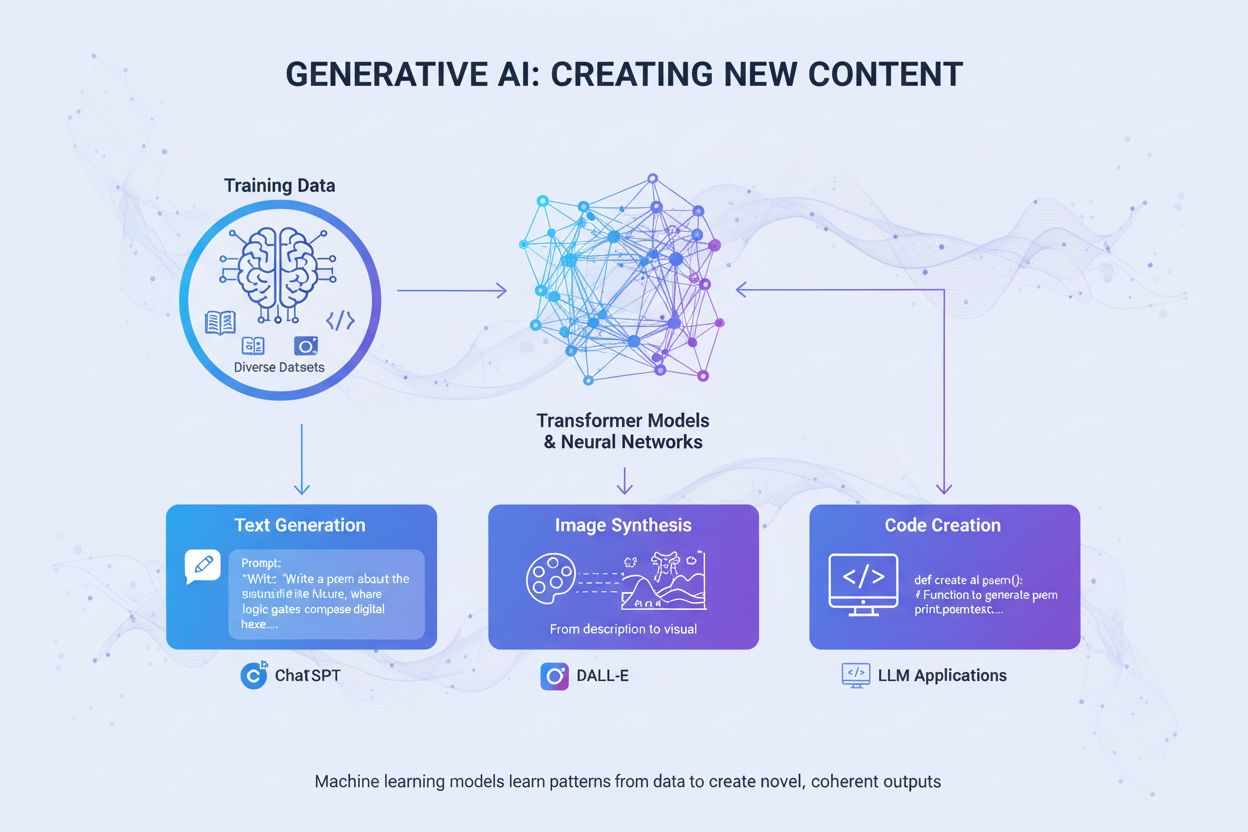
IA generativa
L'IA generativa crea nuovi contenuti dai dati di addestramento utilizzando reti neurali. Scopri come funziona, le sue applicazioni in ChatGPT e DALL-E, e perché...
13 min di lettura
Un’immagine generata dall’IA è un’immagine digitale creata da algoritmi di intelligenza artificiale e modelli di apprendimento automatico invece che da artisti o fotografi umani. Queste immagini vengono prodotte addestrando reti neurali su vasti set di dati di immagini etichettate, permettendo all’IA di apprendere schemi visivi e generare visuali originali e realistiche da prompt testuali, schizzi o altri dati di input.
Un'immagine generata dall'IA è un'immagine digitale creata da algoritmi di intelligenza artificiale e modelli di apprendimento automatico invece che da artisti o fotografi umani. Queste immagini vengono prodotte addestrando reti neurali su vasti set di dati di immagini etichettate, permettendo all'IA di apprendere schemi visivi e generare visuali originali e realistiche da prompt testuali, schizzi o altri dati di input.
