
Come il RAG Cambia le Citazioni dell'IA
Scopri come il Retrieval-Augmented Generation trasforma le citazioni dell'IA, permettendo un'attribuzione accurata delle fonti e risposte fondate su ChatGPT, Pe...
8 min di lettura

Scopri come il grounding degli LLM e la ricerca sul web consentono ai sistemi AI di accedere a informazioni in tempo reale, ridurre le allucinazioni e fornire citazioni accurate. Impara RAG, strategie di implementazione e best practice per le aziende.
I large language model sono addestrati su enormi quantità di dati testuali, ma questo processo di addestramento presenta una limitazione critica: cattura solo le informazioni disponibili fino a un determinato momento, noto come knowledge cutoff date. Ad esempio, se un LLM è stato addestrato con dati fino a dicembre 2023, non ha alcuna conoscenza di eventi, scoperte o sviluppi avvenuti dopo tale data. Quando gli utenti pongono domande su eventi attuali, lanci di nuovi prodotti o notizie dell’ultima ora, il modello non può accedere a queste informazioni nei suoi dati di addestramento. Invece di ammettere incertezza, gli LLM spesso generano risposte plausibili ma errate—un fenomeno noto come allucinazione. Questa tendenza diventa particolarmente problematica in applicazioni dove l’accuratezza è fondamentale, come l’assistenza clienti, i consigli finanziari o le informazioni mediche, dove informazioni obsolete o inventate possono avere conseguenze gravi.
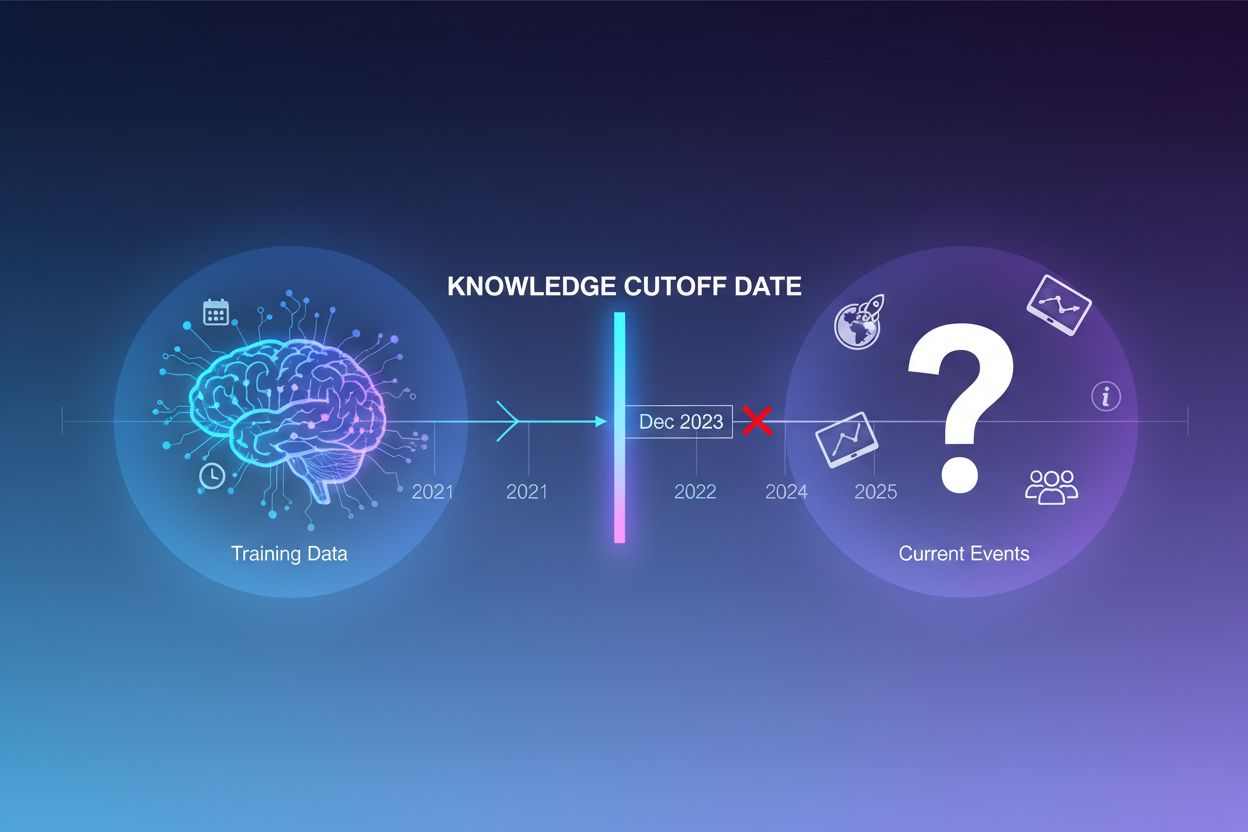
Grounding è il processo di arricchimento della conoscenza pre-addestrata di un LLM con informazioni esterne e contestuali al momento dell’inferenza. Invece di affidarsi solo ai pattern appresi durante l’addestramento, il grounding collega il modello a fonti dati reali—che si