Quali crawler AI dovrei autorizzare? Guida completa per il 2025
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
12 min di lettura

Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito per la visibilità nella ricerca AI.
I crawler AI sono programmi automatizzati progettati per navigare sistematicamente in Internet e raccogliere dati dai siti web, specificamente per addestrare e migliorare modelli di intelligenza artificiale. A differenza dei tradizionali crawler dei motori di ricerca come Googlebot, che indicizzano i contenuti per i risultati di ricerca, i crawler AI raccolgono dati web grezzi da fornire a grandi modelli linguistici (LLM) come ChatGPT, Claude e altri sistemi AI. Questi bot operano continuamente su milioni di siti web, scaricando pagine, analizzando contenuti ed estraendo informazioni che aiutano le piattaforme AI a comprendere schemi linguistici, informazioni fattuali e stili di scrittura diversi. I principali attori di questo settore includono GPTBot di OpenAI, ClaudeBot di Anthropic, Meta-ExternalAgent di Meta, Amazonbot di Amazon e PerplexityBot di Perplexity.ai, ognuno dei quali serve le esigenze di addestramento e operative delle rispettive piattaforme AI. Comprendere come funzionano questi crawler è diventato essenziale per i proprietari di siti web e i creatori di contenuti, poiché la visibilità AI ora incide direttamente su come il tuo brand appare nei risultati di ricerca e nelle raccomandazioni alimentate dall’AI.
Il panorama del crawling web ha subito una trasformazione drastica nell’ultimo anno, con i crawler AI che hanno registrato una crescita esplosiva mentre i crawler di ricerca tradizionali mantengono andamenti stabili. Tra maggio 2024 e maggio 2025, il traffico totale dei crawler è cresciuto del 18%, ma la distribuzione si è spostata significativamente—GPTBot è salito del 305% nelle richieste grezze, mentre altri crawler come ClaudeBot sono diminuiti del 46% e Bytespider è crollato dell'85%. Questa riorganizzazione riflette la crescente competizione tra le aziende AI per assicurarsi dati di addestramento e migliorare i propri modelli. Ecco una panoramica dettagliata dei principali crawler e della loro posizione attuale sul mercato:
| Nome Crawler | Azienda | Richieste Mensili | Crescita YoY | Scopo Principale |
|---|---|---|---|---|
| Googlebot | 4,5 miliardi | 96% | Indicizzazione di ricerca & AI Overviews | |
| GPTBot | OpenAI | 569 milioni | 305% | Addestramento modello ChatGPT & ricerca |
| Claude | Anthropic | 370 milioni | -46% | Addestramento modello Claude & ricerca |
| Bingbot | Microsoft | ~450 milioni | 2% | Indicizzazione di ricerca |
| PerplexityBot | Perplexity.ai | 24,4 milioni | 157.490% | Indicizzazione ricerca AI |
| Meta-ExternalAgent | Meta | ~380 milioni | New entry | Addestramento Meta AI |
| Amazonbot | Amazon | ~210 milioni | -35% | Ricerca & applicazioni AI |
I dati mostrano che, mentre Googlebot mantiene la leadership con 4,5 miliardi di richieste mensili, i crawler AI rappresentano collettivamente circa il 28% del volume di Googlebot, rendendoli una forza significativa nel traffico web. La crescita esplosiva di PerplexityBot (incremento del 157.490%) dimostra quanto rapidamente nuove piattaforme AI stiano scalando le proprie operazioni di crawling, mentre il declino di alcuni crawler AI consolidati suggerisce una concentrazione del mercato attorno alle piattaforme AI di maggior successo.