Un’immagine generata dall’IA è un’immagine digitale creata da algoritmi di intelligenza artificiale e modelli di apprendimento automatico invece che da artisti o fotografi umani. Queste immagini sono prodotte tramite sofisticate reti neurali addestrate su vasti dataset di immagini etichettate, permettendo all’IA di apprendere schemi visivi, stili e relazioni tra concetti. La tecnologia consente ai sistemi IA di generare visuali originali e realistiche da diversi input—più comunemente prompt testuali, ma anche da schizzi, immagini di riferimento o altre fonti di dati. A differenza della fotografia tradizionale o dell’arte manuale, le immagini generate dall’IA possono rappresentare qualsiasi cosa immaginabile, inclusi scenari impossibili, mondi fantastici e concetti astratti mai esistiti nella realtà fisica. Il processo è estremamente rapido, spesso in grado di produrre immagini di alta qualità in pochi secondi, rendendolo una tecnologia trasformativa per le industrie creative, il marketing, il design di prodotto e la creazione di contenuti.
Il percorso della generazione di immagini tramite IA è iniziato con le ricerche fondamentali su deep learning e reti neurali, ma la tecnologia è diventata mainstream solo nei primi anni 2020. Le Reti Generative Avversarie (GAN), introdotte da Ian Goodfellow nel 2014, sono state tra i primi approcci di successo, utilizzando due reti neurali concorrenti per generare immagini realistiche. Tuttavia, la vera svolta è arrivata con l’emergere dei modelli di diffusione e delle architetture basate su transformer, che si sono dimostrate più stabili e capaci di produrre output di qualità superiore. Nel 2022, Stable Diffusion è stato rilasciato come modello open source, democratizzando l’accesso alla generazione di immagini IA e favorendo un’adozione diffusa. Poco dopo, DALL-E 2 di OpenAI e Midjourney hanno attirato grande attenzione, portando la generazione di immagini IA all’attenzione generale. Secondo statistiche recenti, il 71% delle immagini sui social media è ora generato dall’IA, e il mercato globale dei generatori di immagini IA è stato valutato a 299,2 milioni di dollari nel 2023, con previsioni di crescita annua del 17,4% fino al 2030. Questa crescita esplosiva riflette sia la maturazione tecnologica che l’adozione aziendale in vari settori.
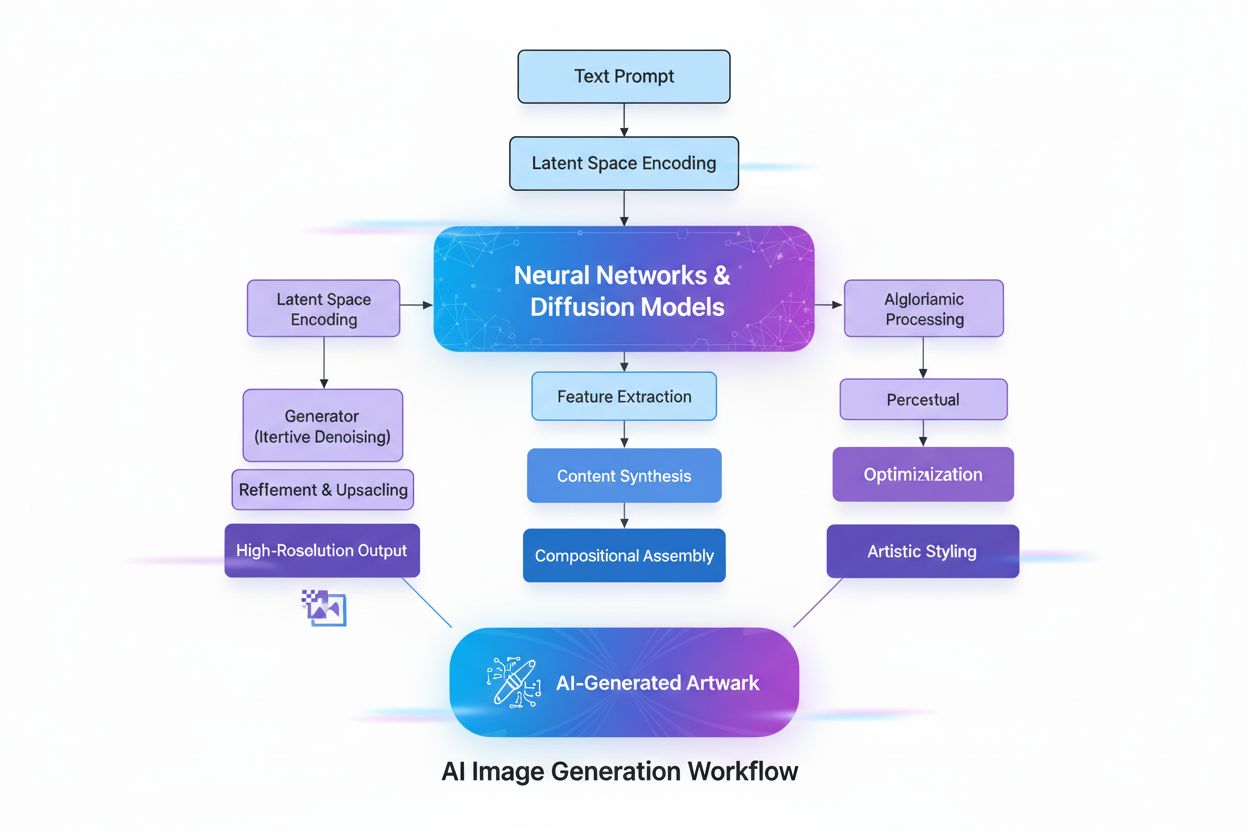
