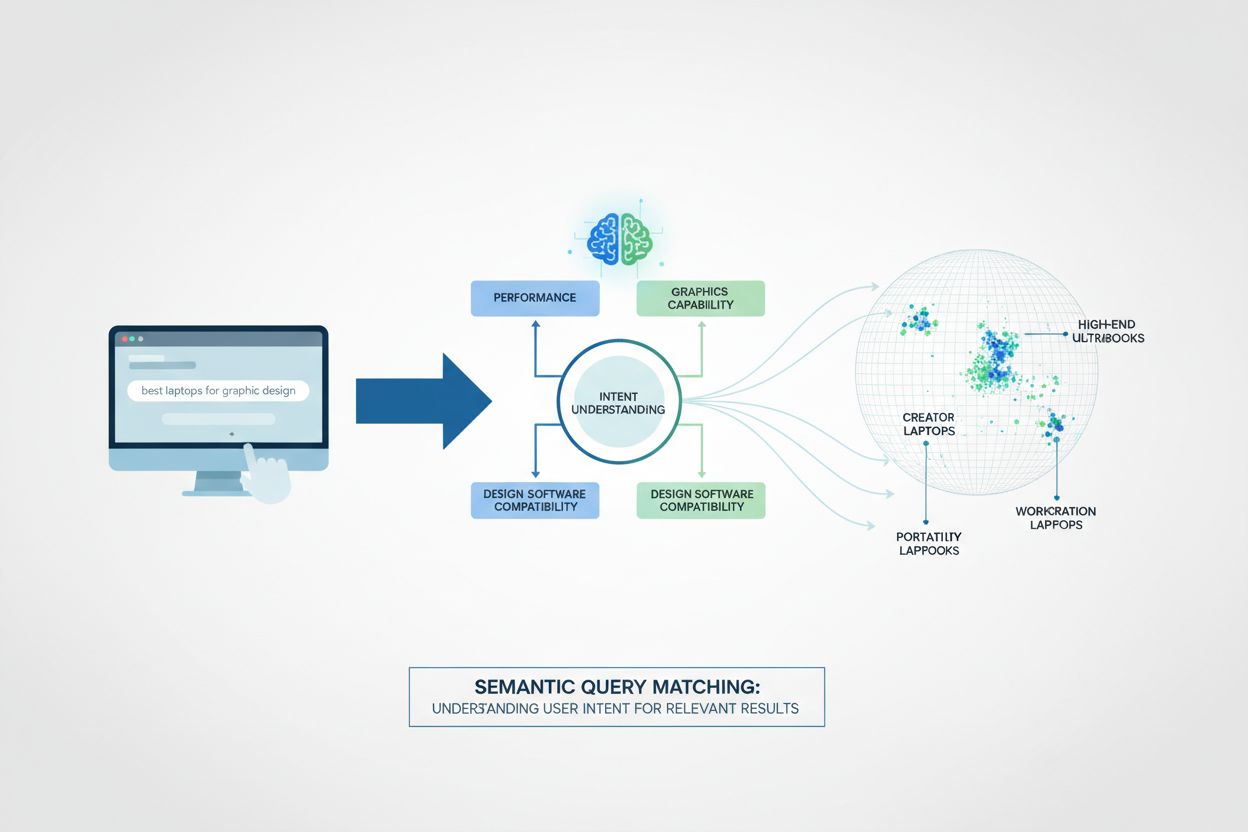
La corrispondenza semantica delle query è una tecnica basata sull’IA che comprende l’intento dell’utente e il significato dietro le query di ricerca, fornendo risultati pertinenti anche quando le parole chiave esatte non corrispondono. Utilizza il processamento del linguaggio naturale e il machine learning per interpretare il contesto, i sinonimi e le relazioni tra i concetti, permettendo esperienze di ricerca più accurate e intuitive in sistemi di IA come GPT, Perplexity e Google AI Overviews.