tratti di pagine web, documenti interni, database o API. Questo concetto deriva dalla psicologia cognitiva, in particolare dalla teoria della cognizione situata, secondo cui la conoscenza viene applicata in modo più efficace quando è ancorata al contesto in cui sarà utilizzata. In termini pratici, il grounding trasforma il problema da “genera una risposta dalla memoria” a “sintetizza una risposta dalle informazioni fornite”. Una definizione rigorosa, secondo le ricerche recenti, richiede che l’LLM utilizzi tutte le conoscenze essenziali dal contesto fornito e rispetti i suoi limiti senza allucinare informazioni aggiuntive.
| Aspetto | Risposta Non Grounded | Risposta Grounded |
|---|---|---|
| Fonte delle informazioni | Solo conoscenza pre-addestrata | Conoscenza pre-addestrata + dati esterni |
| Accuratezza per eventi recenti | Bassa (limiti knowledge cutoff) | Alta (accesso a informazioni attuali) |
| Rischio di allucinazione | Alto (il modello indovina) | Basso (vincolato dal contesto fornito) |
| Capacità di citazione | Limitata o impossibile | Completa tracciabilità alle fonti |
| Scalabilità | Fissa (dimensione modello) | Flessibile (aggiunta di nuove fonti dati) |
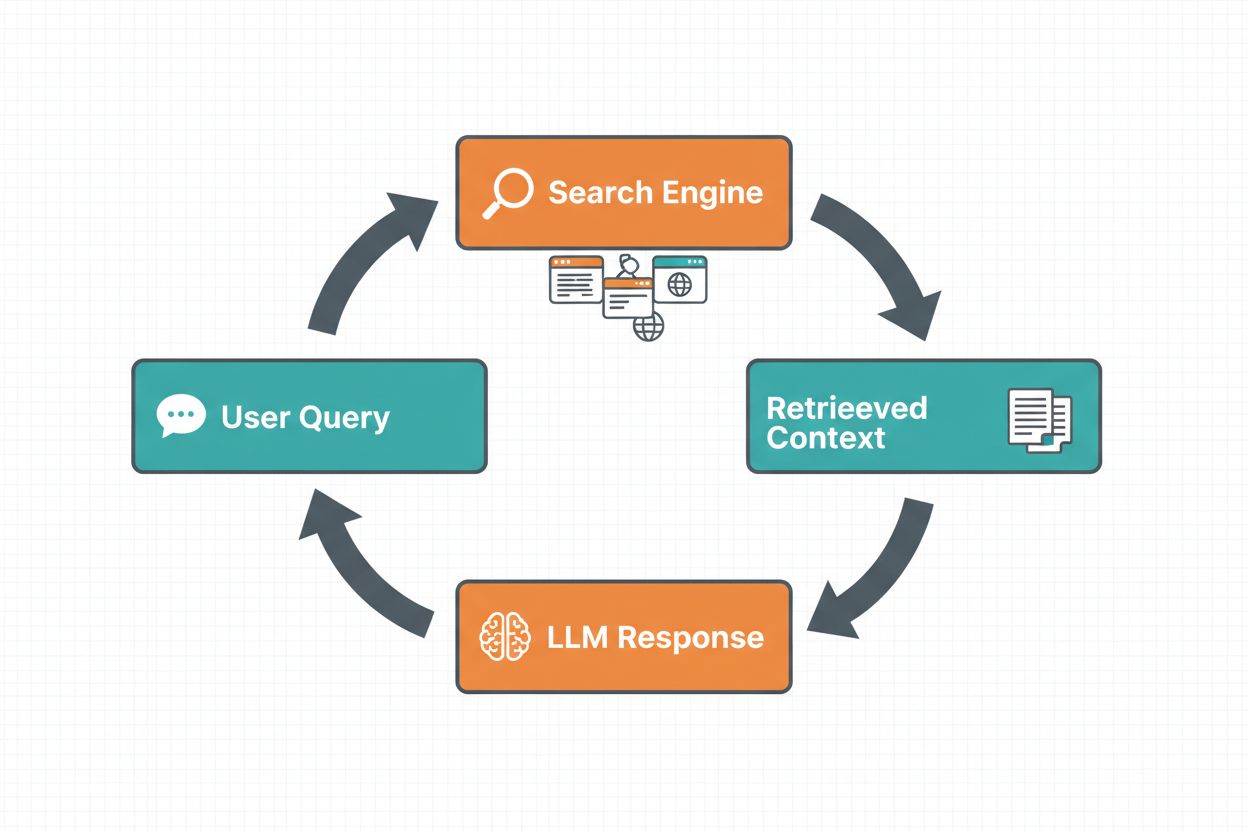
Il grounding tramite ricerca web consente agli LLM di accedere a informazioni in tempo reale cercando automaticamente sul web e incorporando i risultati nel processo di generazione delle risposte. Il flusso di lavoro segue una sequenza strutturata: prima, il sistema analizza il prompt dell’utente per determinare se una ricerca web migliorerebbe la risposta; poi, genera una o più query ottimizzate per recuperare informazioni pertinenti; quindi, esegue queste query su un motore di ricerca (come Google Search o