La creazione di immagini generate dall’IA coinvolge diversi processi tecnici sofisticati che collaborano per trasformare concetti astratti in realtà visiva. Il processo inizia con la comprensione del testo tramite Natural Language Processing (NLP), dove l’IA converte il linguaggio umano in rappresentazioni numeriche chiamate embedding. Modelli come CLIP (Contrastive Language-Image Pre-training) codificano i prompt testuali in vettori ad alta dimensionalità che catturano significato semantico e contesto. Ad esempio, quando un utente inserisce “una mela rossa su un albero”, il modello NLP suddivide questa frase in coordinate numeriche che rappresentano “rosso”, “mela”, “albero” e le loro relazioni spaziali. Questa mappa numerica guida poi il processo di generazione dell’immagine, fungendo da regola che indica all’IA quali elementi includere e come dovrebbero interagire.
I modelli di diffusione, che alimentano molti moderni generatori di immagini IA tra cui DALL-E 2 e Stable Diffusion, funzionano tramite un elegante processo iterativo. Il modello parte da puro rumore casuale—essenzialmente un caotico schema di pixel—e lo affina gradualmente attraverso molteplici passaggi di denoising. Durante l’addestramento, il modello impara a invertire il processo di aggiunta di rumore alle immagini, imparando essenzialmente a “denoisare” versioni corrotte fino a riportarle alla forma originale. Quando genera nuove immagini, applica questo processo appreso al contrario, partendo dal rumore casuale e trasformandolo progressivamente in un’immagine coerente. Il prompt testuale guida questa trasformazione ad ogni passaggio, assicurando che il risultato finale sia allineato alla descrizione dell’utente. Questo raffinamento step-by-step consente un controllo eccezionale e produce immagini dettagliate e di alta qualità.
Le Reti Generative Avversarie (GAN) adottano un approccio fondamentalmente diverso, basato sulla teoria dei giochi. Una GAN è composta da due reti neurali in competizione: un generatore che crea immagini false a partire da input casuali e un discriminatore che cerca di distinguere le immagini reali da quelle false. Queste reti ingaggiano un gioco avversariale in cui il generatore migliora continuamente per ingannare il discriminatore, mentre il discriminatore si affina nel rilevare i falsi. Questa dinamica competitiva spinge entrambe le reti all’eccellenza, producendo infine immagini quasi indistinguibili da fotografie reali. Le GAN sono particolarmente efficaci per la generazione di volti umani fotorealistici e per il transfer di stile, sebbene possano essere meno stabili da addestrare rispetto ai modelli di diffusione.