GPTBot è il crawler web di OpenAI, specificamente progettato per raccogliere dati utili all’addestramento e al miglioramento di ChatGPT e altri modelli OpenAI. Lanciato come attore relativamente marginale con solo il 5% di quota di mercato a maggio 2024, GPTBot è diventato il crawler AI dominante, raggiungendo il 30% di tutto il traffico dei crawler AI a maggio 2025—un notevole incremento del 305% nelle richieste grezze. Questa crescita esplosiva riflette la strategia aggressiva di OpenAI per garantire a ChatGPT l’accesso a contenuti web freschi e diversificati sia per l’addestramento dei modelli sia per le capacità di ricerca in tempo reale tramite ChatGPT Search. GPTBot opera con uno schema di crawling distinto, dando priorità ai contenuti HTML (57,70% dei fetch) ma scaricando anche file JavaScript e immagini, sebbene non esegua JavaScript per generare contenuti dinamici. Il comportamento del crawler mostra che spesso incontra errori 404 (34,82% delle richieste), suggerendo che potrebbe seguire link obsoleti o tentare di accedere a risorse non più esistenti. Per i proprietari di siti web, il dominio di GPTBot significa che garantire l’accessibilità dei propri contenuti a questo crawler è diventato fondamentale per la visibilità nelle funzioni di ricerca di ChatGPT e per la possibile inclusione nei futuri cicli di addestramento dei modelli.
ClaudeBot, sviluppato da Anthropic, è il principale crawler per l’addestramento e l’aggiornamento dell’assistente AI Claude, oltre a supportare le capacità di ricerca e grounding di Claude. Un tempo secondo crawler AI per quota di mercato (27% a maggio 2024), ClaudeBot ha subito un calo significativo al 21% a maggio 2025, con una diminuzione delle richieste grezze del 46% anno su anno. Questo calo non indica necessariamente un problema nella strategia di Anthropic, ma riflette piuttosto il più ampio spostamento di mercato verso il dominio di OpenAI e l’emergere di nuovi concorrenti come Meta-ExternalAgent. ClaudeBot mostra comportamenti simili a GPTBot, privilegiando i contenuti HTML ma dedicando una percentuale maggiore di richieste alle immagini (35,17% dei fetch), suggerendo che Anthropic potrebbe addestrare Claude a comprendere meglio i contenuti visivi oltre al testo. Come altri crawler AI, ClaudeBot non esegue JavaScript, quindi vede solo l’HTML grezzo delle pagine senza alcun contenuto caricato dinamicamente. Per i creatori di contenuti, mantenere la visibilità con ClaudeBot resta importante per assicurare che Claude possa accedere e citare i tuoi contenuti, soprattutto mentre Anthropic continua a sviluppare le funzionalità di ricerca e ragionamento di Claude.
Oltre a GPTBot e ClaudeBot, diversi altri importanti crawler AI raccolgono attivamente dati web per le rispettive piattaforme:
Meta-ExternalAgent (Meta): Il crawler di Meta ha fatto un ingresso dirompente nelle classifiche principali, raggiungendo il 19% di quota di mercato a maggio 2025 come nuovo attore. Questo bot raccoglie dati per le iniziative AI di Meta, incluso il possibile addestramento per Meta AI e l’integrazione con le funzionalità AI di Instagram e Facebook. L’ascesa rapida di Meta suggerisce che l’azienda sta facendo una forte spinta verso la ricerca e le raccomandazioni alimentate dall’AI.
PerplexityBot (Perplexity.ai): Pur avendo solo lo 0,2% di quota di mercato, PerplexityBot ha registrato il tasso di crescita più esplosivo con 157.490% anno su anno. Questo riflette la rapida espansione di Perplexity come motore di risposta AI che si basa sulla ricerca web in tempo reale per fondare le proprie risposte. Per i siti web, le visite di PerplexityBot rappresentano opportunità dirette di essere citati nelle risposte generate da Perplexity AI.
Amazonbot (Amazon): Il crawler di Amazon è passato dal 21% all'11% di quota di mercato, con una diminuzione delle richieste grezze del 35% anno su anno. Amazonbot raccoglie dati per la funzionalità di ricerca di Amazon e per le applicazioni AI, ma il calo suggerisce che Amazon potrebbe aver modificato la propria strategia AI o consolidato le operazioni di crawling.
Applebot (Apple): Il crawler di Apple ha registrato un calo del 26% nelle richieste, scendendo dall'1,9% all'1,2% di quota di mercato. Applebot serve principalmente Siri e Spotlight Search, ma può anche supportare le nuove iniziative AI di Apple. A differenza della maggior parte degli altri crawler AI, Applebot può eseguire il rendering di JavaScript, offrendo capacità simili a Googlebot.