DuckDuckGo); successivamente, elabora i risultati della ricerca ed estrae i contenuti rilevanti; infine, fornisce questo contesto all’LLM come parte del prompt, permettendo al modello di generare una risposta grounded. Il sistema restituisce anche metadati di grounding—informazioni strutturate su quali query sono state eseguite, quali fonti sono state recuperate e come le varie parti della risposta sono supportate da tali fonti. Questi metadati sono essenziali per costruire fiducia e permettere agli utenti di verificare le affermazioni.
Workflow del Grounding tramite Ricerca Web:
La Retrieval Augmented Generation (RAG) si è affermata come la tecnica di grounding dominante, combinando decenni di ricerca sull’information retrieval con le capacità moderne degli LLM. RAG funziona recuperando prima documenti o passaggi rilevanti da una fonte di conoscenza esterna (tipicamente indicizzata in un database vettoriale), quindi fornendo questi elementi recuperati come contesto all’LLM. Il processo di retrieval di solito avviene in due fasi: un retriever utilizza algoritmi efficienti (come BM25 o semantic search con embedding) per identificare i documenti candidati, e un ranker usa modelli neurali più sofisticati per riordinare questi candidati in base alla rilevanza. Il contesto recuperato viene poi incorporato nel prompt, consentendo all’LLM di sintetizzare risposte ancorate a informazioni autorevoli. RAG offre vantaggi significativi rispetto al fine-tuning: è più conveniente (non serve riaddestrare il modello), più scalabile (basta aggiungere nuovi documenti alla knowledge base) e più facile da mantenere (le informazioni si aggiornano senza riaddestramento). Ad esempio, un prompt RAG potrebbe essere:
Usa i seguenti documenti per rispondere alla domanda.
