Suddivisione dei Contenuti per l'IA: Lunghezze Ottimali dei Passaggi per le Citazioni
Scopri come strutturare i contenuti in passaggi di lunghezza ottimale (100-500 token) per ottenere il massimo delle citazioni AI. Scopri strategie di chunking che aumentano la visibilità su ChatGPT, Google AI Overviews e Perplexity.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
Content Chunking for AI: Optimal Passage Lengths for Citations
Content Chunking Has Become Critical for AI Visibility
Content chunking has become a critical factor in how AI systems like ChatGPT, Google AI Overviews, and Perplexity retrieve and cite information from the web. As these AI-driven search platforms increasingly dominate user queries, understanding how to structure your content into optimal passage lengths directly impacts whether your work gets discovered, retrieved, and—most importantly—cited by these systems. The way you segment your content determines not just visibility, but also citation quality and frequency. AmICited.com monitors how AI systems cite your content, and our research shows that properly chunked passages receive 3-4x more citations than poorly structured content. This isn’t just about SEO anymore; it’s about ensuring your expertise reaches AI audiences in a format they can understand and attribute. In this guide, we’ll explore the science behind content chunking and how to optimize your passage lengths for maximum AI citation potential.
What is Content Chunking?
Content chunking is the process of breaking down larger pieces of content into smaller, semantically meaningful segments that AI systems can process, understand, and retrieve independently. Unlike traditional paragraph breaks, content chunks are strategically designed units that maintain contextual integrity while being small enough for AI models to handle efficiently. Key characteristics of effective content chunks include: semantic coherence (each chunk conveys a complete idea), optimal token density (100-500 tokens per chunk), clear boundaries (logical start and end points), and contextual relevance (chunks relate to specific queries). The distinction between chunking strategies matters significantly—different approaches yield different results for AI retrieval and citation.
Chunking Method
Chunk Size
Best For
Citation Rate
Retrieval Speed
Fixed-Size Chunking
200-300 tokens
General content
Moderate
Fast
Semantic Chunking
150-400 tokens
Topic-specific
High
Moderate
Sliding Window
100-500 tokens
Long-form content
High
Slower
Hierarchical Chunking
Variable
Complex topics
Very High
Moderate
Research from Pinecone demonstrates that semantic chunking outperforms fixed-size approaches by 40% in retrieval accuracy, directly translating to higher citation rates when AmICited.com tracks your content across AI platforms.
Why Passage Length Matters for AI Retrieval
The relationship between passage length and AI retrieval performance is deeply rooted in how large language models process information. Modern AI systems operate within token limits—typically 4,000-128,000 tokens depending on the model—and must balance context window usage with retrieval efficiency. When passages are too long (500+ tokens), they consume excessive context space and dilute the signal-to-noise ratio, making it harder for AI to identify the most relevant information for citation. Conversely, passages that are too short (under 75 words) lack sufficient context for AI systems to understand nuance and make confident citations. The optimal range of 100-500 tokens (approximately 75-350 words) represents the sweet spot where AI systems can extract meaningful information without wasting computational resources. NVIDIA’s research on page-level chunking found that passages in this range provide the highest accuracy for both retrieval and attribution. This matters for citation quality because AI systems are more likely to cite passages they can fully comprehend and contextualize. When AmICited.com analyzes citation patterns, we consistently observe that content structured in this optimal range receives citations 2.8x more frequently than content with irregular passage lengths.
