
URL canonici e AI: prevenire problemi di contenuti duplicati
Scopri come gli URL canonici prevengono i problemi di contenuti duplicati nei sistemi di ricerca AI. Scopri le migliori pratiche per implementare i canonici, mi...
7 min di lettura

Scopri come la ripubblicazione dei contenuti genera problemi di contenuto duplicato che danneggiano la visibilità nella ricerca AI più gravemente rispetto alla ricerca tradizionale. Scopri le misure tecniche e le migliori pratiche.
Ripubblicare contenuti su più canali, piattaforme e formati è una strategia legittima e spesso necessaria per massimizzare la portata e il coinvolgimento. Tuttavia, questa pratica crea una tensione fondamentale con il modo in cui i sistemi di ricerca—soprattutto quelli alimentati dall’intelligenza artificiale—elaborano e classificano i contenuti. Il problema non è se puoi ripubblicare, ma se lo fai in modo tale da non sabotare la tua visibilità nei risultati di ricerca AI. A differenza dei motori di ricerca tradizionali che hanno affinato sofisticati meccanismi di rilevamento dei duplicati per decenni, i sistemi AI gestiscono i contenuti duplicati in modo diverso, creando nuovi rischi a cui molti editori non si sono ancora adattati.
Secondo la documentazione tecnica di Microsoft su Copilot e la ricerca AI, “gli LLM raggruppano URL quasi duplicati in un unico cluster e poi scelgono una pagina per rappresentare il gruppo.” Questo comportamento di clustering è fondamentalmente diverso da come l’algoritmo PageRank di Google distribuisce l’autorità sulle pagine duplicate. Piuttosto che consolidare i segnali, i sistemi AI prendono una decisione binaria: selezionano una pagina rappresentativa da un cluster di contenuti simili e in gran parte ignorano le altre. Questo processo di selezione non è sempre prevedibile né si basa sulla versione che preferiresti classificare. L’algoritmo considera fattori come la freschezza, la qualità del contenuto, i segnali tecnici e l’autorità del dominio—ma il peso di questi fattori rimane opaco. Ciò che rende particolarmente problematico questo approccio è che i sistemi AI possono selezionare una versione obsoleta se le differenze tra le pagine sono minime a tal punto che l’algoritmo di clustering non rileva variazioni significative.
| Aspetto | Ricerca Tradizionale | Ricerca AI |
|---|---|---|
| Gestione duplicati | Consolida segnali di autorità | Crea cluster e seleziona un solo rappresentante |
| Rischio penalità | Possibile azione manuale | Nessuna penalità, ma diluizione della visibilità |
| Riconoscimento aggiornamenti | Propagazione graduale dei segnali | Può non rilevare aggiornamenti se le differenze sono minime |
| Efficienza di scansione | Disperde budget sui duplicati | Riduce la priorità di scansione per i duplicati |
| Rispetto dei canonicals | Rispettato ma non garantito | Fondamentale per la selezione del cluster |
Ripubblicare senza le dovute cautele introduce tre rischi interconnessi che impattano direttamente sulla visibilità AI:
Diluizione dei segnali di intento: Quando lo stesso contenuto appare su più URL, il sistema AI riceve segnali contrastanti su quale versione risponda meglio alla query dell’utente. Invece di concentrare l’autorità su un singolo URL, i segnali si disperdono nel cluster. Questa diluizione riduce il punteggio di affidabilità che i sistemi AI assegnano ai tuoi contenuti per decidere se includerli nelle risposte. Un contenuto che avrebbe potuto essere fonte primaria diventa una considerazione secondaria perché il sistema non riesce a determinare con certezza quale versione sia autorevole.
Rischio di rappresentanza: La selezione da parte del sistema AI di quale pagina rappresenti il tuo cluster di contenuti potrebbe non essere allineata ai tuoi obiettivi di business. Potresti ripubblicare un articolo su una rete di syndication aspettandoti che quella versione generi traffico, solo per vedere il sistema AI selezionare la versione originale—o peggio, quella syndication che non rimanda al tuo sito. Questo disallineamento fa sì che la tua strategia di ripubblicazione lavori contro i tuoi obiettivi di visibilità invece che amplificarli.