[Domanda]
Qual è la capitale del Canada?
[Documento 1]
Ottawa è la capitale del Canada, situata in Ontario...
[Documento 2]
Il Canada è un paese del Nord America con dieci province...
Uno dei vantaggi più convincenti del grounding tramite ricerca web è la possibilità di accedere e incorporare informazioni in tempo reale nelle risposte degli LLM. Questo è particolarmente prezioso per applicazioni che richiedono dati attuali—analisi di notizie, ricerche di mercato, informazioni su eventi o disponibilità di prodotti. Oltre al semplice accesso a dati aggiornati, il grounding fornisce citazioni e attribuzione delle fonti, fondamentale per costruire fiducia e permettere la verifica. Quando un LLM genera una risposta grounded, restituisce metadati strutturati che collegano affermazioni specifiche ai documenti di origine, consentendo citazioni inline come “[1] source.com” direttamente nel testo della risposta. Questa funzionalità è in linea con la mission di piattaforme come AmICited.com, che monitorano come i sistemi AI citano le fonti su diverse piattaforme. La possibilità di tracciare quali fonti sono state consultate e come sono state attribuite le informazioni sta diventando sempre più importante per il monitoraggio del brand, l’attribuzione dei contenuti e la responsabilità nell’uso dell’AI.
Le allucinazioni si verificano perché gli LLM sono progettati fondamentalmente per prevedere il token successivo sulla base dei token precedenti e dei pattern appresi, senza comprendere i limiti della propria conoscenza. Quando si trovano di fronte a domande fuori dal loro set di dati di addestramento, continuano a generare testo plausibile anziché ammettere incertezza. Il grounding affronta questo problema cambiando radicalmente il compito del modello: invece di generare dalla memoria, ora il modello sintetizza dalle informazioni fornite. Da un punto di vista tecnico, quando nel prompt è incluso contesto esterno rilevante, la distribuzione di probabilità dei token si orienta verso risposte ancorate a quel contesto, riducendo la probabilità di allucinazioni. La ricerca dimostra che il grounding può ridurre il tasso di allucinazioni del 30-50% a seconda del compito e dell’implementazione. Ad esempio, alla domanda “Chi ha vinto Euro 2024?” senza grounding, un modello vecchio potrebbe dare una risposta errata; con il grounding tramite risultati di ricerca web, identifica correttamente la Spagna come vincitrice con dettagli specifici della partita. Questo meccanismo funziona perché i meccanismi di attenzione del modello possono ora focalizzarsi sul contesto fornito invece di affidarsi a pattern potenzialmente incompleti o contraddittori dei dati di addestramento.
Implementare il grounding tramite ricerca web richiede l’integrazione di diversi componenti: un’API di ricerca (come Google Search, DuckDuckGo via Serp API o Bing Search), una logica per determinare quando è necessario il grounding e il prompt engineering per incorporare efficacemente i risultati della ricerca. Un’implementazione pratica parte di solito dalla valutazione se la query dell’utente necessita di informazioni aggiornate—questo può essere fatto chiedendo direttamente all’LLM se il prompt richiede dati più recenti del suo knowledge cutoff. Se serve grounding, il sistema esegue una ricerca web, processa i risultati per estrarre gli snippet rilevanti e costruisce un prompt che include sia la domanda originale sia il contesto della ricerca. I costi sono un fattore importante: ogni ricerca web comporta costi API, quindi implementare il grounding dinamico (ricercare solo quando necessario) può ridurre notevolmente le spese. Ad esempio, una query come “Perché il cielo è blu?” probabilmente non necessita di una ricerca web, mentre “Chi è l’attuale presidente?” sì. Le implementazioni avanzate usano modelli più piccoli e veloci per decidere se attivare il grounding, riducendo latenza e costi mentre riservano i modelli più grandi alla generazione finale della risposta.