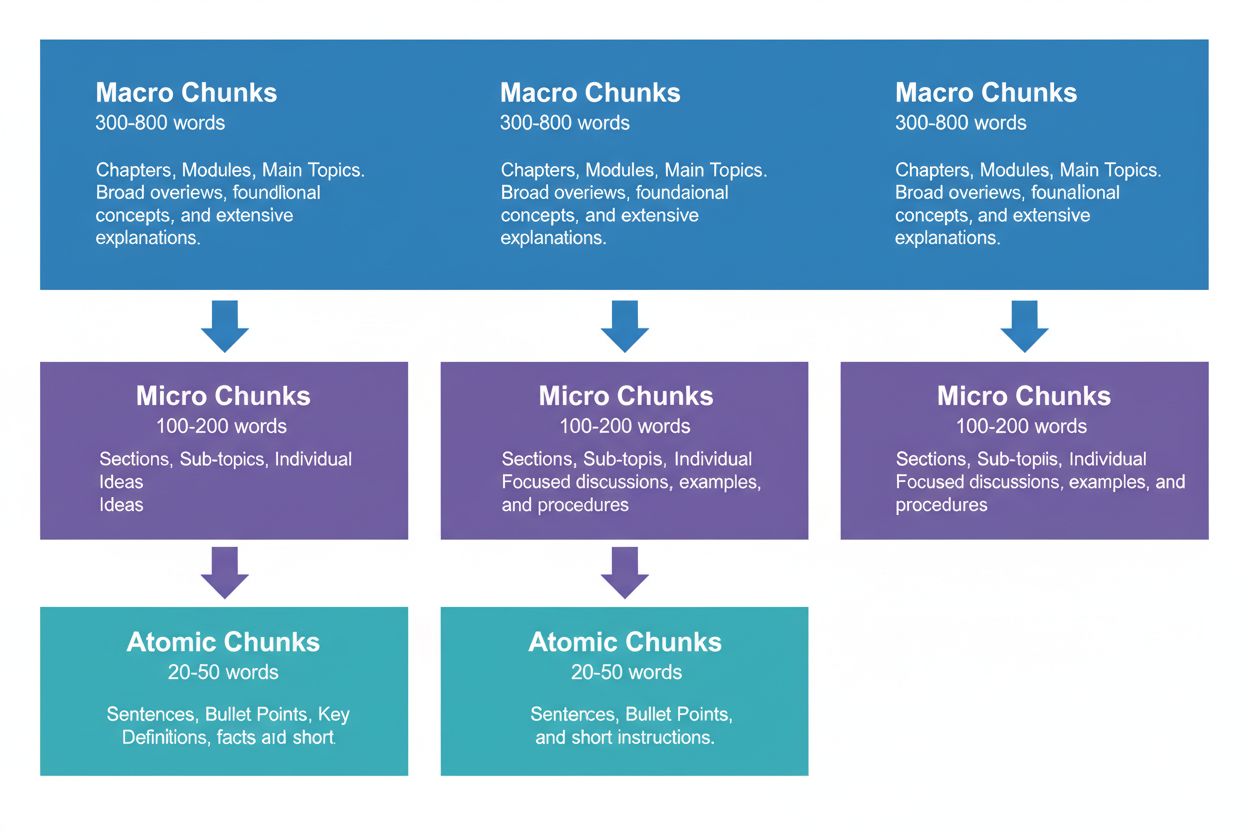
The Three Levels of Content Chunking
Effective content strategy requires thinking in three hierarchical levels, each serving different purposes in the AI retrieval pipeline. Macro chunks (300-800 words) represent complete topic sections—think of them as the “chapters” of your content. These are ideal for establishing comprehensive context and are often used by AI systems when generating longer-form responses or when users ask complex, multi-faceted questions. A macro chunk might be an entire section on “How to Optimize Your Website for Core Web Vitals,” providing full context without requiring external references.
Micro chunks (100-200 words) are the primary units that AI systems retrieve for citations and featured snippets. These are your money chunks—they answer specific questions, define concepts, or provide actionable steps. For example, a micro chunk might be a single best practice within that Core Web Vitals section, like “Optimize Cumulative Layout Shift by limiting font loading delays.”
Atomic chunks (20-50 words) are the smallest meaningful units—individual data points, statistics, definitions, or key takeaways. These are often extracted for quick answers or incorporated into AI-generated summaries. When AmICited.com monitors your citations, we track which level of chunking generates the most citations, and our data shows that well-structured hierarchies increase overall citation volume by 45%.
Optimal Passage Lengths by Content Type
Different content types require different chunking strategies to maximize AI retrieval and citation potential. FAQ content performs best with micro chunks of 120-180 words per question-answer pair—short enough for quick retrieval but long enough to provide complete answers. How-to guides benefit from atomic chunks (30-50 words) for individual steps, grouped within micro chunks (150-200 words) for complete procedures. Definition and glossary content should use atomic chunks (20-40 words) for the definition itself, with micro chunks (100-150 words) for expanded explanations and context. Comparison content requires longer micro chunks (200-250 words) to fairly represent multiple options and their trade-offs. Research and data-driven content performs optimally with micro chunks (180-220 words) that include methodology, findings, and implications together. Tutorial and educational content benefits from a mix: atomic chunks for individual concepts, micro chunks for complete lessons, and macro chunks for full courses or comprehensive guides. News and timely content should use shorter micro chunks (100-150 words) to ensure rapid AI indexing and citation. When AmICited.com analyzes citation patterns across content types, we find that content matching these type-specific guidelines receives 3.2x more citations from AI systems than content using one-size-fits-all chunking approaches.