Latenza negli aggiornamenti e obsolescenza: Quando aggiorni il tuo contenuto originale ma le versioni ripubblicate restano invariate, i sistemi AI possono selezionare una versione obsoleta come pagina rappresentativa. L’algoritmo di clustering non sempre riconosce che una versione è più nuova o accurata di un’altra, soprattutto se le modifiche sono incrementali e non strutturali. Si crea così una situazione in cui il tuo contenuto più aggiornato e accurato è invisibile mentre una versione vecchia rappresenta la tua expertise per i sistemi AI.
L’errore più comune nella ripubblicazione avviene quando i contenuti vengono syndicate su piattaforme di terze parti senza implementare tag canonici. Considera uno scenario tipico: un’azienda software B2B pubblica una guida completa sul proprio blog e poi la syndica a pubblicazioni di settore come Medium, LinkedIn e aggregatori di notizie specializzati. Ogni piattaforma ospita lo stesso contenuto con URL diversi. Senza i tag canonici puntati all’originale, l’algoritmo di clustering dell’AI considera tutte le versioni come ugualmente autorevoli. La piattaforma di syndication potrebbe avere maggiore autorità di dominio, portando il sistema AI a selezionare quella versione come pagina rappresentativa. Ora il tuo contenuto originale—quello che hai ottimizzato, aggiornato e a cui hai costruito backlink—diventa invisibile nei risultati di ricerca AI. Il traffico e l’autorità fluiscono verso la piattaforma di syndication invece che sulla tua proprietà. Questo scenario si ripete migliaia di volte ogni giorno nel settore editoriale, con editori che inconsapevolmente sabotano la propria visibilità per la mancata implementazione di un semplice tag HTML.
I contenuti specifici di campagna generano un problema di contenuto duplicato particolarmente insidioso quando vengono ripubblicati su diversi canali. Un team marketing lancia una landing page ottimizzata per una promozione, poi ripubblica variazioni di quel contenuto su newsletter, social media, annunci a pagamento e siti partner. Ogni versione contiene testo, CTA o formattazione leggermente diversi—ma il contenuto e l’intento di fondo restano identici. I sistemi AI riconoscono questi come quasi duplicati e li raggruppano. Il problema si aggrava quando le pagine di campagna vengono ripubblicate senza un’adeguata implementazione dei canonicals. Il sistema AI potrebbe selezionare la versione newsletter (che non ha tracciamento delle conversioni) come pagina rappresentativa, o quella partner che non porta benefici alle tue metriche. Inoltre, quando le campagne terminano e le pagine vengono archiviate o eliminate, il sistema AI potrebbe aver già selezionato una versione ormai non più attiva, creando situazioni in cui i tuoi contenuti diventano invisibili o portano a esperienze non funzionanti.
La ripubblicazione regionale introduce complessità perché il rilevamento dei contenuti duplicati deve tener conto delle esigenze legittime di localizzazione. Un’azienda con operazioni in più paesi potrebbe pubblicare lo stesso contenuto in lingue diverse o con variazioni regionali. Senza un’implementazione corretta, queste versioni regionali competono tra loro nei cluster AI. Considera una SaaS che pubblica una guida alle funzionalità in inglese sul proprio dominio US, poi la ripubblica sul dominio UK con ortografia britannica e prezzi locali. Il sistema AI le raggruppa come duplicati, selezionando potenzialmente la versione US anche per gli utenti UK. La soluzione richiede l’implementazione dei tag hreflang che segnalano le relazioni regionali ai sistemi AI, anche se l’efficacia di hreflang nella ricerca AI è meno consolidata rispetto a quella nella ricerca tradizionale.
