Meta Tag NoAI: Controllare l’Accesso dell’AI Tramite Header
Scopri come implementare i meta tag noai e noimageai per controllare l’accesso dei crawler AI ai contenuti del tuo sito. Guida completa ai header di controllo e ai metodi di implementazione per l’accesso AI.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
I crawler web sono programmi automatizzati che navigano sistematicamente su Internet raccogliendo informazioni dai siti web. Storicamente, questi bot erano gestiti principalmente dai motori di ricerca come Google, il cui Googlebot scansionava le pagine, indicizzava i contenuti e reindirizzava gli utenti ai siti tramite i risultati di ricerca—creando un rapporto reciprocamente vantaggioso. Tuttavia, l’emergere dei crawler AI ha cambiato radicalmente questa dinamica. A differenza dei bot dei motori di ricerca tradizionali, che forniscono traffico di ritorno in cambio dell’accesso ai contenuti, i crawler di addestramento AI consumano enormi quantità di contenuti web per creare dataset per i modelli linguistici di grandi dimensioni, spesso restituendo poco o nessun traffico ai publisher. Questo cambiamento rende i meta tag—piccole direttive HTML che comunicano istruzioni ai crawler—sempre più importanti per chi crea contenuti e vuole mantenere il controllo su come il proprio lavoro viene utilizzato dai sistemi di intelligenza artificiale.
Cosa Sono i Meta Tag NoAI e NoImageAI?
I meta tag noai e noimageai sono direttive create da DeviantArt nel 2022 per aiutare i creatori di contenuti a impedire che il proprio lavoro venga utilizzato per addestrare generatori di immagini AI. Questi tag funzionano in modo simile alla direttiva noindex, da tempo utilizzata per indicare ai motori di ricerca di non indicizzare una pagina. La direttiva noai segnala che nessun contenuto della pagina deve essere usato per l’addestramento AI, mentre noimageai impedisce specificamente l’utilizzo delle immagini per l’addestramento di modelli AI. Puoi implementare questi tag nella sezione head dell’HTML con la seguente sintassi:
<!-- Blocca tutti i contenuti dall’addestramento AI --><metaname="robots"content="noai">
<!-- Blocca solo le immagini dall’addestramento AI --><metaname="robots"content="noimageai">
<!-- Blocca sia contenuti che immagini --><metaname="robots"content="noai, noimageai">
Ecco una tabella di confronto tra diversi meta tag e i loro scopi:
Direttiva
Scopo
Sintassi
Ambito
noai
Impedisce l’addestramento AI su tutti i contenuti
content="noai"
Tutto il contenuto della pagina
noimageai
Impedisce l’addestramento AI sulle immagini
content="noimageai"
Solo immagini
noindex
Impedisce l’indicizzazione dai motori di ricerca
content="noindex"
Risultati di ricerca
nofollow
Impedisce il follow dei link