Pur essendo potente, il grounding introduce diverse sfide che devono essere gestite con attenzione. La rilevanza dei dati è fondamentale—se le informazioni recuperate non rispondono effettivamente alla domanda dell’utente, il grounding non aiuterà e potrebbe addirittura introdurre contesto irrilevante. La quantità di dati presenta un paradosso: sebbene più informazioni sembrino utili, la ricerca mostra che le performance degli LLM spesso peggiorano con input eccessivi, un fenomeno chiamato “lost in the middle” bias, in cui i modelli faticano a trovare e utilizzare informazioni collocate al centro di contesti lunghi. L’efficienza dei token diventa una preoccupazione poiché ogni pezzo di contesto recuperato consuma token, aumentando latenza e costi. Vale il principio del “less is more”: recuperare solo i top-k risultati più rilevanti (di solito 3-5), lavorare su porzioni di testo più piccole invece che su documenti interi ed eventualmente estrarre frasi chiave da passaggi più lunghi.
| Sfida | Impatto | Soluzione |
|---|---|---|
| Rilevanza Dati | Contesto irrilevante confonde il modello | Usa ricerca semantica + ranker; testa la qualità del retrieval |
| Lost in Middle Bias | Il modello ignora info importanti al centro | Minimizza la dimensione dell’input; colloca info critiche all’inizio/fine |
| Efficienza Token | Latenza e costi elevati | Recupera meno risultati; usa porzioni più piccole |
| Informazioni Obsolete | Contesto datato nella knowledge base | Implementa politiche di refresh; versionamento |
| Latenza | Risposte lente per ricerca + inferenza | Usa operazioni asincrone; cache delle query frequenti |
Implementare sistemi di grounding in produzione richiede particolare attenzione a governance, sicurezza e aspetti operativi. L’assicurazione della qualità dei dati è fondamentale—le informazioni su cui esegui il grounding devono essere accurate, aggiornate e rilevanti per i tuoi casi d’uso. Il controllo degli accessi diventa critico quando si esegue grounding su documenti proprietari o sensibili; devi assicurarti che l’LLM acceda solo alle informazioni appropriate per ciascun utente in base ai suoi permessi. La gestione degli aggiornamenti e del drift richiede politiche su quanto spesso aggiornare le knowledge base e su come gestire informazioni discordanti tra le fonti. L’audit logging è essenziale per conformità e debug—dovresti tracciare quali documenti sono stati recuperati, come sono stati classificati e quale contesto è stato fornito al modello. Altre considerazioni includono:
Il campo del grounding negli LLM sta evolvendo rapidamente oltre il semplice recupero testuale. Sta emergendo il grounding multimodale, in cui i sistemi possono ancorare le risposte su immagini, video e dati strutturati oltre che su testo—particolarmente importante per settori come l’analisi legale di documenti, l’imaging medico e la documentazione tecnica. Si stanno aggiungendo ragionamento e automazione sopra RAG, permettendo agli agenti non solo di recuperare informazioni ma di sintetizzarle da più fonti, trarre conclusioni logiche e spiegare i loro ragionamenti. Si stanno integrando guardrail con il grounding per garantire che, anche con accesso a informazioni esterne, i modelli rispettino vincoli di sicurezza e policy aziendali. Un altro fronte sono gli aggiornamenti in-place del modello: invece di affidarsi solo al retrieval esterno, i ricercatori stanno esplorando modi per aggiornare direttamente i pesi del modello con nuove informazioni, riducendo potenzialmente la necessità di knowledge base esterne estese. Questi progressi suggeriscono che i sistemi di grounding del futuro saranno più intelligenti, efficienti e capaci di gestire compiti complessi di ragionamento multi-step, mantenendo al contempo accuratezza fattuale e tracciabilità.
Il grounding arricchisce un LLM con informazioni esterne al momento dell'inferenza senza modificare il modello stesso, mentre il fine-tuning riaddestra il modello su nuovi dati. Il grounding è più conveniente, veloce da implementare e facile da aggiornare con nuove informazioni. Il fine-tuning è preferibile quando è necessario modificare fondamentalmente il comportamento del modello o quando ci sono schemi specifici di dominio da apprendere.