<!-- Sulla versione US (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Sulla versione UK (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
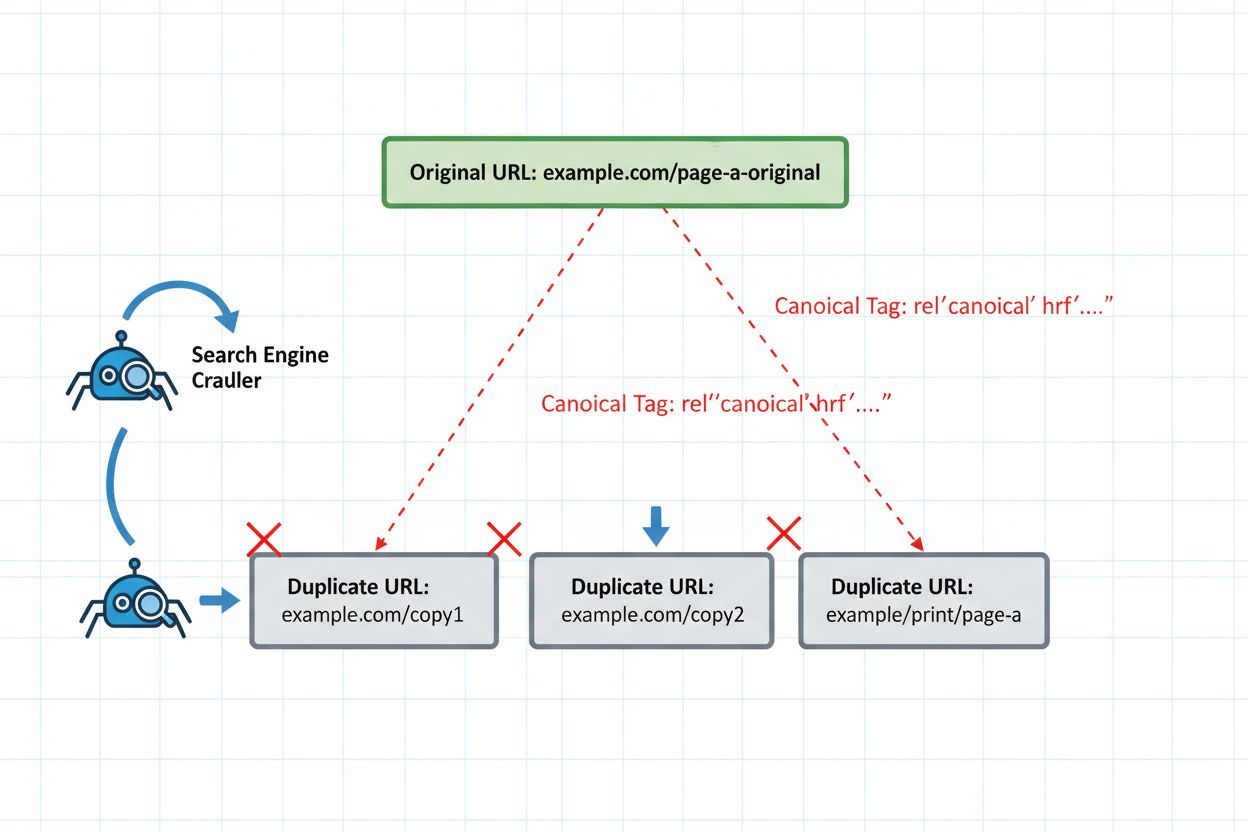
Implementare le giuste misure tecniche è imprescindibile per una ripubblicazione sicura. Il tag canonical resta la tua principale difesa, indicando esplicitamente ai sistemi AI quale versione debba rappresentare il tuo cluster di contenuti. Inserisci il tag canonical nella sezione <head> di ogni versione ripubblicata, puntando alla versione autorevole preferita. Per i contenuti syndication, questo significa di solito puntare al tuo dominio originale.
<!-- Sulla versione syndication (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Per i contenuti che non devono mai competere con altre versioni, implementa noindex sulle versioni secondarie. In questo modo vengono completamente escluse dall’indicizzazione AI, assicurando che non possano essere selezionate come pagine rappresentative. Usa questo approccio per pagine duplicate interne, versioni di test o contenuti syndication per cui desideri zero visibilità nella ricerca AI.
<!-- Sulla versione secondaria che non deve essere indicizzata -->
<meta name="robots" content="noindex, follow" />
I redirect 301 forniscono il segnale più forte per consolidare l’autorità, ma usali solo quando la versione secondaria non verrà mai aggiornata in modo indipendente. I redirect comunicano ai sistemi AI che il vecchio URL è stato spostato definitivamente, consolidando tutti i segnali nella nuova posizione. Tuttavia, se hai bisogno che entrambe le versioni rimangano attive (ad esempio nella syndication), i redirect creano problemi perché interrompono la struttura degli URL della piattaforma syndication.