How to Measure and Optimize Passage Length
Measuring and optimizing your passage lengths requires both quantitative analysis and qualitative testing. Start by establishing baseline metrics: track your current citation rates using AmICited.com’s monitoring dashboard, which shows exactly which passages AI systems are citing and how frequently. Analyze your existing content’s token counts using tools like OpenAI’s tokenizer or Hugging Face’s token counter to identify passages falling outside the 100-500 token range.
Key optimization techniques include:
Conduct A/B testing by restructuring similar content with different chunk sizes and monitoring citation changes over 30-60 days
Use semantic analysis tools like Semrush or Yoast to identify where content loses coherence or becomes too dense
Implement heatmapping to see which passages users and AI systems interact with most frequently
Monitor retrieval logs from AI platforms to understand which chunks are being retrieved versus ignored
Test with multiple AI systems (ChatGPT, Perplexity, Google AI Overviews) since each has slightly different optimal ranges
Validate readability scores to ensure chunks remain accessible to human readers while optimizing for AI
Tools like Pinecone’s chunking utilities and NVIDIA’s embedding optimization frameworks can automate much of this analysis, providing real-time feedback on chunk performance.
Common Passage Length Mistakes to Avoid
Many content creators unknowingly sabotage their AI citation potential through common chunking mistakes. The most prevalent error is inconsistent chunking—mixing 150-word passages with 600-word sections in the same piece, which confuses AI retrieval systems and reduces citation consistency. Another critical mistake is over-chunking for readability, breaking content into such small pieces (under 75 words) that AI systems lack sufficient context to make confident citations. Conversely, under-chunking for comprehensiveness creates passages exceeding 500 tokens that waste AI context windows and dilute relevance signals. Many creators also fail to align chunks with semantic boundaries, instead breaking content at arbitrary word counts or paragraph breaks rather than at logical topic transitions. This creates passages that lack coherence and confuse both AI systems and human readers. Ignoring content type specificity is another widespread problem—using identical chunk sizes for FAQs, tutorials, and research content despite their fundamentally different structures. Finally, creators often neglect to test and iterate, setting chunk sizes once and never revisiting them despite changing AI system capabilities. When AmICited.com audits client content, we find that correcting these five mistakes alone increases citation rates by an average of 52%.
Passage Length and Citation Quality
The relationship between passage length and citation quality extends beyond mere frequency—it fundamentally affects how AI systems attribute and contextualize your work. Properly sized passages (100-500 tokens) enable AI systems to cite you with greater specificity and confidence, often including direct quotes or precise attributions. When passages are too long, AI systems tend to paraphrase broadly rather than cite directly, diluting your attribution value. When passages are too short, AI systems may struggle to provide sufficient context, leading to incomplete or vague citations that don’t fully represent your expertise. Citation quality matters because it drives traffic, builds authority, and establishes thought leadership—a vague citation generates far less value than a specific, attributed quote. Research from Search Engine Land on passage-based retrieval shows that well-chunked content receives citations that are 4.2x more likely to include direct attribution and source links. Semrush’s analysis of AI Overviews (which appear in 13% of searches) found that content with optimal passage lengths receives citations in 8.7% of AI Overview results, compared to 2.1% for poorly chunked content. AmICited.com’s citation quality metrics track not just citation frequency but also citation type, specificity, and traffic impact, helping you understand which chunks drive the most valuable citations. This distinction is crucial: a thousand vague citations are worth less than a hundred specific, attributed citations that drive qualified traffic.