content="nofollow"
Link in uscita
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
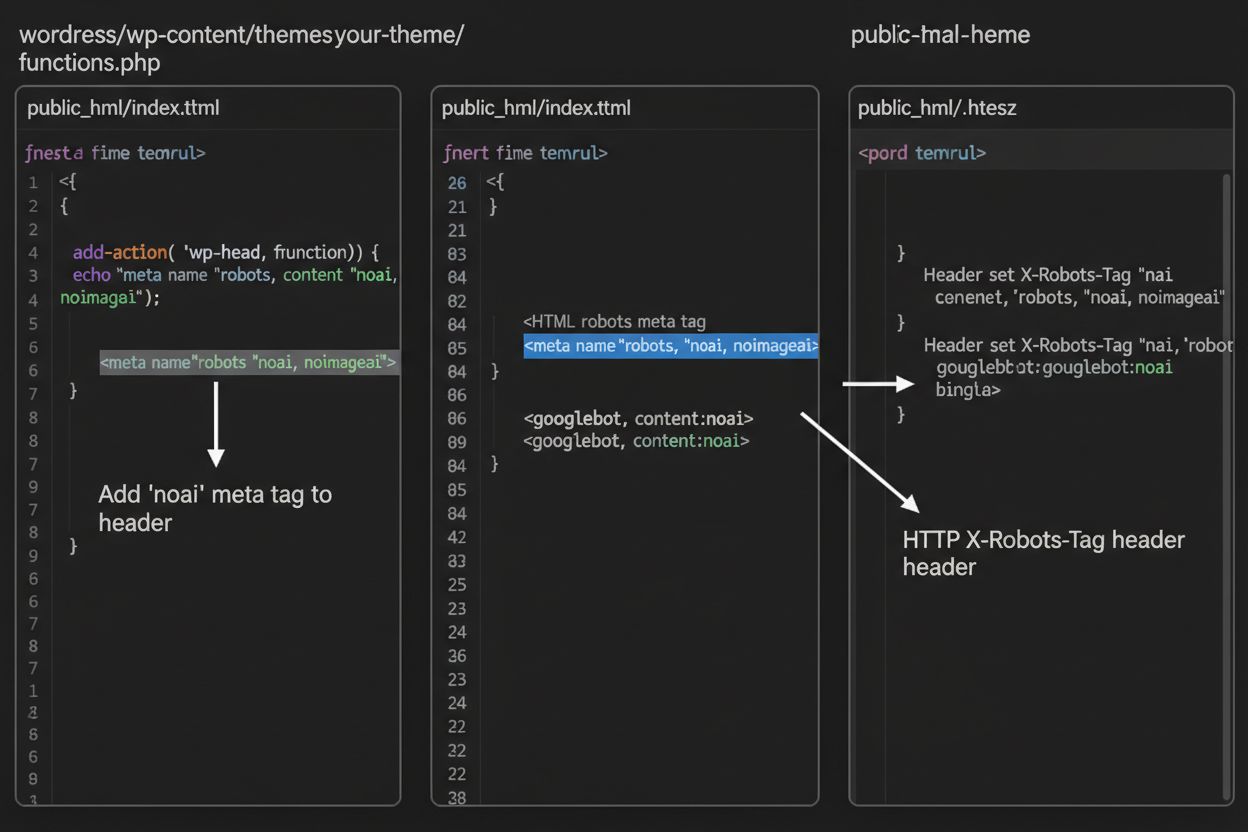
Mentre i meta tag sono inseriti direttamente nell’HTML, gli header HTTP offrono un metodo alternativo per comunicare direttive ai crawler a livello di server. L’header X-Robots-Tag può includere le stesse direttive dei meta tag ma funziona diversamente—viene inviato nella risposta HTTP prima che venga consegnato il contenuto della pagina. Questo approccio è particolarmente utile per controllare l’accesso a file non HTML come PDF, immagini e video, dove non è possibile inserire meta tag HTML.
Per server Apache, puoi impostare gli header X-Robots-Tag nel file .htaccess:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
Per NGINX, aggiungi l’header nella configurazione del server:
Gli header offrono una protezione globale su tutto il sito o su specifiche directory, ideali per strategie di controllo dell’accesso AI complete.
Come i Crawler AI Rispettano (o Ignorano) Queste Direttive
L’efficacia dei tag noai e noimageai dipende interamente dal fatto che i crawler scelgano o meno di rispettarli. I crawler affidabili delle principali aziende AI generalmente rispettano queste direttive:
GPTBot (OpenAI) - Rispetta le direttive noai
ClaudeBot (Anthropic) - Rispetta le direttive noai
PerplexityBot (Perplexity) - Rispetta le direttive noai
Amazonbot (Amazon) - Rispetta le direttive noai
CCBot (Common Crawl) - Rispetta le direttive noai
Crawler minori/sconosciuti - Potrebbero non rispettare le direttive
Tuttavia, i bot meno affidabili e i crawler malevoli possono deliberatamente ignorare queste direttive perché non esiste un meccanismo di enforcement. A differenza del robots.txt, che i motori di ricerca hanno accettato di rispettare come standard di settore, noai non è uno standard web ufficiale, quindi i crawler non sono obbligati a rispettarlo. Per questo motivo, gli esperti di sicurezza consigliano un approccio a più livelli che combini diversi metodi di protezione invece di affidarsi solo ai meta tag.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Metodi di Implementazione sulle Diverse Piattaforme
L’implementazione dei tag noai e noimageai varia in base alla piattaforma del tuo sito. Ecco le istruzioni passo-passo per le piattaforme più comuni:
1. WordPress (tramite functions.php)
Aggiungi questo codice nel file functions.php del child theme:
3. Squarespace
Vai su Impostazioni > Avanzate > Code Injection e aggiungi nel campo Header:
<metaname="robots"content="noai, noimageai">
4. Wix
Vai su Impostazioni > Codice Personalizzato, clicca su “Aggiungi Codice Personalizzato”, incolla il meta tag, seleziona “Head” e applica a tutte le pagine.
