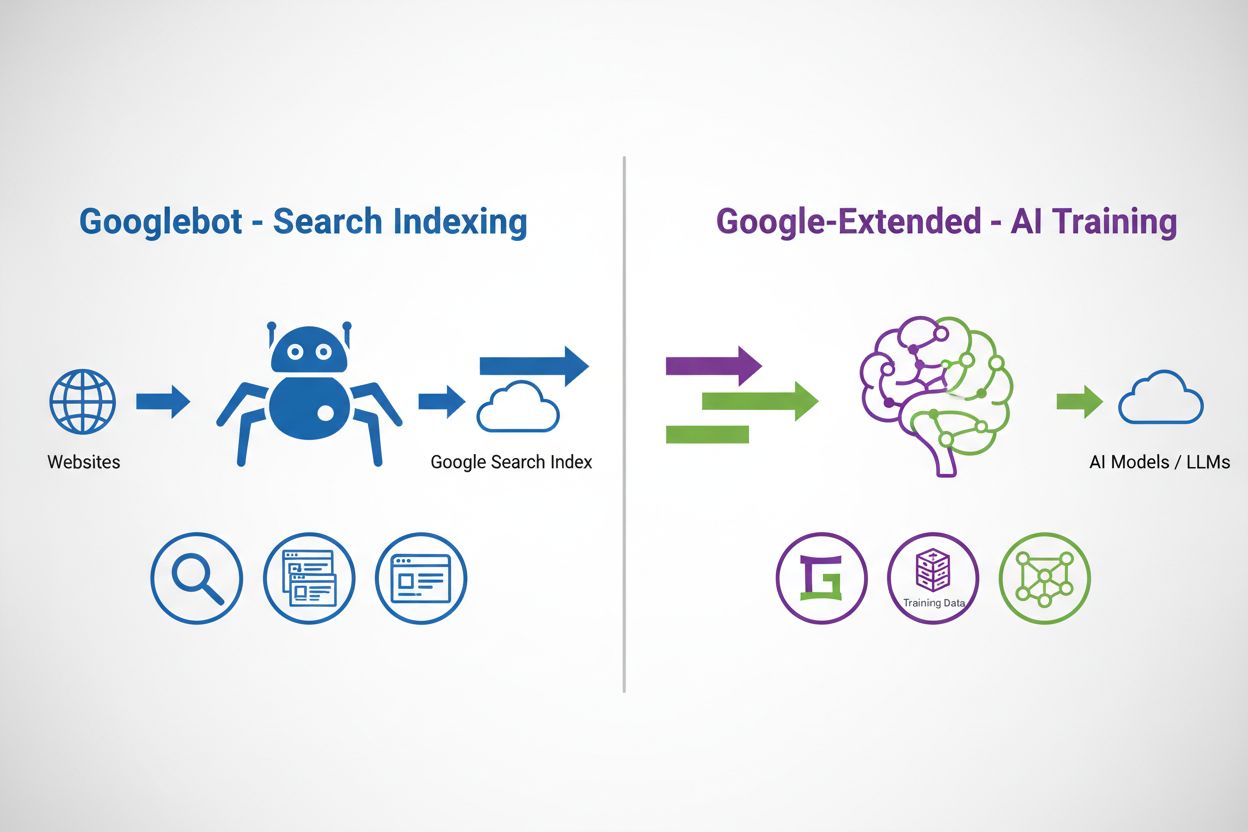
Google-Extended operates through the familiar robots.txt protocol, a plain-text file placed at the root of a website that provides instructions to web crawlers. Unlike other Google crawlers such as Googlebot or Googlebot-Image, Google-Extended doesn’t have a separate HTTP request user agent string—instead, Google uses existing user agent strings for crawling, but the robots.txt user-agent token serves as a control mechanism specifically for AI training purposes. When you add a directive for Google-Extended in your robots.txt file, you’re telling Google whether content from your site can be used for training future generations of Gemini models and for grounding (providing real-time information to improve AI answer accuracy). This separation allows publishers to maintain their search visibility while controlling AI training access independently.
| Crawler | User-Agent Token | HTTP Request Method | Affected Products |
|---|---|---|---|
| Googlebot | Googlebot | Separate user agent string | Google Search, Images, News, Discover |
| Googlebot-Image | Googlebot-Image | Separate user agent string | Google Images, Discover, Video |
| Google-Extended | Google-Extended | Uses existing Google user agents | Gemini Apps, Vertex AI, Grounding |
| Google-CloudVertexBot | Google-CloudVertexBot | Separate user agent string | Vertex AI Agents (site owner requested) |
One of the most important clarifications about Google-Extended is that it has absolutely no impact on your website’s search engine rankings or visibility in Google Search. In April 2025, Google explicitly updated its documentation to state that “Google-Extended does not impact a site’s inclusion in Google Search nor is it used as a ranking signal in Google Search.” This means you can block Google-Extended without worrying about losing organic traffic, search visibility, or any SEO benefits your site currently enjoys. The distinction is crucial: blocking Google-Extended only prevents your content from being used for AI training and grounding—it does not affect how Google’s search algorithms evaluate or rank your pages. This separation empowers publishers to make content governance decisions based on their business model and values, rather than being forced to choose between search visibility and AI training participation.