Il grounding riduce le allucinazioni fornendo all'LLM un contesto fattuale da cui attingere invece di affidarsi solo ai suoi dati di addestramento. Quando nel prompt sono incluse informazioni esterne rilevanti, la distribuzione di probabilità dei token del modello si orienta verso risposte ancorate a quel contesto, rendendo meno probabili informazioni inventate. La ricerca mostra che il grounding può ridurre il tasso di allucinazioni del 30-50%.
La Retrieval Augmented Generation (RAG) è una tecnica di grounding che recupera documenti rilevanti da una fonte di conoscenza esterna e li fornisce come contesto all'LLM. RAG è importante perché è scalabile, conveniente e consente di aggiornare le informazioni senza riaddestrare il modello. È diventato lo standard di settore per la creazione di applicazioni AI ancorate a dati reali.
Implementa il grounding tramite ricerca web quando la tua applicazione ha bisogno di accedere a informazioni aggiornate (notizie, eventi, dati recenti), quando accuratezza e citazioni sono fondamentali, o quando il knowledge cutoff dell'LLM rappresenta un limite. Usa il grounding dinamico per cercare solo quando necessario, riducendo costi e latenza per query che non richiedono informazioni aggiornate.
Le sfide principali includono garantire la rilevanza dei dati (le informazioni recuperate devono realmente rispondere alla domanda), gestire la quantità di dati (più non è sempre meglio), affrontare il bias 'lost in the middle' in cui i modelli trascurano informazioni in contesti lunghi, e ottimizzare l'efficienza dei token. Le soluzioni includono la ricerca semantica con ranker, il recupero di meno risultati ma di qualità superiore e la collocazione delle informazioni critiche all'inizio o alla fine del contesto.
Il grounding è direttamente collegato al monitoraggio delle risposte AI perché consente ai sistemi di fornire citazioni e attribuzione delle fonti. Piattaforme come AmICited tracciano come i sistemi AI fanno riferimento alle fonti, possibile solo quando il grounding è implementato correttamente. Questo aiuta a garantire un uso responsabile dell'AI e l'attribuzione del brand su diverse piattaforme AI.
Il bias 'lost in the middle' è un fenomeno per cui gli LLM performano peggio quando le informazioni rilevanti sono posizionate al centro di contesti lunghi, rispetto a quando sono all'inizio o alla fine. Questo accade perché i modelli tendono a 'scorrere velocemente' quando elaborano grandi quantità di testo. Le soluzioni includono la minimizzazione della dimensione dell'input, la collocazione delle informazioni critiche in posizioni preferenziali e l'uso di porzioni di testo più piccole.
Per la produzione, concentrati sull'assicurare la qualità dei dati, implementa controlli di accesso per le informazioni sensibili, stabilisci politiche di aggiornamento e refresh, abilita la registrazione log per la conformità e crea cicli di feedback utente per identificare i punti critici. Monitora l'utilizzo dei token per ottimizzare i costi, implementa il versionamento delle knowledge base e traccia il comportamento del modello per rilevare drift.
AmICited traccia come GPT, Perplexity e Google AI Overviews citano e fanno riferimento ai tuoi contenuti. Ottieni insight in tempo reale sul monitoraggio delle risposte AI e sull'attribuzione del brand.
Scopri come il Retrieval-Augmented Generation trasforma le citazioni dell'IA, permettendo un'attribuzione accurata delle fonti e risposte fondate su ChatGPT, Pe...

Scopri come i Large Language Model selezionano e citano le fonti attraverso la ponderazione delle evidenze, il riconoscimento delle entità e i dati strutturati....

Scopri come i modelli di IA citano dati visivi e grafici. Scopri perché la visualizzazione dei dati è importante per le citazioni da parte dell'IA e come monito...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.