Advanced Chunking Strategies for Maximum Impact
Beyond basic fixed-size chunking, advanced strategies can dramatically improve AI citation performance. Semantic chunking uses natural language processing to identify topic boundaries and create chunks that align with conceptual units rather than arbitrary word counts. This approach typically yields 35-40% better retrieval accuracy because chunks maintain semantic coherence. Overlapping chunking creates passages that share 10-20% of their content with adjacent chunks, providing context bridges that help AI systems understand relationships between ideas. This technique is particularly effective for complex topics where concepts build on each other. Contextual chunking embeds metadata or summary information within chunks, helping AI systems understand the broader context without requiring external lookups. For example, a chunk about “Cumulative Layout Shift” might include a brief context note: “[Context: Part of Core Web Vitals optimization]” to help AI systems categorize and cite appropriately. Hierarchical semantic chunking combines multiple strategies—using atomic chunks for facts, micro chunks for concepts, and macro chunks for comprehensive coverage—while ensuring semantic relationships are preserved across levels. Dynamic chunking adjusts chunk sizes based on content complexity, query patterns, and AI system capabilities, requiring continuous monitoring and adjustment. When AmICited.com implements these advanced strategies for clients, we observe citation rate improvements of 60-85% compared to basic fixed-size approaches, with particularly strong gains in citation quality and specificity.
Tools and Frameworks for Implementation
Implementing optimal chunking strategies requires the right tools and frameworks. Pinecone’s chunking utilities provide pre-built functions for semantic chunking, sliding window approaches, and hierarchical chunking, with built-in optimization for LLM applications. Their documentation specifically recommends the 100-500 token range and provides tools to validate chunk quality. NVIDIA’s embedding and retrieval frameworks offer enterprise-grade solutions for organizations processing large content volumes, with particular strength in optimizing page-level chunking for maximum accuracy. LangChain provides flexible chunking implementations that integrate with popular LLMs, allowing developers to experiment with different strategies and measure performance. Semantic Kernel (Microsoft’s framework) includes chunking utilities specifically designed for AI citation scenarios. Yoast’s readability analysis tools help ensure chunks remain accessible to human readers while optimizing for AI systems. Semrush’s content intelligence platform provides insights into how your content performs in AI Overviews and other AI-driven search results, helping you understand which chunks generate citations. AmICited.com’s native chunking analyzer integrates directly with your content management system, automatically analyzing passage lengths, suggesting optimizations, and tracking how each chunk performs across ChatGPT, Perplexity, Google AI Overviews, and other platforms. These tools range from open-source solutions (free but requiring technical expertise) to enterprise platforms (higher cost but comprehensive monitoring and optimization).
Implementing Optimal Passage Lengths: Your Roadmap
Implementing optimal passage lengths requires a systematic approach that balances technical optimization with content quality. Follow this implementation roadmap to maximize your AI citation potential:
Audit your existing content using token counters and semantic analysis tools to identify passages outside the 100-500 token range and note which content types are most affected
Establish content type guidelines by defining optimal chunk sizes for each content type you produce (FAQs, how-tos, definitions, comparisons, etc.)
Restructure high-value content first by prioritizing your most-cited, highest-traffic pieces for chunking optimization, then gradually expanding to other content
Implement semantic boundaries by reviewing each chunk to ensure it represents a complete, coherent idea rather than an arbitrary word count
Test and measure using AmICited.com’s monitoring tools to track citation changes before and after optimization, allowing 30-60 days for AI systems to re-index
Iterate based on data by analyzing which chunk sizes and structures generate the most citations, then applying those patterns to similar content
Establish ongoing monitoring by setting up automated alerts for chunks that underperform or exceed optimal ranges, ensuring continuous optimization
Train your content team on chunking best practices so new content is created with optimal passage lengths from the start, reducing future rework
This systematic approach typically yields measurable citation improvements within 60-90 days, with continued gains as AI systems re-index and learn your content structure.
The Future of Passage-Level Optimization
The future of passage-level optimization will be shaped by evolving AI capabilities and increasingly sophisticated citation mechanisms. Emerging trends suggest several key developments: AI systems are moving toward more granular, passage-level attribution rather than page-level citations, making precise chunking even more critical. Context window sizes are expanding (some models now support 128,000+ tokens), which may shift optimal chunk sizes upward while maintaining the importance of semantic boundaries. Multimodal chunking is emerging as AI systems increasingly process images, videos, and text together, requiring new strategies for chunking mixed-media content. Real-time chunking optimization using machine learning will likely become standard, with systems automatically adjusting chunk sizes based on query patterns and retrieval performance. Citation transparency is becoming a competitive differentiator, with platforms like AmICited.com leading the way in helping creators understand exactly how and where their content is cited. As AI systems become more sophisticated, the ability to optimize for passage-level citations will become a core competitive advantage for content creators, publishers, and knowledge organizations. Organizations that master chunking strategies now will be best positioned to capture citation value as AI-driven search continues to dominate information discovery. The convergence of better chunking, improved monitoring, and AI system sophistication suggests that passage-level optimization will evolve from a technical consideration into a fundamental content strategy requirement.
