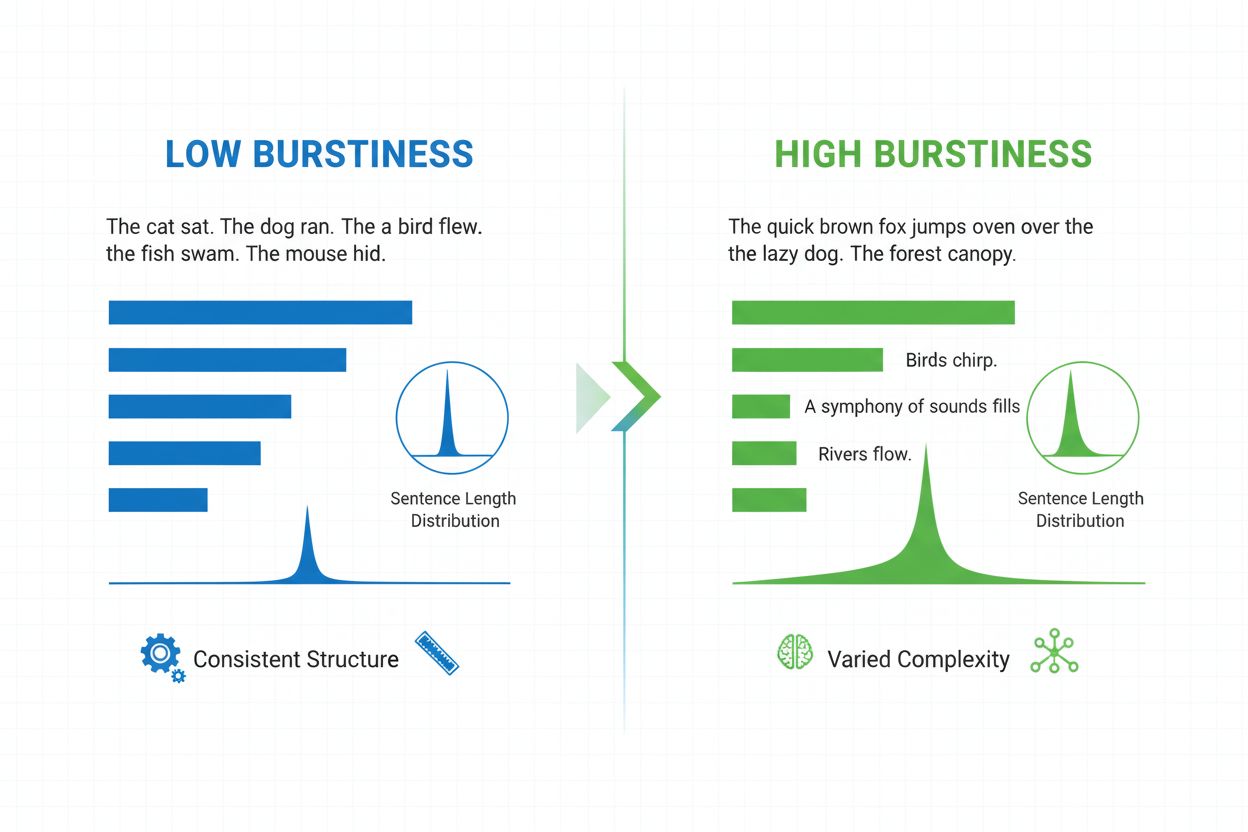
Definizione di Burstiness
La burstiness è una metrica linguistica quantificabile che misura la variabilità e la fluttuazione della lunghezza, struttura e complessità delle frasi all’interno di un documento scritto o di un testo. Il termine deriva dal concetto di “scoppi” di schemi frasali variabili—l’alternanza tra frasi brevi e concise e frasi più lunghe e articolate. Nel contesto dell’elaborazione del linguaggio naturale e del rilevamento dei contenuti IA, la burstiness funge da indicatore critico per stabilire se un testo è stato scritto da un umano o generato da un sistema di intelligenza artificiale. Gli scrittori umani producono naturalmente testi con elevata burstiness perché variano istintivamente la costruzione delle frasi in base all’enfasi, al ritmo e all’intento stilistico. Al contrario, i testi generati dall’IA tipicamente mostrano bassa burstiness perché i modelli linguistici sono addestrati su schemi statistici che favoriscono coerenza e prevedibilità. Comprendere la burstiness è essenziale per creatori di contenuti, educatori, ricercatori e organizzazioni che monitorano contenuti generati dall’IA su piattaforme come ChatGPT, Perplexity, Google AI Overviews e Claude.