I modelli basati su transformer rappresentano un’altra architettura chiave, adattando la tecnologia transformer originariamente sviluppata per il NLP. Questi modelli eccellono nella comprensione di relazioni complesse all’interno dei prompt testuali e nella mappatura dei token linguistici su caratteristiche visive. Utilizzano meccanismi di self-attention per cogliere contesto e rilevanza, permettendo loro di gestire prompt articolati e multi-parte con grande accuratezza. I transformer possono generare immagini che corrispondono strettamente a descrizioni testuali dettagliate, rendendoli ideali per applicazioni che richiedono controllo preciso sulle caratteristiche dell’output.
| Tecnologia | Come Funziona | Punti di Forza | Debolezze | Migliori Casi d’Uso | Strumenti Esempio |
|---|---|---|---|---|---|
| Modelli di Diffusione | Denoisano iterativamente il rumore casuale in immagini strutturate guidate da prompt testuali | Output dettagliati di alta qualità, ottimo allineamento testo-immagine, addestramento stabile, controllo fine sul risultato | Processo di generazione più lento, richiede maggiori risorse computazionali | Generazione testo-immagine, arte ad alta risoluzione, visualizzazioni scientifiche | Stable Diffusion, DALL-E 2, Midjourney |
| GAN | Due reti neurali in competizione (generatore e discriminatore) creano immagini realistiche tramite training avversariale | Generazione veloce, ottima per fotorealismo, efficace in transfer di stile e potenziamento immagini | Instabilità nell’addestramento, rischio di mode collapse, controllo meno preciso sul testo | Volti fotorealistici, transfer di stile, upscaling immagini | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformer | Convertono prompt testuali in immagini usando self-attention e embedding dei token | Sintesi testo-immagine eccezionale, gestisce bene prompt complessi, forte comprensione semantica | Richiede elevate risorse computazionali, tecnologia più recente e meno ottimizzata | Generazione creativa da testo dettagliato, design e pubblicità, concept art immaginativa | DALL-E 2, Runway ML, Imagen |
| Neural Style Transfer | Fonde il contenuto di un’immagine con lo stile artistico di un’altra | Controllo artistico, mantiene il contenuto applicando lo stile, processo interpretabile | Limitato a compiti di transfer di stile, richiede immagini di riferimento, meno flessibile | Creazione artistica, applicazione di stile, potenziamento creativo | DeepDream, Prisma, Artbreeder |
L’adozione delle immagini generate dall’IA nei settori business è stata rapida e trasformativa. Nell’e-commerce e retail, le aziende utilizzano la generazione di immagini IA per creare fotografie di prodotto su larga scala, eliminando la necessità di costosi servizi fotografici. Secondo dati recenti, l'80% dei dirigenti retail prevede di adottare automazione IA entro il 2025, e le aziende retail hanno speso 19,71 miliardi di dollari in strumenti IA nel 2023, con la generazione di immagini a rappresentare una fetta significativa. Il mercato dell’editing di immagini tramite IA è valutato a 88,7 miliardi di dollari nel 2025 e si prevede raggiungerà 8,9 miliardi di dollari entro il 2034, con gli utenti aziendali che rappresentano circa il 42% della spesa totale.
Nel marketing e pubblicità, il 62% dei marketer utilizza l’IA per creare nuovi asset visivi e le aziende che usano l’IA per generare contenuti social segnalano aumenti dei tassi di engagement tra il 15 e il 25%. La capacità di generare rapidamente molteplici variazioni creative permette un A/B testing su scala senza precedenti, consentendo ai marketer di ottimizzare le campagne con precisione data-driven. Cosmopolitan magazine ha fatto notizia nel giugno 2022 pubblicando una copertina creata interamente con DALL-E 2, segnando la prima volta che una grande pubblicazione utilizzava immagini IA per la copertina. Il prompt utilizzato era: “A wide angle shot from below of a female astronaut with an athletic female body walking with swagger on Mars in an infinite universe, synthwave, digital art.”
Nell’imaging medico, le immagini generate dall’IA sono esplorate per scopi diagnostici e per la generazione di dati sintetici. La ricerca ha dimostrato che DALL-E 2 può generare immagini radiografiche realistiche da prompt testuali e persino ricostruire elementi mancanti in immagini radiologiche. Questa capacità ha importanti implicazioni per la formazione medica, la condivisione dei dati tra istituzioni in modo privacy-preserving e l’accelerazione dello sviluppo di nuovi strumenti diagnostici. Il mercato dei social media guidato dall’IA dovrebbe raggiungere 12 miliardi di dollari entro il 2031, rispetto ai 2,1 miliardi di dollari del 2021, a testimonianza del ruolo centrale della tecnologia nella creazione di contenuti digitali.