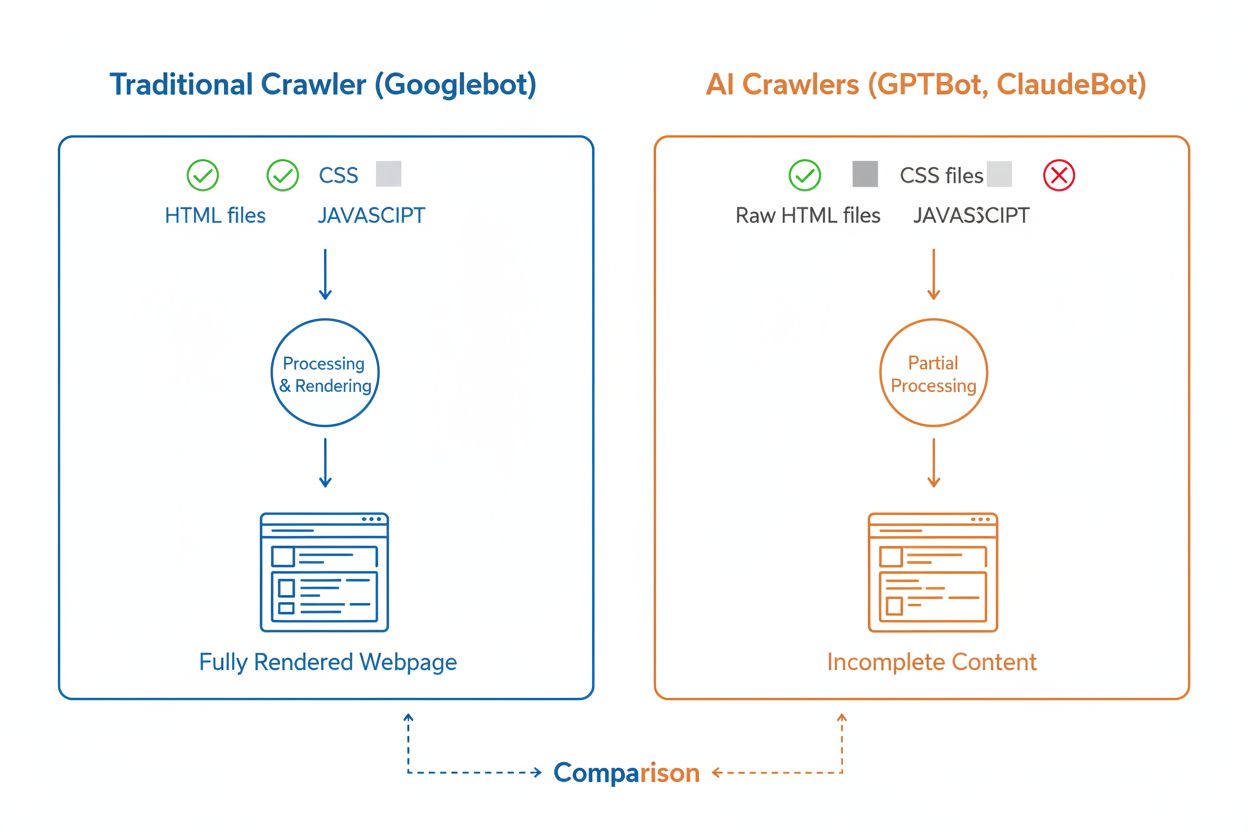
Sebbene i crawler AI e i crawler di ricerca tradizionali come Googlebot navighino entrambi sistematicamente il web, le loro capacità tecniche e i loro comportamenti differiscono notevolmente, con un impatto diretto su come i tuoi contenuti vengono scoperti e compresi. La differenza più importante è il rendering di JavaScript: Googlebot può eseguire JavaScript dopo aver scaricato una pagina, permettendogli di vedere i contenuti caricati dinamicamente, mentre la maggior parte dei crawler AI (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) legge solo l’HTML grezzo e ignora qualsiasi contenuto dipendente da JavaScript. Questo significa che se il tuo sito si basa sul rendering lato client per mostrare informazioni chiave, i crawler AI vedranno una versione incompleta delle tue pagine. Inoltre, i crawler AI mostrano schemi di crawling meno prevedibili rispetto all’approccio sistematico di Googlebot—dedicano il 34,82% delle richieste a pagine 404 e il 14,36% a seguire redirect, rispetto all'8,22% di Googlebot sulle 404 e all'1,49% sui redirect. Anche la frequenza di crawling è diversa: mentre Googlebot visita le pagine in base a un sofisticato sistema di crawl budget, i crawler AI sembrano eseguire il crawling più frequentemente ma in modo meno sistematico, con alcune ricerche che mostrano visite dei crawler AI fino a 100 volte più frequenti rispetto a Google in certi casi. Queste differenze fanno sì che le strategie di ottimizzazione SEO tradizionali potrebbero non coprire pienamente la crawlabilità AI, richiedendo un approccio specifico focalizzato sul rendering lato server e su strutture URL pulite.