Ogni piattaforma offre diversi livelli di controllo—WordPress consente implementazioni specifiche per pagina tramite plugin, mentre Squarespace e Wix forniscono opzioni globali per tutto il sito. Scegli il metodo più adatto al tuo livello di competenza tecnica e alle tue esigenze specifiche.
Limiti ed Efficacia dei Tag NoAI
Anche se i tag noai e noimageai rappresentano un passo importante verso la protezione dei creatori di contenuti, presentano limiti significativi. Primo, non sono standard web ufficiali—sono stati introdotti da DeviantArt come iniziativa comunitaria, quindi non esiste una specifica formale o un meccanismo di enforcement. Secondo, l’adesione è completamente volontaria. I crawler affidabili delle grandi aziende li rispettano, ma quelli meno affidabili e gli scraper possono ignorarli senza conseguenze. Terzo, la mancanza di standardizzazione comporta un’adozione variabile. Alcune aziende e organizzazioni di ricerca AI minori potrebbero non conoscerli o non implementarli affatto. Infine, i meta tag da soli non possono impedire a malintenzionati determinati di eseguire scraping dei tuoi contenuti. Un crawler malevolo può ignorare completamente le tue direttive, quindi sono essenziali ulteriori livelli di protezione per una sicurezza davvero completa.
Combinare Meta Tag, robots.txt e Altri Metodi
La strategia più efficace per il controllo dell’accesso AI prevede più livelli di protezione invece di affidarsi a un solo metodo. Ecco un confronto tra diversi approcci:
Metodo
Ambito
Efficacia
Difficoltà
Meta Tag (noai)
A livello di pagina
Media (adesione volontaria)
Facile
robots.txt
A livello di sito
Media (solo consultivo)
Facile
Header X-Robots-Tag
A livello di server
Medio-Alta (copre tutti i tipi di file)
Media
Regole Firewall
A livello di rete
Alta (blocco a livello infrastrutturale)
Difficile
Allowlist IP
A livello di rete
Molto alta (solo fonti verificate)
Difficile
Una strategia completa può includere: (1) implementazione dei meta tag noai su tutte le pagine, (2) aggiunta di regole robots.txt per bloccare i principali crawler di training AI, (3) configurazione degli header X-Robots-Tag a livello di server per i file non HTML e (4) monitoraggio dei log di accesso per identificare crawler che ignorano le direttive. Questo approccio multilivello aumenta notevolmente la difficoltà per i malintenzionati e mantiene la compatibilità con i crawler affidabili che rispettano le tue preferenze.
Monitoraggio e Verifica della Conformità dei Crawler
Dopo aver implementato i tag noai e altre direttive, dovresti verificare che i crawler rispettino effettivamente le tue regole. Il metodo più diretto consiste nel controllare i log di accesso del server per l’attività dei crawler. Su server Apache, puoi cercare i crawler specifici:
Se noti richieste da parte di crawler che hai bloccato, significa che stanno ignorando le tue direttive. Per NGINX, verifica il file /var/log/nginx/access.log usando lo stesso comando grep. Inoltre, strumenti come Cloudflare Radar offrono una panoramica dei pattern di traffico dei crawler AI sul tuo sito, mostrando quali bot sono più attivi e come cambiano i loro comportamenti nel tempo. Un monitoraggio regolare dei log—almeno mensile—ti aiuta a individuare nuovi crawler e a verificare che le misure di protezione funzionino come previsto.