Contesto Storico e Sviluppo
Il concetto di burstiness nasce dalla ricerca in linguistica computazionale e teoria dell’informazione, dove gli scienziati hanno cercato di quantificare le proprietà statistiche del linguaggio naturale. I primi lavori in stilometria—l’analisi statistica dello stile di scrittura—hanno identificato che la scrittura umana presenta schemi caratteristici di variazione che differiscono fondamentalmente dai testi generati dalle macchine. Con il crescente sviluppo dei large language models (LLM) nei primi anni 2020, i ricercatori hanno riconosciuto che la burstiness, combinata con la perplessità (una misura della prevedibilità delle parole), poteva fungere da indicatore affidabile di contenuti generati dall’IA. Secondo ricerche di QuillBot e istituzioni accademiche, circa il 78% delle aziende ora utilizza strumenti di monitoraggio dei contenuti guidati dall’IA che incorporano l’analisi della burstiness nei loro algoritmi di rilevamento. Lo studio della Stanford University del 2023 sugli elaborati TOEFL ha dimostrato che i metodi di rilevamento basati sulla burstiness, pur essendo utili, presentano limiti significativi—soprattutto riguardo ai falsi positivi nella scrittura non madrelingua inglese. Questa ricerca ha portato allo sviluppo di sistemi di rilevamento IA più sofisticati e multilivello che considerano la burstiness insieme ad altri indicatori linguistici, coerenza semantica e pertinenza contestuale.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Spiegazione Tecnica della Misurazione della Burstiness
La burstiness viene calcolata analizzando la distribuzione statistica delle lunghezze delle frasi e degli schemi strutturali all’interno di un testo. La metrica quantifica la varianza—essenzialmente misura quanto le singole frasi si discostano dalla lunghezza media delle frasi in un documento. Un documento con elevata burstiness contiene frasi che variano notevolmente in lunghezza; ad esempio, uno scrittore può far seguire a una frase di tre parole (“Capito?”) una frase di venticinque parole con molte proposizioni e frasi subordinate. Al contrario, una bassa burstiness indica che la maggior parte delle frasi è raccolta intorno a una lunghezza simile, tipicamente tra dodici e diciotto parole, creando un ritmo monotono. Il calcolo prevede diversi passaggi: prima si misura la lunghezza di ogni frase in parole; poi si calcola la media aritmetica (media) della lunghezza delle frasi; infine si calcola la deviazione standard per stabilire quanto le frasi individuali si discostano dalla media. Una deviazione standard più alta indica maggiore variazione e quindi burstiness più elevata. I moderni rilevatori IA come Winston AI e Pangram impiegano algoritmi sofisticati che non si limitano a contare le parole ma analizzano anche la complessità sintattica—la disposizione strutturale di proposizioni, frasi e elementi grammaticali. Questa analisi più profonda rivela che gli scrittori umani utilizzano strutture frasali diversificate (frasi semplici, composte, complesse e composte-complesse) in schemi imprevedibili, mentre i modelli IA tendono a favorire particolari modelli strutturali che ricorrono frequentemente nei loro dati di addestramento.