Una delle sfide tecniche più significative per i crawler AI è la loro incapacità di eseguire il rendering di JavaScript, una limitazione dovuta ai costi computazionali dell’esecuzione di JavaScript su scala massiva per addestrare grandi modelli linguistici. Quando un crawler scarica la tua pagina web, riceve la risposta HTML iniziale, ma qualsiasi contenuto caricato o modificato tramite JavaScript—come dettagli di prodotto, informazioni sui prezzi, recensioni degli utenti o elementi di navigazione dinamici—resta invisibile ai crawler AI. Questo crea un problema critico per i siti web moderni che si basano pesantemente su framework di rendering lato client come React, Vue o Angular senza rendering lato server (SSR) o generazione di siti statici (SSG). Ad esempio, un sito e-commerce che carica le informazioni sui prodotti tramite JavaScript apparirà ai crawler AI come una pagina vuota senza dettagli sui prodotti, rendendo impossibile per i sistemi AI comprendere o citare quel contenuto. La soluzione è assicurarsi che tutti i contenuti critici siano serviti nella risposta HTML iniziale tramite rendering lato server, che genera l’HTML completo sul server prima di inviarlo al browser. Questo approccio garantisce che sia i visitatori umani sia i crawler AI ricevano la stessa esperienza ricca di contenuti. I siti che utilizzano framework moderni come Next.js con SSR, generatori di siti statici come Hugo o Gatsby, o piattaforme tradizionali come WordPress sono naturalmente più adatti ai crawler AI, mentre quelli che si basano solo sul rendering lato client affrontano sfide significative di visibilità nella ricerca AI.
I crawler AI mostrano schemi di frequenza di crawling distinti e molto diversi dal comportamento di Googlebot, con importanti implicazioni su quanto velocemente i tuoi contenuti vengono recepiti dai sistemi AI. Le ricerche dimostrano che i crawler AI come ChatGPT e Perplexity spesso visitano le pagine più frequentemente di Google nel breve periodo dopo la pubblicazione—talvolta visitando le pagine 8 volte più spesso di Googlebot nei primi giorni. Questo rapido crawling iniziale suggerisce che le piattaforme AI danno priorità alla scoperta e all’indicizzazione dei nuovi contenuti, probabilmente per assicurare ai loro modelli e funzioni di ricerca l’accesso alle informazioni più recenti. Tuttavia, a questa aggressività iniziale segue uno schema in cui i crawler AI possono non tornare se i contenuti non soddisfano determinati standard qualitativi, rendendo la prima impressione cruciale. A differenza di Googlebot, che dispone di un sofisticato sistema di crawl budget e tornerà regolarmente sulle pagine in base alla frequenza di aggiornamento e all’importanza, i crawler AI sembrano decidere rapidamente se valga la pena rivisitare un contenuto. Questo significa che se un crawler AI visita la tua pagina e trova contenuti poveri, errori tecnici o segnali di scarsa esperienza utente, potrebbe passare molto tempo prima che ritorni—se mai ritorna. L’implicazione per i creatori di contenuti è chiara: non puoi contare su una seconda possibilità di ottimizzare i contenuti per i crawler AI come invece succede con i motori di ricerca tradizionali, il che rende essenziale assicurare la qualità prima della pubblicazione.