Corrispondenza Semantica delle Query
La corrispondenza semantica delle query è una tecnica basata sull'IA che comprende l'intento dell'utente e il significato dietro le query di ricerca, fornendo risultati pertinenti anche quando le parole chiave esatte non corrispondono. Utilizza il processamento del linguaggio naturale e il machine learning per interpretare il contesto, i sinonimi e le relazioni tra i concetti, permettendo esperienze di ricerca più accurate e intuitive in sistemi di IA come GPT, Perplexity e Google AI Overviews.
Comprendere la Corrispondenza Semantica delle Query
La corrispondenza semantica delle query è una sofisticata tecnologia di ricerca che comprende il significato e l’intento dietro le domande degli utenti invece di limitarsi a confrontare singole parole chiave. A differenza della corrispondenza tradizionale delle parole chiave, che cerca corrispondenze esatte o semplici variazioni, la corrispondenza semantica delle query analizza il significato contestuale dei termini di ricerca per fornire risultati più pertinenti. Ad esempio, un sistema semantico riconoscerebbe che “Come posso riparare lo schermo rotto del mio telefono?” e “Il display del mio dispositivo è rotto” sono essenzialmente la stessa domanda, anche se usano parole completamente diverse, mentre un sistema basato su parole chiave le considererebbe ricerche separate.
Come Funziona la Corrispondenza Semantica delle Query
La corrispondenza semantica delle query opera attraverso un processo tecnico multilivello che trasforma sia le query che i documenti in rappresentazioni matematiche chiamate embedding. Il sistema prima elabora il linguaggio naturale tramite algoritmi NLP per estrarre il significato, poi converte questa comprensione in vettori ad alta dimensionalità che catturano le relazioni semantiche. Un meccanismo di punteggio di similarità confronta il vettore della query con i vettori dei documenti per classificare i risultati in base alla pertinenza piuttosto che alla frequenza delle parole chiave. Questo approccio permette al sistema di comprendere sinonimi, contesto e intento dell’utente senza una programmazione esplicita per ogni variazione.
Aspetto
Ricerca Tradizionale per Parole Chiave
Corrispondenza Semantica delle Query
Metodo di Corrispondenza
Corrispondenza esatta o parziale delle parole
Punteggio di similarità basato sul significato
Comprensione dell’Intento
Limitata; si basa sulla presenza delle parole chiave
Tecnologie Fondamentali della Corrispondenza Semantica
La base tecnologica della corrispondenza semantica delle query si fonda su diversi componenti interconnessi che lavorano in sinergia:
Processamento del Linguaggio Naturale (NLP): Scompone il linguaggio umano in componenti analizzabili, estraendo struttura grammaticale, entità e relazioni semantiche
Modelli di Machine Learning: Modelli avanzati come BERT e GPT comprendono sfumature linguistiche, contesti e significati su larga scala
Embedding Vettoriali: Convertono il testo in rappresentazioni numeriche dove la similarità semantica si traduce in prossimità geometrica nello spazio vettoriale
Knowledge Graphs: Banche dati strutturate che mappano le relazioni tra concetti, entità e idee per arricchire la comprensione contestuale
Motori di Analisi Contestuale: Valutano le informazioni circostanti per disambiguare il significato e risolvere riferimenti all’interno delle query
Applicazioni Reali in Tutti i Settori
La corrispondenza semantica delle query è diventata indispensabile in numerosi settori e applicazioni. Nell’e-commerce, aiuta i clienti a trovare prodotti usando descrizioni in linguaggio naturale invece dei nomi esatti—cercando “scarpe comode per correre” restituisce calzature sportive pertinenti anche senza quelle parole chiave. I sistemi di assistenza clienti usano la corrispondenza semantica per indirizzare le richieste ai reparti giusti comprendendo il problema sottostante invece dei semplici trigger di parole chiave. Le piattaforme di ricerca aziendale permettono ai dipendenti di trovare documenti interni con query concettuali. I moderni sistemi di IA come ChatGPT, Perplexity e Google AI Overviews si basano fortemente sulla corrispondenza semantica delle query per comprendere l’intento dell’utente e recuperare dati di addestramento pertinenti. I motori di raccomandazione dei contenuti utilizzano la corrispondenza semantica per suggerire articoli, video e prodotti basandosi sul significato e non solo su tag espliciti.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Vantaggi e Benefici Chiave