Burstiness vs. Perplessità: Analisi Comparativa
| Metrica | Burstiness | Perplessità | Focus della Misurazione |
|---|
| Definizione | Variazione nella lunghezza e struttura delle frasi | Prevedibilità delle singole parole | Livello della frase vs. livello della parola |
| Scrittura Umana | Alta (strutture variate) | Alta (parole imprevedibili) | Ritmo naturale e vocabolario |
| Testo Generato dall’IA | Bassa (strutture uniformi) | Bassa (parole prevedibili) | Coerenza statistica |
| Applicazione nel Rilevamento | Identifica monotonia strutturale | Identifica schemi di scelta delle parole | Metodi di rilevamento complementari |
| Rischio Falsi Positivi | Più alto per chi scrive in L2 | Più alto per scrittura tecnica/accademica | Entrambi hanno limitazioni |
| Metodo di Calcolo | Deviazione standard delle lunghezze delle frasi | Analisi della distribuzione di probabilità | Approcci matematici diversi |
| Affidabilità da Sola | Insufficiente per rilevamento definitivo | Insufficiente per rilevamento definitivo | Più efficace se combinata |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Come i Modelli Linguistici IA Producono Bassa Burstiness
I large language model come ChatGPT, Claude e Google Gemini sono addestrati tramite un processo chiamato predizione del prossimo token, in cui il modello apprende a prevedere la parola statisticamente più probabile che dovrebbe seguire una determinata sequenza. Durante l’addestramento, questi modelli sono esplicitamente ottimizzati per minimizzare la perplessità sui loro set di dati di addestramento, il che crea involontariamente bassa burstiness come effetto collaterale. Quando un modello incontra ripetutamente una particolare struttura frasale nei dati di addestramento, impara a riprodurla con alta probabilità, risultando in lunghezze frasali costanti e prevedibili. Le ricerche di Netus AI e Winston AI mostrano che i modelli IA presentano una firma stilometrica distintiva caratterizzata da costruzione uniforme delle frasi, uso eccessivo di frasi di transizione (come “Inoltre,” “Pertanto,” “In aggiunta”) e una preferenza per la forma passiva rispetto a quella attiva. L’affidamento ai modelli di probabilità fa sì che i modelli gravitino verso gli schemi più comuni nei dati di addestramento, invece di esplorare l’intero spettro delle possibili costruzioni frasali. Questo crea una situazione paradossale: più dati vengono usati per addestrare il modello, più quest’ultimo impara a riprodurre schemi comuni e quindi minore diventa la burstiness. Inoltre, i modelli IA mancano della spontaneità e della variazione emotiva che caratterizzano la scrittura umana—non scrivono in modo diverso se sono “entusiasti”, “frustrati” o stanno enfatizzando un concetto. Invece, mantengono una linea stilistica costante che riflette il centro statistico della distribuzione di addestramento.
Burstiness nei Sistemi di Rilevamento IA
Le piattaforme di rilevamento IA hanno integrato l’analisi della burstiness come componente centrale nei loro algoritmi, seppure con diversi gradi di sofisticazione. I primi sistemi di rilevamento si affidavano molto a burstiness e perplessità come metriche principali, ma le ricerche hanno messo in luce limiti significativi di questo approccio. Secondo Pangram Labs, i rilevatori basati su perplessità e burstiness producono falsi positivi quando analizzano testi provenienti dai set di dati di addestramento dei modelli linguistici—notoriamente, la Dichiarazione d’Indipendenza viene spesso segnalata come generata da IA perché compare così frequentemente nei dati di addestramento che il modello le assegna una perplessità uniformemente bassa. I sistemi di rilevamento moderni come Winston AI e Pangram ora adottano approcci ibridi che combinano l’analisi della burstiness con modelli di deep learning addestrati su campioni di testo umano e IA. Questi sistemi analizzano simultaneamente più dimensioni linguistiche: variazione strutturale delle frasi, diversità lessicale (ricchezza del vocabolario), schemi di punteggiatura, coerenza contestuale e allineamento semantico. L’integrazione della burstiness in quadri di rilevamento più ampi ha migliorato notevolmente la precisione—Winston AI riporta un’accuratezza del 99,98% nel distinguere contenuti generati da IA da quelli scritti da umani, analizzando più indicatori invece di affidarsi solo alla burstiness. Tuttavia, la metrica resta preziosa come componente di una strategia di rilevamento completa, soprattutto se combinata con l’analisi di perplessità, schemi stilometrici e coerenza semantica.