I proprietari di siti web possono utilizzare il file robots.txt per comunicare le proprie preferenze riguardo l’accesso dei crawler AI, anche se l’efficacia e l’applicazione di queste regole varia notevolmente tra i diversi crawler. Secondo dati recenti, circa il 14% dei primi 10.000 siti web ha implementato regole specifiche di allow o disallow rivolte ai bot AI nei propri file robots.txt. GPTBot è il crawler bloccato più frequentemente, con 312 domini (250 completamente, 62 parzialmente) che lo vietano esplicitamente, anche se è anche quello più esplicitamente autorizzato con 61 domini che gli concedono accesso. Altri crawler comunemente bloccati includono CCBot (Common Crawl) e Google-Extended (il token di addestramento AI di Google). Il problema con robots.txt è che il rispetto delle regole è volontario—i crawler le seguono solo se gli operatori scelgono di implementare questa funzionalità, e alcuni crawler più recenti o meno trasparenti potrebbero non rispettare affatto le direttive robots.txt. Inoltre, token robots.txt come “Google-Extended” non corrispondono direttamente agli user-agent nelle richieste HTTP; invece, segnalano lo scopo del crawling, il che significa che non puoi sempre verificare il rispetto delle regole tramite i log del server. Per un’applicazione più affidabile, i proprietari di siti optano sempre più spesso per regole firewall e Web Application Firewall (WAF) in grado di bloccare attivamente determinati user-agent dei crawler, offrendo un controllo più efficace rispetto al solo robots.txt. Questo passaggio verso meccanismi di blocco attivi riflette le crescenti preoccupazioni sui diritti dei contenuti e il desiderio di maggiori garanzie sul controllo degli accessi dei crawler AI.
Tracciare l’attività dei crawler AI sul tuo sito web è essenziale per comprendere la tua visibilità nella ricerca AI, ma presenta sfide uniche rispetto al monitoraggio dei crawler dei motori di ricerca tradizionali. Gli strumenti di analisi tradizionali come Google Analytics si basano sul tracciamento JavaScript, che i crawler AI non eseguono, il che significa che questi strumenti non offrono visibilità sulle visite dei bot AI. Allo stesso modo, il tracciamento tramite pixel non funziona perché la maggior parte dei crawler AI processa solo testo e ignora le immagini. L’unico modo affidabile per tracciare l’attività dei crawler AI è attraverso il monitoraggio lato server—analizzando le intestazioni delle richieste HTTP e i log del server per identificare gli user-agent dei crawler prima che la pagina venga inviata. Questo richiede un’analisi manuale dei log o strumenti specializzati progettati appositamente per identificare e tracciare il traffico dei crawler AI. Il monitoraggio in tempo reale è particolarmente importante perché i crawler AI operano secondo orari imprevedibili e potrebbero non tornare sulle pagine se incontrano problemi, il che significa che un audit settimanale o mensile potrebbe non rilevare problemi importanti. Se un crawler AI visita il tuo sito e trova un errore tecnico o contenuti di bassa qualità, potresti non avere un’altra occasione per fare una buona impressione. Implementare soluzioni di monitoraggio 24/7 che ti avvisano immediatamente quando i crawler AI incontrano problemi—come errori 404, tempi di caricamento lenti o markup schema mancanti—ti permette di risolvere i problemi prima che abbiano un impatto sulla tua visibilità nella ricerca AI. Questo approccio in tempo reale rappresenta un cambiamento fondamentale rispetto alle pratiche di monitoraggio SEO tradizionali, riflettendo la velocità e l’imprevedibilità del comportamento dei crawler AI.