La rapida proliferazione delle immagini generate dall’IA ha sollevato importanti questioni etiche e legali che l’industria e i regolatori stanno ancora affrontando. Copyright e proprietà intellettuale rappresentano forse la sfida più controversa. La maggior parte dei generatori di immagini IA viene addestrata su enormi dataset di immagini raccolte dal web, molte delle quali sono opere protette da copyright create da artisti e fotografi. Nel gennaio 2023, tre artisti hanno intentato una causa storica contro Stability AI, Midjourney e DeviantArt, sostenendo che le aziende hanno utilizzato immagini protette per addestrare i loro algoritmi senza consenso o compenso. Questo caso rappresenta la tensione più ampia tra innovazione tecnologica e diritti degli artisti.
La questione di proprietà e diritti sulle immagini generate dall’IA rimane legalmente ambigua. Quando un’opera generata dall’IA ha vinto il primo premio al concorso di belle arti della Colorado State Fair nel 2022, presentata da Jason Allen usando Midjourney, è scoppiata una grande controversia. Molti hanno sostenuto che, essendo generata dall’IA, non dovrebbe qualificarsi come creazione originale umana. L’U.S. Copyright Office ha indicato che le opere create interamente dall’IA senza input creativo umano potrebbero non essere idonee alla protezione del copyright, sebbene si tratti di un ambito in evoluzione con cause legali e sviluppi normativi in corso.
Deepfake e disinformazione rappresentano un altro problema critico. I generatori di immagini IA possono creare immagini estremamente realistiche di eventi mai accaduti, favorendo la diffusione di informazioni false. Nel marzo 2023, immagini deepfake generate dall’IA che ritraevano il falso arresto dell’ex presidente Donald Trump si sono diffuse sui social, create usando Midjourney. Alcuni utenti hanno inizialmente creduto che fossero reali, dimostrando il potenziale della tecnologia per un uso malevolo. La sofisticazione delle immagini IA moderne rende sempre più difficile la rilevazione, creando sfide per piattaforme social e organizzazioni giornalistiche nel mantenere l’autenticità dei contenuti.
Bias nei dati di addestramento è un’altra rilevante questione etica. I modelli IA apprendono da dataset che possono contenere bias culturali, di genere e razziali. Il progetto Gender Shades guidato da Joy Buolamwini al MIT Media Lab ha evidenziato bias significativi nei sistemi commerciali di classificazione di genere, con tassi di errore per donne con pelle scura molto superiori a quelli per uomini con pelle chiara. Bias simili possono manifestarsi nella generazione di immagini, perpetuando stereotipi dannosi o sottorappresentando determinate demografie. Affrontare questi bias richiede un’attenta selezione dei dataset, dati di addestramento diversificati e una continua valutazione degli output dei modelli.
La qualità delle immagini generate dall’IA dipende molto dalla qualità e specificità del prompt di input. Il prompt engineering—l’arte di creare descrizioni testuali efficaci—è diventata una competenza fondamentale per chi vuole ottenere risultati ottimali. I prompt efficaci condividono alcune caratteristiche: sono specifici e dettagliati piuttosto che vaghi, includono descrittori di stile o medium (come “dipinto digitale”, “acquerello” o “fotorealistico”), incorporano informazioni su atmosfera e luce (ad esempio “ora d’oro”, “illuminazione cinematografica” o “ombre drammatiche”) e stabiliscono relazioni chiare tra gli elementi.
Ad esempio, invece di richiedere semplicemente “un gatto”, un prompt più efficace sarebbe: “un soffice gatto tigrato arancione seduto sul davanzale di una finestra al tramonto, luce dorata calda che filtra dalla finestra, fotorealistico, fotografia professionale”. Questo livello di dettaglio fornisce all’IA istruzioni precise su aspetto, ambientazione, illuminazione ed estetica desiderata. Le ricerche dimostrano che prompt strutturati con gerarchie chiare di informazioni producono risultati più coerenti e soddisfacenti. Gli utenti spesso utilizzano tecniche come specificare stili artistici, aggiungere aggettivi descrittivi, includere termini tecnici fotografici e persino citare artisti o movimenti artistici specifici per guidare l’IA verso l’output desiderato.
Le diverse piattaforme di generazione di immagini IA hanno caratteristiche, punti di forza e casi d’uso distinti. DALL-E 2, sviluppato da OpenAI, genera immagini dettagliate da prompt testuali con avanzate capacità di inpainting e editing. Funziona con un sistema a crediti, dove gli utenti acquistano crediti per ogni generazione. DALL-E 2 è noto per la sua versatilità e la capacità di gestire prompt complessi e sfumati, risultando popolare tra professionisti e creativi.