Applicazioni Pratiche e Best Practice
- Creazione di contenuti: Gli scrittori possono variare intenzionalmente lunghezza e struttura delle frasi per creare contenuti più coinvolgenti e umani che risuonano con i lettori ed evitano i flag dei rilevatori IA
- Scrittura accademica: Studenti e ricercatori dovrebbero impiegare costruzioni frasali diversificate per dimostrare competenze di scrittura avanzata ed evitare falsi positivi nei sistemi di rilevamento IA usati nelle istituzioni educative
- SEO e Content Marketing: Gli editori possono migliorare la qualità dei contenuti e il posizionamento nei motori di ricerca aumentando la burstiness, che si correla con punteggi di leggibilità più elevati e migliori metriche di coinvolgimento
- Brand Monitoring: Le organizzazioni che utilizzano piattaforme come AmICited possono analizzare i pattern di burstiness nelle risposte IA per stabilire se le citazioni del loro brand appaiono in contenuti realmente umani o generati da macchine
- Rilevamento e Verifica IA: Educatori, editori e moderatori di contenuti possono usare l’analisi della burstiness come uno dei segnali per identificare possibili contributi generati dall’IA e mantenere standard di autenticità
- Miglioramento della scrittura: Gli autori possono usare le metriche di burstiness come feedback per affinare il proprio stile, assicurando di mantenere il coinvolgimento del lettore attraverso un ritmo naturale e una costruzione variata delle frasi
- Apprendimento delle lingue: Gli insegnanti di inglese L2 possono aiutare gli studenti a capire che sviluppare strutture frasali variate è una competenza avanzata che contribuisce a una scrittura inglese più naturale e autentica
Burstiness e Metriche di Leggibilità
La relazione tra burstiness e leggibilità è ben documentata nella ricerca linguistica. I punteggi Flesch Reading Ease e Flesch-Kincaid Grade Level, che misurano l’accessibilità del testo, si correlano fortemente ai pattern di burstiness. I testi con maggiore burstiness tendono a raggiungere punteggi di leggibilità migliori perché la variazione della lunghezza delle frasi previene l’affaticamento cognitivo e mantiene alta l’attenzione del lettore. Quando i lettori incontrano un ritmo costante di frasi di dimensioni simili, il cervello si adatta al pattern prevedibile, portando a disinteresse e ridotta comprensione. Al contrario, una burstiness elevata crea un effetto di flusso e riflusso che mantiene il lettore mentalmente partecipe grazie alla variazione del carico cognitivo—le frasi brevi offrono informazioni immediate e digeribili, mentre quelle lunghe consentono lo sviluppo di idee complesse e sfumature. Le ricerche di Metrics Masters indicano che un’elevata burstiness genera circa il 15-20% di ritenzione mnemonica in più rispetto ai testi a bassa burstiness, poiché il ritmo vario aiuta a codificare meglio le informazioni nella memoria a lungo termine. Questo principio si applica a tutti i tipi di contenuto: post di blog, articoli accademici, testi di marketing e documentazione tecnica beneficiano tutti di una burstiness strategica. Tuttavia, la relazione non è lineare—una burstiness eccessiva che sacrifica la chiarezza rende il testo frammentato e difficile da seguire. L’approccio ottimale prevede variazione intenzionale in cui le scelte strutturali servono il significato del contenuto e l’intenzione comunicativa dello scrittore invece di esistere solo per aumentare la metrica.
Limiti e Critiche del Rilevamento Basato su Burstiness
Nonostante la sua ampia adozione nei sistemi di rilevamento IA, il rilevamento basato sulla burstiness presenta limiti significativi che ricercatori e operatori devono comprendere. Pangram Labs ha pubblicato una ricerca esaustiva che identifica cinque principali criticità: primo, i testi provenienti dai set di dati di addestramento IA vengono erroneamente classificati come generati da IA perché i modelli sono ottimizzati per minimizzare la perplessità sui dati di addestramento; secondo, i valori di burstiness sono relativi ai modelli linguistici specifici, quindi modelli diversi producono profili di perplessità differenti; terzo, i modelli commerciali closed-source come ChatGPT non espongono le probabilità dei token, rendendo impossibile il calcolo della perplessità; quarto, i parlanti non madrelingua inglese vengono segnalati in modo sproporzionato come IA a causa delle loro strutture frasali più uniformi; e quinto, i rilevatori basati su burstiness non possono auto-migliorarsi iterativamente con nuovi dati. Lo studio Stanford 2023 sugli elaborati TOEFL ha rilevato che circa il 26% dei testi non madrelingua inglese è stato erroneamente segnalato come generato da IA dai rilevatori basati su perplessità e burstiness, contro solo il 2% di falsi positivi nei testi madrelingua. Questo bias solleva seri problemi etici in ambito educativo dove il rilevamento IA viene utilizzato per valutare il lavoro degli studenti. Inoltre, i contenuti basati su template in marketing, scrittura accademica e documentazione tecnica presentano naturalmente minore burstiness a causa di requisiti di stile e convenzioni strutturali, portando a falsi positivi in questi ambiti. Questi limiti hanno spinto allo sviluppo di approcci di rilevamento più sofisticati che trattano la burstiness come un segnale tra molti piuttosto che come indicatore definitivo di generazione IA.