Ottimizzare il tuo sito web per i crawler AI richiede un approccio distinto rispetto alla SEO tradizionale, focalizzato su fattori tecnici che influenzano direttamente come i sistemi AI possono accedere e comprendere i tuoi contenuti. La prima priorità è il rendering lato server: assicurati che tutti i contenuti critici—titoli, testo principale, metadati, dati strutturati—siano inclusi nella risposta HTML iniziale e non caricati dinamicamente tramite JavaScript. Questo vale per la homepage, le landing page principali e qualsiasi contenuto che desideri venga citato o referenziato dai sistemi AI. In secondo luogo, implementa il markup dei dati strutturati (Schema.org) sulle pagine di maggiore impatto, inclusi schema articolo per i post del blog, schema prodotto per gli articoli e-commerce e schema autore per stabilire autorevolezza ed expertise. I crawler AI utilizzano i dati strutturati per comprendere rapidamente la gerarchia e il contesto dei contenuti, semplificando l’analisi e la citazione delle informazioni. Terzo, mantieni alti standard qualitativi dei contenuti su tutte le pagine, poiché i crawler AI sembrano valutare rapidamente se un contenuto valga la pena di essere indicizzato e citato. Questo significa assicurare che i tuoi contenuti siano originali, ben ricercati, accurati e di reale valore per i lettori. In quarto luogo, monitora e ottimizza i Core Web Vitals e le prestazioni generali della pagina, poiché pagine lente indicano una scarsa esperienza utente e possono scoraggiare i crawler AI dal ritornare. Infine, mantieni una struttura degli URL pulita e coerente, aggiorna regolarmente la sitemap XML e configura correttamente il file robots.txt per guidare i crawler verso i contenuti più importanti. Queste ottimizzazioni tecniche creano una base che rende i tuoi contenuti scopribili, comprensibili e citabili dai sistemi AI.
Il panorama dei crawler AI continuerà ad evolversi rapidamente man mano che la competizione tra aziende AI si intensifica e la tecnologia matura. Una tendenza evidente è la concentrazione delle quote di mercato attorno alle piattaforme di maggior successo—GPTBot di OpenAI è emerso come la forza dominante, mentre nuovi attori come Meta-ExternalAgent stanno scalando rapidamente, suggerendo che il mercato si stabilizzerà probabilmente attorno a pochi grandi player. Con la maturazione dei crawler AI, ci si possono aspettare miglioramenti nelle capacità tecniche, in particolare nell’esecuzione di JavaScript e in schemi di crawling più efficienti che riducono le richieste inutili verso pagine 404 e contenuti obsoleti. Il settore si sta inoltre muovendo verso protocolli di comunicazione più standardizzati, come la nuova specifica llms.txt, che consente ai siti web di comunicare esplicitamente la propria struttura dei contenuti e le preferenze di crawling ai sistemi AI. Inoltre, i meccanismi di controllo per la gestione dell’accesso dei crawler AI stanno diventando più sofisticati, con piattaforme come Cloudflare che ora offrono il blocco automatico dei bot di addestramento AI per impostazione predefinita, dando ai proprietari dei siti un controllo più granulare sui propri contenuti. Per i creatori di contenuti e i proprietari di siti web, restare aggiornati su questi cambiamenti significa monitorare costantemente l’attività dei crawler AI, mantenere l’infrastruttura tecnica ottimizzata per l’accessibilità AI e adattare la propria strategia di contenuti considerando che i sistemi AI ora rappresentano una parte significativa del traffico del sito e un canale critico per la visibilità del brand. Il futuro appartiene a chi comprende e si ottimizza per questo nuovo ecosistema di crawler.
I crawler AI sono programmi automatizzati che raccolgono dati web specificamente per addestrare e migliorare modelli di intelligenza artificiale come ChatGPT e Claude. A differenza dei tradizionali crawler dei motori di ricerca come Googlebot, che indicizzano i contenuti per i risultati di ricerca, i crawler AI raccolgono dati web grezzi da inserire nei modelli linguistici di grandi dimensioni. Entrambi i tipi di crawler navigano sistematicamente in Internet, ma hanno scopi diversi e capacità tecniche differenti.