Implementing Google-Extended controls is straightforward and requires only a few lines in your robots.txt file. To block Google-Extended from accessing your content, add the following directive at the root of your website:
User-agent: Google-Extended
Disallow: /
This tells Google’s AI training crawler not to access any part of your website. If you want to allow standard search crawlers like Googlebot to continue indexing your site while blocking AI training access, your complete robots.txt file should look like this:
User-agent: Google-Extended
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
You can also implement selective blocking by specifying particular directories or file types. For example, if you only want to protect your premium content from AI training while allowing general content to be used, you could use:
User-agent: Google-Extended
Disallow: /premium/
Disallow: /subscription/
User-agent: Googlebot
Disallow:
This approach gives you granular control over which parts of your site contribute to AI model training while maintaining full search engine visibility across your entire domain.
Understanding the distinction between AI training access and search indexing is essential for making informed decisions about Google-Extended. When you allow Google-Extended, your content may be used to train Gemini models and provide grounding information in AI-generated answers—meaning your content could appear in Bard responses, Gemini Apps, and Vertex AI applications. When you block Google-Extended, your content remains fully indexed in Google Search and appears in traditional search results, but it won’t be included in AI training datasets or used to ground AI responses. Here’s how different scenarios play out:
The key insight is that these two crawlers operate independently, giving publishers unprecedented control over how their content is used across different Google products and services.
Google introduced Google-Extended in response to growing concerns from website owners, journalists, and content creators about how their work was being used to train AI models without explicit consent or compensation. Publishers raised legitimate questions about copyright ownership, content attribution, brand dilution, and competitive conflicts—particularly when AI systems trained on their content could eventually compete with or replace their original offerings. Many content creators felt their intellectual property was being harvested invisibly, with no transparency about how their work contributed to AI development or any mechanism to opt out. Google-Extended directly addresses these concerns by providing a clear, documented method for publishers to control whether their content participates in AI training. This represents a significant acknowledgment from Google that content creators deserve agency over their intellectual property and a voice in how their work shapes the future of AI technology.
Your decision to allow or block Google-Extended should align with your business model, content strategy, and long-term vision. Content creators and educators who want to maximize visibility and establish thought leadership should generally allow Google-Extended, as appearing in Gemini responses and AI-generated content can significantly boost brand awareness and authority. News publishers and subscription-based platforms should carefully consider blocking Google-Extended to protect their proprietary content and maintain competitive advantages—especially if their business model depends on exclusive access to original reporting. Enterprise software companies and consultancies might take a hybrid approach, allowing Google-Extended for general educational content while blocking it for proprietary methodologies and case studies. The strategic question isn’t whether AI training is good or bad, but rather: Does your content benefit more from broad AI visibility, or does it need protection as a competitive asset? Consider your audience, revenue model, and whether appearing in AI-generated answers drives value or dilutes your brand.
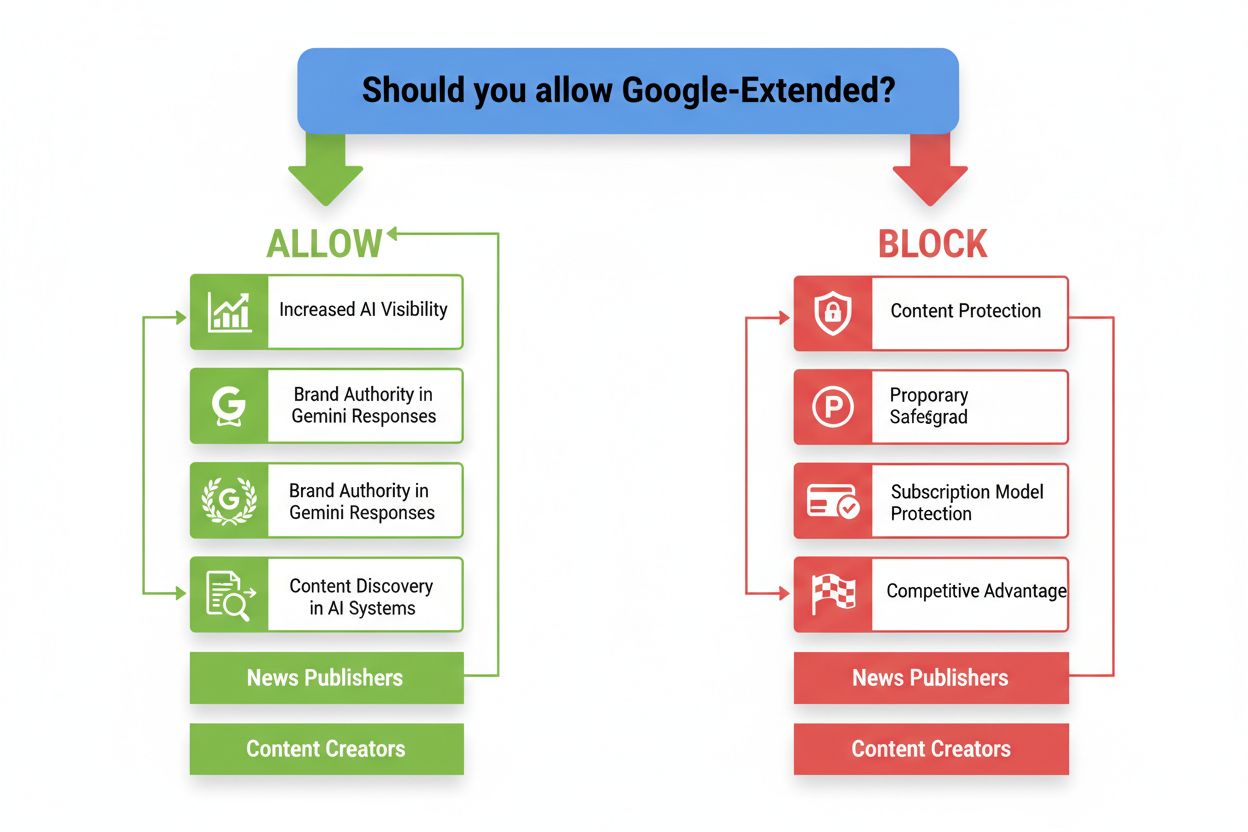