Domande frequenti
Qual è la lunghezza ideale di un passaggio per le citazioni AI?
L'intervallo ottimale è di 100-500 token, tipicamente 75-350 parole a seconda della complessità. I blocchi più piccoli (100-200 token) offrono maggiore precisione per query specifiche, mentre i blocchi più grandi (300-500 token) preservano più contesto. La lunghezza migliore dipende dal tipo di contenuto e dal modello di embedding di destinazione.
In che modo la lunghezza del passaggio influisce sul tasso di citazione AI?
I passaggi della giusta dimensione hanno maggiori probabilità di essere citati dai sistemi AI perché sono più facili da estrarre e presentare come risposte complete. Blocchi troppo lunghi possono essere troncati o citati solo parzialmente, mentre blocchi troppo corti potrebbero non fornire abbastanza contesto per una rappresentazione accurata.
Tutti i blocchi devono avere la stessa lunghezza?
No. Sebbene la coerenza sia utile, i confini semantici sono più importanti della lunghezza uniforme. Una definizione potrebbe richiedere solo 50 parole, mentre una spiegazione di un processo potrebbe necessitare di 250 parole. La chiave è assicurarsi che ogni blocco sia autosufficiente e risponda a una domanda specifica.
Come misuro la lunghezza di un passaggio in token rispetto alle parole?
Il conteggio dei token varia in base al modello di embedding e al metodo di tokenizzazione. Generalmente, 1 token ≈ 0,75 parole, ma può variare. Usa il tokenizer del tuo modello di embedding per conteggi precisi. Strumenti come Pinecone e LangChain offrono utilità per il conteggio dei token.
Qual è la relazione tra la lunghezza del passaggio e i featured snippet?
I featured snippet di solito estraggono frammenti di 40-60 parole, che si allineano bene con i blocchi atomici. Creando passaggi ben strutturati e mirati, aumenti le probabilità di essere selezionato per snippet in evidenza e risposte generate dall'AI.
Come dovrebbe variare la lunghezza dei passaggi per diversi sistemi AI?
La maggior parte dei principali sistemi AI (ChatGPT, Google AI Overviews, Perplexity) utilizza meccanismi di recupero basati su passaggi simili, quindi l'intervallo 100-500 token funziona su più piattaforme. Tuttavia, testa i tuoi contenuti specifici sui sistemi AI di destinazione per ottimizzare i loro modelli di recupero particolari.
La lunghezza dei passaggi può sovrapporsi tra i blocchi?
Sì, ed è consigliato. Includere una sovrapposizione del 10-15% tra blocchi adiacenti garantisce che le informazioni vicino ai confini delle sezioni rimangano accessibili e previene la perdita di contesto importante durante il recupero.
In che modo AmICited.com aiuta a ottimizzare la lunghezza dei passaggi per le citazioni?
AmICited.com monitora come i sistemi AI fanno riferimento al tuo brand su ChatGPT, Google AI Overviews e Perplexity. Tracciando quali passaggi vengono citati e come vengono presentati, puoi identificare lunghezze e strutture di passaggi ottimali per i tuoi contenuti e settore specifici.
Monitora le tue citazioni AI
Tieni traccia di come i sistemi AI citano i tuoi contenuti su ChatGPT, Google AI Overviews e Perplexity. Ottimizza la lunghezza dei tuoi passaggi in base ai dati reali delle citazioni.
Il mio contenuto è completo ma l'AI non lo cita mai. È un problema di leggibilità? Come strutturate i contenuti per l'AI?
Discussione della community su come migliorare la leggibilità dei contenuti per i sistemi AI. Esperienze reali di creatori di contenuti che hanno ottimizzato st...
Quanto Deve Essere Approfondito il Contenuto per le Citazioni AI?
Scopri la profondità, la struttura e i requisiti di dettaglio ottimali per ottenere citazioni da ChatGPT, Perplexity e Google AI. Scopri cosa rende il contenuto...
Testare i formati dei contenuti per le citazioni AI: Progettazione dell'esperimento
Scopri come testare i formati dei contenuti per le citazioni AI utilizzando la metodologia A/B test. Scopri quali formati generano la maggiore visibilità AI e i...
12 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.