Midjourney si concentra sulla creazione di immagini artistiche e stilizzate, preferito da designer e artisti per le sue particolari sensibilità estetiche. La piattaforma funziona tramite un bot su Discord, richiedendo agli utenti di inserire i prompt tramite il comando /imagine. Midjourney è particolarmente noto per la produzione di immagini visivamente accattivanti, con colori complementari, illuminazione bilanciata e dettagli nitidi. Offre abbonamenti mensili da 10 a 120 dollari, con livelli superiori che garantiscono più generazioni mensili.
Stable Diffusion, sviluppato grazie alla collaborazione tra Stability AI, EleutherAI e LAION, è un modello open source che democratizza la generazione di immagini IA. La natura open source permette a sviluppatori e ricercatori di personalizzare e distribuire il modello, ideale per progetti sperimentali e implementazioni aziendali. Stable Diffusion si basa su un’architettura latent diffusion, che consente generazioni efficienti anche su schede grafiche consumer. Il prezzo è competitivo: 0,0023 dollari per immagine, con prove gratuite disponibili per i nuovi utenti.
Imagen di Google rappresenta un altro attore importante, offrendo modelli di diffusione testo-immagine con fotorealismo senza precedenti e profonda comprensione linguistica. Queste piattaforme testimoniano la varietà di approcci e modelli di business nello spazio della generazione di immagini IA, ognuna al servizio di esigenze e casi d’uso diversi.
Il panorama della generazione di immagini IA si evolve rapidamente, con diversi trend significativi che ne plasmano il futuro. Il miglioramento dei modelli e dell’efficienza prosegue a ritmo serrato, con modelli sempre più capaci di produrre output ad alta risoluzione, migliore allineamento testo-immagine e tempi di generazione ridotti. Il mercato dei generatori di immagini IA si prevede crescerà del 17,4% annuo fino al 2030, indicando investimenti e innovazione costanti. I trend emergenti includono la generazione di video da testo, in cui i sistemi IA estendono le capacità di generazione di immagini creando brevi clip; la generazione di modelli 3D, che permette all’IA di creare asset tridimensionali direttamente; e la generazione in tempo reale, che riduce la latenza e consente flussi di lavoro creativi interattivi.
Quadri normativi stanno iniziando ad emergere a livello globale, con governi e organismi di settore impegnati nello sviluppo di standard per trasparenza, protezione del copyright e uso etico. Il NO FAKES Act e normative simili propongono requisiti per watermarking dei contenuti IA e l’obbligo di dichiarare quando l’IA è stata utilizzata. Il 62% dei marketer globali ritiene che etichette obbligatorie per contenuti generati dall’IA avrebbero un effetto positivo sulle performance social, segnalando una presa di coscienza sull’importanza della trasparenza.
L’integrazione con altri sistemi IA sta accelerando, con la generazione di immagini sempre più incorporata in piattaforme e flussi di lavoro più ampi. I sistemi IA multimodali che combinano testo, immagini, audio e video stanno diventando sempre più sofisticati. La tecnologia si sta anche muovendo verso personalizzazione e customizzazione, con modelli IA che possono essere adattati a specifici stili artistici, estetiche di brand o preferenze individuali. Man mano che le immagini generate dall’IA diventano sempre più diffuse sulle piattaforme digitali, cresce di conseguenza l’importanza di monitorare il brand e tracciare le citazioni nelle risposte IA, rendendo gli strumenti che monitorano la presenza dei brand nei contenuti generati dall’IA sempre più preziosi per le aziende che vogliono mantenere visibilità e autorevolezza nell’era dell’IA generativa.
Le immagini generate dall'IA sono create interamente da algoritmi di apprendimento automatico a partire da prompt testuali o altri input, mentre la fotografia tradizionale cattura scene reali attraverso l'obiettivo di una fotocamera. Le immagini generate dall'IA possono rappresentare qualsiasi cosa immaginabile, inclusi scenari impossibili, mentre la fotografia è limitata a ciò che esiste o può essere fisicamente messo in scena. La generazione tramite IA è solitamente più rapida ed economica rispetto all'organizzazione di servizi fotografici, risultando ideale per la creazione di contenuti rapida e la prototipazione.