Currently, there is no robust public tool to monitor exactly how your content is being used by Google’s AI models, which represents a significant gap in transparency. While Google-Extended provides control over whether content is accessed, publishers lack detailed visibility into how their content influences AI outputs or appears in Gemini responses. This limitation has prompted calls for more sophisticated monitoring solutions—tools like AmICited.com are emerging to help publishers track how their brand and content are referenced and cited across AI systems, providing the transparency that the current ecosystem lacks. Looking forward, expect industry standards to evolve around AI attribution, content licensing, and publisher compensation—similar to how traditional media licensing works. For now, a hybrid approach is recommended: block Google-Extended for your most sensitive or proprietary content, allow it for content meant for broad distribution, and use third-party monitoring tools to track how your brand appears in AI-generated content. As AI integration into search and information discovery deepens, the ability to control and monitor your content’s participation in these systems will become increasingly valuable.
Googlebot crawls websites to index content for Google Search results, while Google-Extended is a user-agent token that controls whether content is used for AI training in Gemini and Vertex AI. Googlebot affects search visibility, while Google-Extended does not. Both can be controlled independently through robots.txt, allowing publishers to manage search indexing and AI training separately.
No. Blocking Google-Extended has absolutely no impact on your search engine rankings or visibility in Google Search. Google explicitly confirmed in April 2025 that Google-Extended is not used as a ranking signal and does not affect search inclusion. You can safely block it without worrying about losing organic traffic.
Add these lines to your robots.txt file: User-agent: Google-Extended followed by Disallow: /. This prevents Google's AI training crawler from accessing your content. You can also block specific directories or file types. Remember that this only affects AI training access, not search engine indexing.
Yes, absolutely. Blocking Google-Extended only prevents your content from being used for AI training. Your content will continue to be indexed by Googlebot and appear normally in Google Search results. The two crawlers operate independently, so controlling one doesn't affect the other.
If you allow Google-Extended, your content may be used to train Gemini models and provide grounding information in AI-generated answers. This means your content could appear in Bard responses, Gemini Apps, and Vertex AI applications. This can increase brand visibility but may also mean your content is used in ways you don't directly control.
Yes. You can use selective blocking in robots.txt to protect specific directories or file types. For example, you can disallow Google-Extended from accessing /premium/ or /subscription/ directories while allowing it to access other parts of your site. This gives you granular control over which content participates in AI training.
Some AI companies have introduced their own user-agent tokens or crawlers, but Google-Extended is Google's specific mechanism for controlling AI training access. Other AI platforms like OpenAI, Anthropic, and Perplexity may have different approaches. Currently, there's no universal standard, so you may need to check each AI company's documentation for their specific requirements.
No, Google-Extended is optional. You don't have to add any directives for it in your robots.txt file. By default, if you don't specify anything, Google-Extended will crawl your site for AI training purposes. You only need to add directives if you want to block it or implement selective blocking for specific content.
Track your brand citations across AI platforms like Gemini, Perplexity, and Google AI Overviews with AmICited. Get insights into how AI systems reference your content and measure your AI visibility.
Learn what Google-Extended is, how it works, and whether you should block it in your robots.txt. Understand the difference between AI training control and AI Ov...
Learn about Applebot-Extended, Apple's web crawler for AI training. Understand how it evaluates content for Apple Intelligence, how to block it, and your privac...
Learn what Gemini Extensions are, how they work, and how they enable AI-powered productivity by connecting Gemini to Gmail, Drive, Maps, and other services. Com...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.