I crawler AI accedono al tuo sito web per raccogliere dati da utilizzare nell'addestramento dei modelli di intelligenza artificiale, migliorare le funzionalità di ricerca e supportare le risposte AI con informazioni aggiornate. Quando sistemi come ChatGPT o Perplexity rispondono alle domande degli utenti, spesso devono recuperare i tuoi contenuti in tempo reale per fornire informazioni precise e citate. Consentire l'accesso ai crawler AI aumenta le possibilità che il tuo brand venga menzionato e citato in risposte generate dall'AI.
Sì, puoi utilizzare il file robots.txt per impedire a specifici crawler AI di accedere, specificando i loro nomi user-agent. Tuttavia, il rispetto delle regole robots.txt è volontario e non tutti i crawler le seguono. Per un controllo più rigoroso, puoi utilizzare regole del firewall e Web Application Firewall (WAF) per bloccare attivamente determinati user-agent dei crawler. Questo ti offre un controllo più affidabile su quali crawler AI possono accedere ai tuoi contenuti.
No, la maggior parte dei crawler AI (GPTBot, ClaudeBot, Meta-ExternalAgent) non esegue JavaScript. Leggono solo l'HTML grezzo delle tue pagine, quindi qualsiasi contenuto caricato dinamicamente tramite JavaScript sarà invisibile per loro. Ecco perché il rendering lato server è fondamentale per la crawlabilità AI. Se il tuo sito si basa sul rendering lato client, i crawler AI vedranno una versione incompleta delle tue pagine.
I crawler AI visitano i siti web più frequentemente rispetto ai motori di ricerca tradizionali nel breve periodo dopo la pubblicazione dei contenuti. Le ricerche mostrano che possono visitare le pagine da 8 a 100 volte più spesso di Google nei primi giorni. Tuttavia, se il contenuto non soddisfa gli standard qualitativi, potrebbero non tornare. Questo rende fondamentale la prima impressione: potresti non avere una seconda possibilità di ottimizzare i contenuti per i crawler AI.
Le ottimizzazioni chiave sono: (1) Utilizza il rendering lato server per assicurarti che i contenuti critici siano presenti nell'HTML iniziale, (2) Aggiungi markup di dati strutturati (Schema) per aiutare l'AI a comprendere i tuoi contenuti, (3) Mantieni alta la qualità e l'aggiornamento dei contenuti, (4) Monitora i Core Web Vitals per una buona esperienza utente e (5) Mantieni la struttura degli URL pulita e una sitemap aggiornata. Queste ottimizzazioni tecniche creano una base che rende i tuoi contenuti scopribili e citabili dai sistemi AI.
GPTBot di OpenAI è attualmente il crawler AI dominante, rappresentando il 30% di tutto il traffico dei crawler AI e crescendo del 305% anno su anno. Tuttavia, dovresti ottimizzare per tutti i principali crawler, inclusi ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) e altri. Le diverse piattaforme AI hanno basi utenti diverse, quindi la visibilità su più crawler massimizza la presenza del tuo brand nella ricerca AI.
Gli strumenti di analisi tradizionali come Google Analytics non rilevano l'attività dei crawler AI perché si basano sul tracciamento JavaScript. Invece, è necessario un monitoraggio lato server che analizzi le intestazioni delle richieste HTTP e i log del server per identificare gli user-agent dei crawler. Strumenti specializzati progettati per il tracciamento dei crawler AI offrono visibilità in tempo reale su quali pagine vengono scansionate, con quale frequenza e se i crawler incontrano problemi tecnici.
Tieni traccia di come i crawler AI come GPTBot e ClaudeBot accedono e citano i tuoi contenuti. Ottieni approfondimenti in tempo reale sulla tua visibilità nella ricerca AI con AmICited.
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
Scopri come identificare e monitorare i crawler AI come GPTBot, PerplexityBot e ClaudeBot nei log del tuo server. Scopri stringhe user-agent, metodi di verifica...
Scopri come consentire ai bot AI come GPTBot, PerplexityBot e ClaudeBot di scansionare il tuo sito. Configura robots.txt, imposta llms.txt e ottimizza per la vi...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.