Il Futuro degli Standard per il Controllo dell’Accesso AI
Attualmente, noai e noimageai esistono in una zona grigia: sono ampiamente riconosciuti e rispettati dalle principali aziende AI, ma restano non ufficiali e non standardizzati. Tuttavia, c’è una crescente spinta verso una standardizzazione formale. Il W3C (World Wide Web Consortium) e vari gruppi di settore stanno discutendo su come creare standard ufficiali per il controllo dell’accesso AI, che darebbero a queste direttive lo stesso peso di standard consolidati come robots.txt. Se noai diventasse uno standard web ufficiale, la conformità diventerebbe una prassi attesa dal settore invece che volontaria, aumentando notevolmente l’efficacia delle direttive. Questo sforzo di standardizzazione riflette un cambiamento più ampio nella percezione dei diritti dei creatori di contenuti e nel bilanciamento tra sviluppo AI e protezione dei publisher. Con l’adozione sempre più diffusa di questi tag e la richiesta di tutele più forti, cresce la probabilità di una standardizzazione ufficiale, rendendo il controllo dell’accesso AI fondamentale come le regole di indicizzazione per i motori di ricerca.
Domande frequenti
Cos’è il meta tag noai e come funziona?
Il meta tag noai è una direttiva da inserire nella sezione head dell’HTML del sito che segnala ai crawler AI che i tuoi contenuti non devono essere utilizzati per l’addestramento di modelli di intelligenza artificiale. Funziona comunicando la tua preferenza ai bot AI corretti, anche se non è uno standard web ufficiale e alcuni crawler potrebbero ignorarlo.
Noai è uno standard web ufficiale?
No, noai e noimageai non sono standard web ufficiali. Sono stati creati da DeviantArt come iniziativa della comunità per aiutare i creatori a proteggere il proprio lavoro dall’addestramento AI. Tuttavia, importanti aziende AI come OpenAI, Anthropic e altre hanno iniziato a rispettare queste direttive nei loro crawler.
Quali crawler AI rispettano il meta tag noai?
I principali crawler AI, tra cui GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) e altri rispettano la direttiva noai. Tuttavia, alcuni crawler minori o meno affidabili potrebbero ignorarla, motivo per cui si consiglia un approccio a più livelli per la protezione.
Qual è la differenza tra meta tag e header HTTP per il controllo AI?
I meta tag vengono inseriti nella sezione head dell’HTML e si applicano alle singole pagine, mentre gli header HTTP (X-Robots-Tag) si impostano a livello di server e possono essere applicati globalmente o a specifici tipi di file. Gli header funzionano anche per file non HTML come PDF e immagini, risultando più versatili per una protezione completa.
Posso implementare i tag noai su WordPress?
Sì, puoi implementare i tag noai su WordPress con diversi metodi: aggiungendo codice nel file functions.php del tema, utilizzando un plugin come WPCode o tramite builder come Divi ed Elementor. Il metodo functions.php è il più comune e prevede l’aggiunta di un semplice hook per inserire il meta tag nell’header del sito.
Devo bloccare tutti i crawler AI o solo quelli di training?
Dipende dai tuoi obiettivi di business. Bloccare i crawler di training protegge i tuoi contenuti dall’utilizzo per lo sviluppo di modelli AI. Tuttavia, bloccare i crawler di ricerca come OAI-SearchBot può ridurre la visibilità nei risultati di ricerca AI e sulle piattaforme di discovery. Molti editori adottano un approccio selettivo che blocca i crawler di training ma consente quelli di ricerca.
Come posso verificare che i crawler AI rispettino le mie direttive noai?
Puoi controllare i log del server per l’attività dei crawler usando comandi come grep per cercare specifici user agent dei bot. Strumenti come Cloudflare Radar offrono visibilità sui pattern di traffico dei crawler AI. Monitora regolarmente i log per verificare se crawler bloccati accedono ancora ai tuoi contenuti, segno che stanno ignorando le tue direttive.
Cosa devo fare se i crawler ignorano i miei meta tag noai?
Se i crawler ignorano i tuoi meta tag, implementa ulteriori livelli di protezione come regole robots.txt, header HTTP X-Robots-Tag e blocchi a livello di server tramite .htaccess o regole del firewall. Per una verifica più forte, usa la allowlist degli IP per consentire solo le richieste provenienti dagli IP verificati pubblicati dalle principali aziende AI.
Come Identificare i Crawler AI nei Log del Server: Guida Completa alla Rilevazione
Scopri come identificare e monitorare i crawler AI come GPTBot, PerplexityBot e ClaudeBot nei log del tuo server. Scopri stringhe user-agent, metodi di verifica...
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
Quali crawler AI dovrei autorizzare? Guida completa per il 2025
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
12 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.