I modelli di diffusione funzionano iniziando da puro rumore casuale e raffinando gradualmente l'immagine attraverso passaggi iterativi di denoising. Il prompt testuale viene convertito in embeddings numerici che guidano questo processo di denoising, trasformando progressivamente il rumore in un'immagine coerente che corrisponde alla descrizione. Questo approccio passo dopo passo consente un controllo preciso e produce risultati di alta qualità e dettagliati con un eccellente allineamento al testo di input.
Le tre tecnologie principali sono le Reti Generative Avversarie (GAN), che utilizzano reti neurali concorrenti per creare immagini realistiche; i Modelli di Diffusione, che denoisano iterativamente il rumore randomico in immagini strutturate; e i Transformer, che convertono prompt testuali in immagini usando meccanismi di self-attention. Ogni architettura ha punti di forza distinti: le GAN eccellono nel fotorealismo, i modelli di diffusione producono risultati altamente dettagliati e i transformer gestiscono in modo eccezionale la sintesi testo-immagine complessa.
La titolarità del copyright sulle immagini generate dall'IA rimane legalmente ambigua e varia a seconda della giurisdizione. In molti casi, il copyright può appartenere alla persona che ha creato il prompt, allo sviluppatore del modello IA o potenzialmente a nessuno se l'IA opera in modo autonomo. L'U.S. Copyright Office ha indicato che le opere create interamente dall'IA senza input creativo umano potrebbero non essere idonee alla protezione del copyright, anche se si tratta di un ambito legale in evoluzione con contenziosi e sviluppi normativi in corso.
Le immagini generate dall'IA sono ampiamente utilizzate nell'e-commerce per la fotografia di prodotto, nel marketing per la creazione di visual per campagne e contenuti social, nello sviluppo di videogiochi per la creazione di personaggi e asset, nell'imaging medico per la visualizzazione diagnostica e nella pubblicità per il testing rapido di concept. Secondo dati recenti, il 62% dei marketer utilizza l'IA per creare nuovi asset visivi e il mercato dell'editing di immagini tramite IA è valutato a 88,7 miliardi di dollari nel 2025, a dimostrazione di una significativa adozione aziendale in vari settori.
Gli attuali generatori di immagini IA hanno difficoltà a generare mani e volti umani anatomicamente corretti, producendo spesso caratteristiche innaturali come dita in più o elementi facciali asimmetrici. Dipendono inoltre fortemente dalla qualità dei dati di addestramento, che può introdurre bias e limitare la diversità dei risultati. Inoltre, ottenere dettagli specifici richiede un'attenta progettazione dei prompt e la tecnologia a volte produce risultati che mancano di naturalezza o non riescono a cogliere le sfumature dell'intento creativo.
La maggior parte dei generatori di immagini IA viene addestrata su enormi set di dati di immagini raccolte dal web, molte delle quali sono opere protette da copyright. Questo ha portato a importanti questioni legali, con artisti che hanno intentato cause contro aziende come Stability AI e Midjourney per l'utilizzo di immagini protette senza autorizzazione o compenso. Alcune piattaforme come Getty Images e Shutterstock hanno vietato la pubblicazione di immagini generate dall'IA a causa di queste incertezze sul copyright, e i quadri normativi sono ancora in fase di sviluppo per garantire trasparenza dei dati e compensi equi.
Il mercato globale dei generatori di immagini IA è stato valutato a 299,2 milioni di dollari nel 2023 e si prevede crescerà a un tasso annuo composto del 17,4% fino al 2030. Il mercato più ampio dell'editing di immagini tramite IA è valutato a 88,7 miliardi di dollari nel 2025 e dovrebbe raggiungere gli 8,9 miliardi di dollari entro il 2034. Inoltre, il 71% delle immagini sui social media è ora generato dall'IA e il mercato dei social media guidato dall'IA dovrebbe raggiungere i 12 miliardi di dollari entro il 2031, a dimostrazione di una crescita esplosiva e di un'adozione mainstream.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
L'IA generativa crea nuovi contenuti dai dati di addestramento utilizzando reti neurali. Scopri come funziona, le sue applicazioni in ChatGPT e DALL-E, e perché...

Scopri Meta AI Imagine, la funzione di generazione di immagini da testo di Meta integrata su Facebook, Instagram, WhatsApp e Messenger. Scopri come funziona, le...
Scopri cos'è la generazione di contenuti AI, come funziona, i suoi vantaggi e sfide, e le best practice per utilizzare strumenti AI nella creazione di contenuti...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.