Burstiness nei Diversi Contesti di Scrittura
I pattern di burstiness variano notevolmente tra i diversi generi e contesti di scrittura, riflettendo i diversi scopi comunicativi e le aspettative del pubblico di ciascun dominio. La scrittura accademica, in particolare nei settori STEM, tende a presentare burstiness più bassa perché gli autori seguono guide di stile rigorose e strutture coerenti per chiarezza e precisione. Documenti legali, specifiche tecniche e articoli scientifici privilegiano la coerenza e la prevedibilità rispetto alla variazione stilistica, producendo naturalmente punteggi di burstiness inferiori. Al contrario, scrittura creativa, giornalismo e copywriting dimostrano tipicamente burstiness elevata perché questi generi puntano al coinvolgimento del lettore e all’impatto emotivo attraverso ritmo e variazione. La narrativa letteraria, in particolare, usa forti cambiamenti di lunghezza delle frasi per creare enfasi, tensione e controllare il ritmo narrativo. La comunicazione aziendale occupa una posizione intermedia—email e rapporti professionali mantengono una burstiness moderata per bilanciare chiarezza e coinvolgimento. La metrica Flesch-Kincaid Grade Level rivela che la scrittura accademica destinata a un pubblico universitario spesso utilizza frasi più lunghe e complesse, che potrebbero sembrare ridurre la burstiness; tuttavia, la variazione nella struttura delle proposizioni e nei pattern subordinati crea comunque burstiness significativa. Comprendere queste variazioni contestuali è cruciale per i sistemi di rilevamento IA, che devono tenere conto delle convenzioni di genere per evitare falsi positivi. Un manuale tecnico con frasi uniformemente lunghe non dovrebbe essere segnalato come generato da IA solo perché mostra bassa burstiness—la bassa burstiness riflette scelte stilistiche appropriate al genere e non è indice di generazione automatica.
Evoluzione Futura e Implicazioni Strategiche
Il futuro dell’analisi della burstiness nel rilevamento IA si sta evolvendo verso approcci più sofisticati e consapevoli del contesto, che riconoscono i limiti della metrica pur sfruttandone gli spunti. Man mano che i large language model diventano più avanzati, iniziano a incorporare la variazione della burstiness nei loro output, rendendo il rilevamento basato solo su questa metrica meno affidabile. I ricercatori stanno sviluppando sistemi di rilevamento adattivi che analizzano la burstiness insieme a coerenza semantica, accuratezza fattuale e pertinenza contestuale. L’emergere di strumenti di umanizzazione IA che aumentano deliberatamente burstiness e altre caratteristiche tipiche dell’umano rappresenta una continua corsa agli armamenti tra tecnologie di rilevamento ed elusione. Tuttavia, gli esperti prevedono che un rilevamento davvero affidabile dipenderà in ultima analisi da metodi di verifica crittografica e tracciamento della provenienza più che dalla sola analisi linguistica. Per creatori di contenuti e organizzazioni, l’implicazione strategica è chiara: invece di considerare la burstiness come una metrica da manipolare, gli scrittori dovrebbero concentrarsi sullo sviluppo di uno stile autentico e vario che rifletta naturalmente i modelli comunicativi umani. La piattaforma di monitoraggio AmICited rappresenta una nuova frontiera in questo ambito, monitorando come i brand appaiono nelle risposte IA e analizzando le caratteristiche linguistiche di tali citazioni. Con la crescente prevalenza dei sistemi IA nella generazione e distribuzione di contenuti, comprendere la burstiness e le metriche correlate diventa sempre più importante per mantenere l’autenticità del brand, garantire l’integrità accademica e preservare la distinzione tra contenuti umani e generati da macchine. L’evoluzione verso approcci di rilevamento multi-segnale suggerisce che la burstiness resterà rilevante come componente dei sistemi di monitoraggio IA completi, anche se il suo ruolo diventerà più sfumato e dipendente dal contesto.