# In .htaccess o configurazione server
Redirect 301 /old-article https://yoursite.com/new-article
Per i sistemi di gestione dei contenuti, implementa rel=“canonical” dinamicamente per gestire paginazione, varianti di parametri e URL basati su sessione che creano duplicati involontari. Molte piattaforme CMS generano più URL per lo stesso contenuto tramite diversi percorsi di navigazione—i tag canonici li consolidano automaticamente.
IndexNow accelera la scoperta dei segnali canonici e la consolidazione dei duplicati, riducendo ciò che tradizionalmente richiedeva settimane a pochi giorni. Quando implementi i tag canonici sui contenuti ripubblicati, IndexNow notifica immediatamente ai sistemi di ricerca che questi URL devono essere raggruppati. Invece di attendere che i crawler individuino la relazione canonica tramite la normale scansione, IndexNow invia direttamente questa informazione all’indice di Microsoft e agli altri sistemi partecipanti. Questo è particolarmente prezioso quando stai correggendo errori di ripubblicazione a posteriori—puoi implementare i tag canonici e usare IndexNow per segnalare immediatamente la modifica, senza aspettare che i crawler rivisitino le pagine. Per gli editori che gestiscono contenuti su più piattaforme, IndexNow diventa uno strumento fondamentale per mantenere il controllo su quale versione rappresenta il tuo cluster di contenuti. L’integrazione API consente di inviare URL in blocco, rendendo praticabile la gestione di centinaia o migliaia di pagine ripubblicate.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Monitorare quale versione dei tuoi contenuti ripubblicati viene selezionata dai sistemi AI richiede un controllo oltre le analytics tradizionali. Imposta un tracking per identificare quando i sistemi AI citano o fanno riferimento ai tuoi contenuti, annotando quale URL appare nei risultati di ricerca AI. Strumenti come Semrush, Ahrefs e Moz stanno iniziando ad aggiungere metriche di visibilità nella ricerca AI, anche se ancora meno mature rispetto al tracking di ricerca tradizionale. Implementa parametri UTM sulle versioni syndication per tracciare l’attribuzione del traffico, ma considera che i sistemi AI potrebbero non trasmettere questi parametri, rendendo difficile un’attribuzione diretta. Monitora la Search Console (o strumenti equivalenti per altri motori di ricerca) per i pattern di scansione—se le versioni secondarie sono scansionate più frequentemente della tua versione canonica, significa che il sistema AI potrebbe aver selezionato la pagina rappresentativa sbagliata. Imposta alert per le menzioni dei tuoi contenuti sulle piattaforme di syndication e incrocia questi dati con la tua visibilità AI per identificare disallineamenti tra dove appaiono i tuoi contenuti e da dove i sistemi AI li selezionano.
Applica questa checklist prima di ripubblicare qualsiasi contenuto per mantenere il controllo sulla visibilità AI:
Prima della ripubblicazione, identifica la tua versione canonica—l’URL che vuoi rappresenti quel contenuto nei risultati di ricerca AI. Di solito dovrebbe essere il tuo dominio, non una piattaforma di syndication. Implementa tag canonici su ogni versione ripubblicata puntando al tuo URL canonico, anche se stai ripubblicando su tue stesse proprietà (domini diversi, sottodomini o varianti di parametri). Usa IndexNow per notificare immediatamente ai sistemi di ricerca la relazione canonica, invece di attendere la scoperta tramite scansione. Evita di ripubblicare su piattaforme autorevoli che non supportano i canonicals—alcune piattaforme rimuovono i tag canonici o non li consentono, quindi sono inadatte alla ripubblicazione se non sei disposto a perdere visibilità. Monitora le prime 48 ore dopo la ripubblicazione per verificare che i sistemi AI selezionino la versione canonica desiderata, non un’alternativa. Aggiorna tutte le versioni simultaneamente quando apporti modifiche ai contenuti—se aggiorni solo la versione canonica, l’algoritmo di clustering potrebbe non riconoscere l’aggiornamento su tutte le versioni, rischiando che il sistema AI selezioni una versione obsoleta. Stabilisci un calendario di ripubblicazione che eviti che i contenuti su piattaforme secondarie diventino obsoleti; i contenuti syndication non aggiornati aumentano il rischio che i sistemi AI li selezionino come versione rappresentativa se la versione canonica non è stata aggiornata di recente.