I vantaggi della corrispondenza semantica delle query migliorano notevolmente l’esperienza utente e l’efficacia del sistema. Pertinenza migliorata significa che gli utenti trovano ciò che cercano al primo tentativo, riducendo frustrazione e iterazioni di ricerca. Questa tecnologia eccelle nella gestione di query ambigue o formulate male, comprendendo l’intento anche quando gli utenti faticano a esprimere esattamente i propri bisogni. La comprensione dei sinonimi elimina la necessità per gli utenti di indovinare la terminologia esatta—che si cerchi “automobile”, “auto” o “veicolo”, i sistemi semantici riconoscono questi termini come equivalenti. Questa capacità genera maggiore coinvolgimento poiché gli utenti scoprono contenuti più pertinenti, portando a una maggiore soddisfazione e a tassi di conversione più alti. L’esperienza utente superiore creata dalla corrispondenza semantica è diventata una necessità competitiva nei prodotti digitali moderni.
Sfide e Limitazioni
Nonostante i vantaggi, la corrispondenza semantica delle query affronta notevoli sfide tecniche e pratiche. La complessità computazionale resta elevata; l’elaborazione di vettori ad alta dimensionalità e il calcolo delle similarità su milioni di documenti richiedono molta potenza di calcolo e investimenti infrastrutturali. Le preoccupazioni sulla privacy dei dati sorgono perché i sistemi semantici devono analizzare in dettaglio le query degli utenti, sollevando questioni su conservazione e sicurezza dei dati. L’addestramento dei modelli richiede grandi set di dati di alta qualità e risorse computazionali significative, creando barriere per le organizzazioni più piccole. La tecnologia comporta un rischio di interpretazione errata—i modelli semantici possono restituire con sicurezza risultati irrilevanti quando fraintendono il contesto o affrontano query fuori dominio. Il classico compromesso tra latenza e accuratezza implica che analisi semantiche più sofisticate richiedano più tempo, potenzialmente peggiorando le prestazioni delle ricerche in tempo reale.
Corrispondenza Semantica delle Query nel Monitoraggio del Brand con l’IA
AmICited.com sfrutta la corrispondenza semantica delle query per rivoluzionare il modo in cui i brand monitorano la loro presenza nei contenuti e nelle risposte generate dall’IA. Invece di tracciare solo le menzioni esatte del nome del brand, la piattaforma di AmICited.com comprende l’intento e il contesto di come i sistemi di IA fanno riferimento a brand, prodotti e aziende su ChatGPT, Perplexity, Google AI Overviews e altre principali piattaforme di IA. L’approccio semantico permette di rilevare riferimenti indiretti, menzioni comparative e citazioni contestuali che il monitoraggio basato su parole chiave non coglierebbe affatto. Questa comprensione più profonda offre ai brand una visibilità completa su come i sistemi di IA presentano le loro offerte agli utenti—un’intelligence fondamentale per mantenere la reputazione del brand e la posizione sul mercato. Le capacità semantiche di AmICited.com si integrano perfettamente con strumenti complementari come FlowHunt.io, specializzato nell’ottimizzazione dei flussi di lavoro, creando un ecosistema completo per il monitoraggio dell’IA e l’intelligence di brand. Comprendendo il significato semantico delle risposte generate dall’IA, AmICited.com aiuta i brand a individuare opportunità, affrontare rappresentazioni errate e ottimizzare la propria presenza nel panorama informativo guidato dall’IA.