I tag canonici non prevengono penalità perché il contenuto duplicato non comporta penalità in primo luogo. Tuttavia, i tag canonici sono fondamentali per la ricerca AI perché indicano ai sistemi AI quale versione debba rappresentare il tuo cluster di contenuti. Senza tag canonici, i sistemi AI potrebbero selezionare una versione indesiderata come fonte autorevole, riducendo la tua visibilità.
Monitora quali URL compaiono nei risultati di ricerca AI e nelle citazioni dei tuoi contenuti. Strumenti come Semrush e Ahrefs stanno aggiungendo metriche sulla visibilità nella ricerca AI. Controlla la Search Console per i pattern di scansione—se le versioni secondarie vengono scansionate più frequentemente della tua versione canonica, il sistema AI potrebbe aver selezionato la pagina sbagliata.
Tecnicamente sì, ma non è consigliato. Senza tag canonici, i sistemi AI raggrupperanno i tuoi contenuti e ne selezioneranno una versione come rappresentativa—ma non controllerai quale. La piattaforma di syndication potrebbe avere maggiore autorità, portando l'AI a selezionare quella versione invece del tuo dominio originale.
La ripubblicazione si riferisce solitamente alla distribuzione dei tuoi contenuti su più canali che controlli o con cui collabori. La syndication di contenuti è una forma specifica di ripubblicazione in cui piattaforme di terze parti ripubblicano i tuoi contenuti con il tuo permesso. Entrambe creano problemi di contenuto duplicato se non vengono gestite correttamente con tag canonici.
I tag canonici vengono generalmente riconosciuti entro 24-48 ore se utilizzi IndexNow per notificare immediatamente i sistemi di ricerca. Senza IndexNow, potrebbero essere necessarie settimane affinché i crawler rilevino la relazione canonica. Ecco perché IndexNow è fondamentale per gestire i contenuti ripubblicati—accelera notevolmente il processo.
Usa i redirect 301 solo quando desideri consolidare permanentemente gli URL e la versione secondaria non verrà mai aggiornata in modo indipendente. Usa i tag canonici quando entrambe le versioni devono rimanere attive (come nella syndication). I redirect sono segnali più forti ma interrompono la funzionalità dell'URL secondario.
Sì, se non viene gestita correttamente. La ripubblicazione senza tag canonici diluisce i segnali di autorità su più URL. I sistemi AI potrebbero selezionare la versione syndication invece dell'originale, riducendo la visibilità sul tuo dominio. Una corretta implementazione dei tag canonici previene questo rischio.
Implementa tag canonici su ogni versione ripubblicata puntando al tuo dominio originale. Usa IndexNow per notificare immediatamente i sistemi di ricerca della relazione canonica. Evita di ripubblicare su piattaforme che non supportano i tag canonici. Monitora quale versione viene selezionata dai sistemi AI nelle prime 48 ore e intervieni se necessario.
Tieni traccia di come i sistemi AI citano e fanno riferimento ai tuoi contenuti ripubblicati su tutte le piattaforme. Ottieni informazioni in tempo reale su quale versione l'AI seleziona come fonte autorevole.
Scopri come gli URL canonici prevengono i problemi di contenuti duplicati nei sistemi di ricerca AI. Scopri le migliori pratiche per implementare i canonici, mi...

Scopri come gestire e prevenire i contenuti duplicati quando utilizzi strumenti di IA. Scopri tag canonici, reindirizzamenti, strumenti di rilevamento e best pr...
Scopri come riutilizzare e ottimizzare i contenuti per piattaforme AI come ChatGPT, Perplexity e Claude. Scopri strategie per la visibilità AI, la strutturazion...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.