Evoluzione Futura della Corrispondenza Semantica delle Query
La corrispondenza semantica delle query continua a evolversi verso implementazioni sempre più sofisticate ed efficienti. La corrispondenza multimodale rappresenta il nuovo orizzonte, permettendo ai sistemi di comprendere le query e abbinarle a immagini, video e contenuti audio utilizzando framework semantici unificati. I ricercatori stanno sviluppando modelli di embedding più efficienti che mantengono la comprensione semantica riducendo i requisiti computazionali, rendendo la ricerca semantica accessibile anche alle realtà più piccole. Una personalizzazione migliorata consentirà ai sistemi semantici di adattare la corrispondenza in base alle preferenze individuali, alla cronologia delle ricerche e al contesto. L’integrazione con i sistemi di IA emergenti espanderà la corrispondenza semantica oltre la ricerca tradizionale, includendo IA conversazionali, assistenti vocali e sistemi autonomi. Gli sforzi di standardizzazione stanno creando framework e benchmark comuni per la corrispondenza semantica, consentendo migliore interoperabilità e confronti tra piattaforme. Con la maturazione di queste tecnologie, la corrispondenza semantica delle query diventerà la norma attesa anziché una funzionalità premium.
Domande frequenti
La corrispondenza semantica comprende l’intento e il significato, mentre la ricerca per parole chiave cerca corrispondenze esatte delle parole. La corrispondenza semantica può trovare risultati pertinenti anche quando le parole chiave esatte non vengono usate, riconoscendo che frasi diverse possono esprimere lo stesso concetto.
Gli embedding vettoriali convertono il testo in rappresentazioni numeriche che catturano il significato. Concetti simili sono posizionati vicini nello spazio vettoriale, permettendo al sistema di trovare contenuti semanticamente correlati calcolando le distanze tra i vettori.
Processamento del Linguaggio Naturale (NLP), modelli di machine learning come BERT e GPT, embedding vettoriali e knowledge graph lavorano insieme per comprendere l’intento della query e abbinarlo con contenuti pertinenti.
Sì, la corrispondenza semantica è eccellente nel comprendere sinonimi e variazioni semantiche. Riconosce che 'auto', 'veicolo' e 'automobile' hanno significati simili e può abbinare le query usando uno qualsiasi di questi termini senza configurazioni manuali.
Fornisce risultati più pertinenti in modo più rapido, riduce la necessità per gli utenti di perfezionare le loro ricerche e permette la formulazione di query più naturali e conversazionali senza richiedere corrispondenze esatte di parole chiave.
Le principali sfide includono la complessità computazionale, le preoccupazioni relative alla privacy dei dati, la necessità di un continuo addestramento dei modelli, il rischio di interpretazioni errate e il bilanciamento tra accuratezza e velocità di risposta.
La corrispondenza semantica permette a sistemi come AmICited.com di comprendere l’intento dietro i contenuti generati dall’IA e tracciare le menzioni del brand anche quando i nomi esatti non vengono usati, offrendo un monitoraggio completo della visibilità del brand.
Sebbene la corrispondenza semantica sia sempre più diffusa, entrambi gli approcci coesistono. Molti sistemi moderni utilizzano approcci ibridi che combinano la comprensione semantica con la corrispondenza di parole chiave per risultati ottimali.
Monitora Come i Sistemi di IA Riferiscono il Tuo Brand
AmICited.com utilizza la corrispondenza semantica delle query per tracciare le menzioni del tuo brand su ChatGPT, Perplexity e Google AI Overviews—comprendendo non solo ciò che viene detto, ma anche l’intento che vi sta dietro.
Che cos'è la ricerca semantica per l'IA? Come funziona e perché è importante
Scopri come la ricerca semantica utilizza l'intelligenza artificiale per comprendere l'intento e il contesto dell'utente. Scopri come si differenzia dalla ricer...
La ricerca semantica interpreta il significato e il contesto delle query usando NLP e machine learning. Scopri come si differenzia dalla ricerca a parole chiave...
La similarità semantica misura la correlazione basata sul significato tra testi utilizzando incorporamenti e metriche di distanza. Essenziale per il monitoraggi...
16 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.